本文选择进行改进的因子,源自朱定豪和严佳炜老师在2020年2月27日发布的研报《市场微观结构剖析系列6——量价关系的高频乐章》。该研报共介绍了四个因子,笔者曾成功复现了其中一个,即“滞后一期对数收益率绝对值与成交额的相关性”,该因子在IC和分层回测上均有不错表现。
在复现文章的评论区内,有读者指出该因子稍作修改即可用于实盘。受到这条评论的启发,笔者决定对其尝试进行改进。
计算思想与代码实现
在之前复现的文章中,因子计算的是滞后一期对数收益率绝对值与成交额的相关性。众所周知,成交额与成交量相关性极高,由此构建的两个因子相关性可能接近1。
以往经验表明,将两个高相关性的因子相减,有时能产生效果更好的新因子。但为避免内容同质化,本次我们暂不采用此方法,而是尝试另一种思路:用换手率替换原始因子中的成交额。
具体的改进步骤如下:
- 使用换手率代替成交额。
- 借鉴《邪修!或许这才是换手率因子的正确打开方式,分层回测效果显著提升!》一文中介绍的方法对换手率进行处理(即进行行业市值中性化)。
- 对处理后的换手率数据,按照同一标的在过去21个交易日的同一分钟数据进行z-score标准化。
- 最后,计算滞后一期对数收益率绝对值与该标准化后换手率的相关性,得到新因子
