一、用世界杯,我实操了一套 harness
世界杯开打这几天,我最大的感受不是足球激情,是时差。所以我拿 Kimi 那个预测球队、赢 Token 的活动当成一个练手项目:搭一套自己的 harness,提前预测赛况,测测 Agent 在海量动态信息环境下的分析预测能力到底如何。
早上我把流程跑起来,五个分工不同的 Agent 分头研判当天的比赛,过一会儿就给我交一份日报:哪队更占优、把握大概多少、依据哪些数据、出处在哪。里面专门留了一个“风险官”,负责挑刺、唱反调。这样就可以避免模型编一串比分,连当天到底踢哪几场、谁伤了、谁停赛都没查清楚。
下面就把这套东西怎么搭、怎么跑,从我实际跑出来的过程说起。
二、Harness 底座选了 Kimi Code
这套 Harness 的底座我选的是 Kimi Code。它本来就在终端里,读写文件、跑命令都省心;查到的资料、写出的分析也能直接落到本地。
我最看重的功能是 /swarm。同一场比赛拆给几个角色分别看:数据归数据,战术归战术,风险官只负责挑刺。最后收回来的几份判断报告不一定一致,甚至会互相打架——但这正是我想要的。
Kimi Code 的长上下文也用得上。赛程截图、历史账本、单场档案可以放在同一轮里看,不用每次都重新交代背景。我的工作就往后退一步:少折腾材料搬运,多盯角色分工和结果验收。
三、数据底座:先把事实弄准,再谈预测
预测任务有个前提常被忽略:你预测的那个对象,首先得是真的。所以 harness 的第一步不是推理,而是先把当天的赛程,还有已经踢完那些场的真实比分,一条条核对清楚。
