一、背景介绍
1. 货拉拉介绍
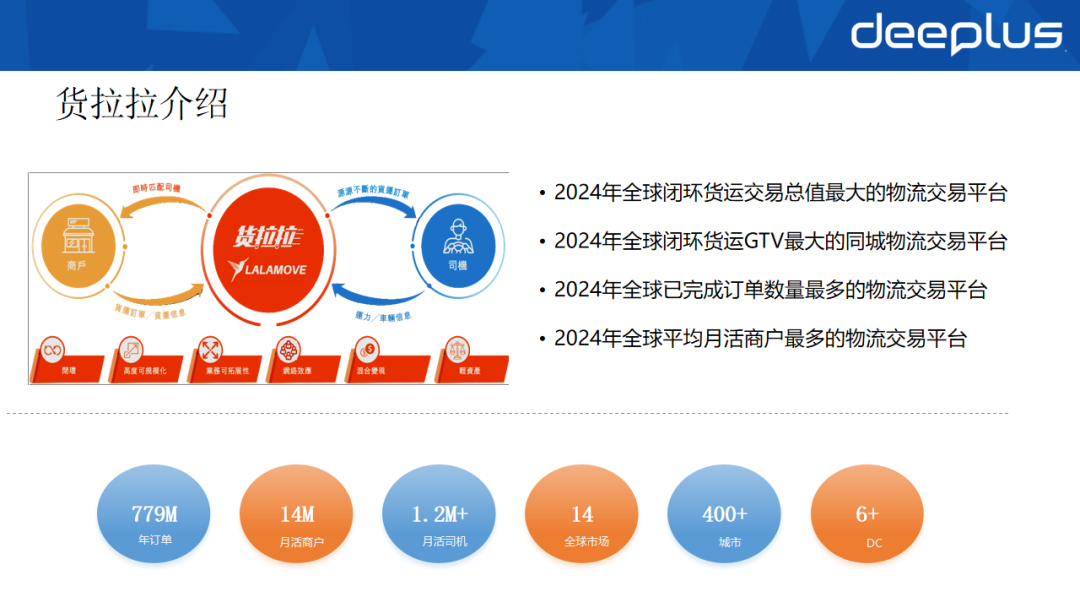
货拉拉成立于2013年,是一家互联网物流商城,提供同城与跨城的货运服务。目前业务涵盖企业服务、零担物流、长途运输、汽车租赁等八条以上业务线,服务覆盖全球14个市场及400多个城市;年订单量超7.79亿,月活跃商户1400万+,月活跃司机120万+;在全球运营6个以上数据中心。
2. 货拉拉大数据

在大数据层面,货拉拉目前拥有4个数据中心,采用跨云混合云架构,涵盖阿里云、腾讯云以及部分自建机房。部署机器数量超过3000台,数据存储量达40PB+,日均处理任务数超过2万。当前,货拉拉的机器规模、数据存储量及日均任务数均处于业界中等水平,且处于快速发展阶段。
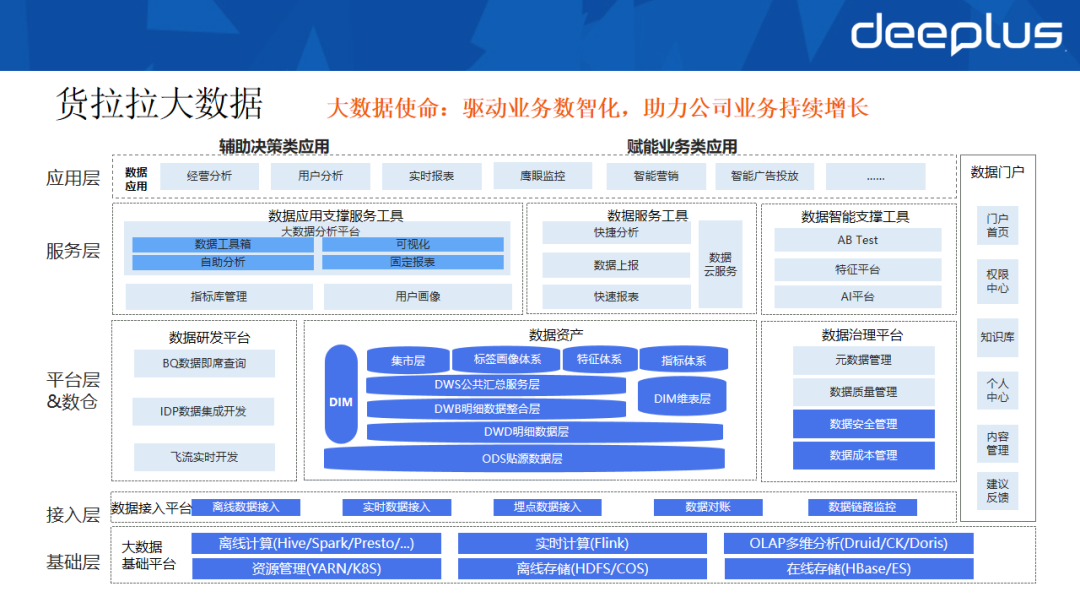
大数据的核心使命是驱动业务数智化,助力公司持续增长。上图展示了货拉拉的大数据架构体系,该体系自下而上相互支撑,以满足公司各类离线场景的需求,主要分为:
- 基础层和接入层:提供基础计算、资源、存储及数据接入能力。
- 平台层和数据层:包含数据研发平台、数据治理平台、数据资产等。
- 服务层:包含面向服务的数据应用、数据服务及数据智能工具。
- 应用层:辅助决策类应用和直接赋能业务的各类应用。
3. 自建+云服务混合架构
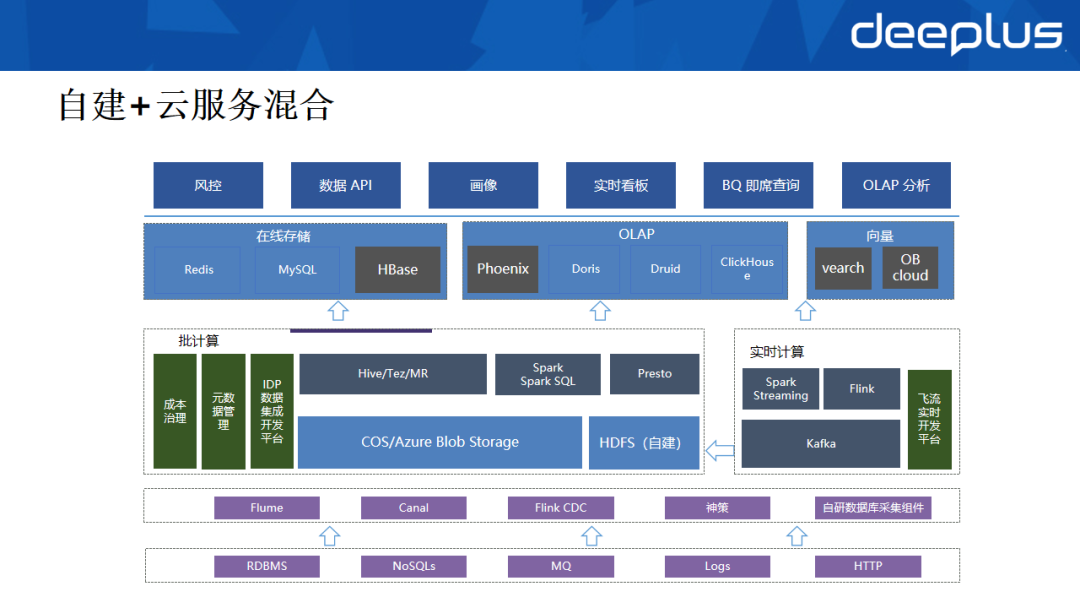
大数据存储架构采用自建与云服务混合部署的模式,数据流向呈现典型的Lambda架构特征。源头数据经过底层的采集、处理与加工后,会分流至实时和离线两条链路。离线数据最终落入离线存储,部分AI数据则流入向量存储。实时数据与处理后的离线数据汇合后,进入在线存储,共同为上层的应用提供服务。
从数据使用视角出发,可将大数据存储划分为在线、离线和向量三大类别。
