要训练好一个机器人,离不开一个耐心的“老师”。研究者往往需要亲自反复示范,再将示范动作转化为训练轨迹。这个过程耗时耗力,成本高昂。
对视觉-语言-动作模型(VLA)来说,训练数据量越大、多样性越丰富,模型性能通常就越强。但机器人示教数据的采集长期依赖人工遥控,效率低,数据瓶颈始终存在。
相比之下,人类第一视角视频(Egocentric Video)场景更丰富、采集成本也更低,却无法直接用于机器人训练——它提供的只是带噪声的伪动作,而机器人数据则是高保真轨迹,两者在表示方式与质量上截然不同。
针对这一问题,ACE Robotics 团队及其合作者提出了 ACE-Ego-0,一个将人类第一视角视频、机器人数据与仿真 rollout 统一纳入同一框架的 VLA 预训练方案。

论文链接:https://arxiv.org/pdf/2606.17200
先来看几个官方 demo:
结果显示,ACE-Ego-0 在 RoboCasa GR1 TableTop 和 RoboTwin 2.0 两大仿真基准上均取得最佳表现,并在真实双臂机器人平台上展现出优秀的迁移能力。这也说明,只要妥善处理人类数据中的噪声,大规模人类视频数据就能稳定提升 VLA 在预训练与监督微调阶段的效果。
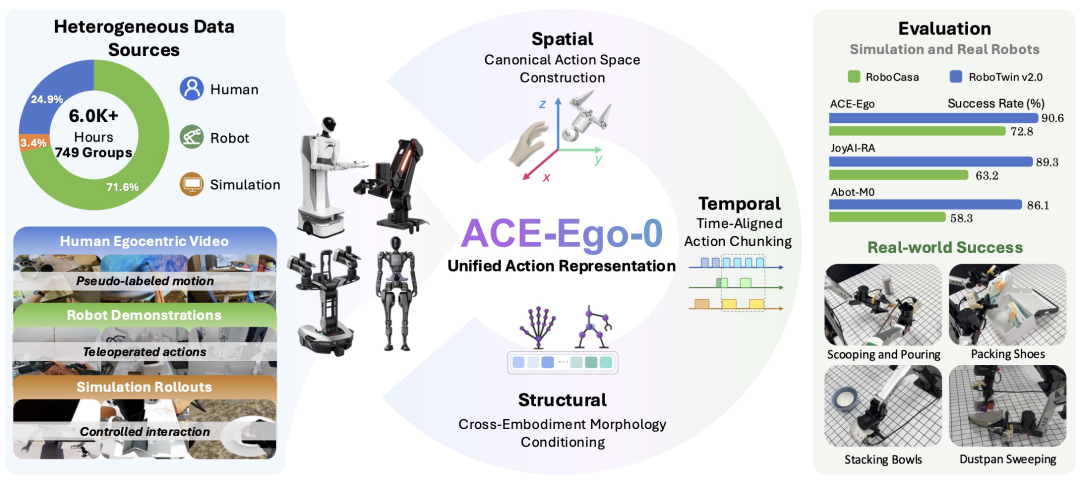
图|ACE-Ego-0 概览
ACE-Ego-0 是如何设计的?
ACE-Ego-0 是一个统一的 VLA 预训练框架。它通过相机空间动作、形态条件化以及时间对齐动作分块,将人类第一视角视频、机器人演示与仿真数据对齐,并引入可靠性感知的人类辅助监督,让那些带噪的伪动作以加权辅助信号的方式参与训练。
在表示层面,ACE-Ego-0 首先把机器人末端轨迹和人类手部重建轨迹统一映射到头部相机坐标系中,使动作与观测共享同一坐标系。人类视频中没有现成的末端执行器,研究团队便以腕部为原点定义了一套对应手部的坐标系,用腕部位移、手部姿态和开合状态来表示动作,再将其转换为与机器人兼容的动作向量。
此外,ACE-Ego-0 还利用基于 URDF 的形态 token 来区分不同机器人的本体结构,同时为不同人类视频数据源分别学习可训练的 embedding,用以刻画数据源之间的固有差异。这些信息仅在动作解码阶段使用,不会进入视觉-语言主干。与此同时,模型按统一物理时长切分动作块,从而对齐不同数据集的时间尺度。
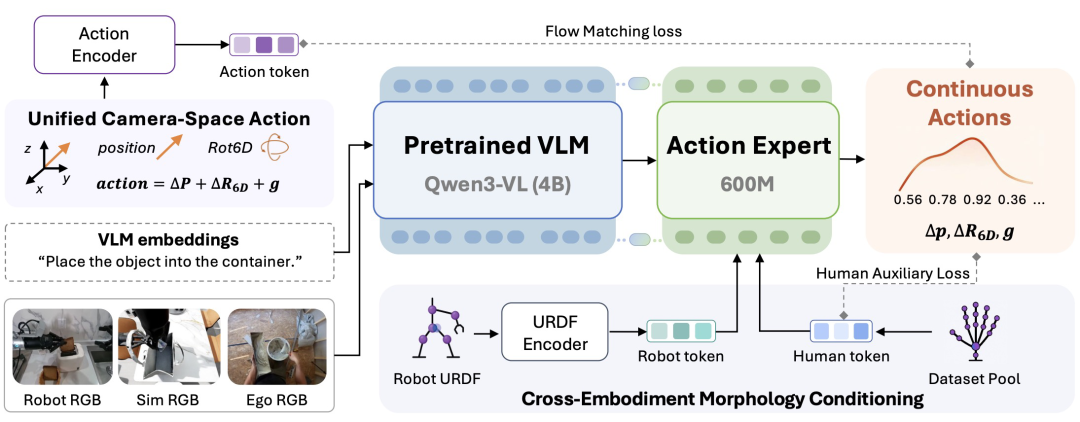
