
Google 自己的页面上,出现了一行不该出现的字。
“3.5 Pro coming soon。”
就这么几个英文单词,让整个开发者圈子炸了。因为这个标签出现的位置,是 Gemini 3.1 Pro 的产品卡片上——Google 自己的 App 里,赫然标注着下一代旗舰模型即将上线。
一个还没发布的产品,被自家前端工程师提前剧透了。
Google 自己“出卖”了自己
事情要从 2026 年 5 月 15 日说起。那天,36Kr / 新智元率先报道了一条消息:一个代号“Cappuccino”的 Gemini 模型 checkpoint 已经开始在社区和 benchmark 平台上出没。
社区前几个小时还在讨论 Gemini 3.2,结果泄露直接跳到了 3.5。
四天后的 Google I/O 大会上,Sundar Pichai 亲自登台,正式介绍了 Gemini 3.5 家族——但只发布了 Flash 版本。
当他抛出“Pro 版本将在 6 月推出”时,台下传来了清晰可闻的叹息声。
666,堂堂 Google I/O,观众嘘自家 CEO,这场面确实不多见。
但泄露归泄露,该有的东西一样没少。从目前已知的信息来看,Gemini 3.5 Pro 有三个关键参数值得关注:
- 200 万 token 上下文窗口 —— 当前所有量产模型中最大的,是 GPT-5.5 和自家 Flash 的两倍
- Deep Think 推理模式 —— 专门啃硬骨头的深度推理能力,继承自 Gemini 3 Deep Think
- 全模态输入 —— 文本、图像、音频、视频一个 API 全搞定
两百万 token 意味着什么
两百万 token 是什么概念?
一个中等规模的代码仓库,大概 50 万到 100 万 token。一份完整的项目文档加 API 参考手册,大概 20 万到 50 万 token。
再加上几十轮对话历史和需求文档——200 万 token 基本上能把一个中型项目的“全部上下文”一次性塞进去。回顾这个时间轴,从 2024 年的 200 万预览到今天的量产,Google 用了两年时间把概念变成产品。
这意味着什么?
本质上,你可以把整个代码库丢给 AI,让它在完全理解项目全局的情况下帮你写代码、查 bug、做重构。不用 RAG 拆分,不用检索增强,不用担心它“看到前面忘了后面”。
666,说实话,这对做 RAG 的公司来说可能不是个好消息。
当然,200 万 token 的“纸面参数”和“实际可用”是两码事。Gemini 3.1 Pro 官方标称 100 万 token,但社区测试发现 Gemini Web App 实际只能访问大约 3.2 万 token 的活跃上下文。
3.5 Pro 的 200 万能不能真的跑满、跑到深处还能保持召回质量,得等独立评测出来才知道。
从纵向时间轴来看,Google 在上下文窗口这个赛道上一直是最激进的那个。 从 2024 年 Gemini 1.5 Pro 首次把 200 万 token 摆上台面,到 2026 年 2 月 3.1 Pro 做到 100 万量产,再到今天 3.5 Pro 直接翻倍——这条时间线从来没变过。回头看,上一代 3.1 Pro 的 100 万已经让很多人觉得够用了,但 Google 显然不这么想。
Google 为什么选择“拖”
按理说,既然连泄露都有了,直接发布不就完了?
Google 偏不。
为什么是 now?Flash 已经把 Pro 的风头抢了。3.5 Flash 比 3.1 Pro 快 4 倍、便宜 40%,在几乎所有 benchmark 上都超越了前代旗舰。
定价只有 1.50 美元/百万输入 token,对比 Pro 预计的 15 美元——整整十倍差距。
问题来了:如果 Flash 已经这么强了,Pro 到底该怎么定位?