tr_new。同时,我们也计算了与未经中性化处理的原始换手率tr的相关性作为对比。
以下是核心代码实现,主要分为数据读取处理和中性化计算两部分:
第一段代码主要负责读取分钟行情数据,并组织计算流程。其中的关键步骤是第19行,调用了 neutralize 方法对换手率进行行业市值中性化处理。
def process_single_day(self, idx):
file_name = self.files[idx]
date_str = file_name.split('.')[0]
cur = pd.to_datetime(date_str) + timedelta(hours=15)
if cur <= pd.to_datetime('2010-01-01') or cur >= pd.to_datetime('2026-01-01'):
return pd.DataFrame(columns=['tr', 'tr_new'])
# 加载当日分钟数据
full_path = os.path.join(self.file_pth, file_name)
data = BaseDataLoader.load_data(full_path, fields=['close'], codes=self.codes).to_dataframes()
ret = np.abs(np.log(1 + data['close'].pct_change().shift(1)))
tr_new, tr = [], []
for i in range(idx - 20, idx + 1):
file_name = self.files[i]
full_path = os.path.join(self.file_pth, file_name)
vol = BaseDataLoader.load_data(full_path, fields=['volume'], codes=self.codes).to_dataframe('volume')
cap = self.market_cap['circulating_cap'].iloc[i - 243]
cap = cap.values.reshape(1, -1)
self.tr = vol / cap
self.neutralize(idx)
tr_new.append(self.res)
