在高性能存储系统中,一个关键矛盾日益凸显:网络带宽正从400Gbps向1.6Tbps跃迁,SSD单盘性能已突破32GB/s,但承担数据处理任务的xPU(如DPU、IPU)却受限于PCIe通道数量,逐渐演变为新的性能瓶颈。传统架构中,压缩、去重、RAID校验等计算密集型任务集中在CPU或DPU上,不仅消耗大量计算资源,更在高速数据流面前显得力不从心。
本文将探讨一种突破性的解决方案——将算力从xPU下沉至SSD本身。通过在SSD控制器中集成专用硬件引擎,实现“算力随容量线性扩展”的模式,帮助存储系统彻底突破I/O墙的限制。这一架构变革不仅重新定义了存储系统的分工协作方式,也为AI时代的数据基础设施提供了全新的设计范式。
一、xPU的困境:从算力中心到潜在瓶颈
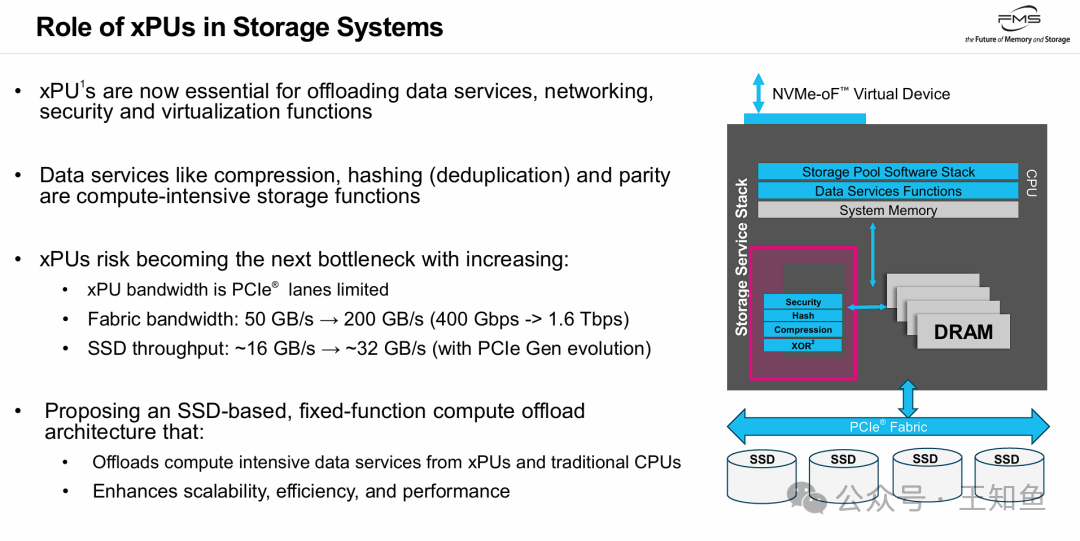
尽管xPU已成功从主CPU接管了网络、安全和虚拟化等基础服务,但在面对现代存储系统极高的I/O吞吐需求时,xPU自身正面临成为系统新瓶颈的风险。
- 核心矛盾在于带宽不匹配:网络带宽(迈向1.6 Tbps)和SSD性能(随PCIe代际演进而增长)的提升速度,已经超过了xPU基于有限PCIe通道的处理能力。
- 计算密集型任务负担重:数据压缩、哈希(用于去重)、奇偶校验(用于RAID/EC)等操作都是典型的计算密集型存储功能。
- 演进方向:为了解决这一瓶颈,业界开始探索将计算任务进一步下沉的方案,即 “基于SSD的固定功能计算卸载架构” ,这实质上指向了计算存储(Computational Storage) 的理念。
二、存储数据流水线:为何传统架构力不从心