二、在线存储
1. 在线存储发展历程
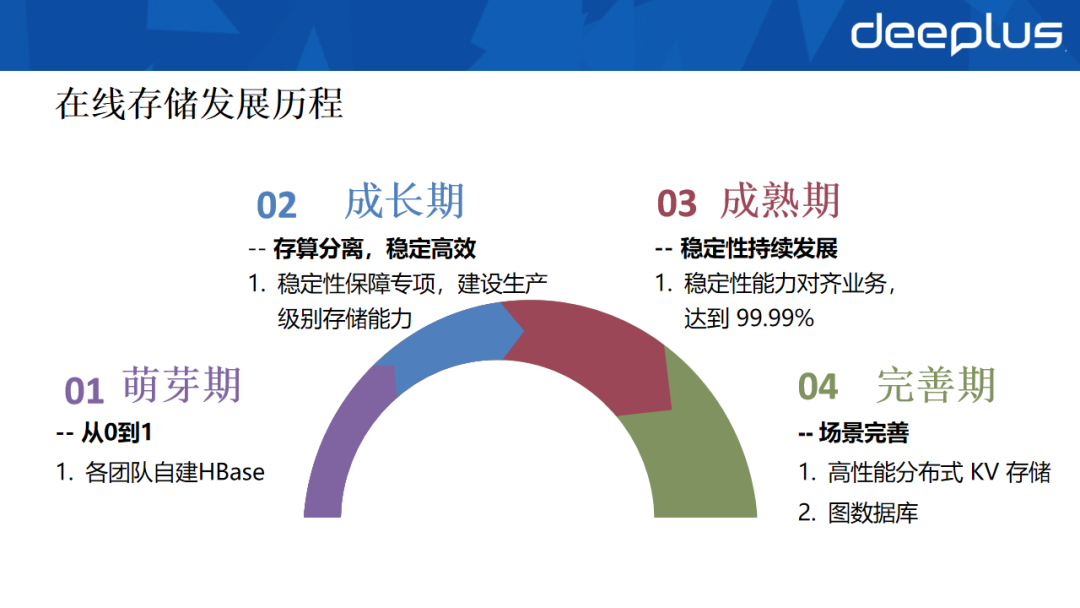
货拉拉的在线存储发展历经四个阶段:
- 萌芽期:各业务团队自建并维护独立系统。
- 成长期:开展稳定性保障专项,构建生产级别的存储能力。
- 成熟期:稳定性能力对齐业务需求,达到99.99%的SLA。
- 完善期:调研新组件以丰富技术栈,支撑更多应用场景。
2. 在线存储使用现状

货拉拉的在线核心存储采用 HBase 2.0.2 数据库,并以多云架构进行部署。目前共运维20套集群,节点数超过200台,承载业务表700余张,其中最大单表数据量接近1PB,服务超过100个业务场景。在此规模下,为保障多业务场景的稳定运行,参考业界最佳实践构建了完整的稳定性体系。
3. 稳定性体系概览
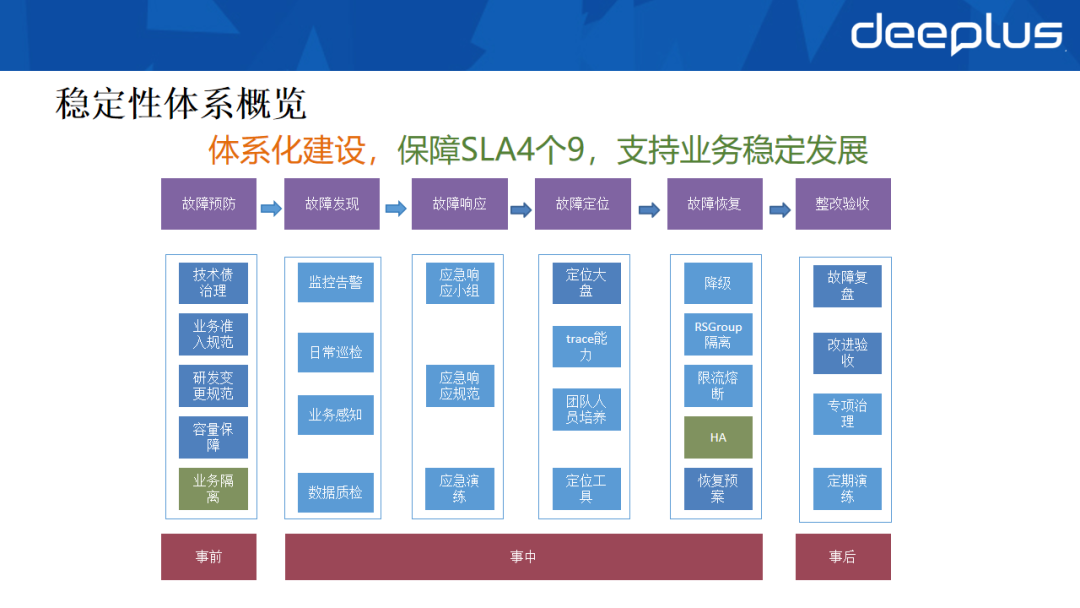
如图,按照事前预防、事中处置、事后改进的顺序,建立了一套完整的稳定性保障体系。
- 事前(故障预防):技术架构与业务负责人盘点、研发变更流程梳理、容量评估、日常演练、业务隔离。
- 事中(故障处置):
- 发现:多维监控告警、日常巡检、业务侧感知、全链路监控。
- 响应:建立应急响应小组、规范响应流程、定期演练。
- 定位:建设统一的问题定位大盘、Trace追踪能力、培养团队人员、配备定位工具箱。
- 恢复:预案降级、RsGroup隔离、限流熔断、高可用切换、执行恢复预案。
- 事后(整改验收):彻底复盘故障、推动改进迭代、开展专项治理、提升云运维能力。
通过以上体系建设,在线存储的SLA从99.9%提升至99.99%,满足了线上业务对高可用的要求。
4. 稳定性实践——业务隔离
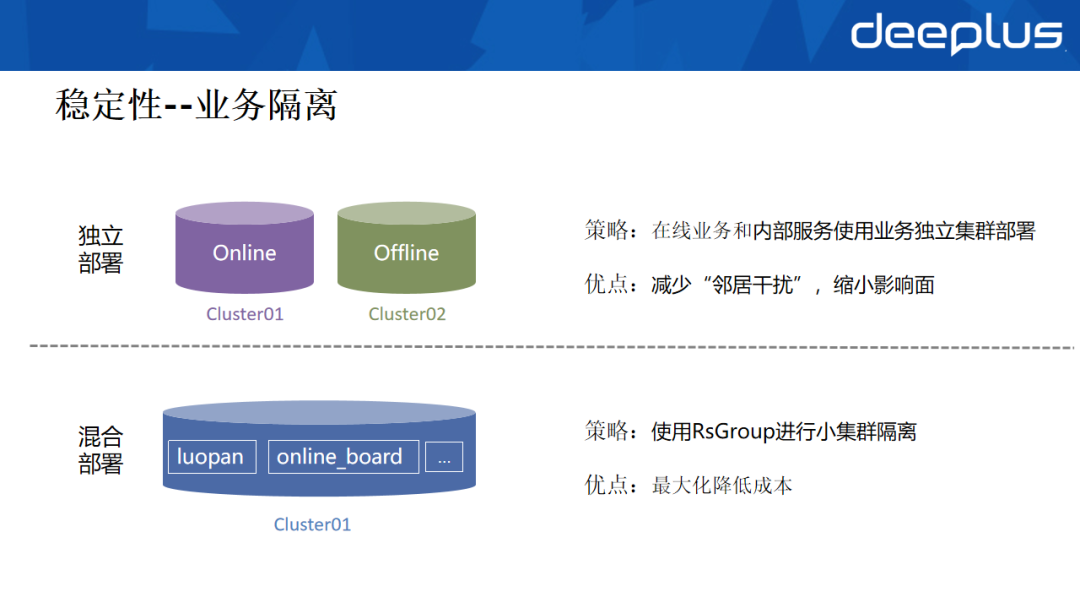
为兼顾不同业务对稳定性与成本的需求,货拉拉采用了灵活的业务隔离策略。
