在之前的技术分享中,我们探讨了一些特定形态的识别算法。然而,这些方法往往因其针对性,仅对特殊形态有效。因此,设计一款更具普适性的波段识别算法,就成为了一个值得深入研究的课题。
技术分析建立在三大基本假设之上:市场包容消化一切、价格以趋势方式演变、历史会重演。波段形态识别的核心,正是基于这些假设——通过分析历史走势,寻找相似形态,总结其规律(概率),并在此基础上对未来行情进行预测。
你一定听说过“波浪理论”,也常听到“千人千浪”的说法。从本质上讲,这套理论是为市场走势寻找一种解释框架。当然,其中也包含一些明确的结论,本文将应用的一个关键结论是(以上涨波浪为例):
- 1、3、5浪的高点依次上升。
- 2、4浪的低点也依次上升。
基于此,一个可行的策略思路是:识别出第1浪后,在第3浪的起始阶段入场,待价格上涨超过第1浪高点后,在回调某个固定比例时平仓离场。如下图所示:
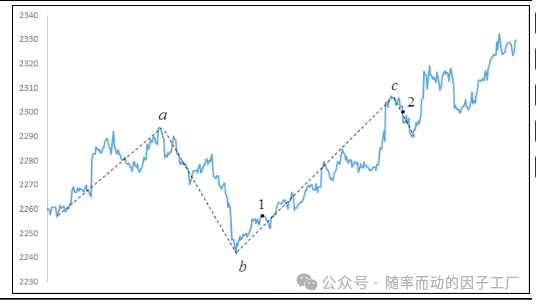
该策略的目标在于,在点“1”时,需要完成以下四步:
- 形态识别:有效识别当前走势形态,并在历史数据中找出所有类似的形态。
- 计算概率:基于上一步找出的相似形态,计算未来价格涨幅能超过点
a 的概率。
- 构建策略买点:若上述概率超过预设阈值,则在点1处买入标的。
- 构建策略卖点:若后期价格涨过点
a,则在回撤某个阈值时平仓;若价格未能涨过 a 点,则在从高点回撤超过止损阈值时离场。
综上所述,本文旨在提供一种能够有效识别波段形态的算法。在此算法框架下,我们可以量化当前形态在历史上演变为上涨或下跌趋势的概率,并据此构建择时或选股策略。
本文的灵感来源于券商研究报告,并进行了算法改进与代码实现。由于内容较多,将分为上、中、下三篇:
- 上篇:传统方法简介与新方法的数据预处理(即本篇)。
- 中篇:形态识别新方法的原理、测试与部分代码实现。
- 下篇:基于识别结果的策略构建与回测。
基本知识
什么是波段
在波浪理论与道氏理论中,股价走势最基本的构成单元就是“Z”字形波浪。所有复杂的波浪形态,都是由这些基础的Z字形波段连接而成。因此,本文的核心目标就是识别这些Z字形波段。
下面是一些由Z字形波构成的经典技术形态:
- 头肩顶形态:
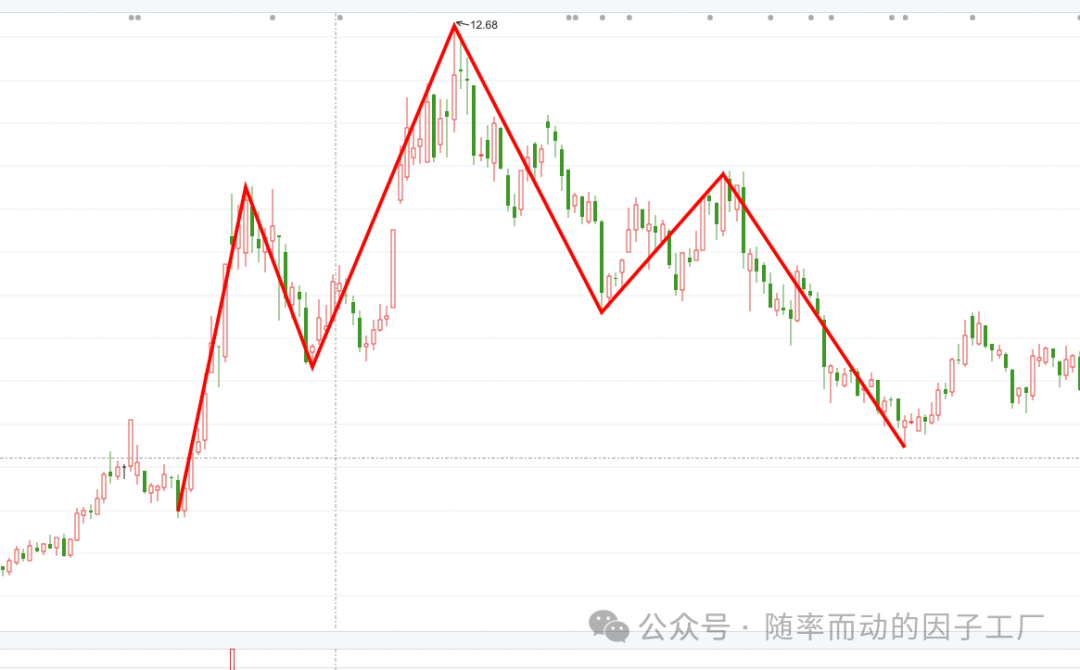
显然是由两个Z字形态构成。
- M头形态:
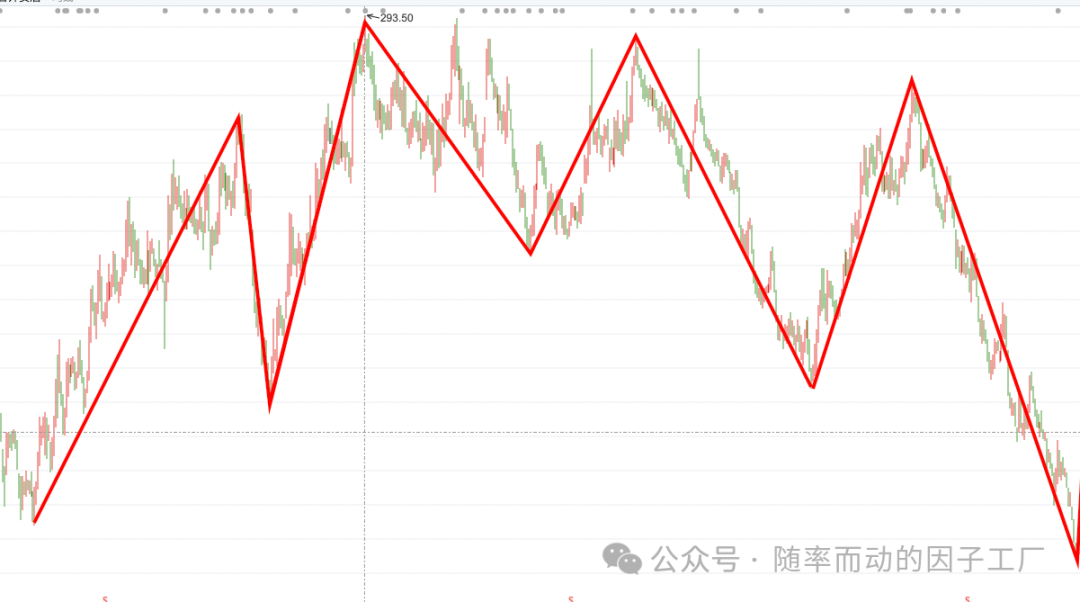