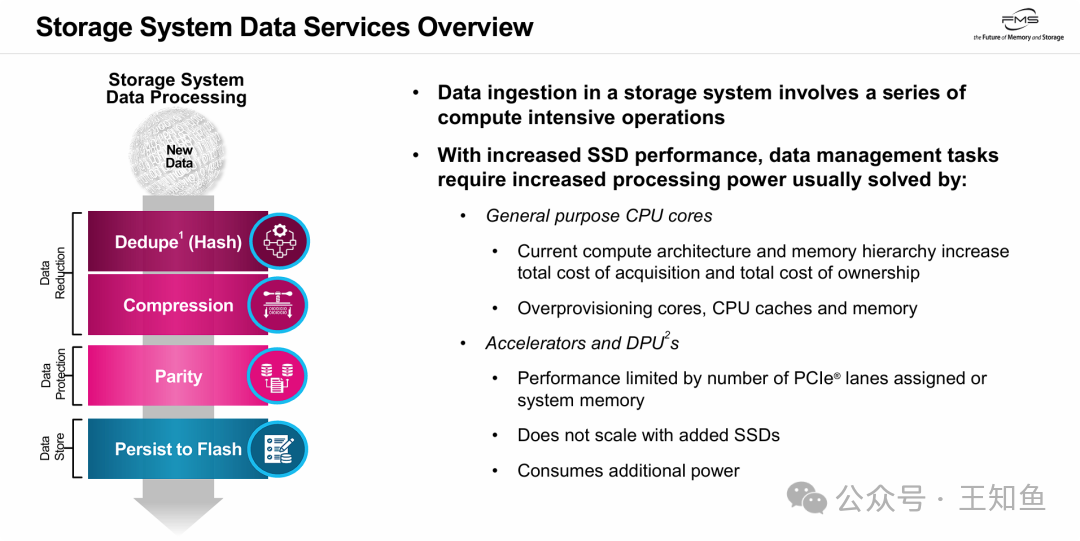
现代全闪存阵列的数据写入路径非常“重”。新数据在最终持久化到闪存之前,必须经过一系列密集的在线(Inline)处理:
- 数据缩减阶段:包括重复数据删除(哈希计算)和数据压缩。
- 数据保护阶段:进行奇偶校验(RAID/纠删码计算)。
- 数据存储阶段:将处理后的数据写入SSD。
问题的核心在于,传统集中式计算架构已无法匹配高性能闪存的数据处理需求:
- CPU效率低下:用通用CPU处理这些任务性价比较低。
- DPU扩展性不足:DPU虽然是专用加速器,但其算力是集中式的。当为了扩容而增加SSD时,DPU的算力并未随之增长,反而会成为新的瓶颈。
这就引出了一个核心推论:要解决“加盘不加算力”的问题,必须将计算能力分布式地部署到每个SSD上,实现算力与存储容量的线性扩展。
三、计算型SSD架构:主机控制,设备执行
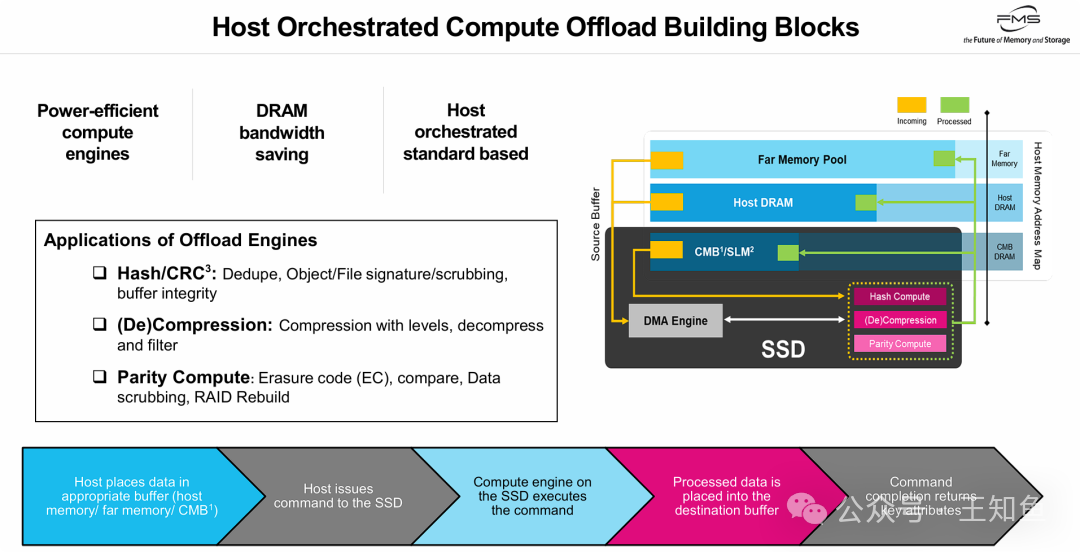
上图定义了“计算型SSD”的具体实现架构,其核心是 “主机控制,设备执行” 的模式。
- 控制与计算分离:主机(Host)作为“大脑”,负责内存管理和任务调度;SSD则作为“肌肉”,利用内部集成的专用硬件引擎(Hash计算、压缩/解压、奇偶校验)来执行繁重的计算任务。
- 灵活的内存访问:SSD的计算引擎可以处理主机DRAM、远端内存甚至SSD自身CMB(控制器内存缓冲区)中的数据,使其成为一个高效的PCIe协处理器。
- 核心价值:
- 节省CPU资源:彻底释放主机CPU,使其专注于应用逻辑。
- 节省内存带宽:数据直接在SSD内部处理,减少了在PCIe总线和主机内存间的无效搬运。
