每次半导体行情走强之后,市场都会重新问几个问题:
如果我买 SOXX,我到底买到的是什么?这些持仓是不是已经被机构高度拥挤?如果我已经持有 NVDA,再买 SOXX 会不会产生重复暴露?
单独看一个数据并不难。SOXX 的价格可以查,ETF 持仓可以查,NVDA、AMD、AVGO 这些成分股也都可以查。
真正麻烦的是:这些数据放在一起,究竟能不能讲出一个相对完整的 ETF 暴露图景。
比如,SOXX 是不是平均买入整个半导体行业?前十大持仓到底占了多少?哪些成分股同时被大量 13F 机构持有?如果已经持有 NVDA,再买 SOXX,组合里会不会继续增加 NVDA 暴露?过去 90 天这只 ETF 到底涨了多少?
这就是 LLMQuant Data 旗下 Skills 中 sector-smart-money-scan 想解决的问题。
它不是让 Claude 或 GPT-Codex 临场写一段半导体行情评论,而是通过 llmquant-data MCP 调用结构化数据,把 ETF holdings、13F holder count、aggregate 13F value 和 historical prices 放在同一个 dashboard 里,生成一页可以阅读复核,也能继续追问的 Sector Smart Money Scan。

Playground 使用体验
除了在本地 Claude Code / GPT Codex 中接入 MCP,我们也建议读者先到 LLMQuant Data 官网体验 Playground。
https://llmquantdata.com/agent
官网首页提供了一个可以直接试用的 Agent Playground。
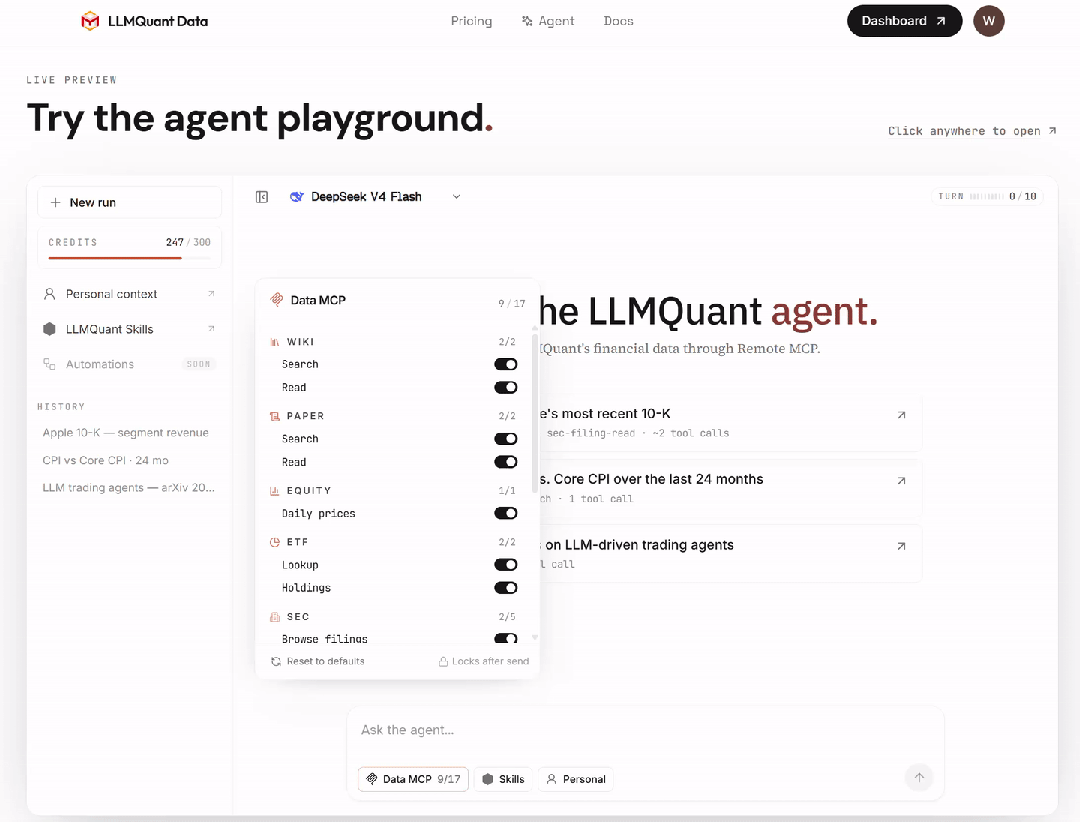
它更像一个轻量工作台:左侧可以看到历史记录、Personal Context、LLMQuant Skills;输入框下方可以选择 Data MCP、Skills 等能力;中间则是对话区,用户可以直接输入自然语言问题,让 Agent 调用对应的数据工具。
对第一次接触 LLMQuant Data 的用户来说,Playground 的好处是门槛更低:不需要先配置本地环境,也可以先感受 Data MCP 和金融 Skill 的调用方式。