tr.append(self.tr)
tr = pd.concat(tr)
tr['minute'] = tr.index.hour * 60 + tr.index.minute
tr = tr.groupby('minute', as_index=False, group_keys=False).apply(self.z_score)
tr_new = pd.concat(tr_new)
tr_new['minute'] = tr_new.index.hour * 60 + tr.index.minute
tr_new = tr_new.groupby('minute', as_index=False, group_keys=False).apply(self.z_score)
res = pd.concat([ret.corrwith(tr), ret.corrwith(tr_new)])
res.columns = ['tr', 'tr_new']
res['datetime'] = cur
return res
neutralize 方法负责执行行业市值中性化:
def neutralize(self, idx):
self.res = []
df = pd.concat([self.ind_data.iloc[idx - 1458], self.market_cap['market_cap'].iloc[idx - 243]], axis=1)
df.columns = ['ind', 'cap']
df.groupby('ind', as_index=False, group_keys=False).apply(self.__neutralize__)
self.res = pd.concat(self.res, axis=1)
需要注意:由于行业数据、市值数据和分钟行情数据的起始日期不同,在索引对齐时存在一个固定的偏移量(代码中体现为 idx - 1458 和 idx - 243)。
中性化的具体操作在 __neutralize__ 方法中完成,其逻辑是按照行业内部市值大小进行分组,然后在组内进行去均值处理:
def __neutralize__(self, group):
group.sort_values(by='cap', inplace=True)
start = 0
for q in [0.3, 0.7, 1]:
