一个 17 岁的少年,花 20 小时就能学会开车。
GPT-4 读完了 30 万亿个 token,约 10^14 字节的文本。一个 4 岁孩子的视觉皮层,从出生到 4 岁,通过 200 万根视神经纤维,同样接收了约 10^14 字节的信息。信息量在一个数量级上,结果天差地别:孩子掌握了重力、物体永久性、因果、动量守恒,GPT-4 掌握了语言的统计规律。
这个差距说明一件事——孩子有世界模型,GPT-4 没有。
从 Meta 离开,LeCun 在巴黎创立 AMI Labs,募了 10 亿美元,远离硅谷 VC。理念是:当前所有 AI,包括最强的 LLM,都无法对世界建模;任何缺少内部预测模型的系统,会永久停留在脆弱、不安全、样本效率低下的状态;补上这块缺口的,是建立在联合嵌入预测架构(JEPA)之上的世界模型,而不仅仅是生成式的 token 预测。
一、世界模型是什么
世界模型回答一个问题:给定世界当前状态 $s_t$,以及我设想采取的动作 $a$,下一刻的状态 $s_{t+1}$ 会是什么样?
ŝ_{t+1} = WM(s_t, a_t)
关键是在一个抽象的、学到的状态表示上运算。把这个模型沿时间向前滚动,在想象出的动作序列上做优化,通过优化来规划——这便是 System 2 推理的基础。
世界是非确定的。前方的车可能加速也可能刹车,球可能弹向左也可能弹向右。世界模型不预测单一未来,它维护一个隐变量 $z$ 来参数化所有合理未来的分布:
ŝ_{t+1} = WM(s_t, a_t, z), z ~ p(z)
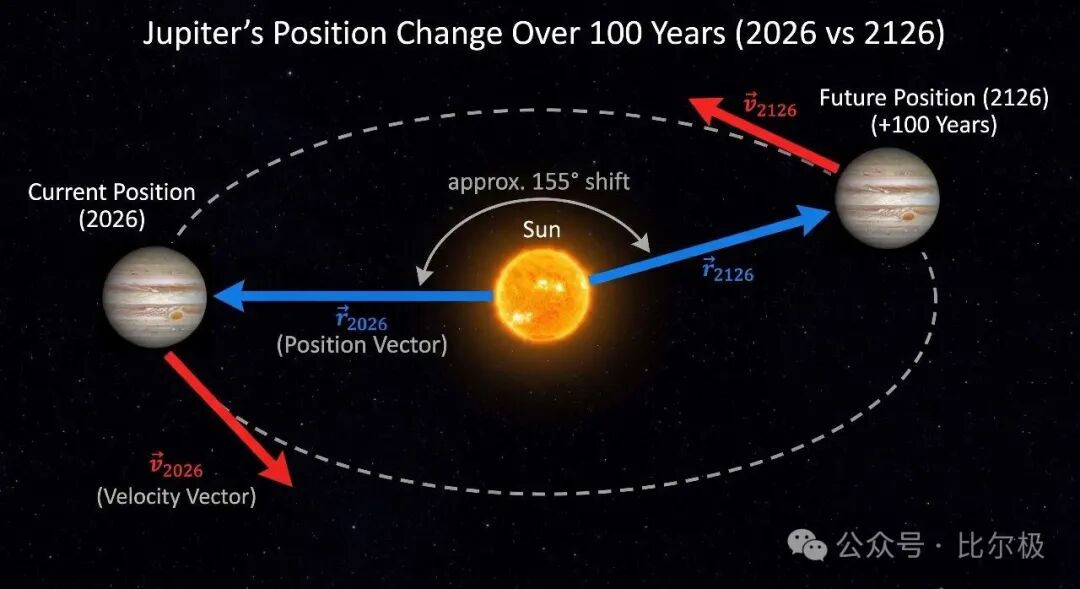
“正确的表示”意味着什么?预测木星 100 年后的位置,只需要 6 个数字——位置和速度向量。 不需要模拟木星上的每一个分子。正确的表示消除无关细节,只保留预测所需的结构。这个直觉贯穿整个 JEPA 框架。
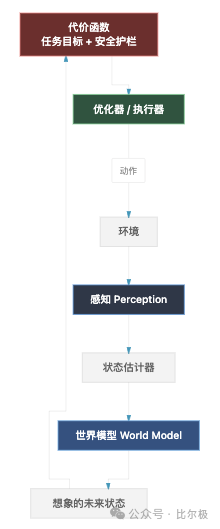
世界模型的完整认知架构:感知模块估计状态,工作记忆保存近期信息,世界模型滚动预测想象中的未来,代价函数同时编码任务目标和安全约束,优化器搜索同时满足两者的动作。
安全护栏被硬编码进代价函数,作为优化问题定义的一部分,不是现在 LLM 那种事后过滤器或者 SFT/RLVR。系统逃不出护栏,因为护栏就是它求解的约束本身。
二、为什么 LLM 走不到这一步
LLM 是优秀的语言产品,但自回归 token 预测在结构上产生不了世界模型。
2.1 缺陷一:每个 token 分到的计算量恒定
Transformer 的一次前向传播,attention 部分是 $O(n^2d)$。序列里每个 token,无论承载的是“2+2 等于几”还是“证明这个 NP 难问题”,拿到的计算量完全一样。
难题需要比简单问题更多的计算,LLM 没有识别“这个问题难、要多算一会儿”的机制。Chain-of-thought 的本质,是诱导模型多吐 token,用 token 数量换计算量。底层仍然是逐 token 生成,只是被提示生成得更多。