图|ACE-Ego-0 的整体架构
在训练层面,ACE-Ego-0 并不对机器人数据和人类视频等权处理。机器人示教承担主监督角色,人类视频中的伪动作则按照可靠性进行加权,作为辅助监督信号:其中位置信号稳定性较高,权重更大;而旋转和夹爪状态的噪声较多,权重则被压低。
在数据层面,研究团队设计了一条五阶段处理流程,涵盖数据集筛选、视频筛选、三维手部重建、动作参数化以及质量控制,从而将原始第一视角视频转化为可供训练的伪动作标签。最终,他们从 6 个数据源中整理出 1478 小时带伪动作标注的人类视频,与机器人和仿真数据一起,构成了超过 6.0K 小时的混合预训练数据池。
图|原始第一视角视频到相机空间伪动作的转换流程
ACE-Ego-0 的效果怎么样?
整体来看,ACE-Ego-0 在 RoboCasa 和 RoboTwin 2.0 两个仿真基准上均取得领先,并在真实双臂机器人平台上展现出较强的迁移能力。具体而言,它在 RoboCasa GR1 TableTop 上取得了 72.8% 的平均成功率,高于 DIAL 的 70.2%、JoyAI-RA 的 63.2%、ABot-M0 的 58.3% 和 FLARE 的 55.0%。
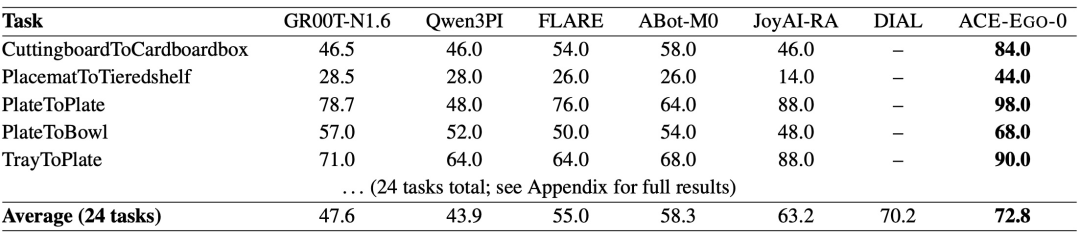
图|RoboCasa GR1 TableTop 基准上的评测结果
在 RoboTwin 2.0 中,其 Easy/Clean 与 Hard/Randomized 设置下的成功率分别达到 91.12% 和 90.62%。

图|RoboTwin 2.0 基准的总体评测结果
在真实双臂机器人评估中,ACE-Ego-0 同样表现突出:在 ARX 平台的 6 个任务上(每任务 30 次评测),其平均成功率达到 78.3%,显著优于同任务数据微调后的 π0.5(71.7%)和 GR00T-N1.7(35.6%),并在 6 个任务中的 5 个任务上保持领先。尤其在双臂协同要求较高的 Scoop Coffee 任务上,它拿到了 86.7% 的成绩,远超 π0.5 的 70.0% 和 GR00T-N1.7 的 36.7%。不过,在流程最长的 Pack Shoes 任务上,所有模型的表现都明显下滑。
这揭示出一个共同的挑战:在长时序操作链中,如何有效控制累积性的轨迹漂移,仍是当前预训练 VLA 架构亟待突破的难点。
