如果一个智能体不仅能够改进自己的任务策略,还能够改进“如何改进策略”的方法,会发生什么?
受哥德尔机(Gödel Machine)思想启发,北京大学、加州大学和亚利桑那大学的研究团队联合提出 哥德尔智能体(Gödel Agent) 框架。它使多智能体系统能够在运行过程中读取、修改并重构自身的行为逻辑,实现递归式自我改进。实验结果表明,哥德尔智能体不仅在数学推理、科学问答等任务上显著优于传统智能体和元学习方法,更能够在持续试错过程中自主演化出回溯、启发式搜索等复杂策略。这项研究为构建能够持续进化的 AI 系统 提供了一种全新的设计范式。
关键词:递归,自指,智能体,自进化

论文标题:Gödel Agent: A Self-Referential Agent Framework for Recursive Self-Improvement
论文链接:https://arxiv.org/abs/2410.04444
发表日期:2024年10月6日
发表期刊:arXiv
哥德尔智能体是如何工作的
2025年提出的哥德尔智能体(Gödel Agent),其思想源头可以追溯到二十多年前的一项理论构想。
2003年,LSTM的发明者Jürgen Schmidhuber发表了一篇题为《Gödel Machines: Fully Self-referential Optimal Universal Self-improvers》(哥德尔机:完全自指的最优通用自我改进者)的论文。在这篇论文中,他提出了一种极具前瞻性的理论模型:哥德尔机(Gödel Machine)。
哥德尔机的核心思想是“自指”(self-reference)。与传统程序只能按照预先设定的规则运行不同,哥德尔机能够将自身视为研究对象,不仅可以分析自己的运行逻辑,还能够修改自己的代码。理论上,它可以重写系统中的任何部分,包括感知模块、决策策略、学习算法,甚至负责管理代码修改过程的元规则(meta-rules),从而持续提升自身性能。
然而,这种自我修改并不是随意进行的。哥德尔机要求,在执行任何修改之前,系统必须首先“证明”(或高概率确信)这种重写能够带来全局效用的提升。这一设计使哥德尔机具备了极强的理论吸引力:与传统的元学习不同,后者虽然能够优化策略,但优化规则本身仍然由人类预先设定;而哥德尔机进一步允许对修改的策略进行修改。这相当于把“进化法则”本身也交给了系统持续改进。
但问题在于,这种严格的证明机制几乎无法在现实中实现。为了证明一次代码修改一定有益,系统往往需要分析修改后程序未来所有可能的运行结果,而这类问题很容易演化为极其复杂的程序验证任务。对于一般情况,并不存在能够在有限时间内完成此类证明的通用方法。因此,尽管理论上极具吸引力,哥德尔机长期停留在概念层面,难以真正落地。
