过去几年,数据中心GPU的发展主线始终围绕超大规模模型训练展开。而NVIDIA Blackwell Ultra架构的问世,彻底扭转了这一重心。Blackwell Ultra专为推理与推理阶段的算力负载深度优化——在推理环节,模型处理的 token 总量远超训练阶段,延迟、功耗与内存表现的重要性,已可比肩芯片的峰值浮点算力。

在这一行业变革背景下,两款硬件产品重新定义了AI基础设施的基础算力单元与整机部署单元:B300单GPU模组、搭载NVL72互联架构的GB300整机柜系统。二者相辅相成,让Blackwell Ultra不再只是一代常规迭代产品,而是一套面向企业级、自主可控大规模算力集群的完整建设与运营设计蓝图。
一、Ultra架构核心升级
Blackwell Ultra延续了Blackwell系列的技术路线,但硬件设计全面向AI推理、复杂逻辑推演、超大内存与高速互联场景倾斜。
芯片层面,Blackwell Ultra综合性能较标准版Blackwell提升约1.5倍;硬件原生支持NVFP4精度格式,在保证运算精度的同时,将有效算力密度直接翻倍,并降低了内存占用。
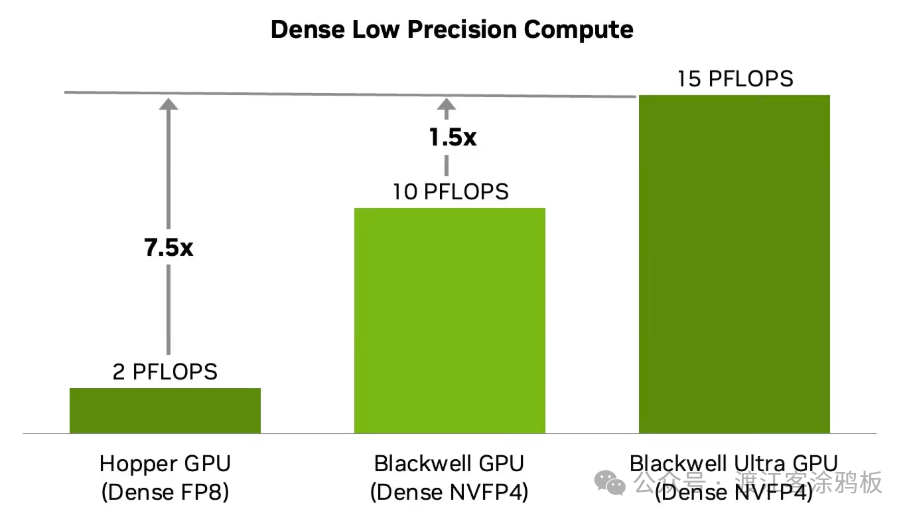
相比标准版Blackwell,另一项核心升级是注意力层加速单元的性能实现翻倍。当前,处理超长上下文、高推理负载的模型时,注意力计算几乎占据推理成本的大头。注意力机制依赖通用矩阵乘法(GEMM)与Softmax指数运算完成计算。虽然历代GPU的矩阵运算能力持续攀升,但负责指数等超越函数运算的专用功能单元(SFU)性能提升相对滞后,导致算力匹配失衡。对此,PyTorch官方博客有详细深度解读。
后面我们再翻翻这个资料
https://pytorch.org/blog/flashattention-3/
Blackwell Ultra 对专用功能单元(SFU)进行了大幅增强,能够更高效地执行注意力相关运算,从而让 Transformer 类模型的推理速度更快、算力开销更低。