消融实验逐一移除了 ACE-Ego-0 的三项关键设计:形态 token、时间对齐动作分块,以及可靠性感知的人类辅助损失。结果显示,三者对最终性能都有贡献。在 RoboCasa 上,移除形态 token 后成功率从 72.8% 降到 70.9%,移除时间对齐动作分块后降到 71.7%,而移除可靠性感知的人类辅助损失后降幅最大,跌至 69.2%。
数据源消融实验则表明:仅用 Qwen 初始化、不做具身预训练时,成功率为 65.4%;加入机器人数据后升至 68.3%;再引入人类视频,性能进一步提升到 72.8%。
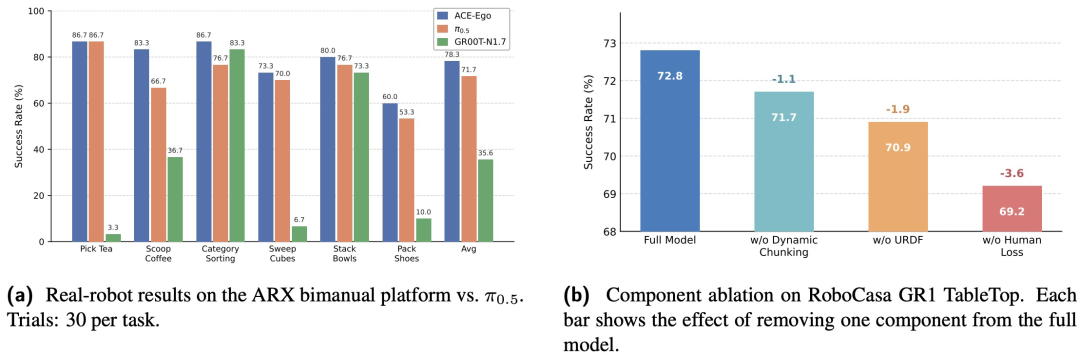
图|ACE-Ego-0 的真实机器人评测结果(a)与消融实验(b)
在数据稀缺场景下,人类视频同样带来显著增益。以 Sweep Cubes 的微调实验为例,仅使用 34 条机器人示教时,成功率只有 10%;加入 419 条任务匹配的人类视频后,成功率跃升至 40%。从工作空间覆盖来看,机器人示教所覆盖的末端执行器工作空间为 0.062 平方米,而人类视频则达到 0.296 平方米,是前者的约 4.8 倍。
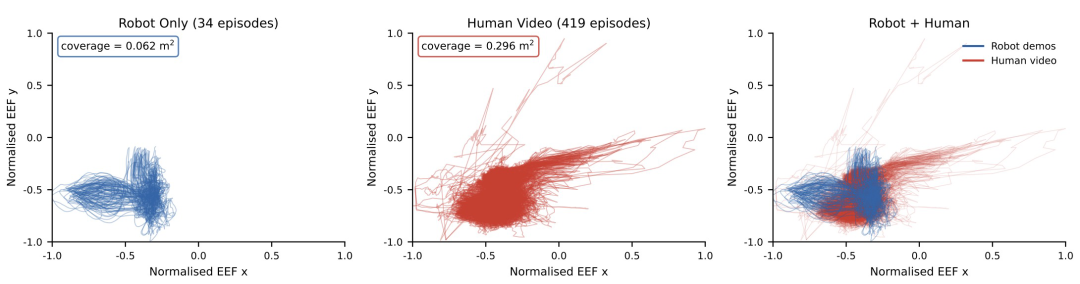
图|Sweep Cubes 微调数据中右臂末端执行器轨迹在水平面上的投影
不足与未来方向
研究团队指出,ACE-Ego-0 当前的评估仍主要集中在桌面操作场景,其通用性尚未在更复杂的设定下得到充分验证。例如,将这套相机空间动作接口拓展到移动操作、全身人形机器人控制,或者可变形物体操作时,是否依然有效,还有待进一步研究。
与此同时,真实机器人实验虽已验证该方法在 ARX 双臂平台上的迁移能力,但长时序任务中的累积漂移问题仍未根本解决——比如在包含合盖动作的 Pack Shoes 任务上,所有评测模型都出现了明显的性能下降。
从数据与感知模态来看,当前超过 6.0K 小时的预训练数据池中,既未纳入灵巧手数据,也不包含力/力矩传感信息。未来仍需继续扩充人类第一视角视频的规模,提升伪动作管线在旋转和精细手指动作上的重建精度,并引入更丰富的模态信息。这些改进有望让可靠性感知训练目标覆盖更多位置维度以外的动作通道,进一步释放人类示教向机器人控制迁移的潜力。
更多技术细节,可参阅原论文。
整理:夏千斯
如需转载或投稿,请在原文评论区留言。
 发表于 2026-6-19 01:08:20
|
查看: 168|
回复: 0
发表于 2026-6-19 01:08:20
|
查看: 168|
回复: 0