受到哥德尔机的启发,研究者开始探索一种更具工程可行性的方案。哥德尔智能体让多智能体系统不再依赖人类预设的固定流程或元学习算法,而是通过大模型在运行时动态重写决定执行过程的逻辑代码(图1),实现了从“策略”到“学习算法”的双重递归进化。
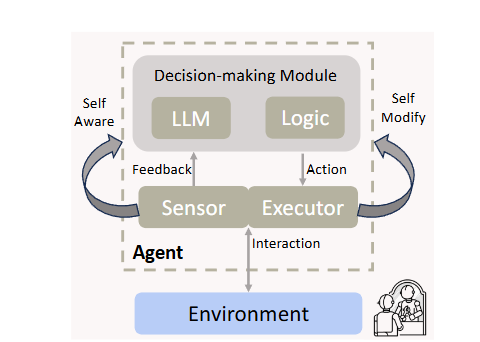
图1:哥德尔智能体的模块化演示。与传统多智能体相比,该框架的传感器和执行器能够读取和写入其自身的代码。
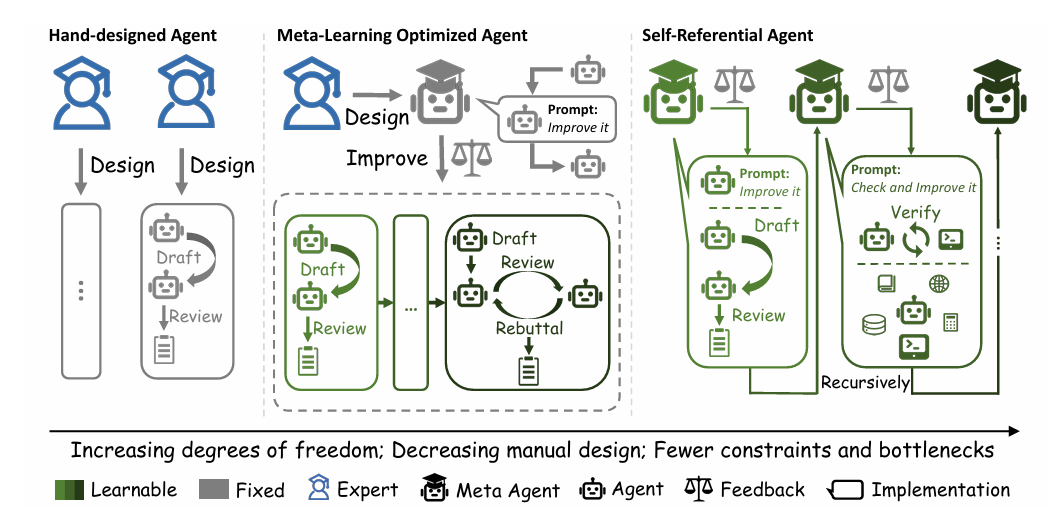
图2:手动设计的智能体,元学习智能体和哥德尔智能体的对比
目前最主流的智能体框架仍然属于人工设计范式(图2左)。无论是ReAct、Tree of Thoughts,还是Self-Refine,其推理流程、搜索策略和反思机制都由研究者提前设计完成。智能体虽然能够完成复杂任务,但其运行逻辑本质上仍被限制在人类预设的框架之内。
为了打破手工设计的局限,研究者们提出了元学习智能体(图2中)。这类系统允许智能体通过环境反馈,利用自然语言梯度或进化算法来优化自己的提示词或模块组合。但在这类系统中,人类预设了变异、交叉及梯度更新的规则,智能体只是在狭窄的人类先验空间内进行局部搜索。
哥德尔智能体试图更进一步。它不仅能够修改任务策略本身,还能够修改负责策略更新的规则,从而实现真正意义上的“自指”(self-reference)(图2右图)。这一过程主要由四个步骤组成:
- self_inspect(内省):智能体调用代码读取模块,获取包括它的任务执行逻辑,以及它当前正在使用的“自我修改算法”的源代码。这相当于人类意识中的“元认知”(Metacognition),即思考“我正在如何思考”。
- interact(交互):智能体使用当前的策略与环境交互,并通过效用函数获取反馈。这相当于进化论中的适应度评估。
- self_update(自更新):这是最核心的一步(图4)。智能体利用大模型的生成能力,直接生成新的 Python 代码(或Prompt逻辑),并在运行时替换掉旧的代码。这一步利用 Python 的动态解析,在运行时内存中直接替换旧的函数或类方法,将新生成的代码无缝绑定到当前运行的智能体实例上,无需重启进程。这在生物学上,类似于不改变DNA序列,但通过表观遗传学机制瞬间改变了基因的表达方式,让智能体在不停止思考(进程不中断)的情况下完成自我更新。
- continue_improve(递归进化):如果当前没有更好的修改方案,Agent 会递归地调用自身的决策函数,开启新一轮的“内省-交互-更新”循环。
在传统的元学习中,策略更新过程可表示为:
$\pi_{t+1}=I(\pi_{t}, r_{t})$
其中,$\pi_{t}$ 表示当前策略,$r_{t}$ 表示环境反馈,而更新规则 $I$ 是固定不变的。这意味着系统虽然能够优化策略,但优化策略的方法本身无法改变。