- 基于标准:依托NVMe等标准协议,保障了生态兼容性。这种将特定计算任务卸载到专用硬件的思路,与追求极致效率的云原生/IaaS理念有异曲同工之妙。
四、系统级收益:xPU角色重塑与线性扩展
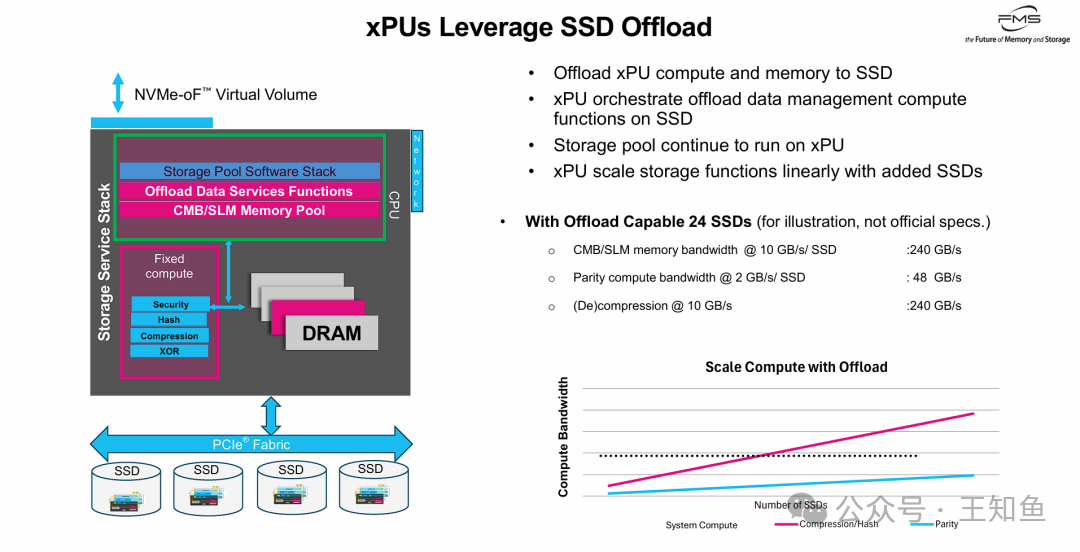
当引入计算型SSD后,整个系统架构和xPU的角色发生了根本性变化:
- xPU角色转变:xPU从“计算执行者”转变为“资源调度者”。它负责编排SSD集群上的计算任务,而存储池管理等控制平面逻辑继续在xPU上运行。
- 突破I/O墙:计算能力从集中式变为分布式,系统不再受限于xPU有限的PCIe通道和算力。
- 核心优势:存算线性扩展:这是该架构最大的价值主张——“买容量即送算力”。每增加一块SSD,不仅增加了存储空间,还同步增加了压缩、校验和内存带宽等处理能力。例如,在一个24盘位的系统中,聚合的压缩/解压带宽可达240 GB/s,这远超单个xPU或CPU的PCIe带宽上限。
五、架构演进:为AI时代铺平道路

这一架构变革引领存储系统向更高级的形态演进:
- 迈向无机头架构:DPU成为连接网络和SSD集群的核心枢纽,推动存储系统向高密度、高效率的分布式无机头架构发展。
- 赋能AI与高级数据处理:通过将基础的数据缩减与保护操作卸载到SSD,宝贵的DPU/CPU算力得以释放,可用于数据向量化等AI相关任务,使存储系统不仅能“存”数据,还能初步“处理”数据。
- 理想的经济模型:在大规模数据中心和云计算环境中,这种“算力随容量线性增长”的模型,避免了为扩容而被迫过度采购计算资源的浪费,显著优化了TCO(总拥有成本)。