由多个Z字形态构成。
- 5浪上涨形态:
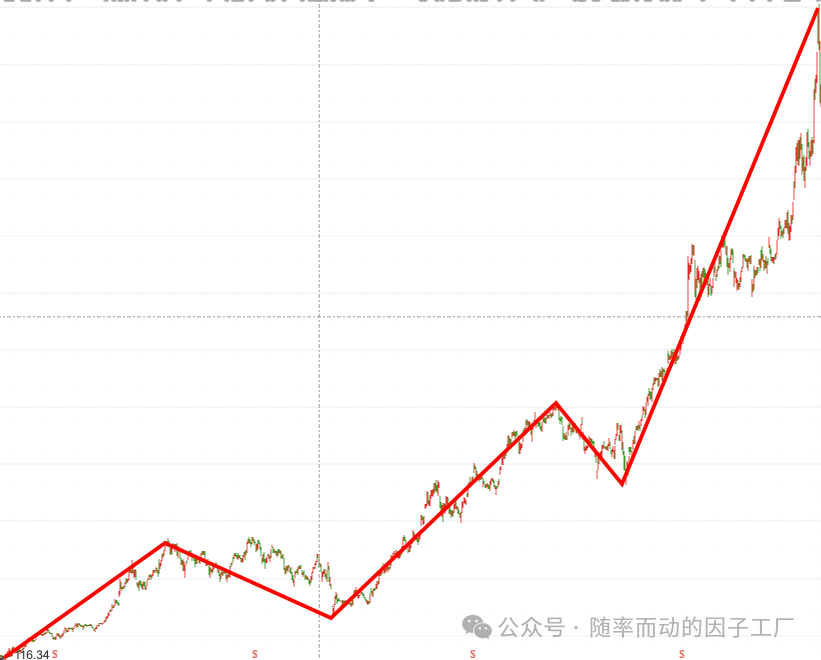
显然也是由Z字形波段构成。
其他形态不一一列举,相信你已经理解了“波段”的基本概念。
识别方法
技术分析中有一个普遍认同的观点:价格在空间上的变化,其重要性远大于时间上的变化。因此,在设计识别算法时,我们应更侧重于价格变化本身。
传统识别方法
目前最常见的相似性匹配策略,大多采用固定时间窗口,然后在历史数据中进行滑动匹配。
传统算法步骤:
- 将价格数据进行归一化或标准化处理。
- 在固定长度的序列空间中计算欧氏距离,或计算两者之间的相关系数。
传统方法的局限性:
- 窗口固定:固定的时间窗口限制了价格在空间上的变化幅度,导致基于欧氏距离的识别效果往往不理想。
- 时间错位:两个走势相似的波段,其高低点出现的时间位置可能不同,这会使欧氏距离计算失效,导致无法识别出本应相似的图形。
- 忽略相对位置:在技术分析中,Z字形波浪中各高低点的相对位置(例如高点是否依次抬高)至关重要,它直接反映了多空力量的对比。但传统欧氏距离方法并未对此做出明确判断。
接下来,我们将介绍一种能够有效解决上述问题的新识别方法。
新方法概述
新方法的整体流程如下图所示,参考并改进了券商研报的思路:

整个流程可以看作一个完整的 数据处理 管道,其目的是从嘈杂的原始价格中提取出清晰的波段拓扑结构。
第一步:布林带归一化处理
与传统识别技术直接对收盘价进行标准化不同,新方法采用布林带(Bollinger Bands)的上下轨对原始收盘价进行归一化处理,计算所谓的“%b指标”。
归一化的优点
相较于股票原始价格,%b指标具备以下优势:
- 趋势同步:指标趋势与价格变化同步,价格下跌时,%b同步下降,无延迟。
- 数值标准化:%b指标值通常标准化在-1至2之间,便于制定通用的数据预处理流程,有效减少股价波动的噪音干扰。
- 敏感放大:%b指标对股票波动有放大作用,能更敏感地检测波动,缩短关键点位确认的滞后时间。
计算方法
%b指标的计算公式为:%b = (收盘价 - 布林带下轨) / (布林带上轨 - 布林带下轨)
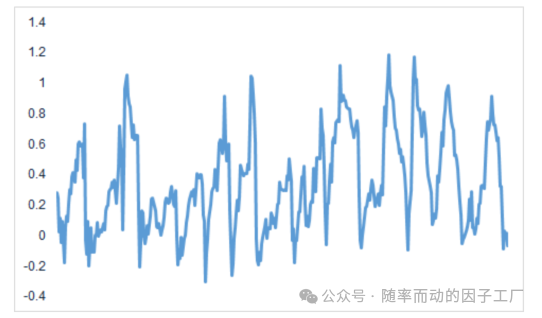
结果展示
原始价格序列经过布林带归一化处理后,得到%b指标序列,如下图所示:
第二步:确定高低点(ZIG分割)