正确的推理机制应该是在输出空间上做优化——一个能把更多计算分配给更难子问题的搜索过程。A*、MCTS、SAT 求解、经典规划都具备这个性质,token 预测不具备。
2.2 缺陷二:自回归误差按指数衰减
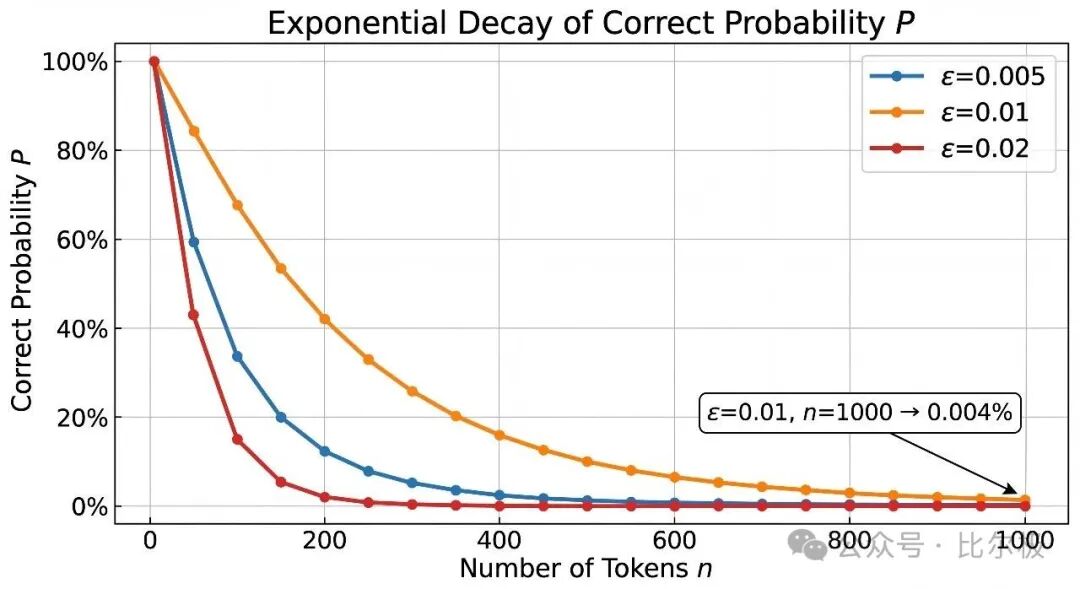
LLM 逐 token 生成,每一步从约 10 万个 token 的分布里采样一个。设每步偏离正确子树的概率为 ε。生成树没有回溯边——一旦走出正确子树,回不来。长度为 n 的序列全部正确的概率:
P(正确序列) = (1 - ε)^n
取 ε = 0.01,n = 1000:
P ≈ 4.3 × 10⁻⁵ ≈ 0.004%
这不来自训练不足。语言本身有歧义、依赖上下文,ε 永远压不到零。唯一的出路是改变答案的产生方式。人类不靠一个词一个词往外蹦来回答问题,而是先形成一个抽象的想法——答案的语义表示——再翻译成词。LLM 跳过了抽象想法,直接输出到 token 表面含义上了。
2.3 缺陷三:没有世界模型,就无法规划
一个规划系统必须能回答“我在状态 s 执行动作 a,会发生什么”。LLM 没有显式的状态表示,没有运动模型,无法把世界向前滚动。它能生成描述计划的文本,但是缺点是没有机制去验证这些计划在物理世界里是否成立。
当前基于 LLM 的智能体执行动作、观察结果,再执行下一步——这是错误的规划方式,不是预测式规划。我无法理解,一个系统在不具备预测自身行为后果能力的前提下,怎么能被叫做智能体系统。
2.4 缺陷四:语言是有损的抽象
语言为共享世界模型的人类之间的沟通而演化。“猫在垫子上”你能听懂,因为你早已从现实中的物理经验里知道猫、垫子和“在……上”分别意味着什么。语言是对思想的压缩表达,本身不是思想。LLM 只接触到压缩后的产物,够不到语言当初要压缩的那些物理直觉。
由此引出对 VLA(视觉-语言-动作)模型的错误分析。RT-2、Physical Intelligence 的 π 系列把 VLM 接上动作头,用人类演示数据做大规模行为克隆。继承 LLM 的全部结构性缺陷,又叠加了机器人特有的脆弱:
- 泛化有硬边界:能迁移 LLM 主干已知的概念,但发明不了新的操作策略,遇到与预/后训练分布差太远的配置就崩。
- 数据采集不可扩展:人类演示昂贵,受限于人的可用性,而物理环境的多样性是无穷的。
- 没有显式规划过程:端到端从图像映射到动作,无法模拟“如果我把箱子往左推而不是往右推会怎样”,没有安全保证。作为对照,V-JEPA 2 在 100 万小时互联网视频上预训练,不用机器人数据、不用标注;只需加入 62 小时无标注机器人轨迹,就能做动作条件预测。1M+ 小时观察 : 62 小时动作数据,这个比例比行为克隆所需的数量级有利得多。
2.5 缺陷的根源:生成式视频在数学上不可行