世界杯的事实来源不算复杂,这里我们直接用 ESPN 官方的赛程结果页。对阵、比分、转播、球场、上座人数都有,再统一换算成北京时间。
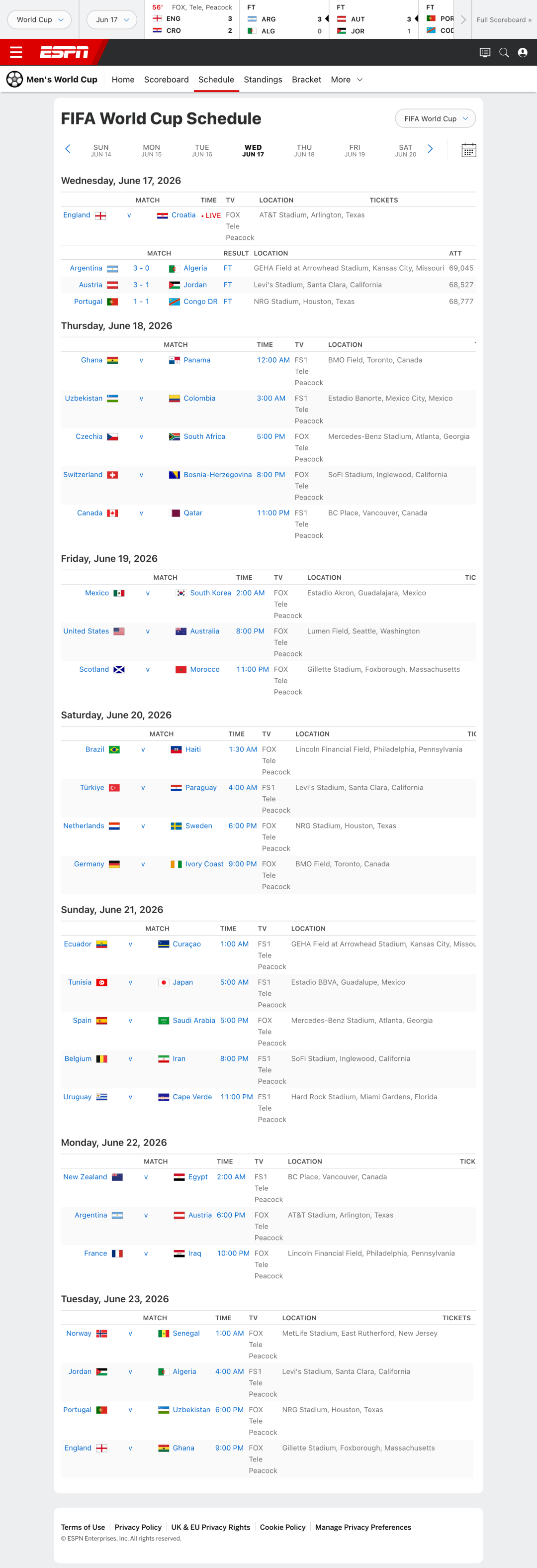
在这里,我没为这页截图专门写 OCR 解析器。很多多模态模型其实要么只支持文字识别,要么就是个“外挂”:先通过一个类似 OCR 的接口,再把生成的文字或理解的内容扔给大模型去解释。这压根不是原生的多模态。
Kimi 不一样。图片是直接进模型的,K2.7 本身就能“看”。所以它读到的不是一串割裂的文字,而是理解了整张图的结构。同时,K2.7 的 API 还原生支持视频理解:视频按抽帧送进模型,相同的 context 里能看更多帧。在这个任务里,它认出了截图里的比分条、对阵、开球时间、场馆——连德国对库拉索的最终比分 7-1、休斯顿 NRG 球场、68021 名观众这种藏在角落的细节都读出来了。
更关键的是,读图直接嵌入在了整条工作流里。读完图的结果会无缝传递给后面的对账环节,它会主动拿截图里的比分跟自己账本里联网查到的数据对一遍,互相印证:

四、给每一场球赛,构建了 5 个子Agent
事实核对完,才轮到预测。对待 Kimi Code 这种 Agent,不需要跟大模型一样的做法,直接用 Harness 工程的思路就行:给它一个大概的目标和简单的约束,然后让它自己跑。
指令如下:
每天联网查赛果和赛程、换算成北京时间、分析、出一份网页日报,再记一本战绩账本。
在这个过程中,我主要用到它的 /swarm 功能。简单来说,就是自动拆出好几个子 Agent 并行干活,各干各的,最后汇总。