经过第一步转换后,我们仍然无法清晰识别出符合条件的波峰和波谷。这就需要引入一个关键技术:ZIG分割。
可能有些读者认为ZIG函数涉及“未来函数”,但请注意,本文所述方法完全可以通过时间序列的逐步推进来剔除未来信息。请放心,所有算法和结论均不存在未来函数问题。
1. 具体计算逻辑
如下图所示:
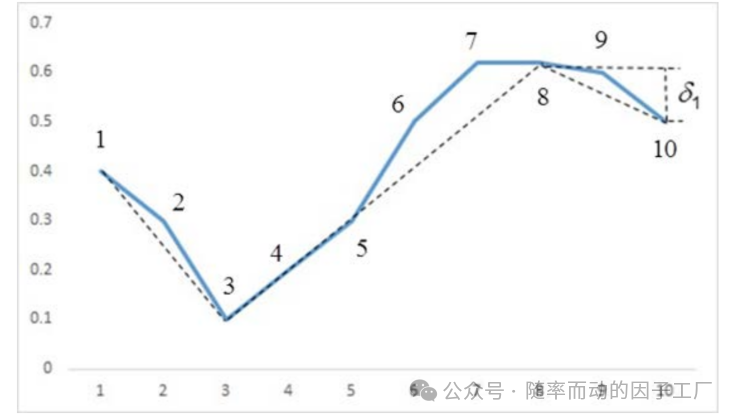
假设当前点为点3,我们以点3为起始点。若后续点位上涨,则向后移动,扩大观察窗口。点7和点8高度相同,我们取后一点(点8)作为高点。点9和点10均低于先前高点,当运行到点10时,该点到最高点(点8)的回撤距离超过了预设阈值(δ₁),因此我们确认点10为该窗口的终点,并在此过程中确定了高点(点8)。
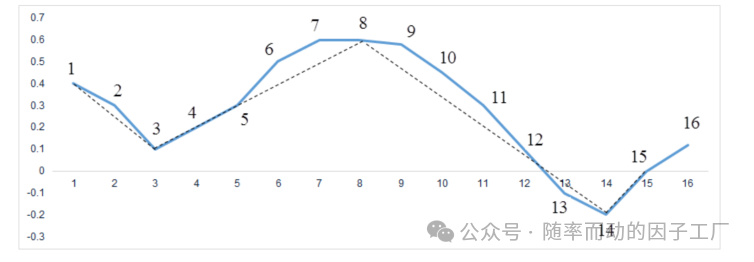
同理,点8将成为下一个分割段的起始点,开始新一轮的划分。最终,我们得到了一系列Z字形分割段。图中,点8到点10是为了确认一个潜在高点所需的时间窗口。经过完整的ZIG分割后,效果如下图:
2. 数学公式
给定当前窗口起始点 t_s,则该窗口的极值点 t_e(高点或低点)需满足:
P(t_e) 是当前窗口内的最大值(对于上涨段)或最小值(对于下跌段)。- 从
t_e 到窗口内后续某一点 t 的回撤(或反弹)幅度 |P(t) - P(t_e)| ≥ δ₁。
t_e 是满足条件1和2的最后一个点。
3. 效果展示
对%b指标序列进行ZIG分割后,得到的效果如下图所示:
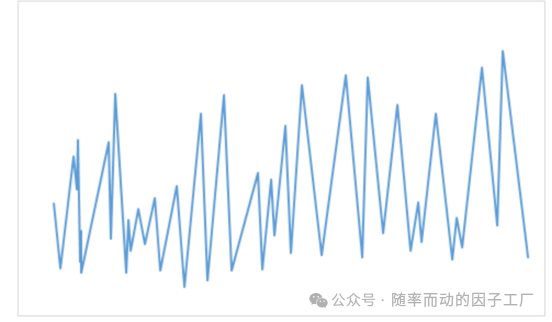
第三步:指标线的裁剪
即使经过ZIG分割,结果中仍可能存在一些幅度较小的“噪音”波动。因此,我们需要引入第二个阈值 δ₂ 进行裁剪。
裁剪规则:如下图所示,在上涨趋势中,若点4的高度高于点2,且点3相较于点2的跌幅小于阈值 δ₂,那么我们认为上涨趋势未被破坏,因此删除中间的点2和点3,直接将点1与点4连接。
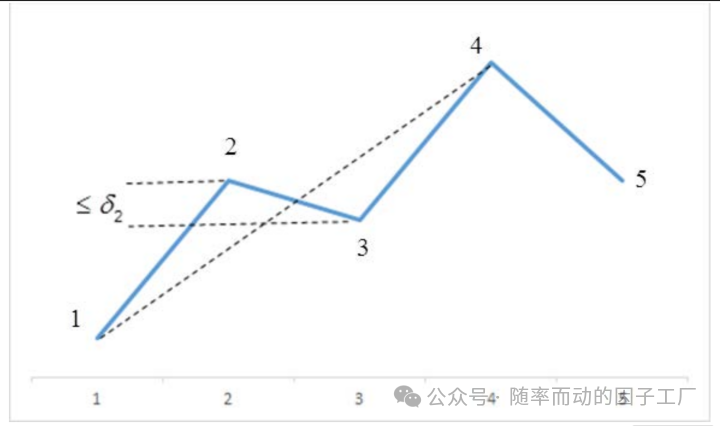
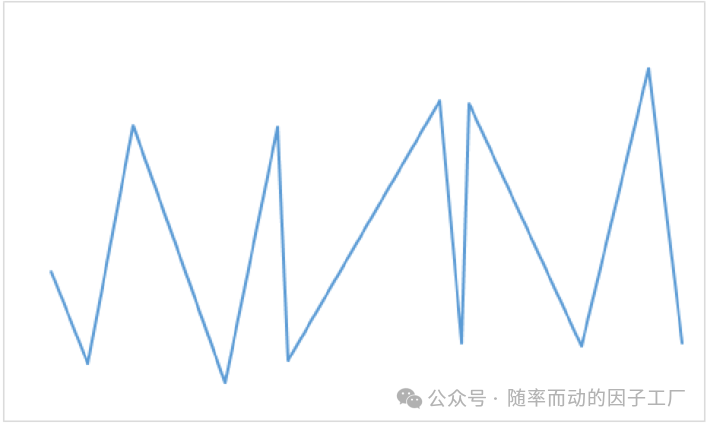
下跌趋势中的处理逻辑与此类似。经过这一步裁剪后,得到的形态线条更加清晰平滑:
第四步:原始价格数据映射与裁剪
我们将上一步裁剪后得到的%b指标转折点,通过其索引位置映射回原始价格序列,得到对应的价格转折点。
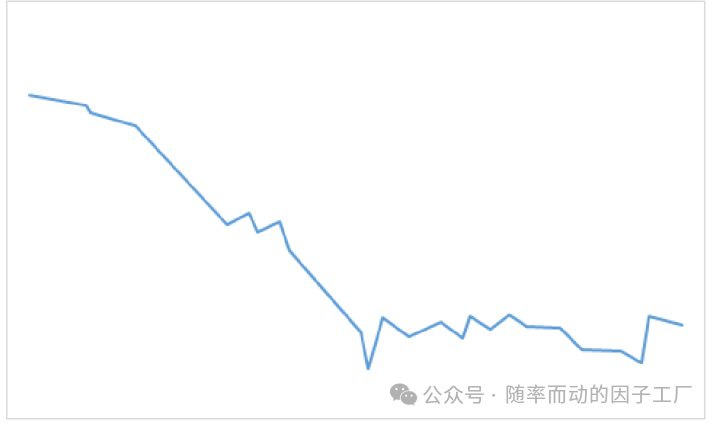