最深的技术理由针对生成式视频模型。预测下一帧,目标是一个 $[H \times W \times 3]$ 的张量。以 1080p 为例:
1920 × 1080 × 3 ≈ 620 万个像素值
每通道 256 个离散值
可能的下一帧:256^(620万) ≈ 10^(1500万)
可观测宇宙的原子数约 $10^{80}$。LLM 能工作,是因为词表只有约 10 万 token,可以枚举并赋概率。视频帧没有对应的枚举方案。生成式视频模型面对不确定性只剩三条路:对所有未来取平均(得到模糊画面);用隐变量(简单视频可行,复杂自然场景失败);学连续分布(需要估计配分函数 Z)。

第三条是原则上正确的,但 $Z = \int \exp(-E(y)) dy$ 对任何非平凡的神经能量函数都没有闭式解。这是数学上的不可解。JEPA 绕开了这个死胡同:不建模下一帧的分布,而是建模下一个嵌入的分布——一个维度低得多的空间。像素级细节的不确定性被编码器吸收,不再要求预测器显式建模。
三、能量、坍缩与 SIGReg
3.1 能量模型:统一视角
整个自监督学习可放进能量模型(EBM)的框架。一个 EBM 定义标量函数 $F_\theta(x, y)$,度量输入 $x$ 和候选输出 $y$ 的相容程度。低能量等于相容,高能量等于不相容。训练就是塑形这个能量曲面,推理则是给定 $x$,求最小化能量的 $y$:
y* = argmin_y F_θ(x, y)
这是通过优化来推理,不是 LLM 的一次前向传播。最短路径、SAT 求解、Viterbi 解码、最优控制都是这个结构。Gibbs 分布能把能量转成概率,但配分函数 $Z(x)$ 对绝大多数分布不可解。直接和能量打交道,从源头绕开归一化问题。
3.2 坍缩问题
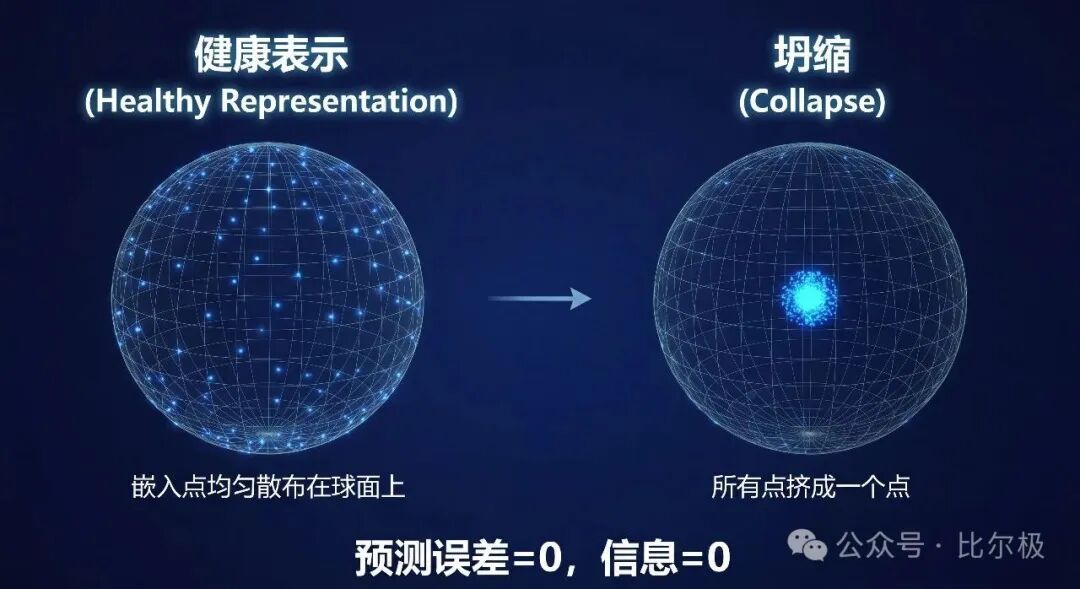
最朴素的 JEPA 目标是最小化正样本对之间的预测误差:
L = ‖E_θ(y) - P_φ(E_θ(x), z)‖²
它有一个平凡最优解:编码器把一切映射成同一个常向量。此时预测误差为零,表示携带的信息也为零。能量曲面变得处处平坦,模型什么都没学到。防止坍缩,是所有 JEPA 方法真正在解决的工程问题。
3.3 路线 A:对比方法
构造负样本,把不相容对的能量推高。最有原则的目标是 InfoNCE,它等价于一个 $(N+1)$ 类分类的交叉熵,并且给互信息提供下界。MoCo 用一个缓慢更新的动量编码器维护负样本队列,把队列大小和 batch 大小解耦。但存在维度灾难:覆盖 $d$ 维表示空间,最坏情况需要 $O(\exp(d))$ 个负样本。
3.4 路线 B:冗余消除
不去推开负样本,而是约束能量低的区域体积,强迫表示用满整个空间。
Barlow Twins 来自 Horace Barlow 1961 年关于视觉神经元消除冗余的假说。对两个增强视图的嵌入计算互相关矩阵 $C$,损失把对角线推向 1、非对角推向 0,目标是 $C = I$,等价于对表示做白化。