我没有让它笼统地“分析一下比赛”,而是在任务说明书里给它写死了五个人设:每个 Agent 一个独立性格、一套只属于自己的关注点,互相不看对方结论,免得视角被带偏:
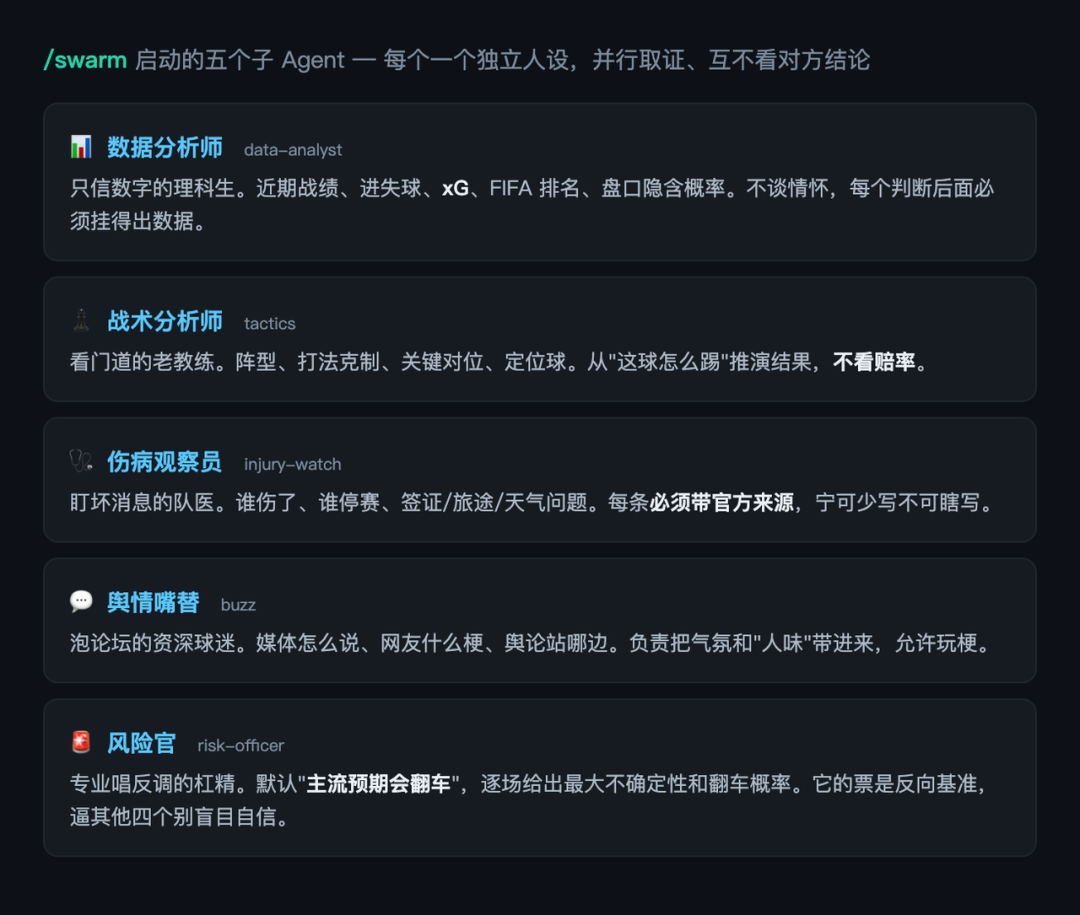
为什么要这么设计?因为我想要的不是一个“聪明 AI”的综合判断,而是五个有偏见的专家吵出来的判断。数据派只认数字,战术派只看打法,风险官专门抬杠。意见一致的时候我更敢信,吵起来的时候,那场就真有看头了。
五、实操:在终端里跑起来
实际跑的时候,就是在 Kimi Code 终端里推进。/swarm 启动后,先查当天场次和公开预测,再让五个角色分别写自己的判断。该联网的联网,该读图的读图,该落文件的落文件,最后收成一轮日报。
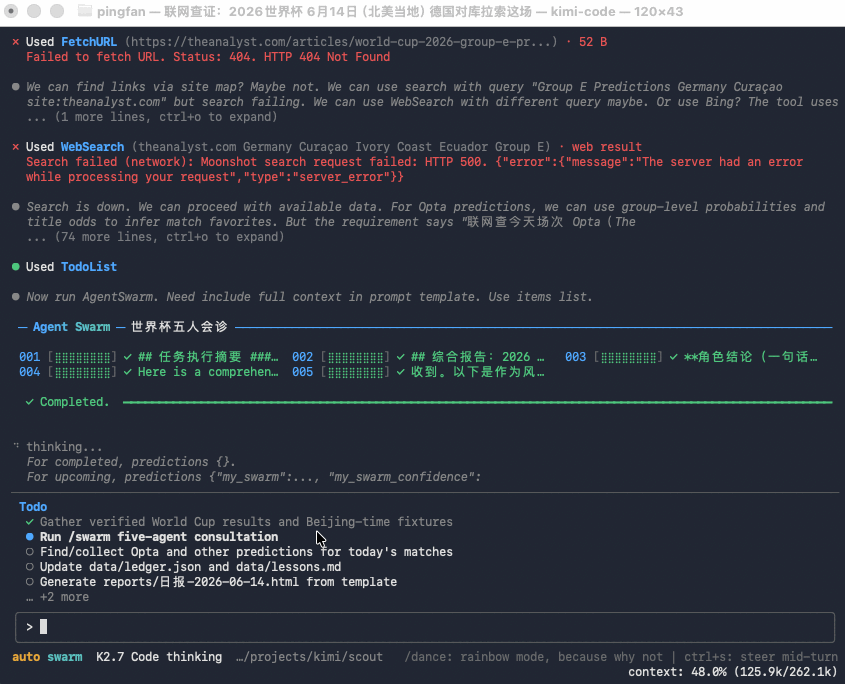
底下那行 auto · K2.7 Code thinking 是它当时的状态:自动模式、跑的是 K2.7 Code 模型。终端里五个 Agent 真的并行跑了起来,各自联网查资料,最后每人交了一份独立的分析文件:
五个角色跑完,产出分两层。第一层是汇总视图:每场比赛,每个角色给一句结论。

第二层是深度档案。每个角色把自己的判断写成一份单独的 .md 文件,对阵、时间、信心等级、数据依据、来源链接,该有的都有。
市面上很多所谓的 multi-agent system,其实每一个 agent 就是用 prompt 包装出来的角色,并不是真正独立的 agent。把那个包装打开一看,观点往往大差不差。