- 独立部署:将在线业务与离线业务进行物理集群拆分。离线业务常伴随大规模或不规律的读写,对底层磁盘IO压力大,数据量也庞杂,与在线业务混部会严重影响其稳定性与性能。
- 混合部署下的逻辑隔离:即使在在线业务内部,不同业务特性也可能导致资源竞争。例如,基于Flink读写的实时维表业务在任务重启时可能引发流量激增,抢占CPU与磁盘IO;而风控业务则要求稳定的低延迟。将两者部署在同一资源池中,易导致关键业务性能劣化。
为解决此问题,我们利用了HBase的RsGroup能力在集群内部实现逻辑分组隔离。该方案避免了新建独立集群的成本,实现了存储资源的共享,同时借助HDFS本地读取特性保障了读写性能。通过这种措施,实现了P0/P1/P2不同级别业务的隔离,在保障性能的同时控制了成本。
5. 稳定性实践——高可用(HA)能力建设
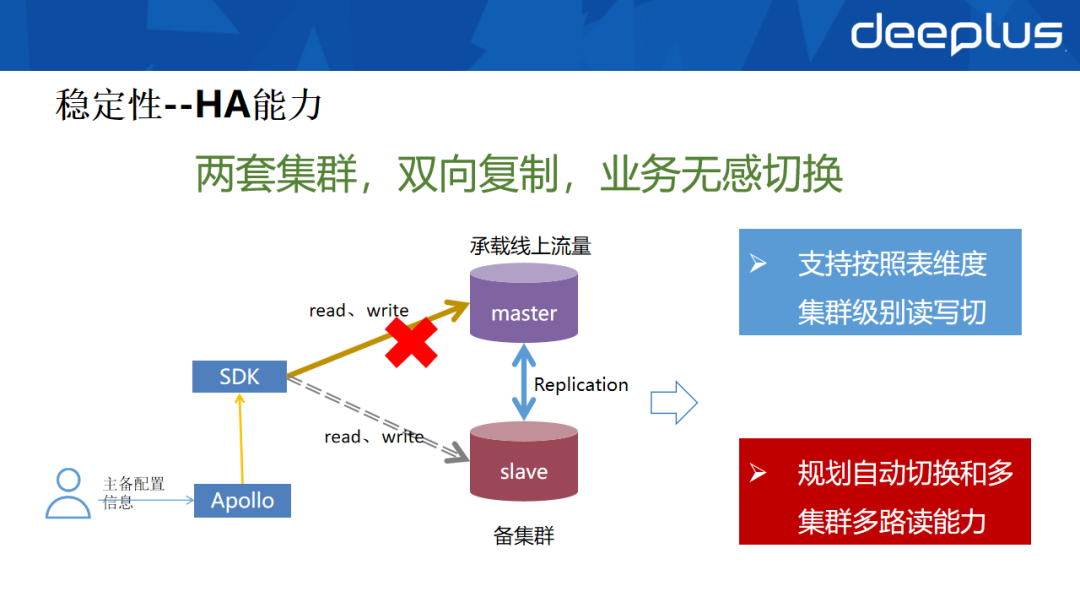
HBase 2.0.2版本的复制(Replication)功能存在一些缺陷。通过研究后续版本实现,我们合并了约40个相关issue来完善该功能。如图,通过搭建两套集群并配置双向复制,实现了互为主备的容灾效果,且备集群与主集群位于不同可用区,达到Region级别的容灾能力。
由于社区版HBase客户端缺乏自动切换能力,我们基于公司内部的配置中心,自主研发了支持HA的HBase SDK。当主集群发生故障时,可通过配置中心动态修改主备配置参数,实现读写链路的平滑切换。目前该HA方案已支持表级别的切换。
未来规划是实现故障的自动切换机制,以进一步缩短恢复时间(RTO),并希望通过HA架构拓展多路读能力,缓解HBase的长尾延迟问题。
6. 性能与效率优化——面临的挑战
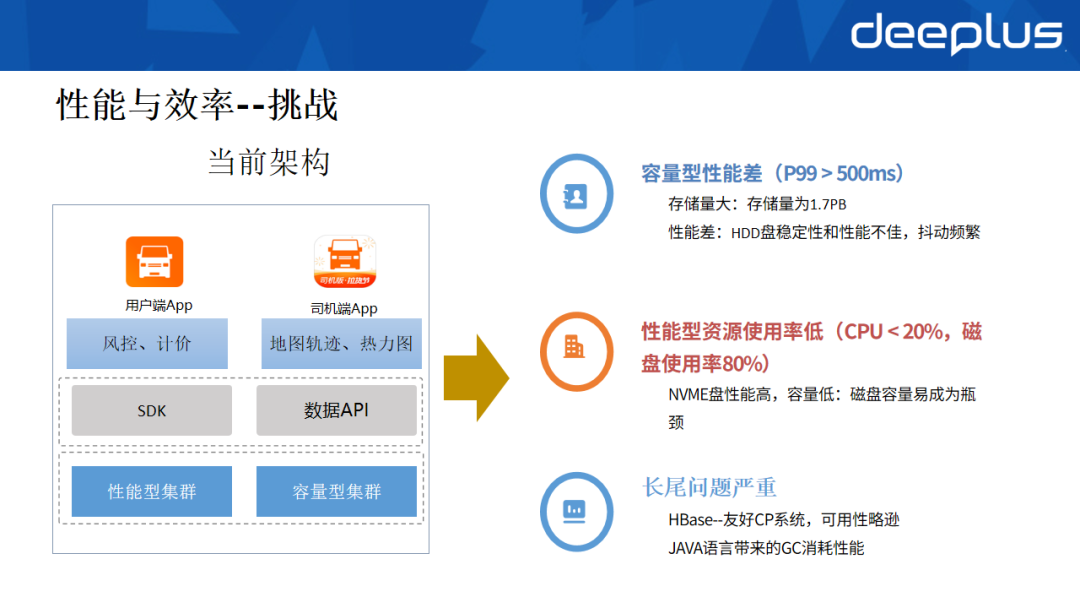