VICReg 把反坍缩逻辑拆成三项显式相加:不变性项拉近匹配视图,方差项让每个维度的标准差保持在阈值之上,协方差项让不同维度去相关。
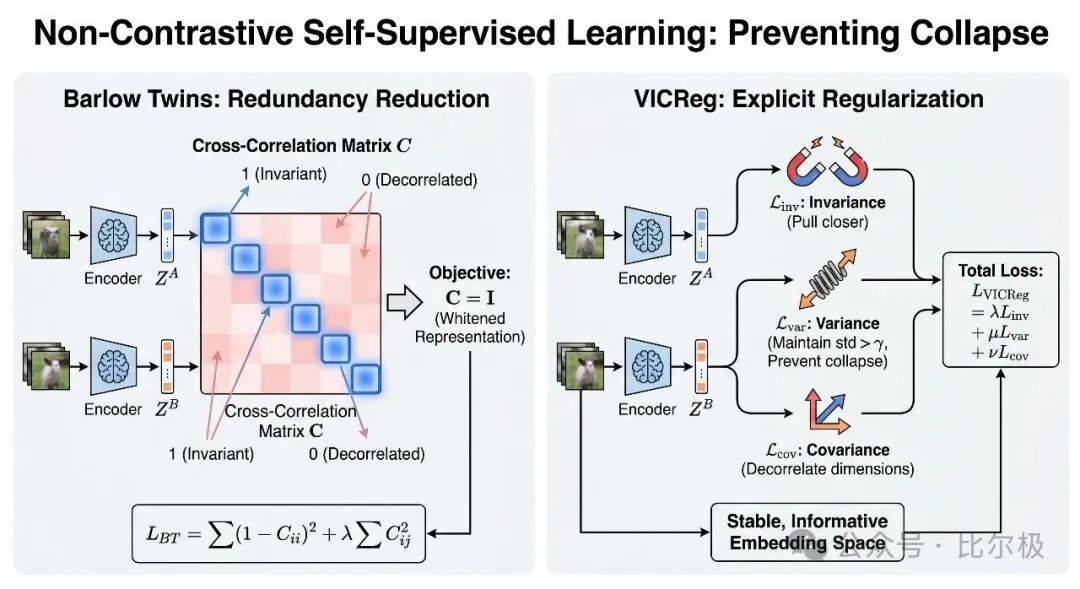
3.5 SIGReg:现代的有原则替代
Balestriero 提出的 SIGReg 用一个目标替掉 VICReg 的多项:把整个嵌入分布正则化到各向同性高斯 $N(0, I)$。直接检验高维分布是否高斯很贵。SIGReg 借助 Cramér-Wold 定理,把问题转成让所有一维投影看起来都像 $N(0,1)$。抽 M 个随机单位向量,对每个投影施加可微的正态性检验统计量:
SIGReg(Z) = (1/M) Σ_m T_EP(Z·u_m)
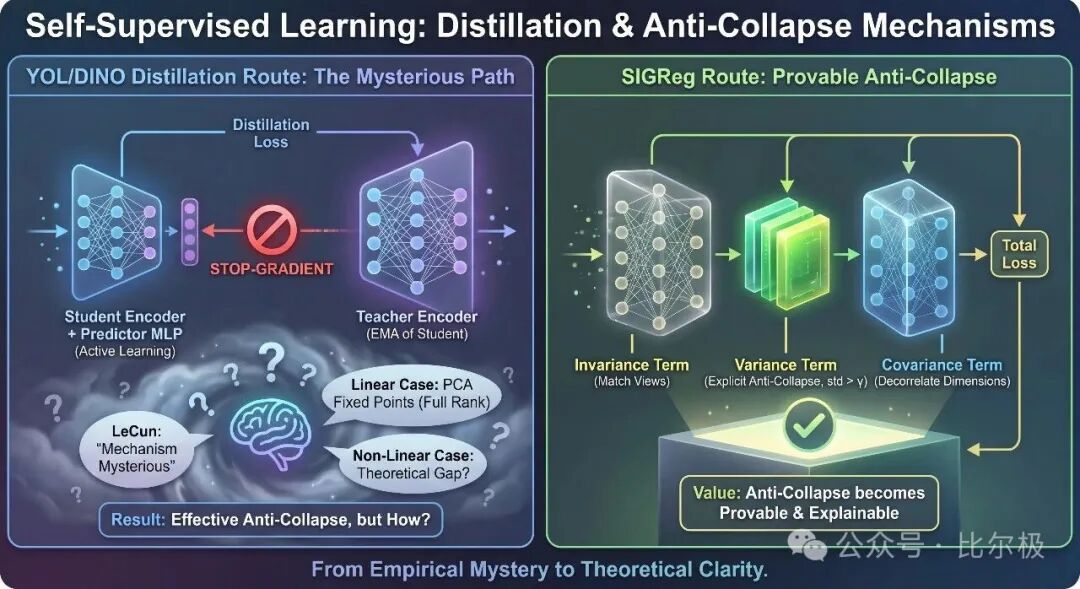
好处是只剩一个超参,自带反坍缩保证,且不需要 stop-gradient 或 EMA。LeWorldModel 最干净的训练目标端到端从原始像素训练,两项损失、一个超参。
值得注意的还有 BYOL/DINO 这条蒸馏路线:靠师生不对称来防坍缩。它有效,但 LeCun 坦承“机制神秘”——非线性情形理论上仍未完全解释。SIGReg 的价值正在于它把“为什么不坍缩”变成了可证明的事。
3.6 表示的几何意义
物理里的重整化群消除细粒度自由度、保留粗粒度的预测结构——好的编码器就是一个学出来的重整化操作。每上升一个表示层级,丢失的信息就是熵;每一层科学抽象都由它刻意丢弃的信息来定义。编码器应当丢弃在给定上下文下不可预测的信息——世界的“不可约熵”——剩下的就是可预测的结构:位置、速度、力、意图。
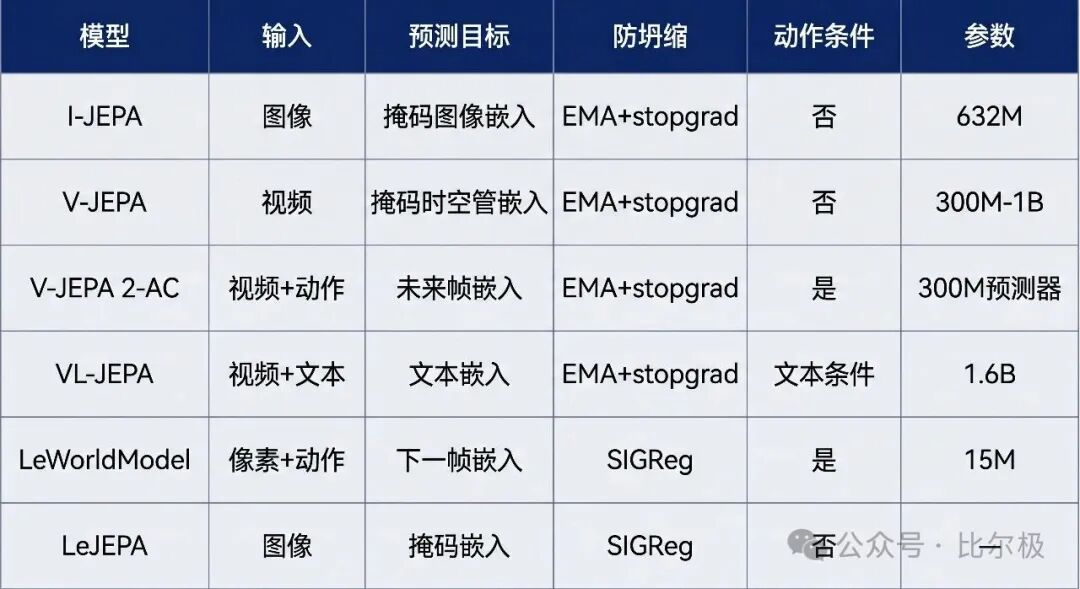
四、JEPA 架构家族:从 1992 到现在
自监督学习路线可以归纳为三类:生成式、对比式、以及联合嵌入预测型(JEPA)。对于文本等离散符号序列,生成式方法效果良好;而在处理图像、视频等连续高维信号时,唯有联合嵌入预测架构具备扩展性。生成式方法在不可压缩的像素噪声上消耗建模能力,对比式方法遇到组合爆炸的瓶颈,JEPA 以极简结构突破限制。
4.1 起点:孪生网络(贝尔实验室,1992)
LeCun 1994 年为签名防伪造了第一个孪生网络:两个共享权重的编码器分别编码签名 A 和 B,在嵌入空间比距离。1992 年就已具备的性质——共享编码器权重、正负对对比训练、不重建原始输入、在嵌入空间做预测——是所有现代 JEPA 变体的直系祖先。
4.2 I-JEPA:图像
把图像的一大块连续区域作为上下文,4 个各约 15%的连续块作为预测目标。预测器以掩码块的空间位置为条件,必须学出场景的空间地图。和 MAE 的对比很说明问题:MAE 预测像素、学到纹理、冻结表示弱;I-JEPA 预测嵌入、学到语义、冻结表示强,且训练 GPU 时间约为 MAE 的 1/7。