六、概念验证:显著的资源释放效果
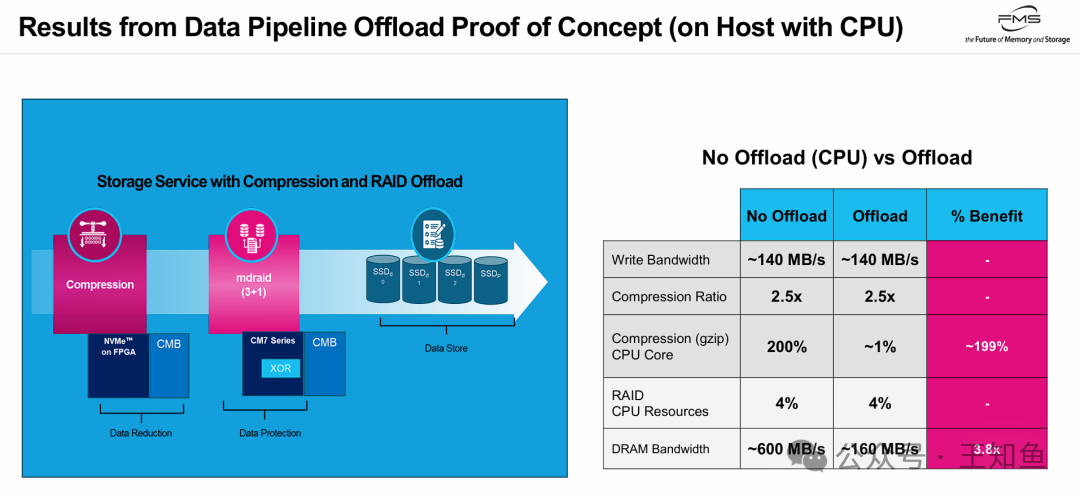
实测数据有力地验证了计算存储的能效价值:
- 极致释放CPU:在完成相同压缩任务(2.5倍压缩比)时,卸载方案将CPU占用从200%(约2个核心)降至近1%,实现了近乎零的CPU消耗。
- 大幅节省内存带宽:通过利用SSD的CMB,减少了数据搬运,系统DRAM带宽需求从约600 MB/s降至约160 MB/s,效率提升近4倍。
- 同效低耗:在保持相同写入带宽(140 MB/s)和压缩质量的前提下,实现了系统资源消耗的断崖式下降,证明了其在降低TCO方面的巨大潜力。
本文讨论的xPU计算卸载主要聚焦于企业级存储常见的数据缩减场景。在AI与智能应用爆发的未来,端侧与近数据计算的需求将更为旺盛,届时计算型存储的应用价值将被进一步放大。
延伸思考
- 在你的工作场景中,是否已观察到xPU/CPU在处理存储密集型任务时的性能瓶颈?当时是如何应对的?
- 计算存储架构虽能释放CPU并提升效率,但可能带来SSD成本上升和运维复杂度增加。你认为这种权衡在哪些应用场景下是值得的?
- 随着AI应用对数据处理需求的爆发,除了压缩和校验,你认为未来存储系统还需要优先卸载哪些计算任务?
原文基于KIOXIA在FMS 2025的分享“Offloading xPU Storage Compute Tasks to SSD”整理。 |  发表于 2026-1-18 11:03:16
|
查看: 195|
回复: 0
发表于 2026-1-18 11:03:16
|
查看: 195|
回复: 0