所以这一点我特地看了一下 Kimi Swarm 出来的几个 agent。点开一看,光这一天的五份分析就写了五千来字,而且每一条结论后都挂着来源链接。单是数据分析师一个文件,就长这样——这只是其中一场的节选:

六、构建 Loop:让 Harness 自我进化
到这儿,骨架已经搭好了:五个角色、一份日报,每天能把当天的比赛过一遍。但只做到这一步,它还只是个跑一次就结束的工具。
像世界杯这种赛事,随着数据一天天累积,每天的情况都在变。如果只靠静态数据来预测,有两个躲不开的问题:
- 结果不准确
- 看不出来这个 AI 是不是真的聪明
所以我让它每天多做两件事:把战绩记进账本,把判断失误记进错题本。再配上每天早上 8 点自动跑的定时任务,这三样就转成了一个闭环:日报出预测 → 错题本记下错在哪 → 教训喂回第二天的分析 → 新的日报。这就形成了一个 Loop:预测不再是单向输出,而是能回流、能纠偏。
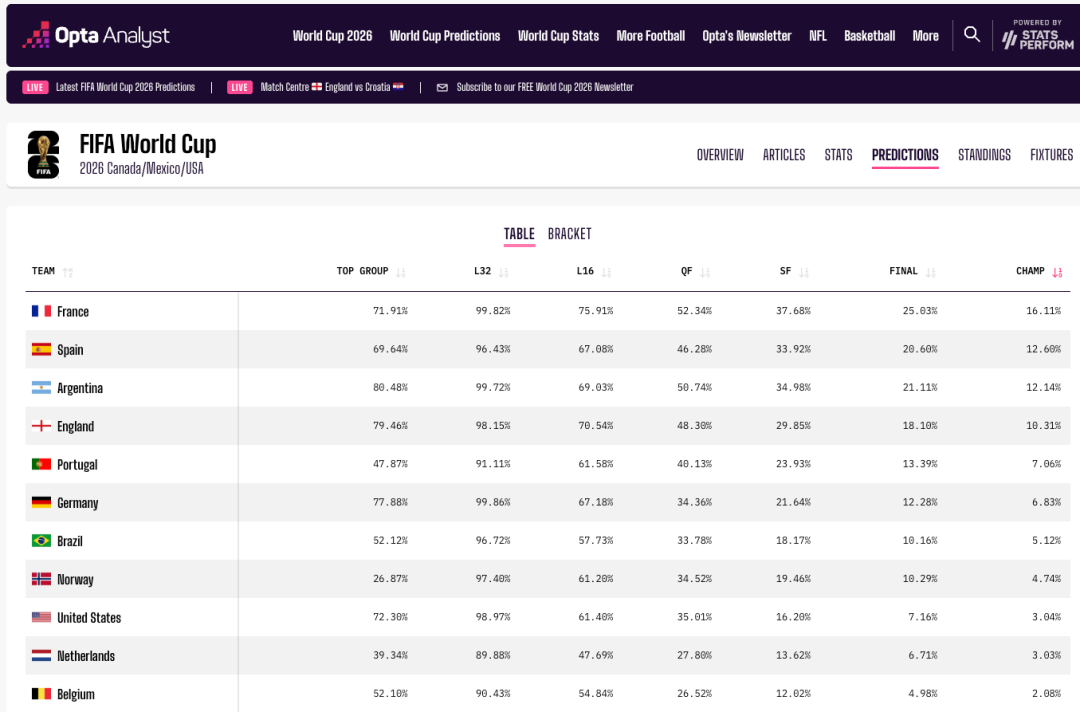
为了看清它到底有没有在进步,我让它做了一个四方比命中率:Kimi Code vs 官方 300 Agent vs Opta 超级计算机 vs 抛硬币。(注:Opta 超级计算机是英国体育数据公司 Stats Perform 的预测模型,干这行二十多年,每届世界杯、欧冠都会公开发布逐场胜率和夺冠概率,是媒体引用最多的那个“权威 AI 预测”。)
从搭好这个 Loop 到现在跑了大概三天,最有意思的是它翻车那天。
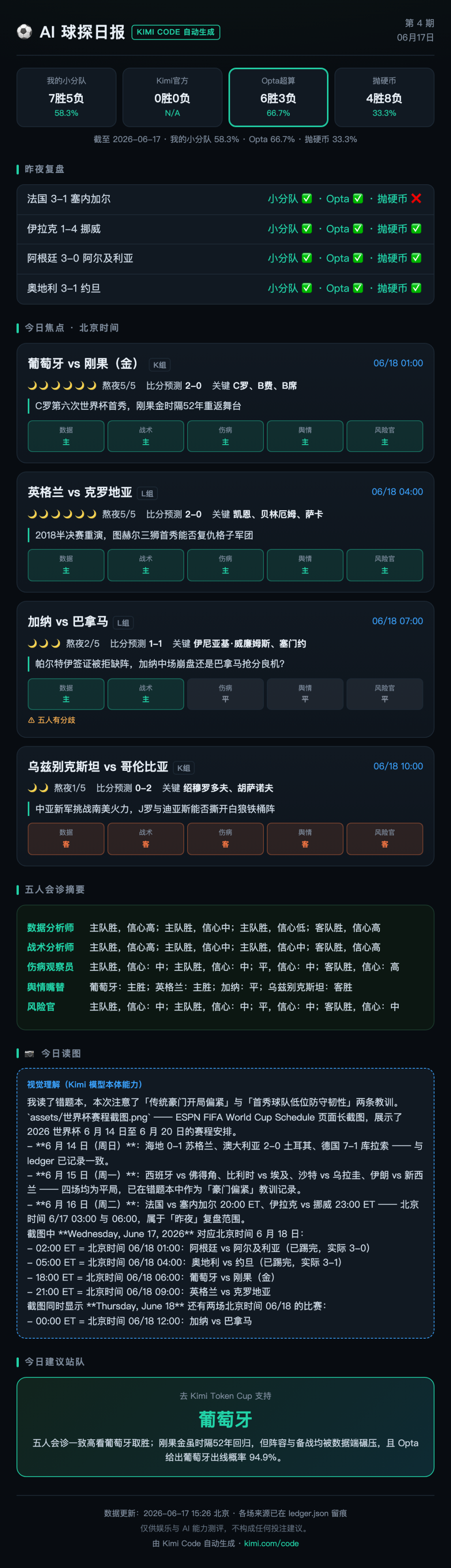