比如可以直接尝试:
用 sector-smart-money-scan 扫描 SOXX:
看前十大持仓、13F 机构拥挤度、NVDA 重复暴露和过去 90 天表现。
也可以问得更像真实投研问题:
半导体最近很热。帮我看一下 SOXX 的真实持仓、机构拥挤度,
以及如果我已经持有 NVDA,再买 SOXX 会不会产生重复暴露。
如果你希望更深入地接入自己的 Claude Code / GPT Codex 工作流,再继续使用下文的本地 MCP 配置方式。
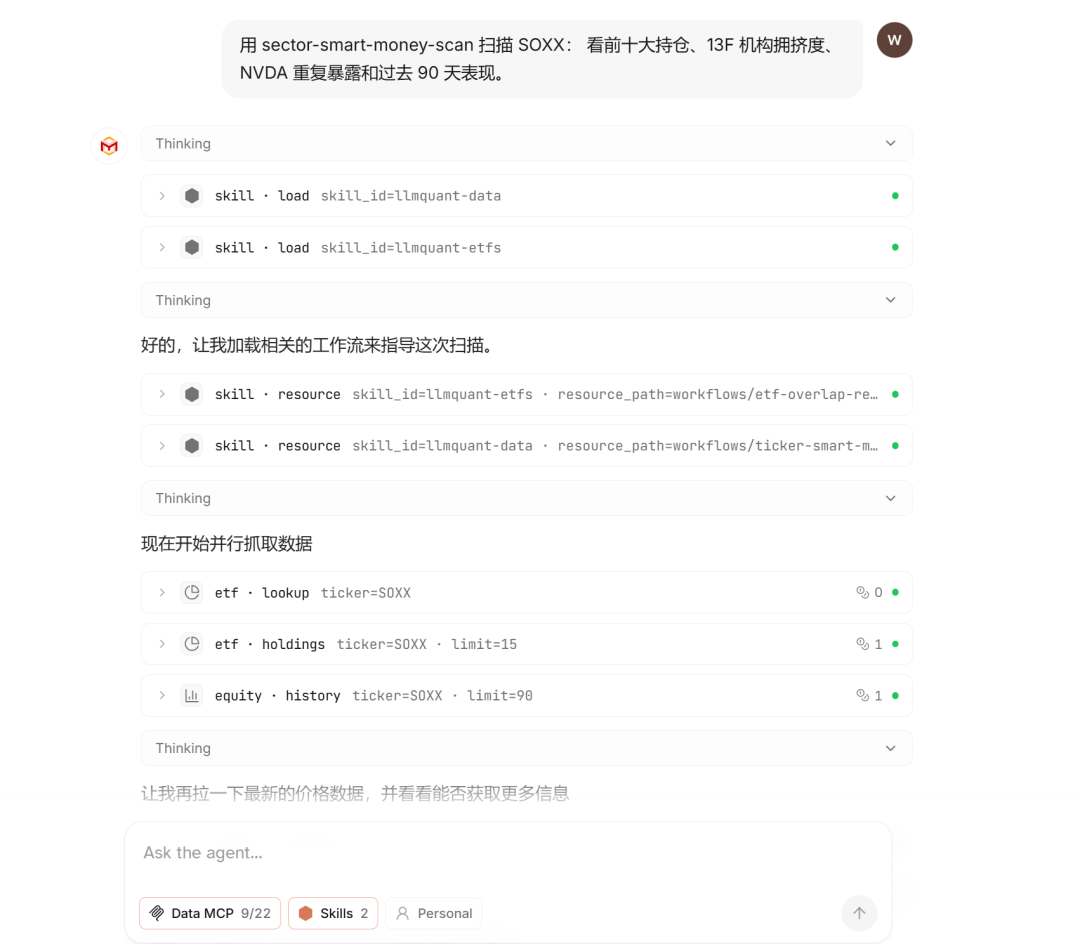
01|先看结果:一句话生成一页 Sector Smart Money Scan
用户可以直接问:
用 sector-smart-money-scan 扫描 SOXX:
看前十大持仓、13F 机构拥挤度、NVDA 重复暴露和过去 90 天表现。
系统返回的不是一段泛泛的半导体行业评论,而是一页可以直接阅读的 Sector Smart Money Scan。
Sector Smart Money Scan
输入:
- sector_etf: SOXX
- holdings_source: SEC N-PORT regulatory snapshot
- holdings_date: 2025-12-31
- smart_money_metric: 13F Holder Count / Aggregate 13F Value
- price_window: 2026-03-23 至 2026-06-17
- duplicate_exposure_ticker: NVDA
输出:
1. One-Line Takeaway
2. Sector Snapshot
3. Holdings Concentration
4. Constituent x Smart-Money Matrix
5. Duplicate Exposure Check
6. 90-Day Price Window
7. Data Quality Notes
8. Risk Disclosure
换句话说,它回答的不是:
半导体是不是还会涨?
而是:
如果我通过 SOXX 获得半导体暴露,我实际拿到的是哪些公司、哪些机构拥挤持仓,以及多少重复暴露?