稳定性体系建成后,HBase在线业务进入平稳期。根据业务需求特性,集群规模被划分为两类:
- 性能型集群:承载风控、数据API等对延迟敏感、性能要求高的业务。
- 容量型集群:承载地图轨迹等内部服务,该类业务对时延不敏感但数据体量大,适合部署在成本更优的容量型集群。
随着业务发展,该架构逐渐暴露出三个痛点:
- 容量型集群性能不足:HDD盘的读写性能和不稳定性成为瓶颈。例如,轨迹数据开始被风控业务使用,一旦查询超时将直接影响风控策略执行。
- 性能型集群资源利用率低:为保障性能采用三副本存储在NVMe盘上,但NVMe盘容量小,常成为扩展瓶颈,导致CPU使用率长期处于低位,成本高昂。
- 长尾延迟问题严重:这是HBase存算分离架构及JVM GC不确定性带来的典型问题,请求毛刺频发。
7. 异构存储方案
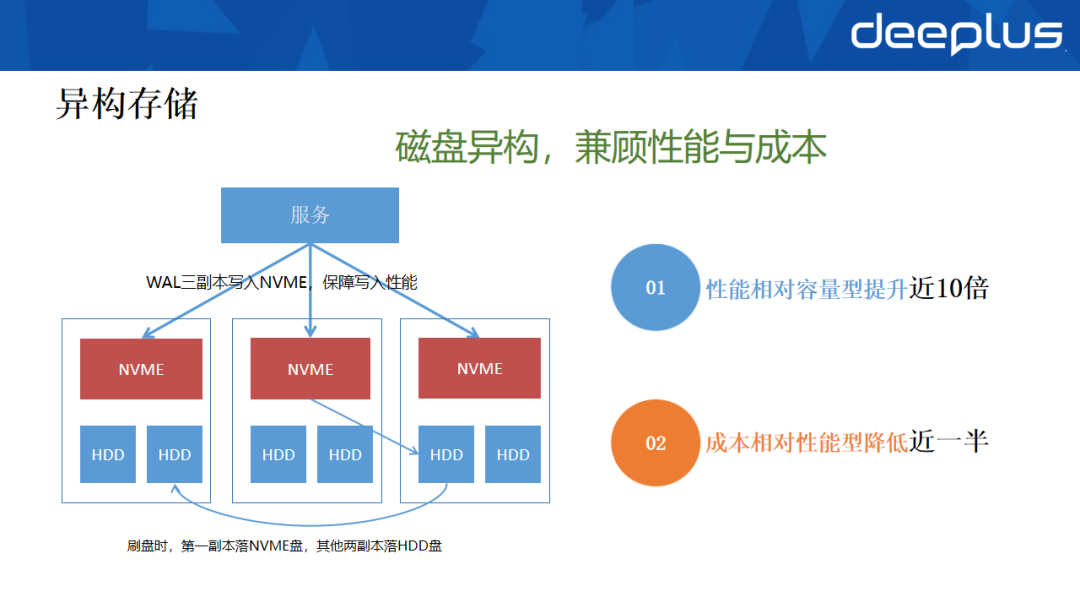
针对上述性能与成本的矛盾,我们引入了异构存储解决方案。
具体做法是,利用HDFS的磁盘异构能力,在每台物理机上同时配备高性能的NVMe盘和大容量的HDD硬盘。数据写入时,确保WAL(预写日志)的三个副本均写入NVMe盘以保证写入性能。数据块(Block)则优先写入本地NVMe盘,其余两个副本存储于其他节点的HDD盘。
在数据查询时,借助HBase的数据本地性优势和Compaction策略优化,优先从本地NVMe盘读取热数据。通过此架构,异构集群的读写性能相比纯HDD集群提升了近十倍。同时,存储模式从“三副本NVMe”调整为“单副本NVMe+两副本HDD”,使集群成本较原先的全闪存方案降低了近一半,成功实现了性能与成本的平衡。
8. 应对长尾:高性能KV组件选型
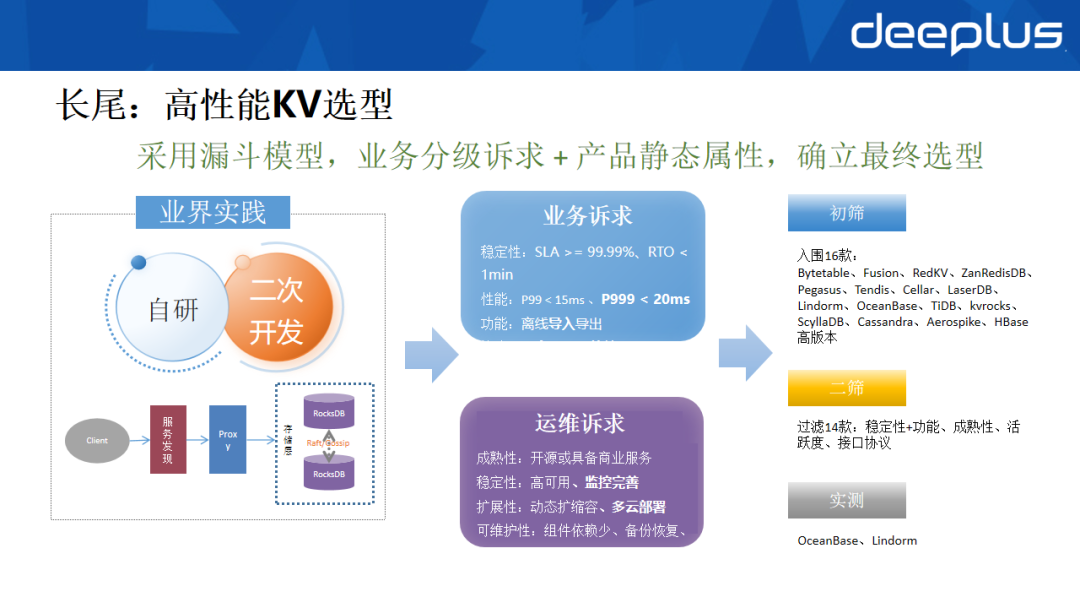