在哥德尔智能体中,更新过程被定义为:
$\pi_{t+1}, I_{t+1} = I_{t}(\pi_{t}, I_{t}, r_{t}, g)$
其中:$\pi_{t}$ 是当前任务策略,$I_{t}$ 是当前的更新规则(元算法),$r_{t}$ 是环境反馈,$g$ 是优化目标。
与传统元学习最大的不同在于,更新规则 $I_{t}$ 本身也成为优化对象。每一次迭代不仅会产生新的任务策略 $\pi_{t+1}$,还可能产生新的更新规则 $I_{t+1}$。换句话说,系统不仅在学习如何完成任务,也在学习如何学习。
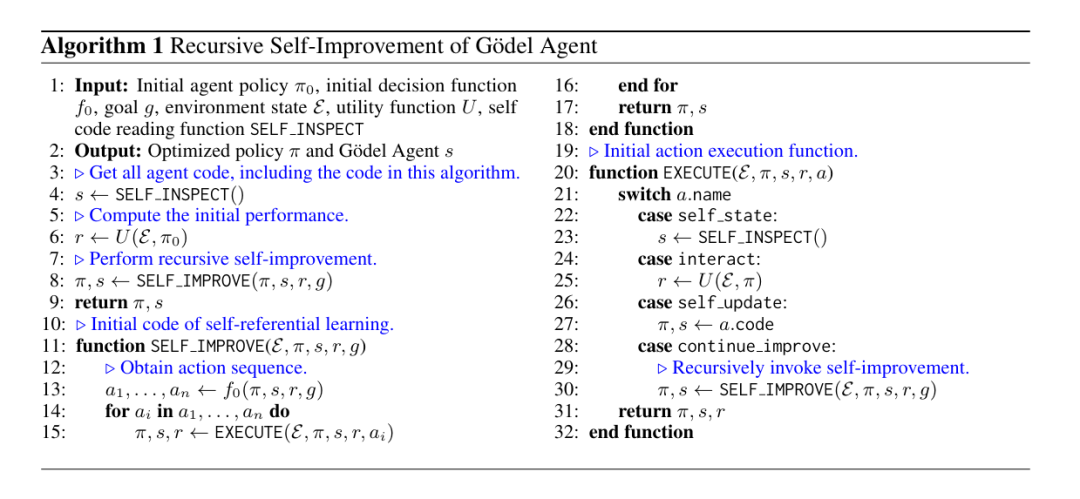
图3:哥德尔智能体的伪代码
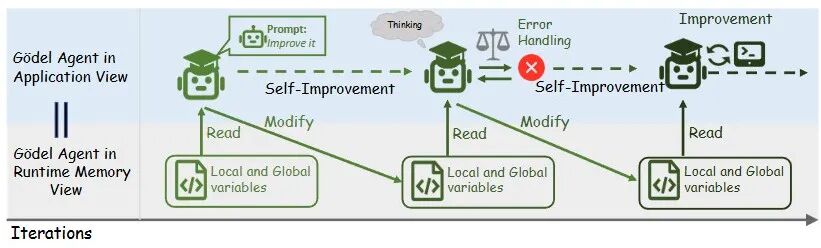
图4:哥德尔智能体是如何实现自我改进的
对于最关键的递归自指机制,论文指出其实现方式并不唯一。本研究采用了一种工程上较为直接的方案:将智能体自身的规划与执行逻辑作为可读取、可修改的对象,并利用大语言模型在运行过程中动态重写这些逻辑。
具体而言,智能体首先读取当前的代码和运行状态,并结合任务反馈判断现有策略是否存在改进空间。如果发现当前逻辑无法有效解决问题,它会调用大语言模型生成新的代码或新的推理流程,并用这些新逻辑替换原有实现。在技术层面,研究团队利用了 Python 的动态执行机制,使新生成的代码能够直接加载到正在运行的系统中,而无需重新启动整个智能体。这样一来,智能体便能够在执行任务的同时修改自身的行为逻辑,实现边运行、边优化的自我更新过程。
这种设计使哥德尔智能体不再局限于固定的工作流,而能够根据环境反馈持续调整自身结构。随着任务和环境的变化,它可以不断添加、替换或删除功能模块,逐步演化出新的解决策略,从而实现递归式的自我改进。
不仅是性能提升,还意味着发现新策略
为了验证哥德尔智能体的有效性,研究团队在多个基准测试上对其进行了评估,包括阅读理解(DROP)、多语言数学推理(MGSM)、多任务理解(MMLU)以及研究生级别的科学问答(GPQA)。研究者对比了手工设计的经典方法(如CoT, Self-Refine, LLM-Debate)和基于元学习的设计方法,以及两种哥德尔智能体的变体:
- Gödel-constrained(约束版):仅允许更新任务策略 π,不允许更新元规则 I(即退化为传统的元学习优化)。
- Gödel-free(无约束版):允许同时更新 π 和 I,实现完全的递归自我改进。
实验结果表明,允许修改元规则的 Gödel-free 表现明显优于其它方法(表1)。在MGSM任务上,CoT的准确率为 28.0%,元学习智能体为53.4%,而 Gödel-free 达到了 90.6%。在GPQA上,元学习智能体的准确率为 34.6%,而 Gödel-free 达到了 55.7%。