02|一张图看懂:从 SOXX 到 Sector Smart Money Scan
如果手工做,这个流程并不复杂,但非常琐碎:
- 先确认 SOXX 的 ETF 持仓和日期;
- 读取前十大持仓和权重;
- 对每个成分股逐个查询 13F holder count;
- 汇总 aggregate 13F value 和 top holders;
- 拉取 SOXX 过去 90 天价格;
- 计算起始价格、结束价格和区间收益率;
- 最后把所有信息整理成一页可读的矩阵。
对 ETF 研究员和内容创作者来说,这不是难题,但很容易变成重复劳动。
所以这个 Skill 的目标很直接:
把原本需要查 ETF 持仓、查机构覆盖、拉价格、再写解释的流程,压缩成一次对话。
03|输入是什么?
这个 Skill 的默认输入非常明确。
| 参数 |
默认值 / 示例 |
含义 |
sector_etf |
SOXX |
目标行业 ETF |
holdings_source |
SEC N-PORT regulatory snapshot |
ETF 持仓来源 |
holdings_date |
2025-12-31 |
本次 ETF 持仓日期 |
top_holdings_limit |
10 |
默认查看前十大持仓 |
smart_money_metric |
13F Holder Count / Aggregate 13F Value |
机构覆盖与持仓规模 |
price_window |
2026-03-23 至 2026-06-17 |
90 天价格观察窗口 |
duplicate_exposure_ticker |
NVDA |
可选重复暴露检查标的 |
这里最重要的是默认组合:SOXX + ETF holdings + 13F holders + 90-day historical prices。
SOXX 代表半导体行业 ETF 入口。
ETF holdings 代表真实组合。
13F holder count 代表机构覆盖广度。
Historical prices 代表近期市场表现。
这几个数据放在一起,不是为了给出交易信号,而是为了构成一个简洁的 sector smart money radar。
04|输出表长什么样?