如图所示,映射后的原始价格转折点序列可能仍包含一些噪声。为了进一步净化信号,我们基于价格本身的幅度,再次应用类似的裁剪逻辑,最终得到清晰的波段结构:
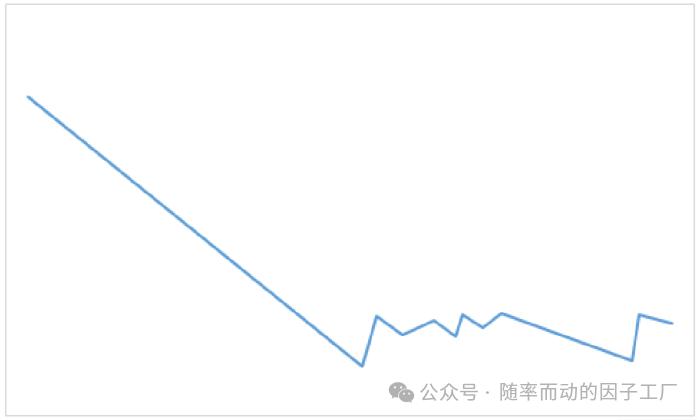
此时,价格的上升、下降波段一目了然。
流程总结
整个数据处理与波段提取的流程可总结为以下示意图:
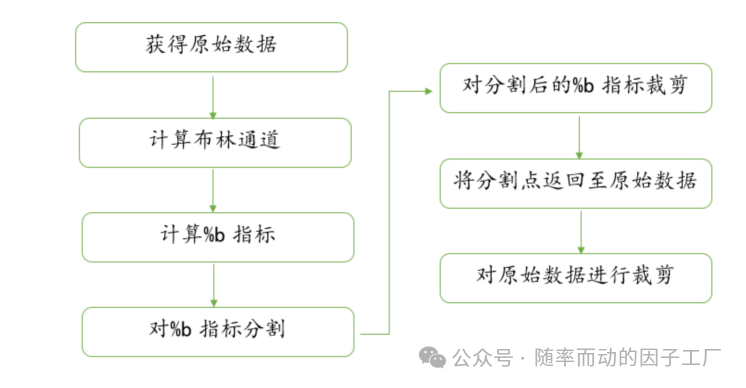
核心代码实现
以下是用 Python 实现上述数据预处理流程的核心代码,包括布林带计算、ZIG分割和裁剪函数。
import numpy as np
import pandas as pd
import plotly.graph_objects as go
from plotly.subplots import make_subplots
from typing import List, Tuple, Dict
import warnings
warnings.filterwarnings('ignore')
# ====================== 参数配置 ======================
BB_WINDOW = 20 # 布林带窗口
BB_STD = 2 # 标准差倍数
ZIG_THRESHOLD = 0.005 # ZIG分割阈值δ₁ (0.5%)
TRIM_THRESHOLD = 0.003 # 裁剪阈值δ₂ (0.3%)
SIMILARITY_GAMMA = 0.1 # 相似距离阈值γ
PREDICT_EPSILON = 0.005 # 趋势判断阈值ε
STOP_LOSS = 0.005 # 止损比例
LOOKBACK_WINDOW = 4 # 匹配波段长度(包含几个端点)
# ====================== 数据加载 ======================
def load_data(file_path: str) -> pd.DataFrame:
"""加载本地CSV文件,需包含日期、开盘、最高、最低、收盘"""
df = pd.read_csv(file_path, parse_dates=['date'])
df.sort_values('date', inplace=True)
df.reset_index(drop=True, inplace=True)