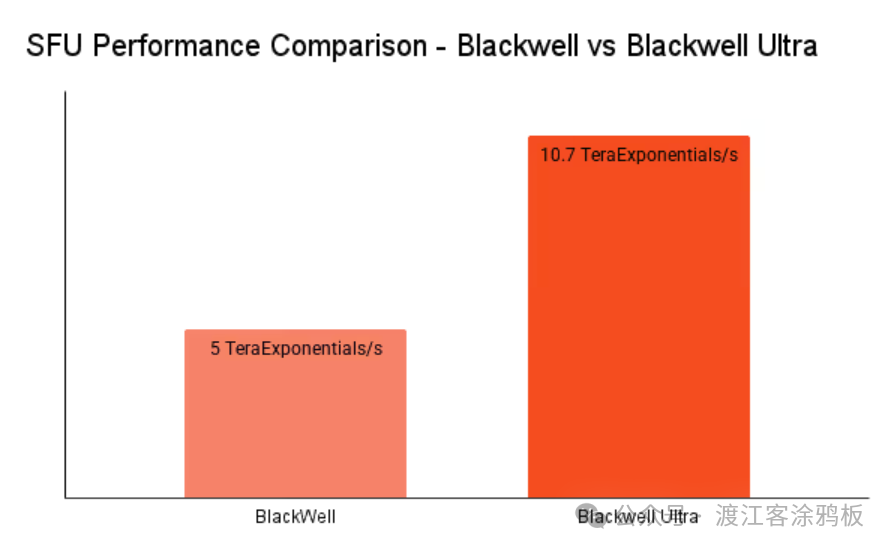
同时,Blackwell Ultra在高带宽内存(HBM)方面迎来重大升级:单颗GPU搭载12层堆叠的HBM3e显存,容量达到288GB,而前代产品仅采用8层堆叠方案。此次升级大幅拉高了硬件内存上限,对大语言模型(LLM)、检索增强生成系统(RAG)、稀疏专家模型(MoE)具有极高价值——这类模型需要充足的内存来存放模型权重、键值缓存与激活值。
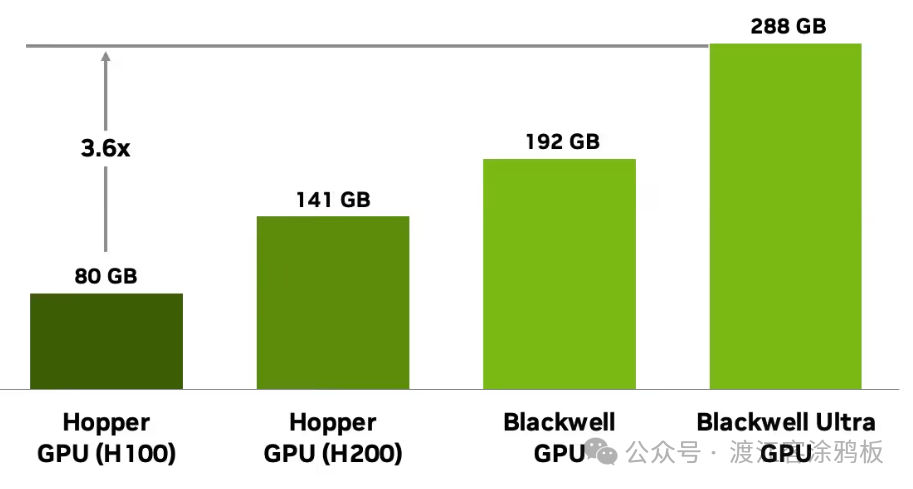
上述所有硬件优化,都体现出产品设计思路的战略转变:不再仅侧重模型训练,而是持续优化常态化推理场景的综合使用成本。
二、B300与GB300 NVL72
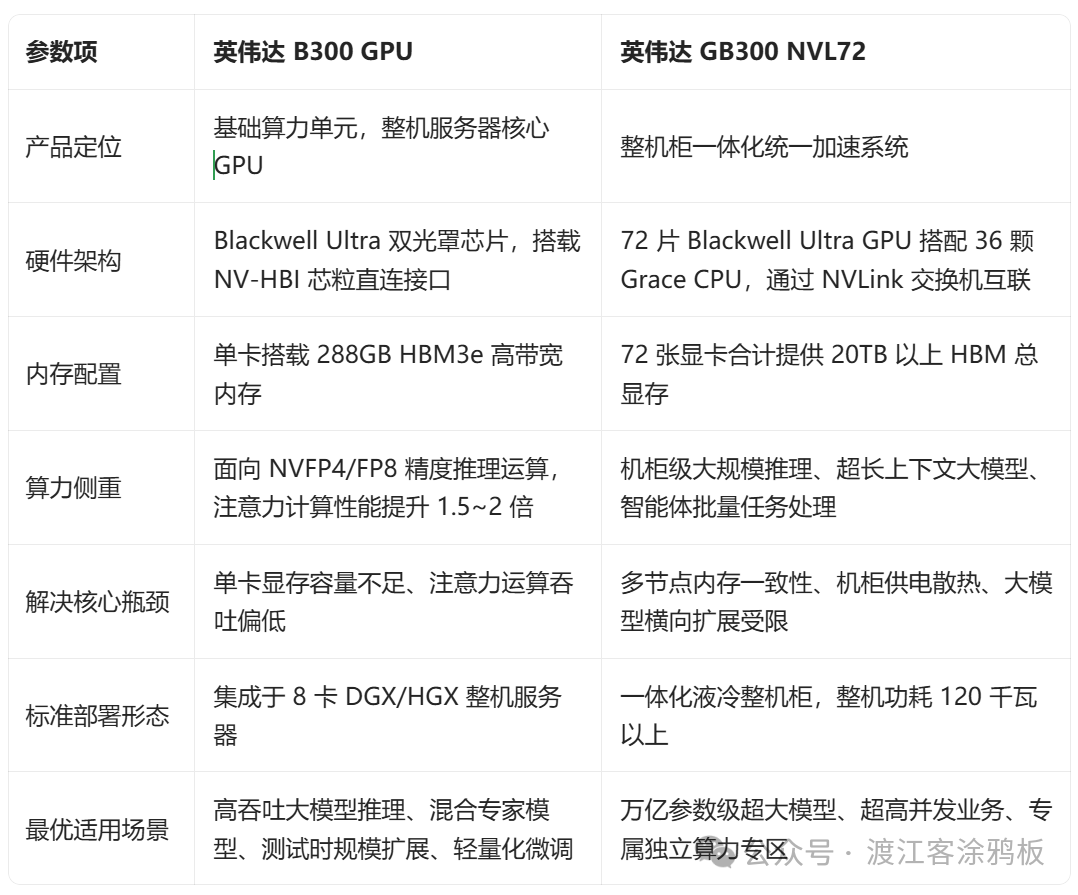
B300是Blackwell Ultra架构的基础算力单元,是一款面向推理场景、拥有超大内存的处理器,专门适配大语言模型、智能体系统以及超长上下文推理任务。芯片采用双光罩架构设计,NVFP4张量核心的吞吐能力大幅提升,单卡标配288GB HBM3e高带宽显存。
B300做了定向取舍:弱化传统FP64高精度算力,全力提升低精度运算效率、注意力计算速度,同时拉满显存带宽,让超大完整模型或大量混合专家子模型能够全部驻留在显存中。实际落地时,B300常以8卡整机节点(DGX/HGX B300)形态部署,也是调度平台与业务团队规划资源时的基础算力单元。
与之相对,GB300 NVL72是一套整机柜一体化AI算力集群。整机集成72颗B300规格GPU、36颗Grace架构CPU,搭配新一代NVLink高速互联,构成统一完整的加速域。整机聚合数十TB HBM显存,辅以超大 NVLink 互联带宽,其运行逻辑不再是多节点集群,而是面向工业级大规模推理打造的一体化巨型加速单元。