针对长尾问题,我们实施了包括Compaction优化、GC调优、内存优化在内的多项措施,但由于HBase的架构限制,无法根除该问题。因此,我们启动了高性能KV组件的选型工作。
参考业界实践(如字节跳动表格存储、滴滴Fusion等),主流方案多采用非Java语言开发,基于单机RocksDB封装,并通过Raft等协议保证一致性。我们决定优先选用成熟产品,并结合自身业务痛点进行筛选。筛选采用漏斗模型,从十余款产品中最终聚焦于OceanBase与Lindorm。核心筛选标准如下:
- 业务诉求:
- SLA高于99.99%。
- 支持风控场景的多跳图查询,要求P99延迟足够低。
- 支持离线数据大批量旁路导入,且不影响在线读写。
- 兼容HBase协议,降低业务改造成本。
- 运维诉求:
- 成熟度高(活跃开源社区或大厂商业支持)。
- 支持高可用、具备完善的监控与追踪能力。
- 支持动态扩缩容与多云部署。
- 具备机房级容灾能力,组件依赖少,备份恢复便捷。
9. 测试与上线规划
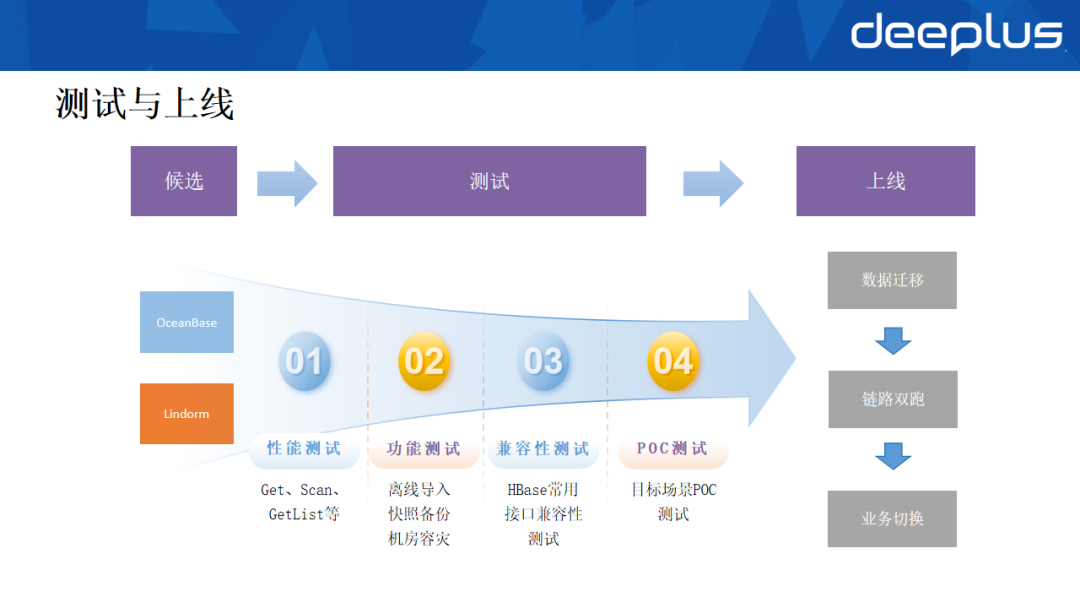
OceanBase和Lindorm均能满足基本需求,我们针对性地设计了四类测试方案:
- 性能测试:聚焦Get、Scan和GetList场景。测试结果显示两者性能相当,Lindorm在部分查询场景中略占优势。
- 功能测试:
- 离线导入:两者均能满足大规模数据导入导出需求。
- 机房容灾:OceanBase仅需三个副本即可实现跨Region容灾(云上甚至可两副本+仲裁节点),而Lindorm需要六个副本才能达到类似效果。在多云部署上,Lindorm目前主要绑定阿里云,而OceanBase支持多云架构,更符合货拉拉的混合云形态。
- 兼容性测试:Lindorm完全兼容HBase协议,对现有业务几乎零改造,优势明显。
- POC测试:目前处于POC验证阶段,两款组件各有优劣。完成后将推进上线与数据迁移,并计划利用HA能力实现业务无感切换。