return df
# ====================== 技术指标 ======================
def compute_bollinger_bands(close: pd.Series, window: int = BB_WINDOW, std: int = BB_STD) -> pd.DataFrame:
"""计算布林带及%b指标"""
ma = close.rolling(window).mean()
std_ = close.rolling(window).std()
upper = ma + std * std_
lower = ma - std * std_
b = (close - lower) / (upper - lower) # %b指标
return pd.DataFrame({'close': close, 'ma': ma, 'upper': upper, 'lower': lower, 'b': b})
# ====================== ZIG分割与裁剪 ======================
def zig_segment(series: pd.Series, threshold: float) -> List[Tuple[int, float, str]]:
"""
ZIG分割:识别转折点
返回列表[(索引, 值, 类型)],类型为'peak'或'trough'
"""
points = []
if len(series) < 2:
return points
# 初始方向:由前两个点决定
idx0, val0 = 0, series.iloc[0]
idx1, val1 = 1, series.iloc[1]
direction = 1 if val1 > val0 else -1 # 1上涨,-1下跌
last_peak_trough_idx = idx0 if direction == 1 else idx1 # 暂存极值点索引
for i in range(2, len(series)):
val = series.iloc[i]
if direction == 1: # 当前在上涨段,寻找新的高点
if val > series.iloc[last_peak_trough_idx]:
last_peak_trough_idx = i