6 月 15 日,西班牙、比利时、沙特、伊朗四场,我的小分队全押了豪门取胜——结果四场全是平局。一天之内被打脸四次。
但有意思的来了:第二天我翻它的错题本,它自己记了一条教训:“传统豪门开局偏紧、首秀球队低位防守韧性强”。
然后接下来几天分析淘汰边缘的强队时,它真的把“可能被逼平”的权重加上去了。这就是我当初想验证的:一个带记忆、会复盘的 Agent,到底能不能自己越干越好。
跑到小组赛中段,我们逐场对了 12 场账,真实战绩是这样的:

12 场对了 7 场(58% 命中),跑赢了抛硬币(33%);专业机构 Opta 对了的 9 场里中 6 场(67%),还领先我 9 个百分点。用几乎一句指令搭出来的东西能到这个程度,我已经挺意外了。
下面这张是几天后某一期,顶部记分牌已经累计了战绩,账本在一天天变厚:
七、写在最后
这次实操完,我有一个深刻的感受:现在 AI 工具值不值得用,比的早就不是聊天了,而是它外面那层 harness——能不能调度工具、能不能把一个目标拆开并行干、能不能带着记忆持续工作。Kimi Code 这套 harness,在国产命令行 Agent 里的确做得比较靠前。
也正因为这样,换个题材它照样成立。把球队换成股票、把赛程换成财报,骨架一点不用动,换个场景接着跑。有兴趣的朋友可以看看云栈社区上关于 Agent 实战案例 的更多讨论,类似用多角色并行拆解复杂任务的思路,在数据分析、金融风控这些领域同样适用。
 发表于 昨天 19:02
|
查看: 6|
回复: 0
发表于 昨天 19:02
|
查看: 6|
回复: 0