end = int(len(group) * q)
tmp_group = group.iloc[start:end]
codes = tmp_group.index.tolist()
self.res.append(self.tr[codes] - self.tr[codes].mean(axis=1).values.reshape(-1, 1))
start = end
因子评价
首先,我们看一下两个因子的相关性。从热力图可以看出,改进后的因子 tr_new 与原始换手率因子 tr 的相关性依然较高,超过了0.7。
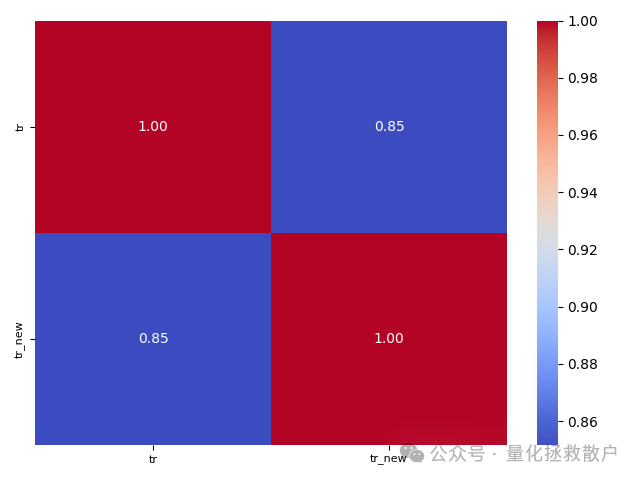
从后续的IC分析和分层回测结果来看,两个因子的表现差距并不悬殊。tr_new 因子的IC略高一点,而分层回测则是各有优劣。因此,下文将主要以 tr_new 的展示为主,tr 因子的分层回测结果将作为对比一并提供。
01 IC分析
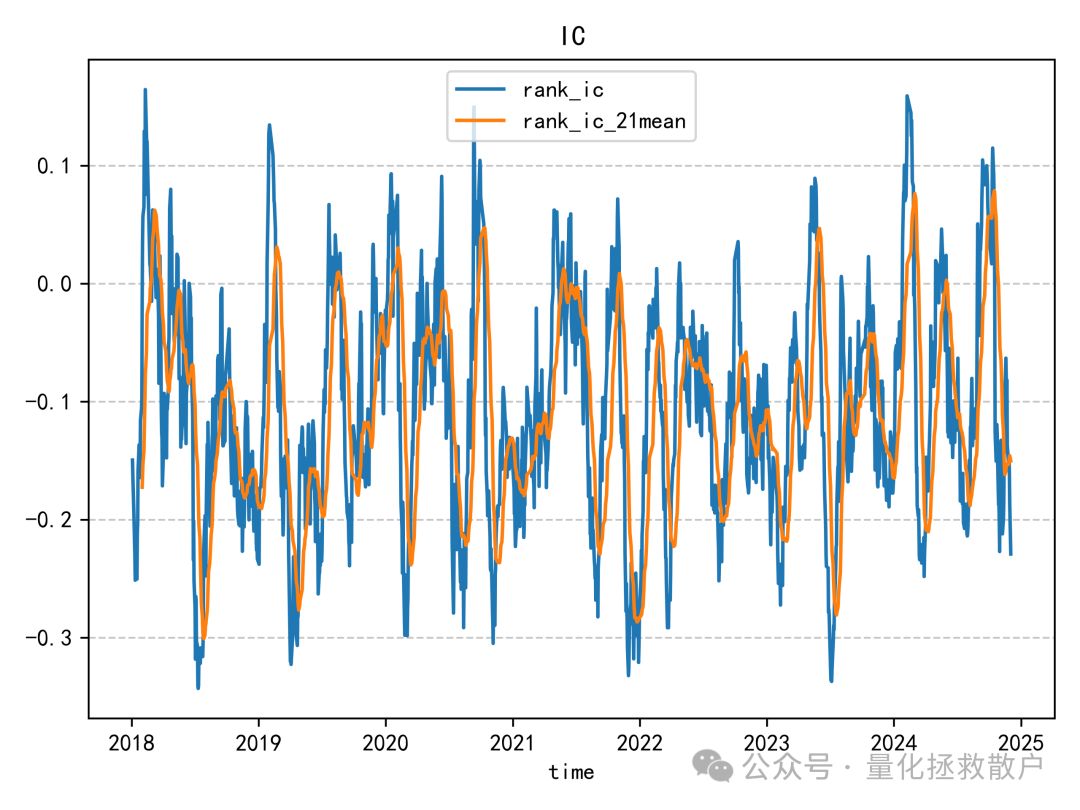

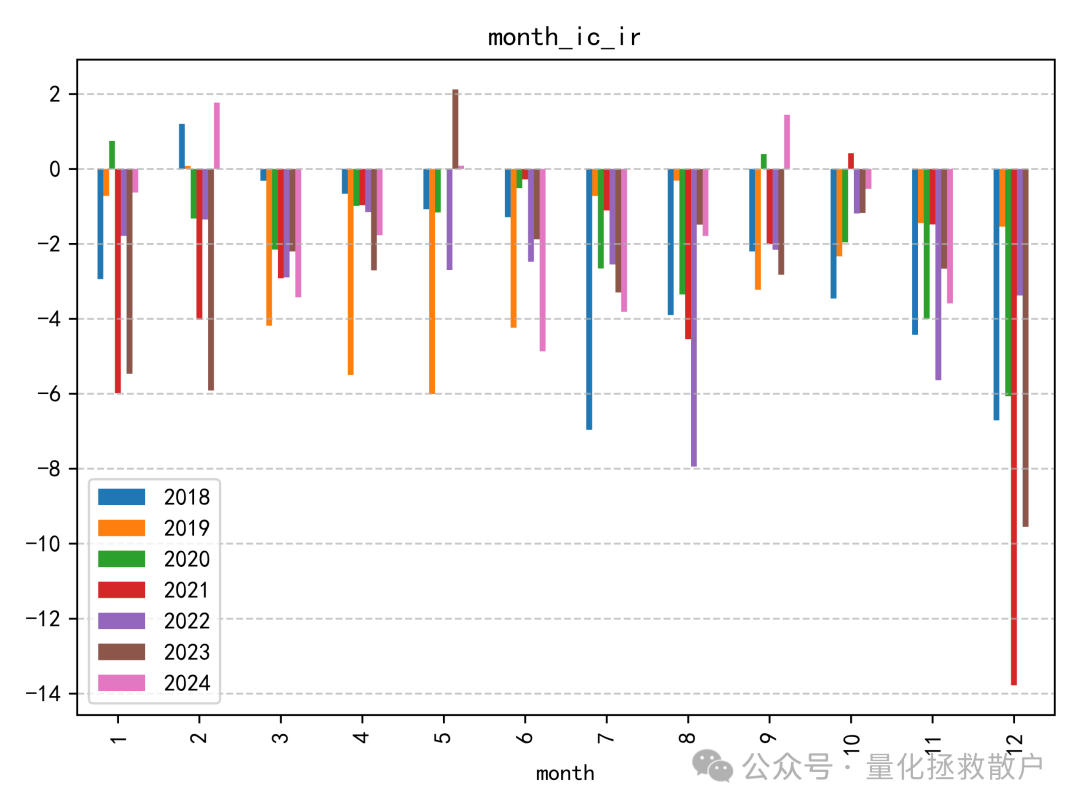
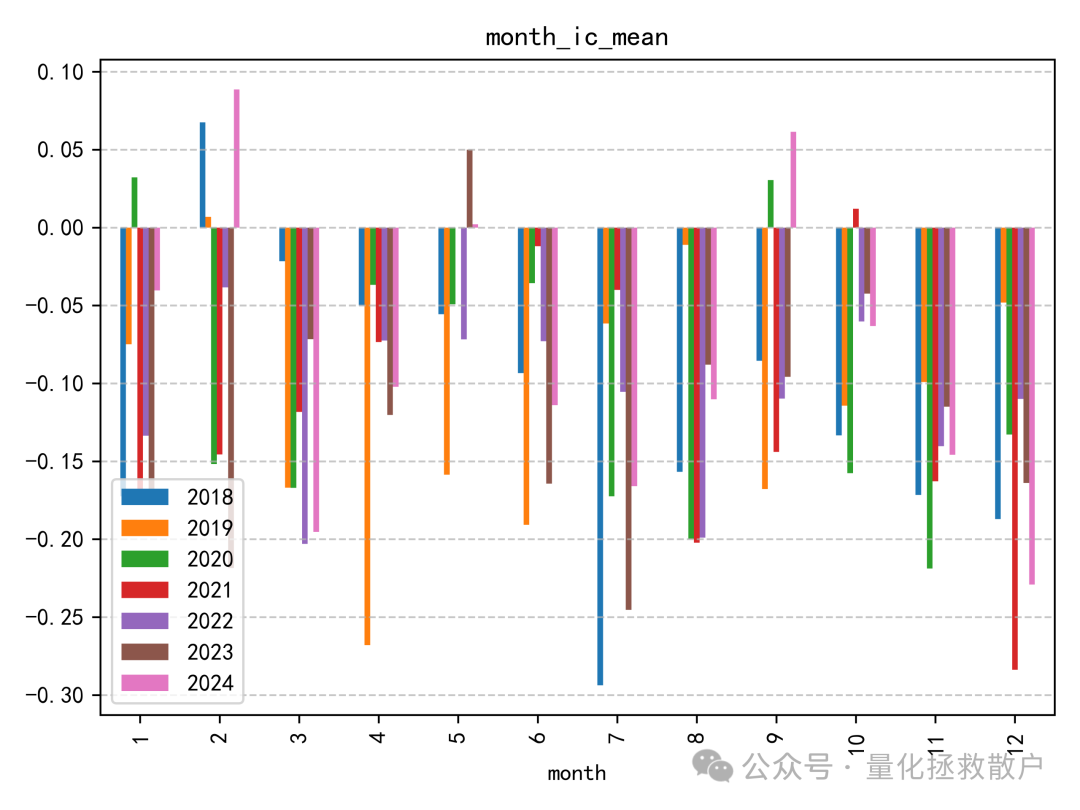