4.3 V-JEPA:视频
把 2D 空间预测扩展到 3D 时空预测。预测器学会物体永久性、运动连续性、物理因果,全部来自原始视频、没有标注。V-JEPA 2 的编码器是 ViT-g/16,用 3D-RoPE 做位置编码,在 22M 小时视频上训练。基准上动作识别和预判均有显著提升。
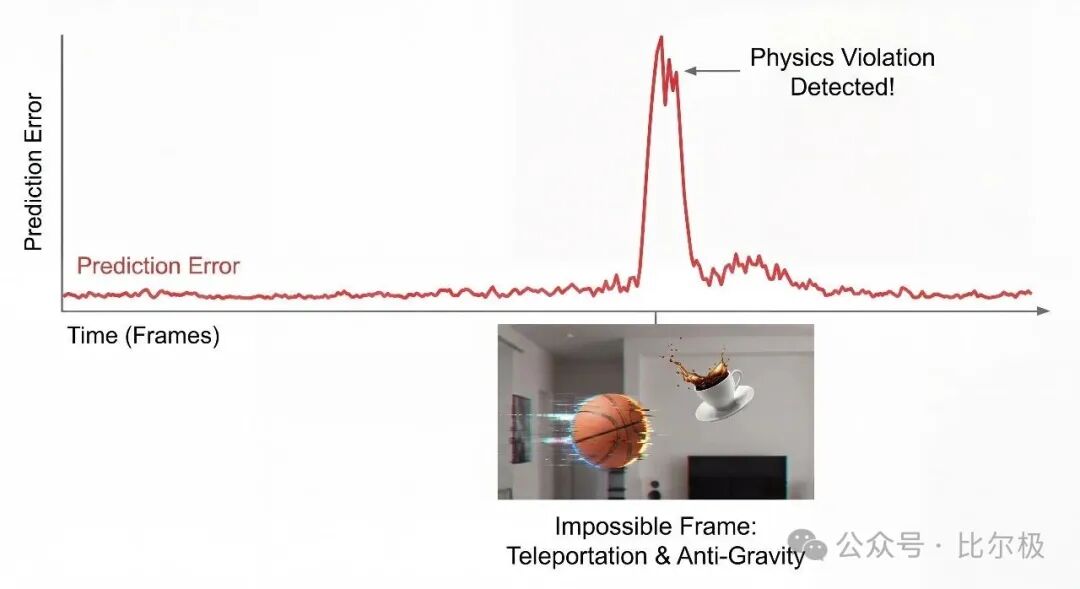
最有意思的是常识物理:给它看球在半空中瞬移、物体向上掉落这类违反物理的视频,预测误差会在不可能事件发生的那一刻急剧飙升。这是第一个纯从视频、无任何物理标签或符号规则,就能检测物理不合理性的 AI 系统。
4.4 V-JEPA 2-AC:动作条件
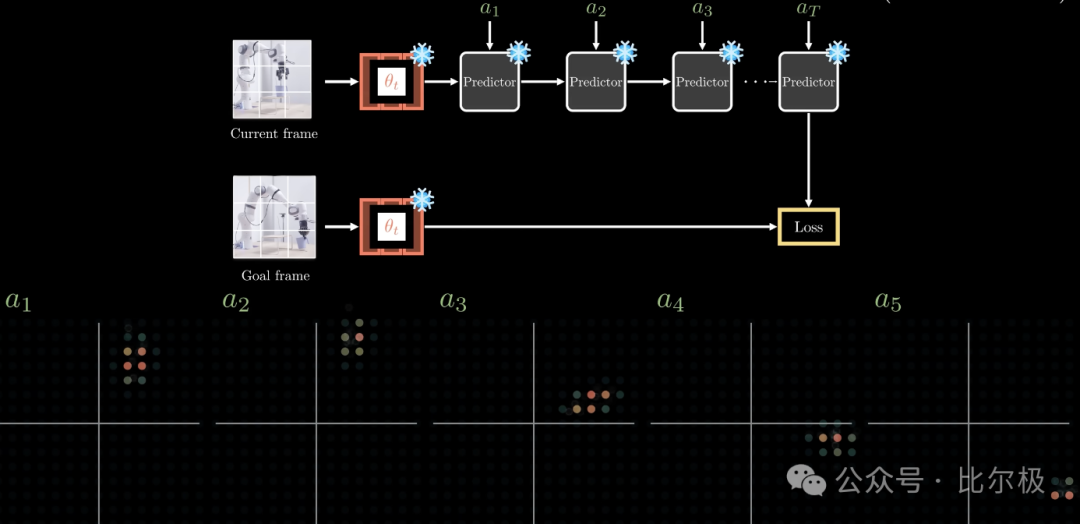
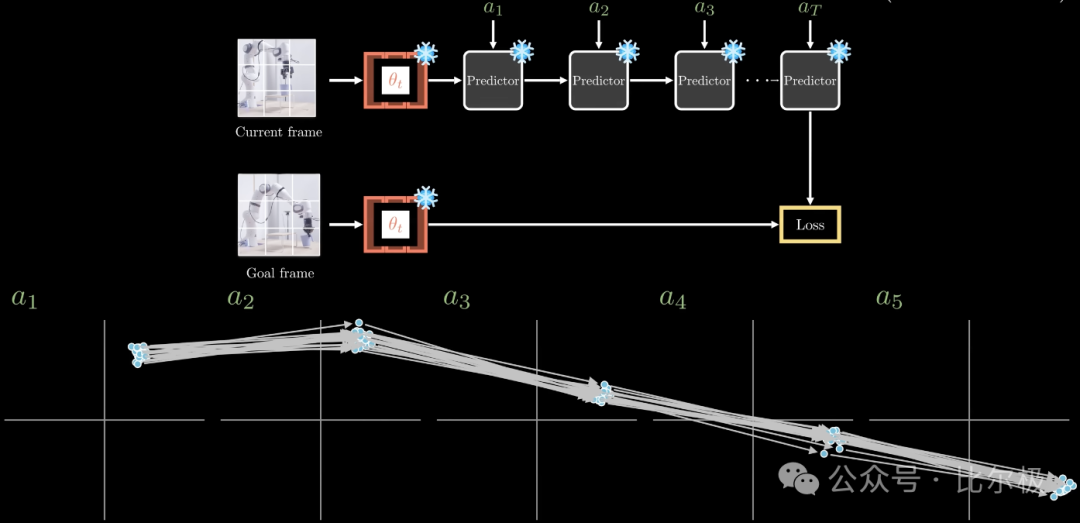
两阶段训练。阶段一是自监督预训练,产出冻结的视频编码器。阶段二在 62 小时无标注机器人轨迹上训练一个动作条件预测器。重活由预训练编码器干完,预测器只需学习动作如何修改已学好的表示。部署时零样本:在不同实验室的 Franka 机械臂上,不采集环境数据、不做任务特定训练,目标用图像指定。规划用 MPC + CEM 在世界模型上搜索想象的动作序列,机械臂完成了对新物体的拿取-放置。
4.5 VL-JEPA:接住语言
标准 VLM 是“图像编码器 + 自回归 LLM”。VL-JEPA 把生成式输出换成嵌入预测。这为什么更高效呢?同一个物理事实在文本里有许多种说法,token 空间里这几句几乎正交,选了正确的另一种措辞反而被惩罚。嵌入空间里语义相近的句子被映射到邻近点,目标分布从多峰变成近似单峰,好拟合得多。实测对照显示,VL-JEPA 用 1.6B 参数在 GQA 上胜过 7B 的标准 VLM。
顺带解决了实时视频流。VL-JEPA 每帧一次前向得到一个嵌入,持续监控这条语义嵌入流,只在检测到语义突变时才触发解码器,解码调用大幅减少。智能眼镜需要这种方法:常开监控视野,只在重要的事发生时才出声。
4.6 LeWorldModel:最干净的端到端系统
ViT-Tiny 编码器加 Transformer 预测器,总计 15M 参数,单 GPU 几小时训完。它是第一个从像素端到端、带可证明反坍缩保证的 JEPA。
它的规划速度优势来自 token 数量。DINO-WM 每帧约 200 个 patch token,H=25 步规划每次 CEM 迭代需要大量预测;LeWM 每帧 1 个 CLS token,规划快 48×。训练后用线性探针能从它的潜空间读出物体位置、速度、朝向、质量——它从像素-动作轨迹里隐式学到了牛顿定律,没有任何物理标签。
五、学到“真正的”世界模型的时间
一个世界模型要可信,它的内部表示必须对应世界真实的自由度。在什么条件下,学到的表示能线性恢复世界真实的隐变量?