答案是:Pro 要做的事情,Flash 做不了。
TechTimes 的分析指出,3.5 Flash 在编码和 agent 任务上确实超越了 3.1 Pro,但在最难的推理任务上出现了回退——而这恰恰是 Pro 要补的缺口。
Google 需要时间让 Pro 在 Deep Think 模式下跑出足够亮眼的成绩,才能说服开发者为什么值得花十倍价格。
再加上 OpenAI 有 Codex、Anthropic 有 Claude Code,开发者的心智已经被分走了不少。Google 需要的不只是一个“参数更大的模型”,而是一个“能改变开发者工作方式的产品”。这就是底层机制层面的竞争——不只是比参数,而是比谁能把模型变成开发者离不开的工作流。
三巨头的上下文窗口军备竞赛
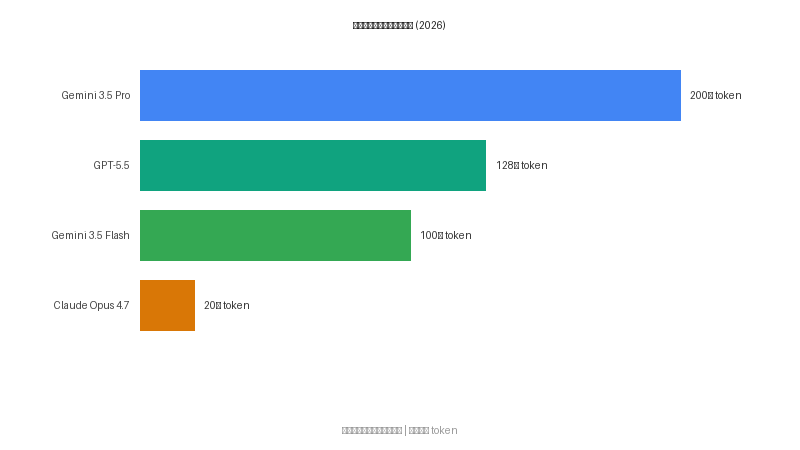
把目光拉远一点,沿时间轴看看当前三大模型的上下文窗口对比:
| 模型 |
上下文窗口 |
定价(输入/输出 每百万 token) |
状态 |
| Gemini 3.5 Pro |
200 万 |
预计约 108 元/约 432 元(约 15/60 美元) |
企业预览,6 月底 GA |
| Gemini 3.5 Flash |
100 万 |
约 10.8 元/约 64.8 元(1.50/9 美元) |
已发布 |
| Claude Opus 4.7 |
20 万 |
约 108 元/约 540 元 |
已发布 |
| GPT-5.5 |
128 万 |
约 108 元/约 432 元 |
已发布 |
一目了然:在上下文窗口这件事上,Google 直接把天花板翻了一倍。
但窗口大不等于体验好。Claude Opus 4.7 虽然只有 20 万 token,但在代码理解和生成质量上一直被开发者推崇。
GPT-5.5 的 128 万 token 也已经覆盖了绝大多数场景。真正决定胜负的,不是“能装多少”,而是“装进去之后能多好地理解”。
Deep Think 模式就是 Google 的答案。它让模型在面对复杂问题时花更多时间“想”,而不是急着给答案。从 Gemini 3 Deep Think 在国际数学和编程奥林匹克上拿金牌的表现来看,这条路走得通。
有一点几乎可以确定:200 万 token 很快会成为旗舰模型的标配,但“能不能用好 200 万”才是真正拉开差距的地方。
开发者现在该做什么——我的决策建议
如果你问我倾向怎么做,说白了就三件事。
第一,别急着切换。 Gemini 3.5 Pro 目前只在 Vertex AI 企业预览里可用,正式版预计 6 月底上线。在它真正开放、独立评测跑完之前,不要因为一个泄露就改变技术栈。
第二,关注 Flash。 如果你今天就需要用 Gemini,3.5 Flash 已经很强了——比上一代 Pro 还强,价格只要十分之一。对大多数开发者来说,Flash 可能才是性价比之王。
第三,等 Pro 上线后,优先试“大上下文”场景。 把整个项目代码库、完整文档、历史对话一次性丢进去,看看它在 200 万 token 深度下的实际表现。
这才是 Pro 相对于其他模型的真正差异化价值。
至于定价,按照惯例 Pro 大概是 Flash 的十倍。换算成人民币,输入大约 108 元/百万 token,输出大约 432 元/百万 token。
不便宜,但如果你的项目真的需要一次性理解整个代码库,这个价格可能比雇一个初级工程师还划算。
666,想想也挺魔幻的。
3 年后回头看,今天 200 万 token 的发布本身可能不会被记住——真正会被记住的是,这是 AI 第一次真正“看到”了整个代码库的全貌。 这才是 2026 年的意义。
相关资源:
更多 AI 最新动态与开发者见解,欢迎做客 云栈社区 一起交流。
 发表于 4 小时前
|
查看: 5|
回复: 0
发表于 4 小时前
|
查看: 5|
回复: 0
