用 Claude Code、Cursor、Copilot 做过稍微复杂一点任务的人,大概都经历过这个时刻——
聊了二三十分钟,助手突然开始“失忆”。它忘了自己改了哪些文件,忘了你让它用 TypeScript 而不是 JavaScript,忘了上一个 bug 修到一半。
模型没变笨,是上下文窗口被塞满了。
AI 编程助手的上下文窗口有一个容量上限(Claude 是 200k tokens)。每次工具调用——读文件、跑命令、抓网页——原始输出都会灌进这个窗口。一个 Playwright 页面快照吃掉 56 KB,拉 20 条 GitHub Issues 吃掉 59 KB,一份访问日志吃掉 45 KB。
30 分钟后,40% 的上下文被工具输出占满。然后 agent 压缩对话腾空间,但压缩过程会丢掉关键信息:正在编辑的文件、进行中的任务、你的偏好和决策。
上下文窗口是 AI 编程助手最稀缺的资源,但大多数优化思路都走偏了——要么让模型“少说点”(牺牲回答质量),要么手动清理(打断工作流)。
如果你也在被这个问题困扰,不妨看看 开源实战 中一个叫 context-mode 的项目是怎么解决的。
四个层面解决上下文问题
context-mode 是一个 MCP(Model Context Protocol)服务器,从四个层面处理上下文浪费问题。
Sandbox 执行:原始数据不进上下文
核心机制很简单:工具输出不直接灌入上下文,而是在隔离的子进程里执行代码,只把 stdout 结果放进对话。
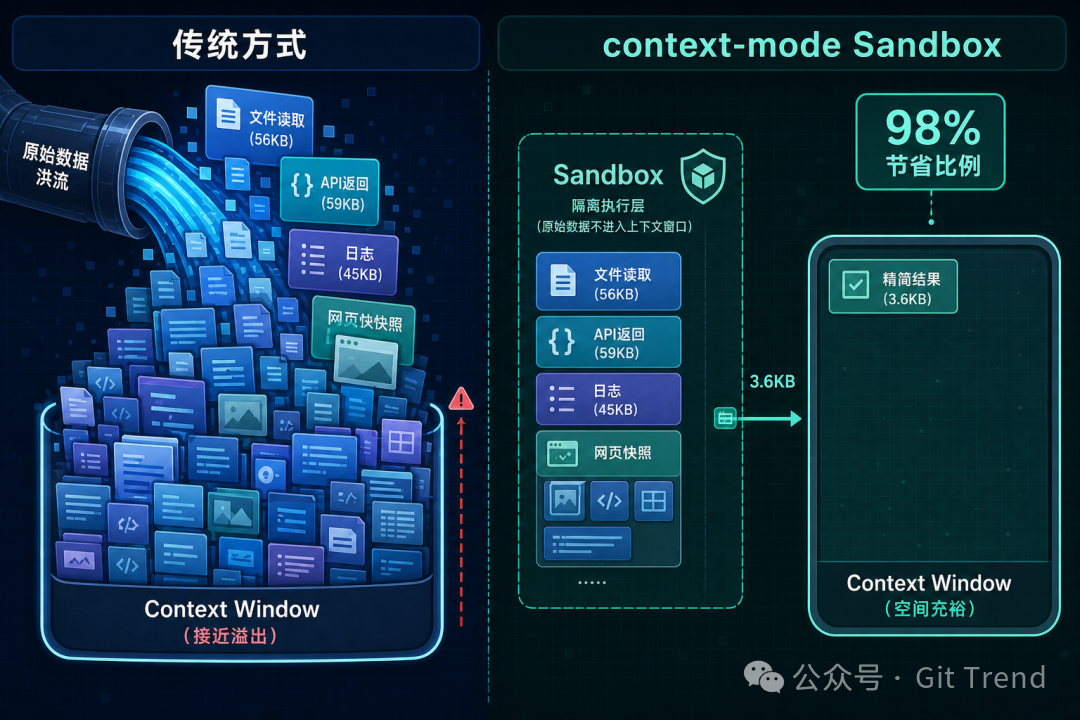
一个典型的例子:你想分析 50 个 TypeScript 文件的行数。常规做法是调用 50 次 Read,700 KB 数据涌入上下文。context-mode 的做法是让 agent 写一段脚本在 sandbox 里跑,只返回行数统计——3.6 KB。
12 种语言 runtime 都支持(JS、TS、Python、Shell、Ruby、Go、Rust、PHP 等)。gh、aws、kubectl 这些需要凭证的 CLI 也能用,凭证透传但不暴露到对话中。
实测数据:315 KB 的原始输出被压缩到 5.4 KB,减少 98%。
Think in Code:让 LLM 写代码而不是读数据
这是一个更根本的范式转变。context-mode 要求 agent 用编程的方式处理数据,而不是把数据搬进上下文让模型“看”。
数文件行数?写个脚本 console.log 结果。抓 20 条 GitHub Issues?写个脚本解析 API 返回。分析日志文件?写个脚本做聚合。
把 LLM 从“数据处理器”变成“代码生成器”。一个脚本替代十次工具调用,节省 100 倍上下文。这种思路上的转变,在 人工智能 领域的实践中越来越被重视。
会话连续性:压缩后不丢状态

四个功能里,这个对日常体验影响最大。
当对话被压缩(compact)后,context-mode 不会像其他方案那样把所有历史数据塞回上下文。它用 SQLite 记录了会话中每一个关键事件——文件编辑、git 操作、任务状态、错误修复、用户决策——然后通过 FTS5 全文搜索按需检索。
压缩前,PreCompact hook 构建一个 ≤2 KB 的优先级快照。压缩后,SessionStart hook 恢复完整工作状态:上次在做什么、哪些任务完成、哪些文件改过、用户做了什么决策。
恢复后的模型能看到:上次在改哪个文件、哪些任务完成了、你做了什么决策(比如“用 TypeScript 不要 JavaScript”)、哪些错误已修复。不需要你重新交代任何背景。
第四点容易被忽略但很重要:context-mode 只管“数据往哪去”,不管“模型怎么说”。它不会强制模型缩短回复,不会改你的代码风格。有研究表明,激进压缩提示词会降低代码和推理的基准测试表现(Moonshot AI 在 kimi-k2.5 上的发现)。关于这类 后端 & 架构 中的设计权衡,官方文档里有更详细的 技术文档 可供参考。
谁能用,怎么装