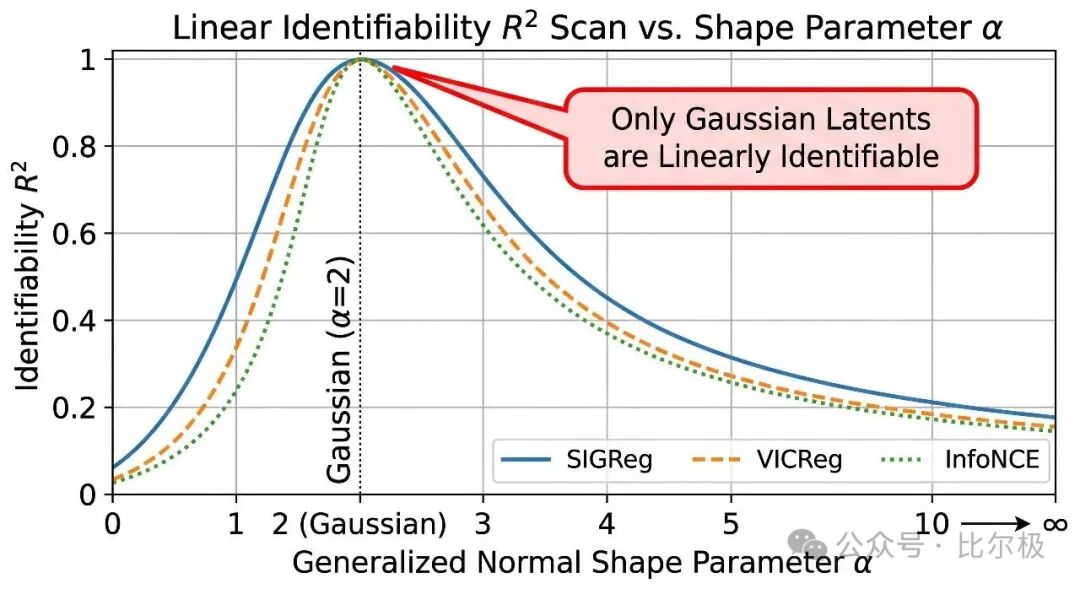
理论假设高斯隐变量,正样本对之间是 Ornstein-Uhlenbeck 转移。在这个设定下,转移算子的本征函数恰好是 Hermite 多项式,d 次多项式的本征值是 $\rho^d$。含义很关键:
- 线性函数($d=1$)最可预测,本征值 $\rho$
- 二次($d=2$)次之,本征值 $\rho^2$
- 更高的非线性,本征值 $\rho^d$ 指数级变小
任何对表示的非线性扭曲都会严格降低正样本对之间的相关。
四个主要定理由此展开:
定理一(正向):在高斯世界、OU 转移下,最小化对齐损失并约束嵌入为 $N(0,I)$,唯一的最优解是 $h(z) = Qz$,$Q$ 是正交矩阵。
定理二(逆向):如果每个满足协方差为 $I$ 的最优解都是线性的,那么 $z$ 必须是高斯的。只匹配二阶矩的 VICReg 不够,只有匹配完整高斯的 SIGReg 才保证线性可识别性。
定理三(近似可识别性):实践中对齐和高斯约束都只近似满足。定理给出恢复误差随近似误差的缩放界,且界优雅退化——训练损失越低,世界模型越好,不需要监督验证集。
定理四(桥接):若 $h(z) = Qz$,则对任何代价函数旋转不变的有限时域最优控制问题,潜空间里的规划等价于真实隐变量空间里的规划。可识别性是潜空间规划能找到物理上正确方案的前提。
六、分层规划:唯一还没解决的硬骨头
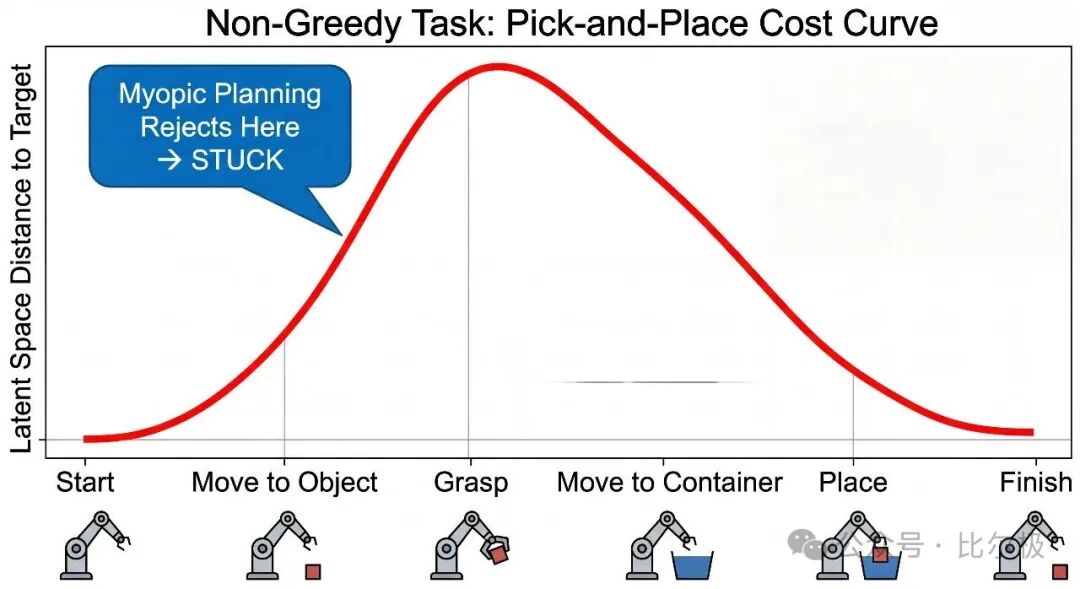
单层 JEPA 配 CEM/MPC 在短任务上能用,超过约 5 步就会失败,原因有二:误差累积与搜索空间爆炸。最能说明问题的是拿取-放置任务。机械臂必须先朝物体移动(代价上升)才能抓取,再移向容器。短视的平坦规划器看到第一步代价上升就拒绝,卡在原地。
HWM(分层世界模型)用两层解决:
- 低层世界模型 $P^{(1)}(z_{t+1} | z_t, a_t)$:处理原始动作,规划时域 5-10 步,高时间分辨率。
- 高层世界模型 $P^{(2)}(z_{t+K} | z_t, l_t)$:处理潜宏动作 $l\_t$,规划时域 3-5 个宏步,低时间分辨率。
两个模型活在同一个编码器产生的潜空间里。高层产出一串中间潜子目标,低层对子目标局部贪心。结果:拿取-放置 HWM 70% vs 平坦 MPC 0%,并且胜过用 77× 更多机器人数据训练的 VLA。模式跨架构、跨任务一致:只要任务需要非贪心行为或长时域,分层就带来大幅提升。
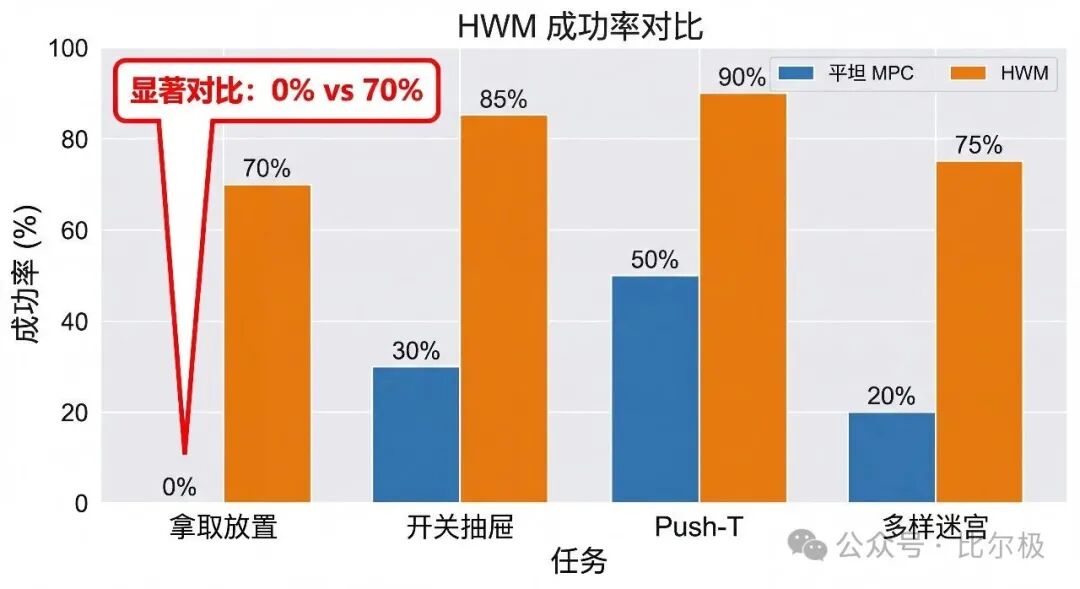
天花板在哪里?用外部提供的“神谕子目标”绕开高层规划器,HWM 和平坦 MPC 都能到 80%。差距完全在高层规划器产出子目标的质量上。剩下的开放问题:子目标质量、训练时如何选路标,以及最重要的,层级能否自发涌现而非手工指定。一个人从纽约飞巴黎,会在至少四个抽象层次上规划。LeCun 希望训练分层 JEPA 时,合适的层级结构会像 CNN 自发学出“边缘→形状→物体→场景”那样涌现出来。HWM 是一个起点,目前只有两层。
七、与大脑的对应
JEPA 与神经科学的对应:
预测编码:大脑不被动接收感觉输入,而主动预测它,用预测误差更新内部模型。这套框架和 JEPA 结构高度同构:自顶向下的预测信号对应预测器,自底向上的预测误差对应预测损失,分层皮层区对应分层世界模型。
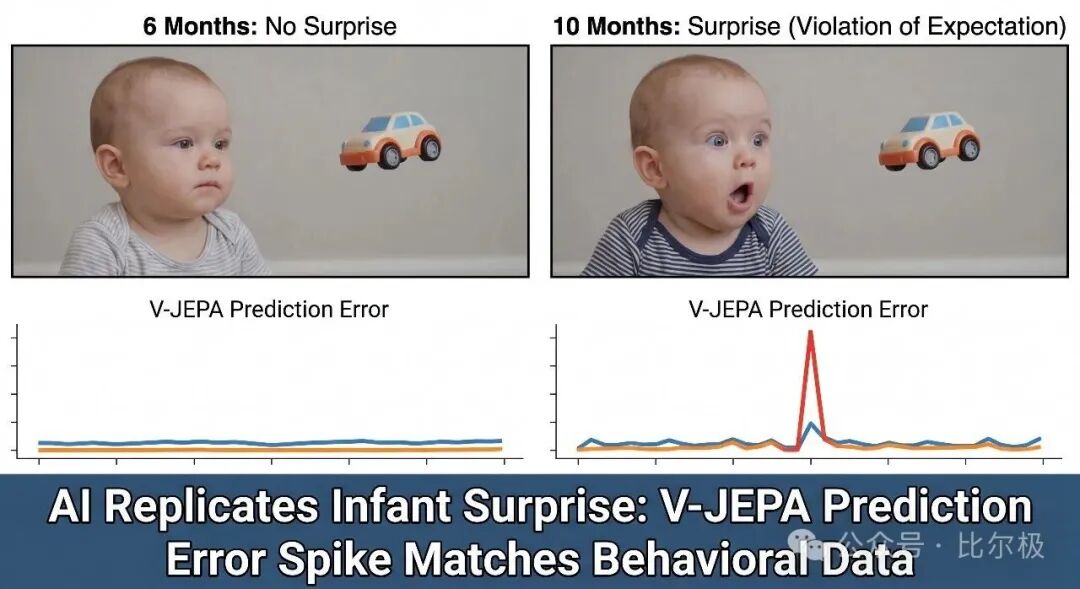