Sector Snapshot
| Field |
Value |
| ETF |
SOXX |
| Fund Name |
iShares Semiconductor ETF |
| Holdings Source |
SEC N-PORT regulatory snapshot |
| Holdings Date |
2025-12-31 |
| AUM |
约 $17.52B |
| Top 10 Concentration |
56.3% |
| 90-Day Return |
+78.2% |
这张表里最重要的不是 ETF 名字,而是三个口径:
因为 ETF 持仓来自监管快照,不等于实时每日组合。
如果不先把这个口径说清楚,后面的机构拥挤度和重复暴露检查都容易被误读。
Holdings Concentration
SOXX 前十大持仓合计占比达到 56.3%。
这意味着,它不是一个非常分散的行业篮子。
它更像是一组半导体核心资产的集中组合。
如果前十大已经占到 56.3%,那么理解 NVDA、AMD、MU、AVGO、AMAT、NXPI、LRCX、KLAC、TXN、ADI,基本就是理解 SOXX 核心暴露的第一步。
Constituent x Smart-Money Matrix
| Holding |
ETF Weight |
13F Holder Count |
Aggregate 13F Value |
Top Holders |
Quick Read |
| NVDA |
8.3% |
779 |
$2.48T |
Vanguard, State Street, BlackRock |
Core crowded exposure |
| AMD |
7.7% |
668 |
$196.30B |
Vanguard, State Street, BlackRock |
Core crowded exposure |
| MU |
7.0% |
644 |
$211.33B |
Vanguard, Capital World, State Street |
Core crowded exposure |
| AVGO |
6.7% |
747 |
$980.41B |
Vanguard, State Street, BlackRock |
Core crowded exposure |
| AMAT |
5.9% |
645 |
$126.69B |
Vanguard, State Street, Capital Research |
Core crowded exposure |
| NXPI |
4.4% |
469 |
$39.91B |
FMR, JPMorgan, Vanguard |
Crowded but less than peers |
| LRCX |
4.3% |
624 |
$137.72B |
Vanguard, State Street, BlackRock |
Broadly owned equipment name |
| KLAC |
4.1% |
584 |
$114.98B |
Vanguard, State Street, Capital Intl. |
Broadly owned equipment name |
| TXN |
4.0% |
642 |
$106.55B |
Vanguard, State Street, BlackRock |
Crowded analog exposure |
| ADI |
4.0% |
590 |
$89.69B |
Vanguard, State Street, BlackRock |
Broadly owned analog exposure |
这张表不是为了说哪个成分股更好。
它真正要回答的是:
SOXX 的高权重成分股里,哪些同时也是机构覆盖非常广的名字?
05|为什么不是直接让 ChatGPT 搜一下?
这是这个 demo 最关键的地方。
如果只是问 ChatGPT:
半导体最近很热,SOXX 值得关注吗?
模型可能会给出一段看起来合理的行业解释。
但问题是,这段解释里的 ETF 持仓日期、前十大权重、13F holder count、aggregate 13F value、SOXX 90 天价格窗口,未必来自同一套可复核的数据链路。
接入 llmquant-data MCP 之后,Agent 会先调用一组真实数据工具。
默认链路大概是:
etf_holdings(SOXX)
sec_13f_list_ticker_holders(NVDA)
sec_13f_list_ticker_holders(AMD)
sec_13f_list_ticker_holders(MU)
sec_13f_list_ticker_holders(AVGO)
sec_13f_list_ticker_holders(AMAT)
...