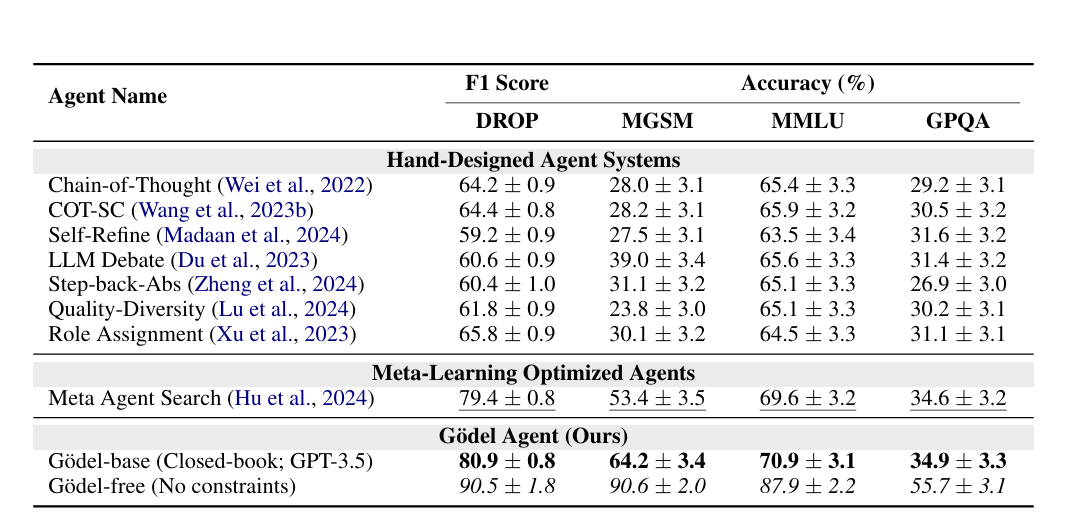
表1:不同类型的多智能体在基准测试上的表现对比
除了最终成绩,研究团队还统计了哥德尔智能体在自我改进过程中执行各类操作的次数(图4)。结果发现,面对不同复杂度的任务,哥德尔智能体需要经历的“突变-筛选”次数截然不同。动作数量的差异,反映了不同任务适应度景观的崎岖程度。众多的自我修改步骤,也说明了在各项任务上,哥德尔智能体的表现来自其自我改进的能力。
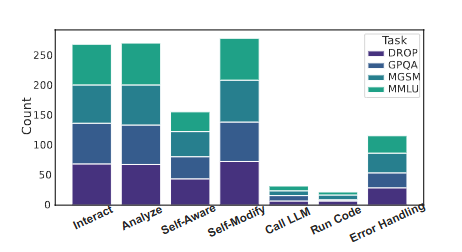
图4:不同类型任务智能体进行上述4项操作的数目
为了分析哪些能力对递归改进最为重要,研究团队进一步进行了消融实验(表2)。结果显示,移除反思(Reflection)和错误处理(Error Handling)模块后,系统性能下降最明显。其中,反思机制负责分析当前策略存在的问题,先思考再处理让智能体具备了规划能力;而错误处理机制则允许智能体在代码生成失败时发现错误、回退修改并重新尝试。由于大语言模型生成代码时不可避免会产生错误,这种试错与纠错能力成为持续自我改进的重要基础。
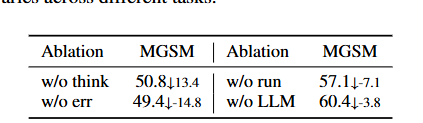
表2:消融分析,在原始的哥德尔智能体上去除对应的模块考察其性能改变
不过,相比基准测试分数,更值得关注的是智能体在24点任务中的行为演化过程(图5A)。在实验初期,哥德尔智能体生成的新代码经常导致性能下降甚至运行错误,因此系统需要频繁回退到之前的版本。然而随着迭代深入,哥德尔智能体自发地编写代码维护了一个“候选解队列”,实现了“回溯”(Backtracking)逻辑,并自主设计了“启发式评估函数”来剪枝。值得注意的是,这些机制并非研究者预先设计,而是在持续的自我修改过程中逐渐出现的。哥德尔智能体自发演化出了类似于“蒙特卡洛树搜索(MCTS)”和“思维树(ToT)”的复杂算法机制。
图5B对比了与其它策略的多智能体系统的性能差异。结果表明,如果智能体的初始策略很强,那么优化过程的收敛速度会更快,优化空间也会更小。相反,如果初始策略较弱,则优化过程收敛得更慢,所需的改进幅度也会更大,智能体需要做出更多的调整。不过,即便在这种情况下,哥德尔智能体的表现仍然无法超越使用Tree of Thought这一元学习方法所得到的结果(图5B)。鉴于当前大语言模型的局限性,哥德尔智能体要超越现有算法水平进行创新是非常困难的。预计随着大语言模型能力的提升,未来将会出现更多创新的自我优化策略。
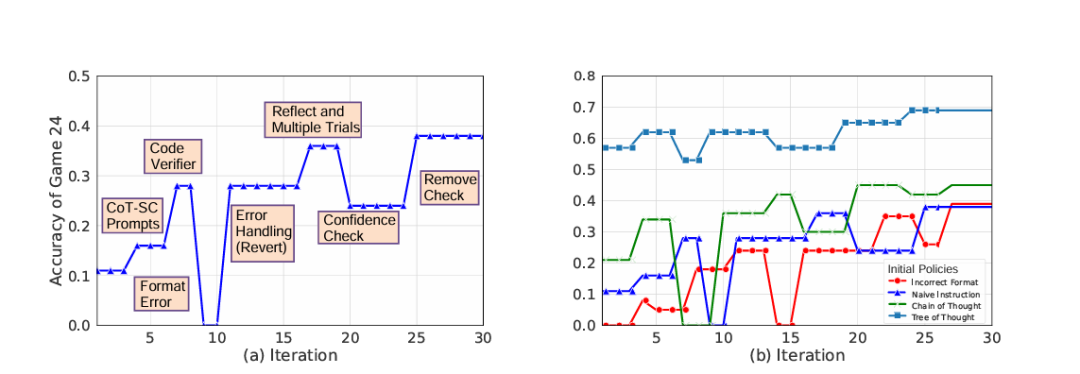
图5:哥德尔智能体求解24点的过程和准确性
使用哥德尔智能体框架的尝试与局限