婴儿认知:给 6 个月大的婴儿看小车悬浮,婴儿不惊讶——还没有重力的世界模型。给 10 个月大的婴儿看同样画面,婴儿明显多盯着看——惊讶反应。V-JEPA 在同类实验里表现出相同行为:物理不可能事件处预测误差飙升。它没被喂过物理标签,纯训练于视频,就建起了 10 个月婴儿那样的原始直觉物理。
System 1 与 System 2:Kahneman 的两套系统直接映射到 JEPA 认知架构。System 1 是反应式策略,适合走路、伸手;System 2 是通过优化规划,适合新任务和安全攸关决策。LLM 只作为 System 1 运行,没有真正的 System 2。
神经底物的对应:前额叶皮层对应世界模型,海马体对应情景/工作记忆,视觉皮层对应编码器,基底节对应代价函数,小脑对应低层运动世界模型。小脑尤其值得注意——它维护一个极精确的身体力学前向模型,是运动控制层面的生物 JEPA。
八、硬件:当这套范式落地,芯片要变成什么样
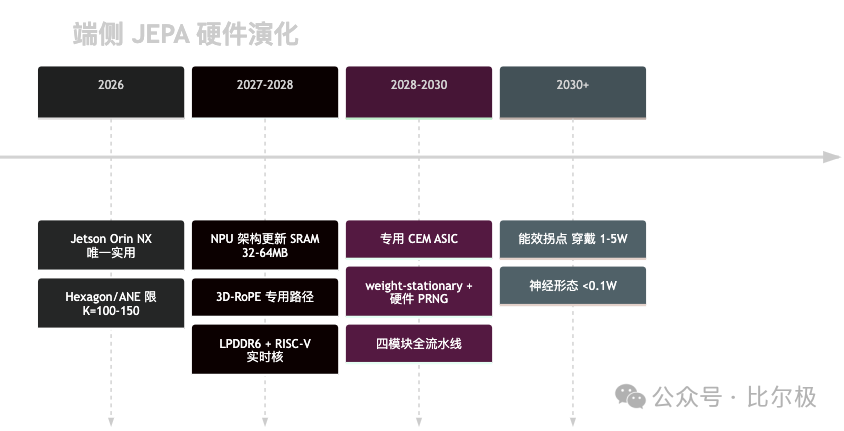
JEPA 对端侧硬件的需求与 LLM 完全不同。
8.1 两种截然不同的访问模式
LLM 自回归解码,每生成一个 token,要把整个模型的权重过一遍内存总线。在 1 FLOP/byte 的工况下,GPU 算力利用率极低,是典型的内存带宽受限负载。
JEPA 的访问模式倒过来。CEM 规划并行评估 K 条轨迹,全部共享同一套预测器权重。权重加载一次,K 条轨迹同时复用,全程在片上 SRAM 内完成,DRAM 带宽压力近似为零。JEPA 不需要 HBM,需要的是足够大的片上 SRAM。
8.2 三大端侧平台的真实差距
用两个核心负载横评高通 Hexagon NPU、Apple ANE、NVIDIA Jetson Orin NX。
负载一:ViT Encoder 推理。三个平台有个共同盲点——3D-RoPE。现有 NPU 的 RoPE 单元只实现了 1D 版本,3D 版本回退到通用矩阵乘法,效率降 3-5×。Jetson 是唯一有 CUDA 自定义 kernel 能力的平台,可针对性优化,但功耗达 15W。
负载二:CEM 规划(K=500):这是拉开差距的测试。Hexagon 的张量加速器设计上限 batch≤16,实际 K 压到约 150 才能进 100ms 预算。Apple ANE 要求编译时定死 batch,CEM 需要的动态 K 它原生不支持。Jetson 的 CUDA 对 batch=500 无设计限制,TensorRT 推理约 55ms 进 100ms 预算。它是当下唯一能在实际功耗下跑完完整规划循环的端侧平台,但 10-25W 功耗在穿戴场景是瓶颈。
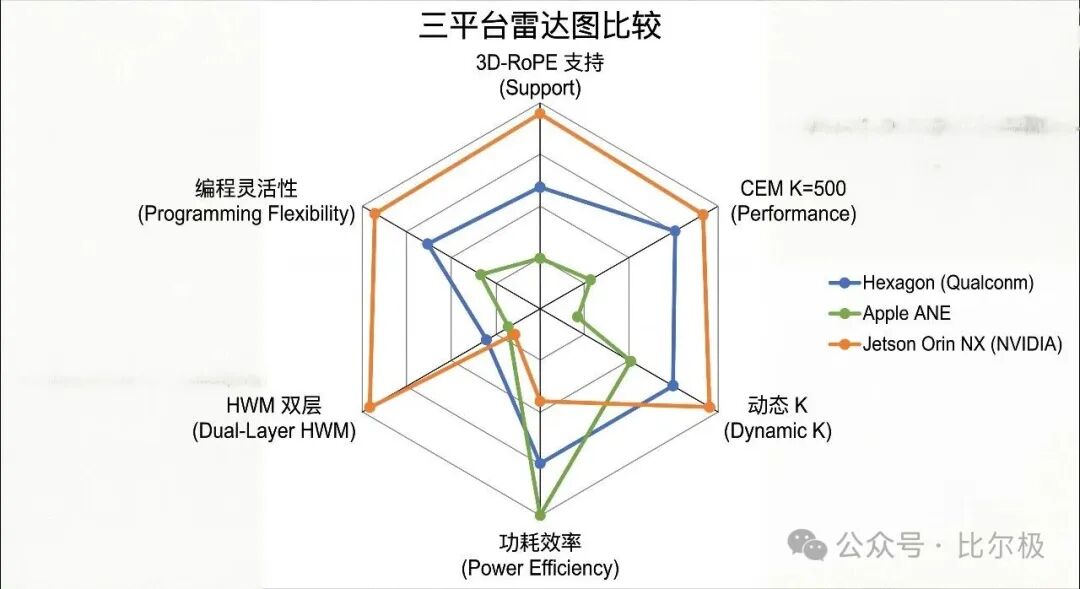
8.3 各类芯片的受力方向
NPU 是最直接的受益者,也要做最大调整:片上 SRAM 扩到 32-64MB,增加 3D-RoPE 专用路径,支持大 batch 并行推理。
CPU 从 GPU 的服务员变成规划循环的指挥者。HWM 两层规划需要 CPU 维护 CEM 的高斯分布参数、排序选精英、更新分布、判断高低层切换。需求变化是低延迟核间通信、确定性延迟、片上硬件 PRNG。
LPDDR 崛起:JEPA 预测器参数小、访问模式是“一次加载大量复用”,带宽不是瓶颈,端侧 LPDDR5X 理论上足以支撑。真正的瓶颈是片上 SRAM 大小,不是片外带宽。
8.4 RISC-V:实时规划循环