context-mode 支持 16 个平台,覆盖了主流 AI 编程工具:Claude Code、Cursor、VS Code/JetBrains Copilot、Gemini CLI、Codex CLI、OpenCode、Kiro、Zed、Pi 等。
Claude Code 上安装最简单,两行命令:
/plugin marketplace add mksglu/context-mode
/plugin install context-mode@context-mode
重启后运行 /context-mode:ctx-doctor 检查状态。其他平台通过 npm 全局安装 + MCP 配置接入,README 里有每个平台的详细步骤。
一个影响体验的差异:有 hooks 的平台(Claude Code、Gemini CLI、Copilot 等)能实现约 98% 的路由拦截率——程序级阻断,工具调用在执行前就被截住。没有 hooks 的平台(Zed、Antigravity)靠规则文件引导模型,大约 60% 合规率,偶尔会有工具调用绕过去。
压缩之外:检索能力
除了 sandbox 执行的压缩,context-mode 还有一套基于 SQLite FTS5 的全文检索系统。ctx_index 把文档按标题分块索引,代码块完整保留;ctx_search 用 BM25 + Porter 词干 + RRF 融合检索。ctx_fetch_and_index 抓取网页后自动转 markdown 并索引,带 24 小时缓存。
两种模式配合使用:需要聚合信息时用 sandbox 压缩统计,需要精确代码片段时用 FTS5 检索返回原文。
边界和代价
几个值得注意的点:
ELv2 许可证。不是 MIT。允许自由使用、修改、分发,但不能作为托管/管理服务转售。对于个人开发者和公司内部使用没有任何限制,但想把它包成 SaaS 卖钱不行。
不支持 Node.js < 22.5(Linux 上)。原因是要用 node:sqlite 内置模块替代 better-sqlite3 原生插件来避免 SIGSEGV 崩溃。
部分平台的 session continuity 不完整。Cursor 的 SessionStart 被 validator 拒绝,Kiro 的 agentSpawn 还没实现,Zed 和 Antigravity 完全没有 hook 支持。在这些平台上,context-mode 依然能做 sandbox 执行和知识库检索,但压缩后的状态恢复要打折扣。
全部本地运行,零 telemetry,零云端同步,无账户要求。SQLite 数据库存在本地,用完即删——这是刻意的设计选择,不是没来得及做的功能。
什么时候值得装?
如果你经常遇到以下情况之一,context-mode 值得一试:
- 一次会话超过 30 分钟,agent 开始丢上下文
- 需要分析大量文件、日志、API 返回
- 用
--continue 恢复会话后要重新交代背景
- 在多个 AI 编程工具之间切换
安装成本很低(Claude Code 两行命令),不需要任何配置就能工作。运行 ctx stats 可以看到每次工具调用节省了多少上下文。
如果你只是偶尔让 AI 写几个函数、改几行代码,上下文窗口远远够用,那 context-mode 的价值就不大。
但如果你依赖 AI 编程助手做深度工作——研究代码库、调试复杂问题、多步骤重构——上下文窗口就是最大的结构性瓶颈。context-mode 给了一个目前看来最完整的解法。
项目卡片
- 项目:context-mode[1]
- 状态:v1.0.162 / 16.4k stars / 270k+ 用户 / Hacker News #1
- 一句话判断:目前最完整的 AI 编程助手 context window 优化方案,从 sandbox 执行到会话连续性全覆盖,16 个平台一把梭
引用链接
[1] context-mode: https://github.com/mksglu/context-mode
 发表于 5 小时前
|
查看: 6|
回复: 0
发表于 5 小时前
|
查看: 6|
回复: 0