elif val <= series.iloc[last_peak_trough_idx] - threshold:
# 从高点回撤超过阈值,确认高点
points.append((last_peak_trough_idx, series.iloc[last_peak_trough_idx], 'peak'))
direction = -1
last_peak_trough_idx = i
else: # 当前在下跌段,寻找新的低点
if val < series.iloc[last_peak_trough_idx]:
last_peak_trough_idx = i
elif val >= series.iloc[last_peak_trough_idx] + threshold:
# 从低点反弹超过阈值,确认低点
points.append((last_peak_trough_idx, series.iloc[last_peak_trough_idx], 'trough'))
direction = 1
last_peak_trough_idx = i
# 最后一个点作为终点(类型根据方向推断)
if direction == 1:
points.append((len(series)-1, series.iloc[-1], 'peak')) # 若最后方向向上,终点为peak
else:
points.append((len(series)-1, series.iloc[-1], 'trough'))
return points
def trim_zig(points: List[Tuple[int, float, str]], threshold: float) -> List[Tuple[int, float, str]]:
"""
裁剪:合并幅度小于threshold的相邻波动
算法:循环检查相邻点幅度,若小于阈值则删除中间点
"""
if len(points) < 3:
return points
trimmed = points[:]
changed = True
while changed:
changed = False
i = 1
while i < len(trimmed)-1:
prev = trimmed[i-1]
curr = trimmed[i]
nxt = trimmed[i+1]
# 计算当前波动幅度
amp = abs(curr[1] - prev[1])