HWM 的调度层需要持续运行、μs 级延迟:NPU 跑完一批推理后,读分数、做 top-k、更新分布、触发下一次迭代。ARM Cortex-A 的乱序核无法提供确定的延迟。RISC-V 顺序执行核有无乱序缓冲区的结构性优势,开放 ISA 可加自定义指令服务 CEM 调度。
预期 2027-2028 的机器人 SoC 会是三层异构:Cortex-A 跑 Linux/ROS 做高层协调,RISC-V 实时核跑 RTOS 做 CEM 调度和传感器融合,NPU/ASIC 跑 Encoder 和预测器。
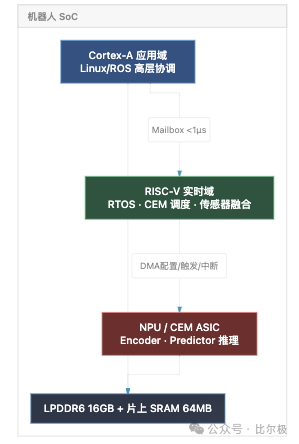
8.5 专用 CEM ASIC 的 dataflow
通用 NPU 撞到效率上限后,专用 ASIC 会出现。核心抉择是 systolic array 还是 vector processor。最优解是混合,且 systolic array 的 dataflow 必须选 weight-stationary:权重完全固定,K 条轨迹激活依次流过,零重新加载。四个模块——systolic array、向量单元、CEM 控制器、PRNG——可以完全流水线化。
PRNG 单元是不可忽视的关键路径。软件 PRNG 约 875μs,超过单次迭代时间;硬件 PRNG 约 342ns,完全隐藏在阵列计算延迟内。单元面积 <0.2mm²,但去掉它,K=500 的 CEM 在端侧实时运行的可能性直接归零。
8.6 演化路线图与能效约束
能效是最终约束。GPU 做 CEM 约 15-25W,设计良好的专用 ASIC 约 1-3W(10× 提升),神经形态推测 ~0.1W。LLM 时代芯片竞争围绕“谁的内存带宽更大”,JEPA 时代转向“谁能在有限 SRAM 里并行跑最多条规划轨迹、同时功耗足够低”。
九、时间表
预计行业在 2027 年前后开始承认这次范式转移。AMI Labs 的近期计划分两步:头一两年把 JEPA 世界模型用于复杂工业控制——喷气发动机、化工厂、电网、个性化医疗——这些领域方程写不全,但有传感器数据,学一个现象学动力学模型加规划就能产生价值。这是 JEPA 在家用机器人解决之前的工业楔子。第三到五年扩展为智能机器人系统的主要供应商。
竞争对手都在走 VLA 优先路线。AMI Labs 是另一条路:JEPA 加分层规划,不只是原则上更优,而是会在 VLA 路线触顶之前先造出可商业部署的机器人。
标准是,家用机器人第一次被口头告知去清晚餐桌,就能完成——像一个被吩咐收拾餐桌的 10 岁孩子。目前没有任何系统接近这个目标。
过去十年,AI 领域痴迷于“蛋糕上的樱桃”(强化学习),偶然靠 next-token prediction 实现了蛋糕底层的自监督学习,但只在语言这个离散域里。让自监督学习在连续高维信号——视频、传感器流、物理世界——里也成立,在表示空间而非像素空间里预测,用优化来推理,把安全约束融合进优化问题本身。这同时会催生新的硬件迭代和爆发。芯片还会继续高歌猛进。
参考:ETH Zürich "Frontiers of Embodied AI" 演讲、I-JEPA / V-JEPA / V-JEPA 2 / VL-JEPA / LeJEPA / LeWorldModel / HWM 论文。
 发表于 2026-6-18 00:01:23
|
查看: 213|
回复: 0
发表于 2026-6-18 00:01:23
|
查看: 213|
回复: 0