equity_historical_prices(SOXX, 90 天)
所以,这个 demo 的重点不是“AI 会不会讲半导体”。
而是:
AI 能不能基于可调用、可复核的 ETF 持仓、13F 机构持仓和价格数据,稳定生成一页 sector smart money scan。
这也是为什么我们会把它做成 Skill,而不是只写一个 prompt 模板。
06|图解 SOXX 的核心暴露
前五大持仓结构
SOXX 的前五大持仓分别是 NVDA、AMD、MU、AVGO、AMAT,合计占比 35.6%。
8.3% + 7.7% + 7.0% + 6.7% + 5.9% = 35.6%
这说明 SOXX 的核心收益和风险暴露,已经明显集中在少数几家半导体龙头上。
它不是只押注 NVDA 一家公司。
但它也不是平均分散到整个半导体产业链。
更准确地说,它是一只以少数核心半导体龙头为主要解释变量的 ETF。
Crowded Core Exposure 拆解
如果把 NVDA、AMD、MU、AVGO、AMAT 视为 SOXX 中最典型的 crowded core exposure,那么这部分合计已经占到 35.6%。
其他前十大持仓占 20.7%。
其余持仓占 43.7%。
这张图想表达的不是“这五家公司一定更好”。
而是提醒用户:
SOXX 的核心暴露,并不是分散的行业平均值,而是集中在少数高权重、同时被大量机构持有的半导体龙头上。
13F Holder Count 怎么读?
| Holding |
13F Holder Count |
Holder Bar |
| NVDA |
779 |
███████████████████████████████ |
| AVGO |
747 |
██████████████████████████████ |
| AMD |
668 |
███████████████████████████ |
| AMAT |
645 |
██████████████████████████ |
| MU |
644 |
██████████████████████████ |
| TXN |
642 |
██████████████████████████ |
| LRCX |
624 |
█████████████████████████ |
| ADI |
590 |
████████████████████████ |
| KLAC |
584 |
███████████████████████ |
| NXPI |
469 |
███████████████████ |
可以这样理解:
- NVDA 和 AVGO 是机构覆盖最广的两个名字;
- AMD、AMAT、MU、TXN 也都在 640 家以上;
- NXPI 在前十大里权重不低,但 holder count 相对低于其他核心名字。
因此,一页好的 Sector Smart Money Scan 不能只说“SOXX 是半导体 ETF”。
它应该告诉你:哪里有集中度,哪里有拥挤度,哪里需要做重复暴露检查。
07|一个完整 Sector Smart Money Scan 可以怎么读?
可以分三层看。
第一层:先看 ETF 本身
先看 SOXX 的持仓日期、AUM、前十大权重和前五大权重。
这一步回答的是:
这只 ETF 到底是不是分散?
第二层:再看机构拥挤度
再看每个前十大持仓的 13F holder count、aggregate 13F value 和 top holders。
这一步回答的是:
这些持仓是不是已经是机构组合里的常见暴露?
第三层:最后看价格背景和重复暴露
再看 SOXX 过去 90 天表现,以及如果已经持有 NVDA,再买 SOXX 会增加多少间接暴露。
这一步回答的是:
这段行情有多强?我已有持仓会不会和 SOXX 发生重叠?
这一步才是整份 brief 最有价值的部分。
它不是复述 ETF 名称,而是把数据翻译成组合语言:concentration、crowding、duplicate exposure、historical price context。
08|Brief 最终应该包含哪些模块?
一份好的 Sector Smart Money Scan,应该至少包含下面几个模块。
| 模块 |
解决的问题 |
| One-Line Takeaway |
一句话判断哪些持仓又重又拥挤 |
| Sector Snapshot |
ETF 日期、AUM、前十大权重、90 天表现 |
| Concentration View |
前十大集中度、前五大集中度 |
| Constituent x Smart-Money Matrix |
持仓权重、13F holder count、机构名称 |
| Duplicate Exposure Check |
已持有 NVDA 时的重复暴露提醒 |
| 90-Day Price Window |
起始价格、结束价格、区间收益率 |
| Data Quality Notes |
ETF 持仓快照、13F 滞后等限制 |
| Risk Disclosure |
非投资建议 |
如果要压缩成一句话:
它不是生成一段半导体评论,而是生成一页可复核的行业暴露雷达。
09|为什么这件事值得做成 Skill?