if amp < threshold:
# 删除当前点,连接前后
del trimmed[i]
changed = True
continue
i += 1
return trimmed
def get_price_waves(close: pd.Series, b: pd.Series, zig_thresh: float, trim_thresh: float) -> pd.DataFrame:
"""
完整数据处理流程:
1. 对%b做ZIG分割
2. 裁剪%b的ZIG结果
3. 将裁剪后的转折点索引映射回原始价格
4. 对原始价格再裁剪
返回带转折点标记的价格序列
"""
# 对%b分割
b_points = zig_segment(b, zig_thresh)
# 裁剪%b转折点
b_points_trimmed = trim_zig(b_points, trim_thresh)
# 提取索引
idx_b = [p[0] for p in b_points_trimmed]
# 构造原始价格序列的候选转折点(直接取对应索引的价格)
price_points = [(idx, close.iloc[idx], p[2]) for idx, p in zip(idx_b, b_points_trimmed)]
# 对原始价格再裁剪(由于映射后可能仍有小幅波动)
price_points_trimmed = trim_zig(price_points, trim_thresh * close.mean()) # 阈值转换为绝对价格
return pd.DataFrame(price_points_trimmed, columns=['idx', 'price', 'type'])
总结
本文作为波段识别系列的上篇,主要介绍了传统识别方法的局限性,并重点阐述了一种新方法的数据预处理全流程。该流程通过布林带归一化、ZIG分割和多级裁剪,有效地从原始股价数据中剔除了噪音,提取出了能够清晰反映价格运行本质的波段结构,为后续的形态相似性匹配与策略构建打下了坚实的基础。在接下来的中篇,我们将深入讲解基于此预处理结果的形态识别新算法。欢迎在云栈社区交流更多关于 技术分析与策略 实现的想法。
 发表于 2026-2-25 01:31:33
|
查看: 246|
回复: 0
发表于 2026-2-25 01:31:33
|
查看: 246|
回复: 0