10. 多级存储架构
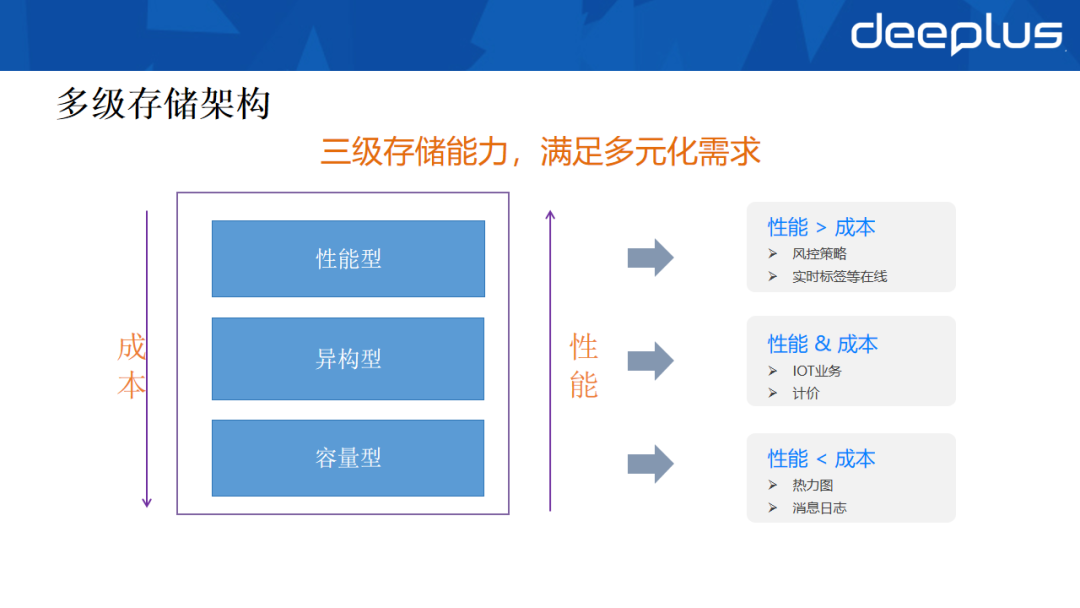
根据当前规划与建设,在线存储已形成按性能与成本划分的三级架构:
- 性能型:性能优先,成本次要。适配风控策略、实时消息等核心在线业务。
- 异构型:性能与成本平衡。适配IOT时序数据、计价等场景。
- 容量型:成本优先,性能次之。适配热力图、操作日志等温冷数据业务。
不同业务可根据自身特征选择适配的存储类型,满足了多元化的业务需求。
三、离线存储
1. 离线存储发展历程
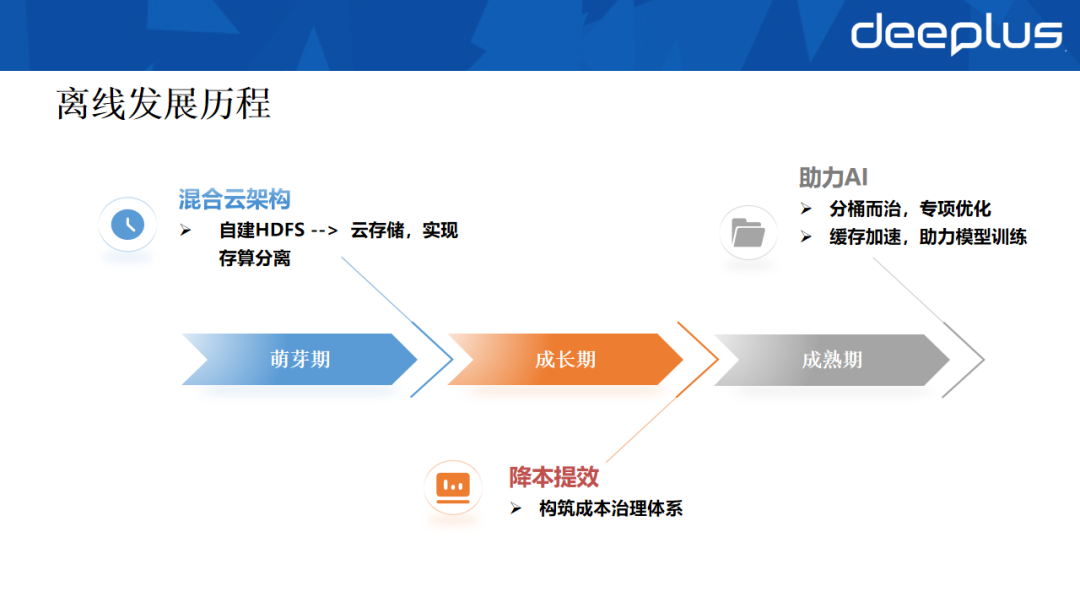
- 萌芽期:从自建HDFS起步,逐步转向云上对象存储,通过存算分离降低成本。
- 成长期:随着数仓扩张,存储成本激增,建立成本治理体系以降低单均成本。
- 成熟期:在AI时代,离线存储需协同支撑AI应用落地,通过分桶治理、专项优化及缓存加速助力模型训练。
2. 冷热分层与成本治理
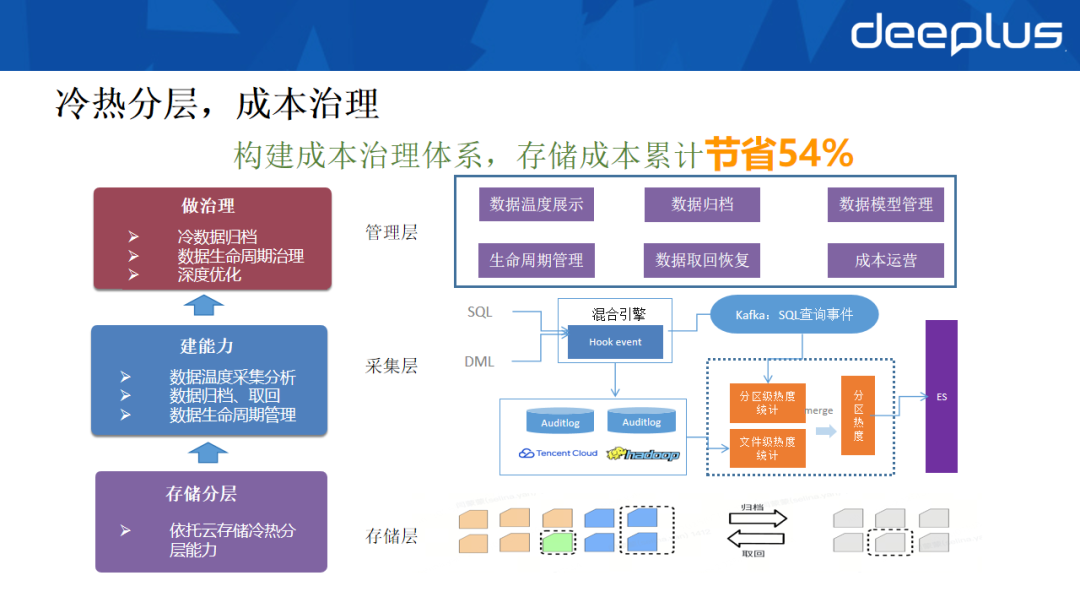
我们构建了云数据管理平台作为成本治理的核心,通过体系化的治理与优化,累计节省存储成本54%。该平台架构分为三层:
- 存储层:直接利用云对象存储提供的冷、热、归档等多级存储能力。
- 采集层:构建数据热度分析能力。通过Hook拦截分析查询SQL,按分区粒度统计访问频次;同时结合存储层的审计日志,补充文件级访问信息,形成完整的热度画像,最终存入Elasticsearch。
- 管理层:负责治理策略执行与推广,包括自动冷数据归档、温数据可视化、生命周期管理及存储格式深度优化(如小文件合并、压缩算法升级)。
目前,正协同元数据管理团队推进“健康分”治理与“红黑榜”功能,形成成本优化的良性闭环。
3. AI时代的新挑战