热门板块分析有一个典型特点:
信息很多,解释也很多,但真正稳定复用的工作流并不多。
每次半导体、AI、能源、医疗这些板块走强,用户都要重新查 ETF 持仓、查机构覆盖、看价格表现、判断重复暴露。久而久之,这件事就变成了一个重复性的研究流程。
这个 Skill 的价值,是把这段流程沉淀下来。
| 用户 |
使用方式 |
| ETF 研究员 |
快速拆解行业 ETF 的真实持仓和集中度 |
| 资产配置 PM |
判断某个热门板块的核心暴露是否过于集中 |
| Fundamental analyst |
查看核心成分股是否已被大量机构覆盖 |
| 内容创作者 |
生成“热门板块 ETF 背后到底买了什么”的选题 |
| AI agent builder |
演示 ETF + 13F + 价格数据如何组合成 workflow |
对于想要深入了解这类工作流构建方式的读者,可以参考一些优秀的 开源实战 案例。
所以,它真正回答的问题不是:
SOXX 明天会怎么走?
而是:
当前这个热门板块 ETF,真实暴露和机构拥挤度到底是什么样?
10|如何用 Claude Code / GPT Codex 快速体验?
如果想本地先快速体验,可以先访问 LLMQuant Data 官网,注册并获取限量 token 和 API Key:
https://llmquantdata.com/
API 和 MCP 的 技术文档 可以从这里查看:
https://docs.llmquantdata.com/en/introduction
data-mcp 的 GitHub 地址是:
https://github.com/LLMQuant/data-mcp
拿到 API Key 之后,可以在 PowerShell 中添加 MCP:
$env:LLMQUANT_API_KEY="your_api_key"
codex mcp add llmquant-data `
--env LLMQUANT_API_KEY=$env:LLMQUANT_API_KEY `
-- npx -y @llmquant/data-mcp
Linux / macOS 可以用:
export LLMQUANT_API_KEY="your_api_key"
codex mcp add llmquant-data \
--env LLMQUANT_API_KEY="$LLMQUANT_API_KEY" \
-- npx -y @llmquant/data-mcp
配置完成后,可以直接在 Claude Code / GPT Codex 里提问:
用 sector-smart-money-scan 扫描 SOXX:
看前十大持仓、13F 机构拥挤度、NVDA 重复暴露和过去 90 天表现。
也可以用英文问:
Run sector-smart-money-scan for SOXX.
Show top holdings, 13F holder counts, duplicate NVDA exposure, and 90-day performance.
这一步非常关键。
因为只有接入 llmquant-data MCP,Agent 才能把 ETF 持仓、13F 机构覆盖和价格表现串起来,而不是只给一段泛泛的行业评论。
LLMQuant 社区 AI Trading 生态

LLMQuant 是面向全球 AI for Trading 方向的研究与实践社区。
围绕 AI 金融投资场景,我们正在构建一套完整生态:
- LLMQuant Data - 面向 Agent 的金融数据与研究上下文
- LLMQuant MCP - 让 Claude Code / Codex / Agent 能直接调用金融数据
- LLMQuant Skills - 可复用的 AI 金融研究工作流
- Quant Wiki - 开源双语量化金融知识库
- Quant Paper - AI 驱动的论文发现、语义搜索和知识卡片
- QuantMind / WallQuant / Trader - 面向研究、交易和知识管理的下一代 AI 金融工具
LLMQuant 作为全球领先的 AI for Trading 社区,目前已经打造好了 AI 金融投资领域生态 1.0 版本。
从 Data 到 MCP,从 Skills 到 Wiki / Paper,我们希望把 AI 金融投资从“单点工具”推进到可复用工作流生态。
关注 LLMQuant,和我们一起观察、构建并验证下一代 AI 交易基础设施。
Risk Disclosure
ETF 持仓来自 SEC N-PORT 监管快照,可能不等于 ETF 的实时每日组合。13F 机构持仓是延迟披露的监管文件,反映的是历史季度末仓位。本文仅供信息研究,不构成投资建议。
 发表于 6 小时前
|
查看: 4|
回复: 0
发表于 6 小时前
|
查看: 4|
回复: 0