过去十余年,深度学习的本质是在参数空间中寻找最优解。无论模型多大,其网络架构(Transformer)、损失函数(Cross-Entropy)、优化器(Adam)都是人类锁死的。哥德尔智能体标志着AI开始转向“设计空间”。它不再调整权重,而是修改“调整权重的规则”。通过将更新规则本身纳入可修改范围,它打破了传统元学习智能体受限于人类预设搜索算法的瓶颈。它不再受限于任何固定的元学习算法,代表多智能体系统从被设计的机器向具备自组织能力的复杂适应系统(CAS)的范式跃迁。
哥德尔智能体框架实现了任务策略和元学习算法的同步演化,使多智能体能够探索更广阔的架构设计空间。该研究证明了哥德尔智能体能够通过自指进行递归自我改进,大幅提升复杂推理任务的性能,为突破现有多智能体设计的性能天花板提供了一种全新的范式。而当AI掌握了自我修改的能力,传统基于预设规则的对齐将彻底失效。我们必须学会在复杂适应系统的层面,以进化的视角去理解和约束AI。
哥德尔智能体的研究发表于2025年,2026年的arXiv研究“Polaris: A Gödel Agent Framework for Small Language Models through Experience-Abstracted Policy Repair”进一步改进了对应框架,增加了经验抽象(Experience Abstraction)与最小补丁修复(Minimal Code Patch Repair),在7B的小模型上实现了多项基准测试上超过现有的多智能体模型,证明了哥德尔智能体的框架也适用于小参数的语言模型。
类似的研究,还包括2026年的arXiv论文“Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents”以及“Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine”,这些系统都声称能够自动提升其编码能力,显著优于那些没有自我改进或缺乏开放式探索能力的基线算法。
然而,相比Jürgen Schmidhuber提出的哥德尔机,哥德尔智能体的问题在于其无法证明其修改是有效的,只是通过实证(这次跑出的准确率是否提升)来决定是否保留前一次迭代的改变。这种用“环境适应度”代替“先验全局效用”,本质上是将“理性主义的先验证明”降格成了“经验主义的进化选择”。上述与哥德尔机的差异,虽然避免了哥德尔机这一理论构想因难以证明自修改有益而难以落地的缺陷,但也意味着哥德尔智能体在崎岖的适应度景观上,会面临局部最优,难以通过试错找到最优解。此外,哥德尔智能体的自指改进选项来自经由人类经验训练出来的大模型,这会限制它去探索人类未曾设想的解空间。这或许正是云栈社区的技术爱好者们未来可以深入探讨和突破的方向。
 发表于 4 小时前
|
查看: 3|
回复: 0
发表于 4 小时前
|
查看: 3|
回复: 0