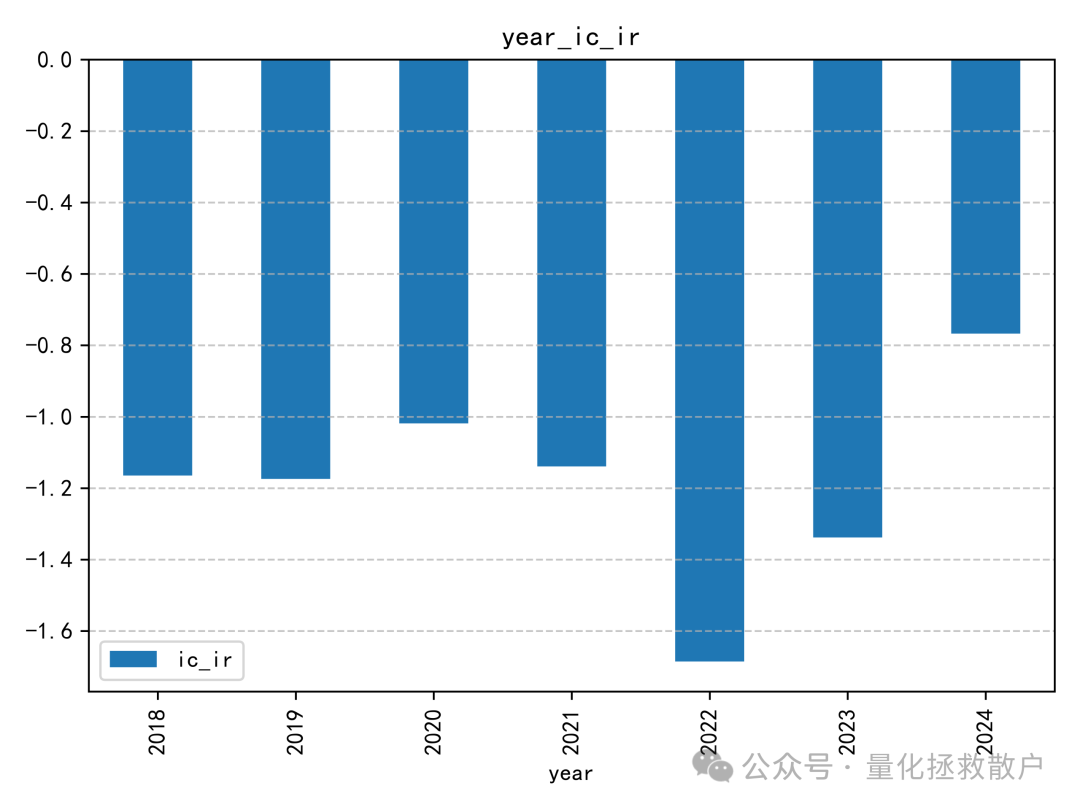
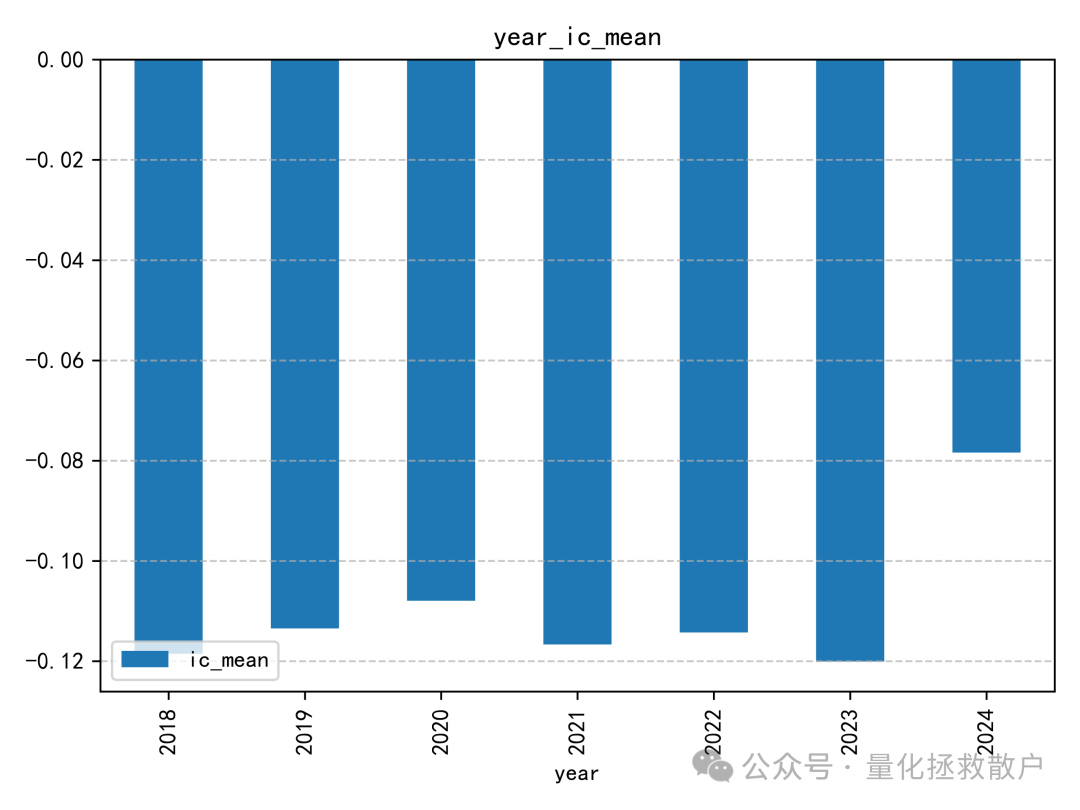
tr_new 因子的IC表现相当出色。在测试年份中,有六年的IC绝对值超过了0.1,其中一年甚至达到了0.12。即使在表现最弱的年份,其IC绝对值也接近0.08。作为对比,原始 tr 因子在2023年的IC绝对值距离0.12尚有一些微小差距。
02 回归分析
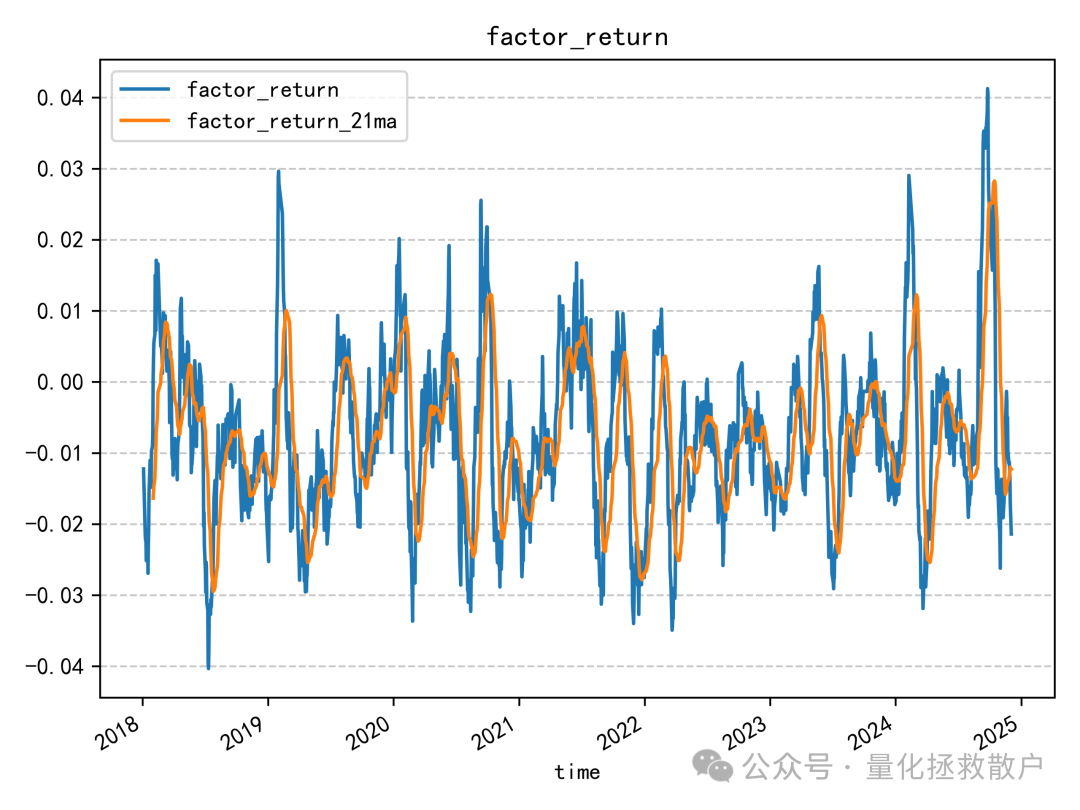
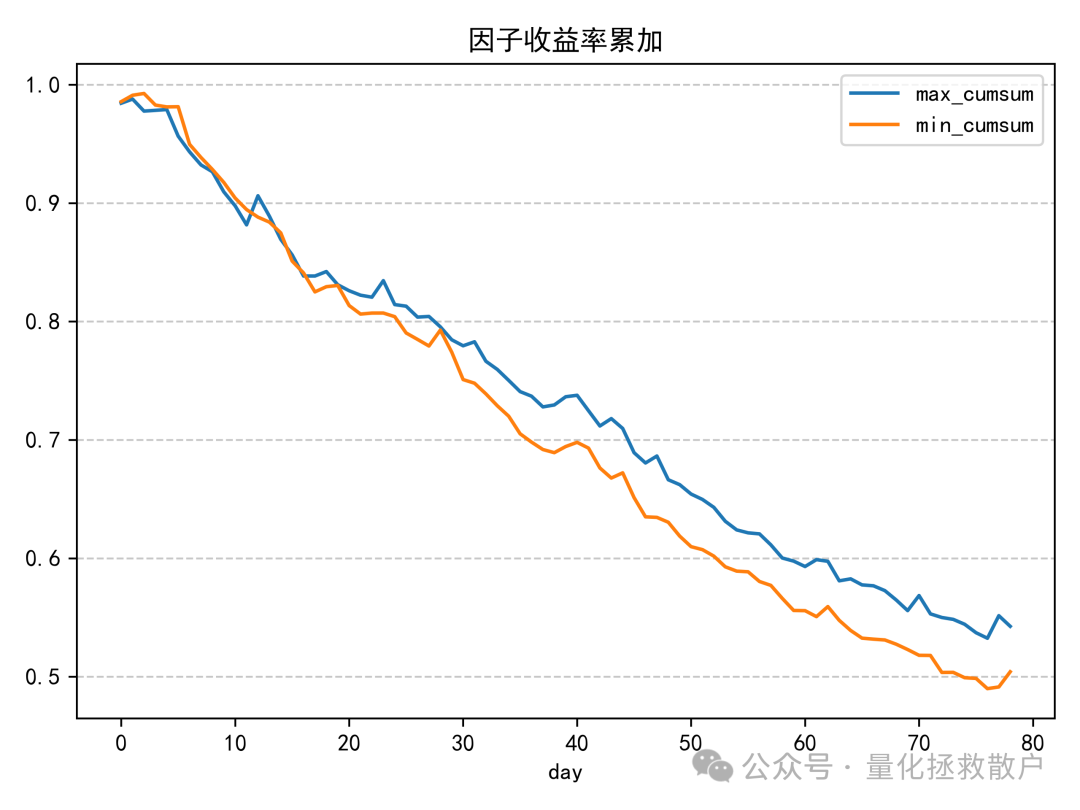
03 换手率分析
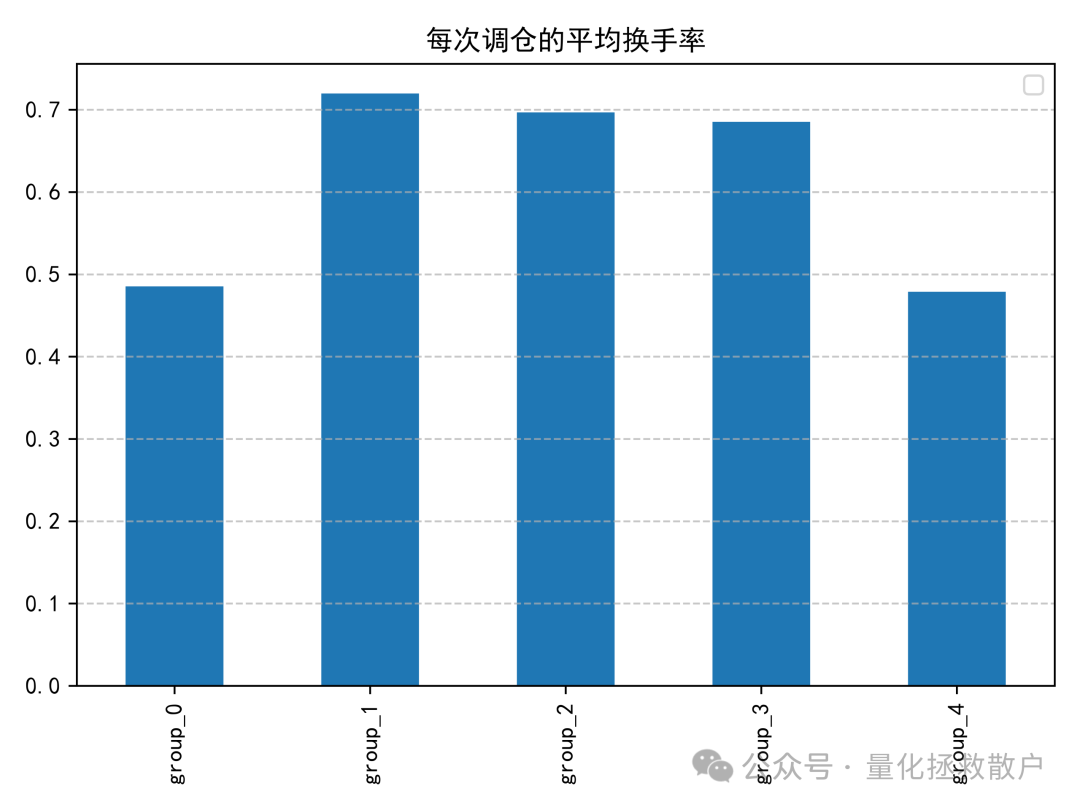
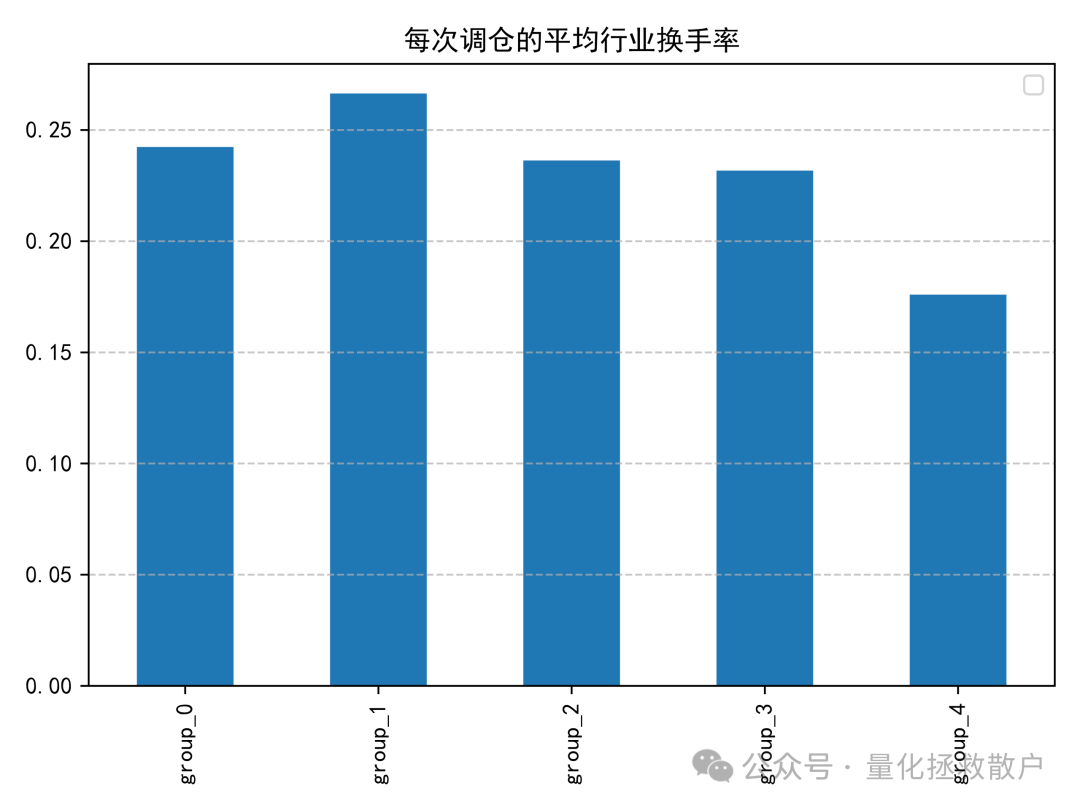
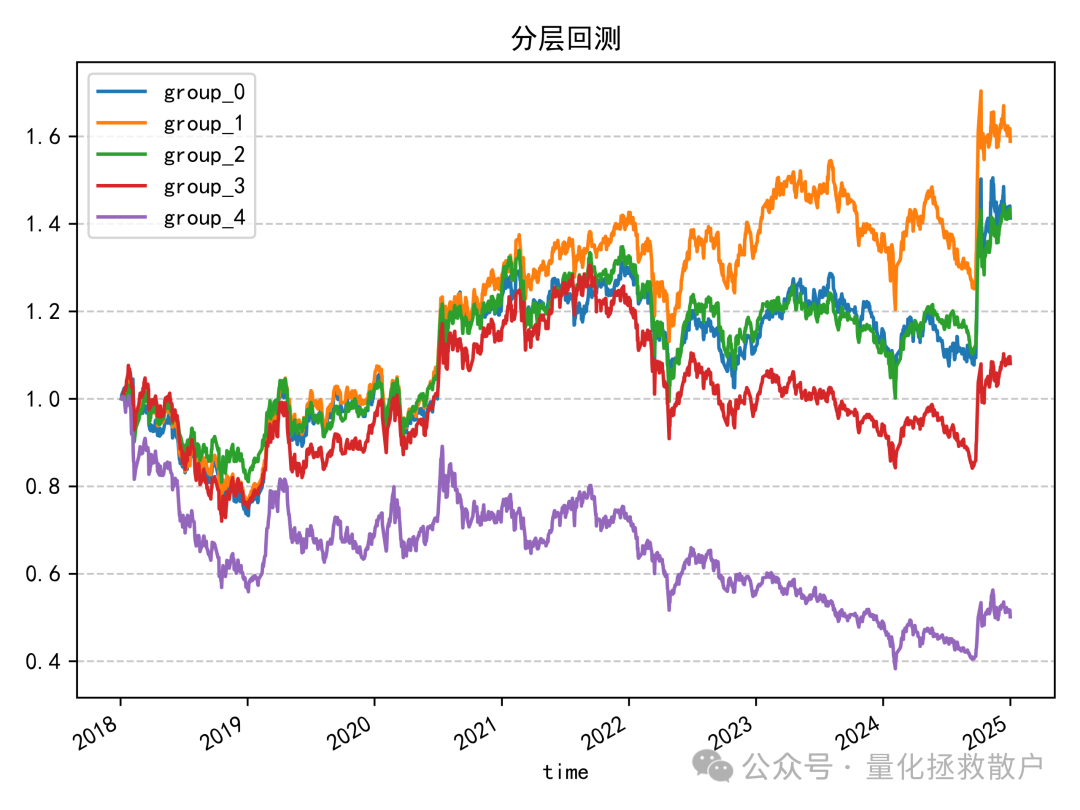
04 收益分析
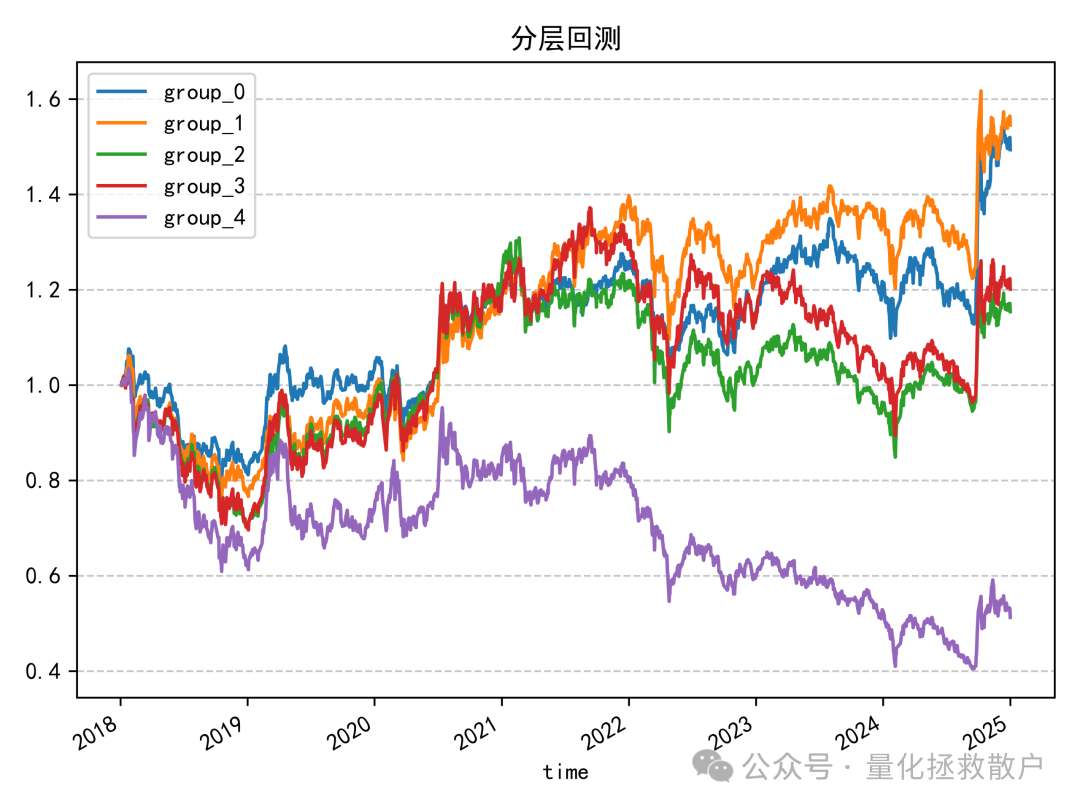
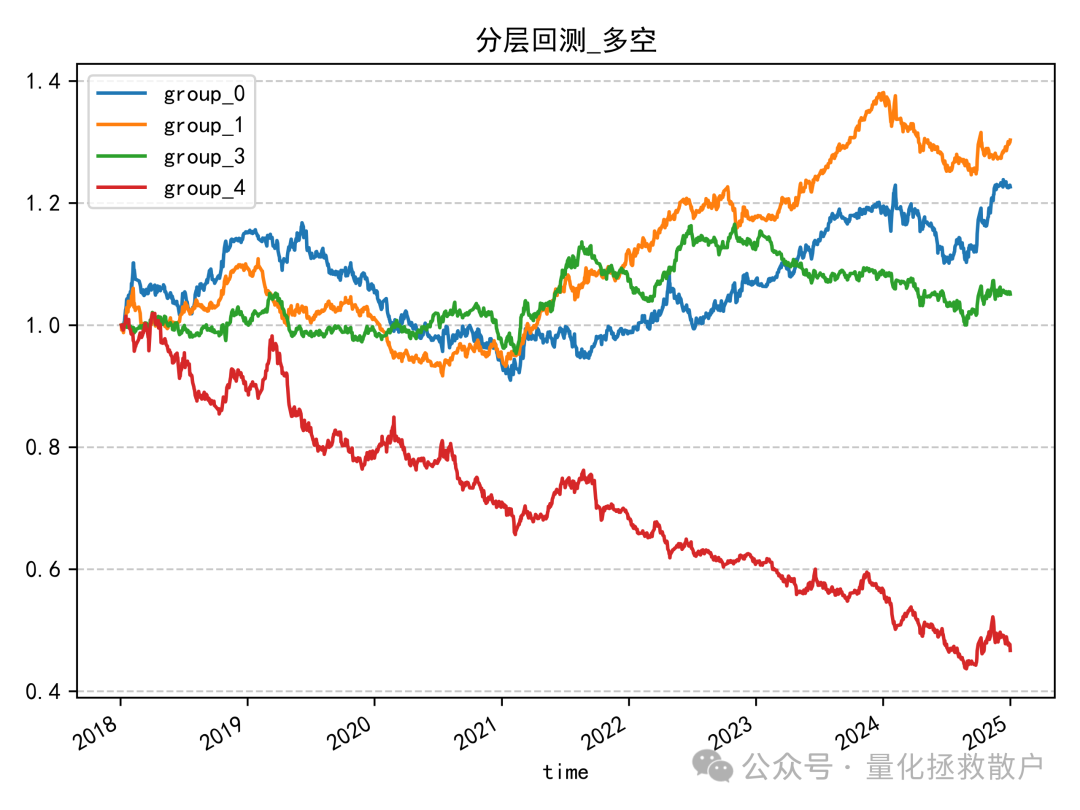