如果说B300聚焦芯片底层能力优化——显存、算力吞吐、注意力运算;那么GB300则侧重整机系统层面的优化,涵盖供电、散热、互联链路与机柜级内存一致性。该整机柜方案可作为基础部署单元,搭建自主可控算力专区、多机柜推理集群以及新一代企业级 AI 云平台。
下文对B300显卡与GB300 NVL72整机柜系统进行参数对比。
三、产品设计方向与核心影响
1. 优先低精度算力,适度弱化FP64通用高精度能力
Blackwell Ultra架构以及搭载该架构的B300芯片,深度面向NVFP4、FP8这类低精度张量格式与注意力类负载做硬件专项优化。这也意味着传统高性能计算、物理仿真、科研数值模拟等重度依赖FP64高精度运算的业务,很难再获得同等幅度的性能提升。
这种硬件取舍传递出清晰的产品战略:英伟达不再追求一款加速器适配全部场景,而是集中资源深耕 Transformer、大语言模型、推理、逻辑推演等AI类业务。
2. 显存密度跃升,功耗与散热成为核心约束
单卡288GB大容量HBM3e显存、单机柜集成数十张GPU,内存容量瓶颈已被突破,取而代之的是整机功耗与机柜热密度两大核心制约因素。GB300 NVL72整机柜普遍配套液冷系统,同时需要专属的大功率供电配套,这足以体现整机超高功率密度与重载运行特性。
这种变化将彻底重构数据中心的规划逻辑,机房的留白布局、制冷管路、供电回路、冗余备份,甚至建筑抗震与振动控制,都需纳入前期设计考量。
3. Blackwell Ultra搭建成熟的下一代算力体系
Blackwell Ultra的推出不只是一代常规硬件迭代,更是AI基础设施运行模式的全面革新。行业不再单纯追逐浮点算力的小幅提升,而是重新定义GPU的核心定位:面向超大显存负载、低精度张量运算、大规模推理部署,以及机柜级统一内存一致性架构。
参考资料:
Ref: https://radiant.co/
免责声明:作者尊重知识产权、数据隐私,部分图片和内容来源于公开网络,版权归原撰写发布机构所有,如涉及侵权,请及时联系我们删除。
 发表于 2 小时前
|
查看: 3|
回复: 0
发表于 2 小时前
|
查看: 3|
回复: 0