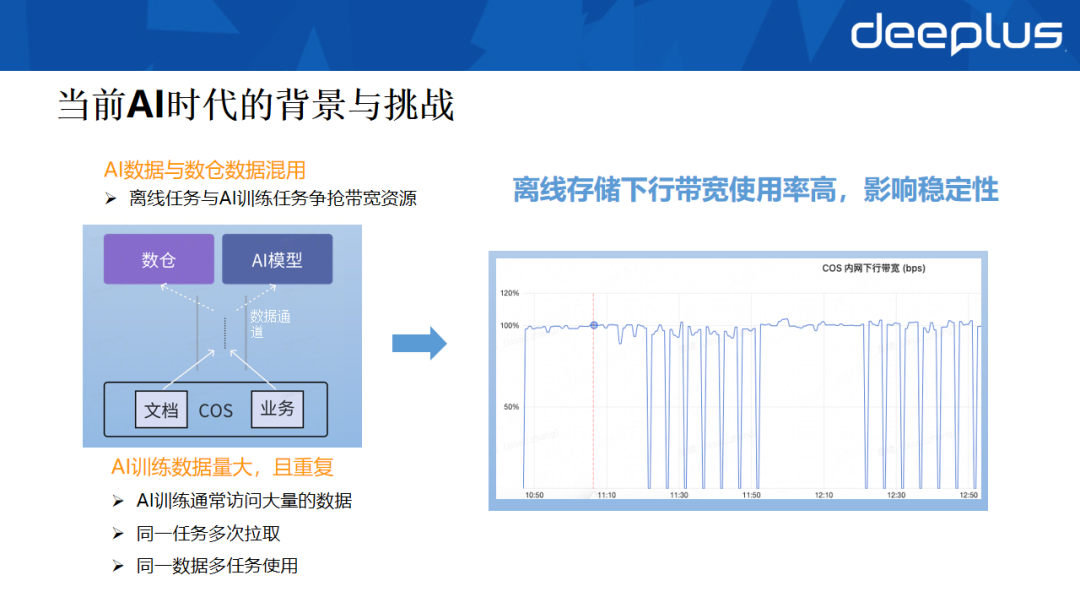
大模型训练的兴起给离线存储带来了新挑战。尽管已向云厂商申请了较高的带宽配额,但下行带宽仍频繁吃紧。
经排查发现,问题根源在于AI训练任务与离线数仓任务混用同一存储资源池。AI训练具有数据读取量大、反复拉取的特点,长期占用大量带宽,严重影响了离线数仓ETL等链路的稳定性。
4. 分桶而治,助力AI训练
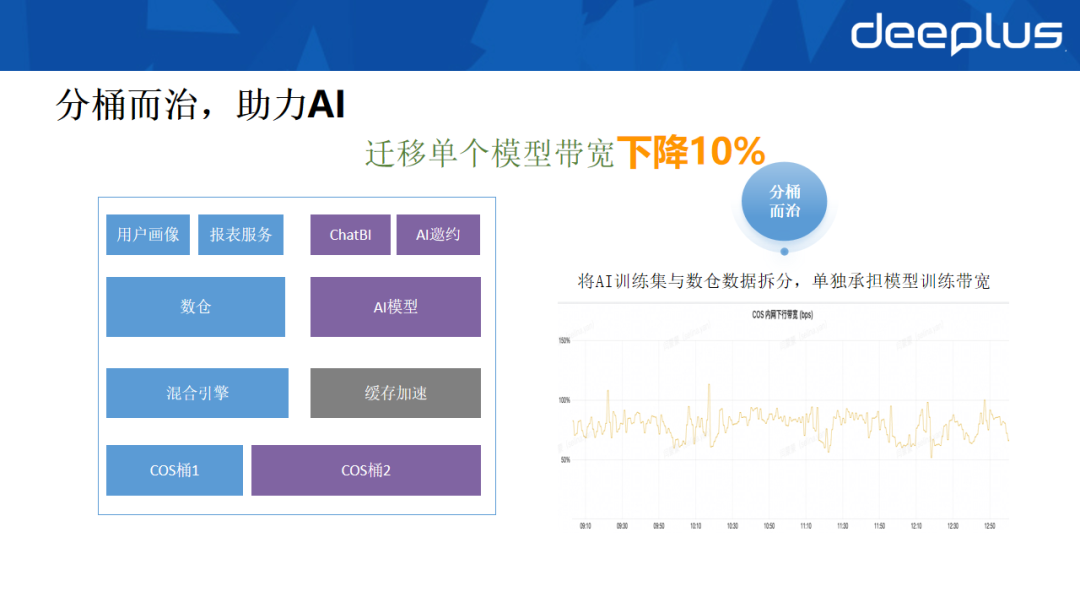
为解决这一问题,我们采取了“分桶隔离”与“增加缓存”的组合方案:
- 存储隔离:将AI训练所需的数据与离线数仓数据在存储桶(Bucket)层面进行物理隔离,避免相互干扰。
- 增加缓存层:为AI训练任务单独增加高性能缓存层(如Alluxio、JuiceFS),缓存频繁读取的数据,极大减少对底层对象存储的重复拉取,降低带宽压力。
初步验证显示,仅迁移单个模型的数据后,整体下行带宽消耗就降低了约10%。目前正与腾讯云合作,利用其缓存加速解决方案,以更少的资源满足AI训练对存储高吞吐的需求。
四、AI向量存储
1. 发展历程
- 萌芽期:为快速支持业务落地,多款向量数据库组件并行试点。
- 成长期:随着应用稳定与技术能力沉淀,开始进行统一的技术选型与平台化建设。
- 成熟期:伴随多模态AI应用深入,向量存储方案持续演进,以支撑更复杂的智能场景。
2. 大模型在货拉拉的应用

大模型已应用于货拉拉14个部门的超50个业务场景。向量存储作为核心组件,支撑了文生图、文生视频、以及基于RAG的企业知识库问答等多种应用。
1) 智能客服助手
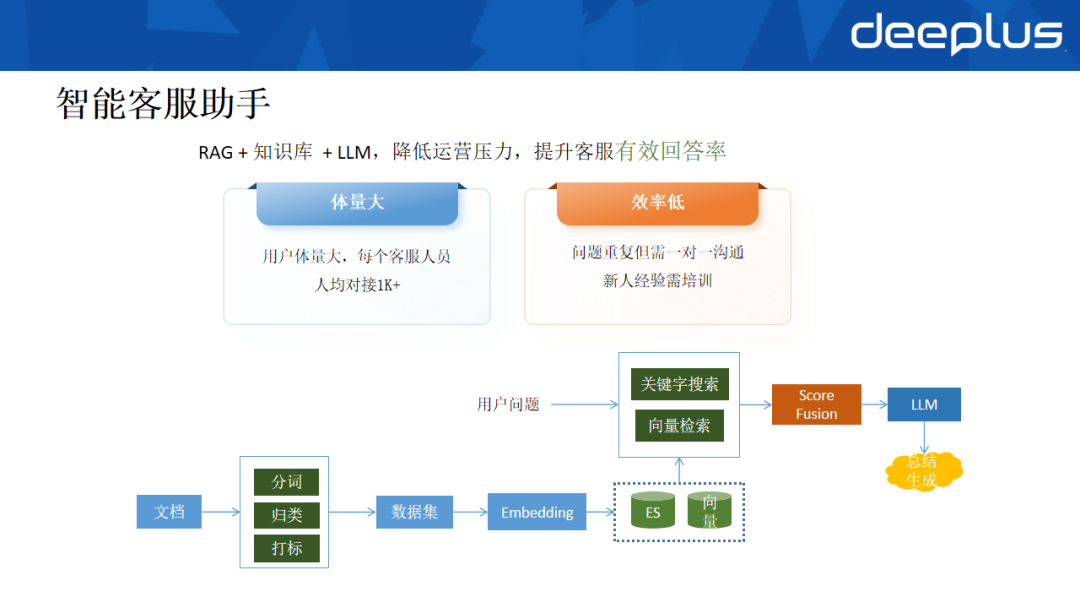
客服业务面临两大痛点:服务体量大(人均对接千名以上用户)、传统方式效率低。为此,我们开发了基于RAG+LLM的智能客服助手。