虽然 tr_new 因子在IC指标上表现突出,但其分层回测结果则略有遗憾,组别收益的单调性并非完美。
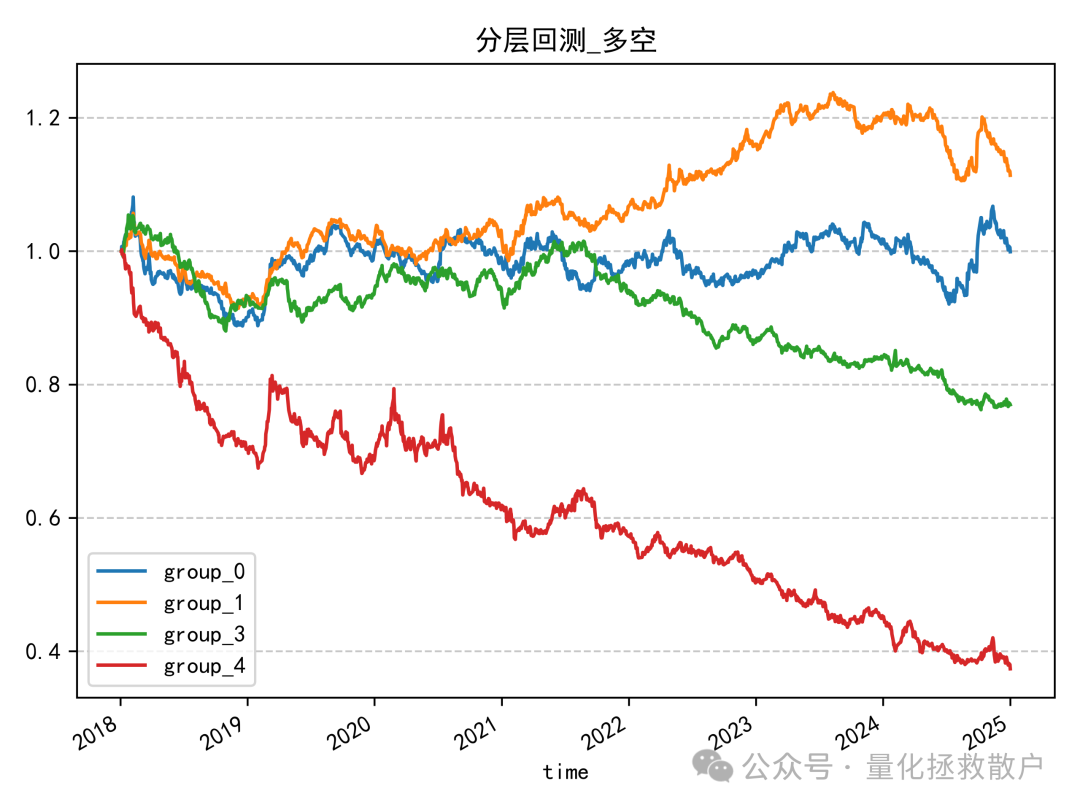
作为对比,原始 tr 因子的分层回测表现如下。它的优势在于多头组(蓝线)与次优组(黄线)的收益差距相对较小,但其单调性同样不理想,最低分组(红线)的年化收益看起来超过了中间组(绿线)。
总结
本次改进通过引入换手率并进行行业市值中性化及标准化处理,构建了一个新的量价关系因子。该因子在IC表现上取得了显著的提升,连续多年IC绝对值超过0.1,证明了其在预测能力上的稳定性。然而,其在分层回测中展现的收益单调性仍有优化空间。这再次说明了因子研究是一个多目标权衡的过程,出色的IC是基础,但如何将其转化为稳健的策略收益,还需要在组合构建、风险控制等方面进行更深入的探索。希望本次关于数据处理和因子构建的分享,能为你在量化交易与数据科学领域的实践带来一些启发。欢迎在云栈社区交流更多想法。
 发表于 2026-2-14 02:22:05
|
查看: 306|
回复: 0
发表于 2026-2-14 02:22:05
|
查看: 306|
回复: 0