- 知识处理:将SOP文档、历史聊天记录进行分词、打标,通过Embedding模型转换为向量,存入向量数据库。
- 智能应答:用户提问时,系统并行执行关键词搜索(通过ES)和语义检索(通过向量数据库)。将两者的结果进行分数融合(Score Fusion)重新排序,将TOP结果作为上下文,提交给大模型生成标准回答,客服仅需简单审核即可发送。
2) IT运维助手

IT运维场景的痛点在于问题解决门槛高、重复性问题多。内部IT运维助手有效提升了效率。
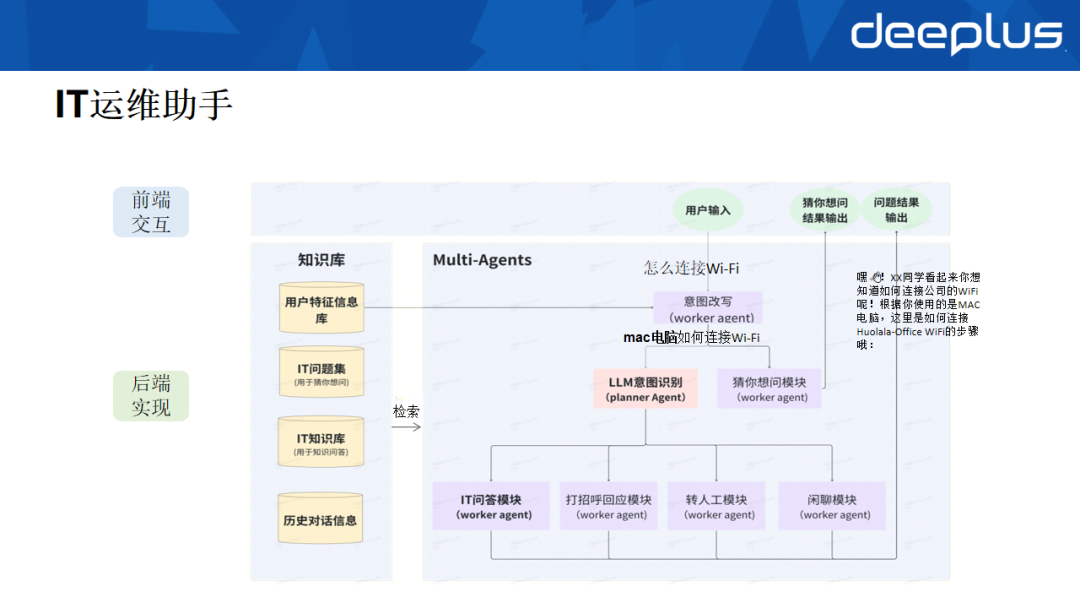
- 问题理解与改写:用户输入问题后,系统会结合用户身份、设备信息(如Mac电脑)对问题进行自动化改写,使其更精确(如“怎么连wifi”被改写为“Mac电脑如何连接wifi”)。
- 意图识别与路由:通过大模型识别用户意图,并路由到对应的处理Agent(如IT问答Agent)。
- 知识检索与答案生成:IT问答Agent从向量化的知识库中检索相似问题与答案,经过优化改写后,拼接至Prompt中,交由大模型生成最终回复。系统还提供“猜你想问”功能,主动推荐相关高频问题,辅助用户澄清需求。
该应用已集成至飞书工作台,大部分常见IT问题可实现自主问答,显著提升运维效率。
五、结语
货拉拉的大数据存储架构演进,是一个围绕稳定性、成本、性能与新兴业务需求(如AI)持续平衡与优化的过程。从在线存储的多级架构与HA建设,到离线存储的成本深度治理与AI缓存加速,再到向量存储支撑的智能应用落地,每一步都体现了技术驱动业务发展的核心理念。未来,我们将继续探索存储分层融合、向量原生与智能自治的基础设施,以应对更大规模、更复杂的业务挑战。
 发表于 2025-12-13 08:20:47
|
查看: 293|
回复: 0
发表于 2025-12-13 08:20:47
|
查看: 293|
回复: 0
