过去三天,我让 Kimi 连续跑了一套因子挖掘 Agent,全程没有人工干预。最终生成了 300 多个候选 alpha,提交通过 24 个,Spectacular 级别的因子超过 20 个。
更有意思的是,它并非在机械地随机生成表达式,而是持续总结经验、修正错误、调整研究方向。跑到第三天的时候,它已经和第一天完全不是一个级别的研究员了。
很多做量化的朋友经常问我:能不能让 AI 帮我批量挖因子,我睡觉它干活,一觉醒来给我一批能用的 alpha?听起来很美好,但真做起来,大部分人第一步就卡住了——你首先得搭一套完整的本地 harness:维护数据、写表达式、计算 IC、回测、可视化……成熟团队都有自研框架,可对许多新人来说,光是稳定的数据源就能劝退一大批人,更别提后面数据清洗、因子计算这些脏活累活。
所以我选择了 WorldQuant BRAIN + Kimi Code。WQ 相当于一个「高并发因子验证器」。字段、回测、IS 检查、PnL 计算、相关性筛查,所有基础设施都是现成的。你只需要把想法翻译成 FASTEXPR,提交上去,平台就会告诉你这个因子能不能用。更重要的是,成为 BRAIN 顾问后,提交通过的 alpha 能持续带来收入。
但问题是,怎么做到持续、稳定地产出高质量 alpha,而不是同一类表达式反复被 SELF_CORRELATION 打回?借助 Kimi K2.7 以及 Kimi Code,我搭了一个能自我进化的因子挖掘 SKILL:无需人工介入,它可以全天自动挖掘因子,边运行边积累经验,最终进化成一个因子挖掘的专家。项目(QuantML-Research/wq-alpha-research)已经在 GitHub 开源。
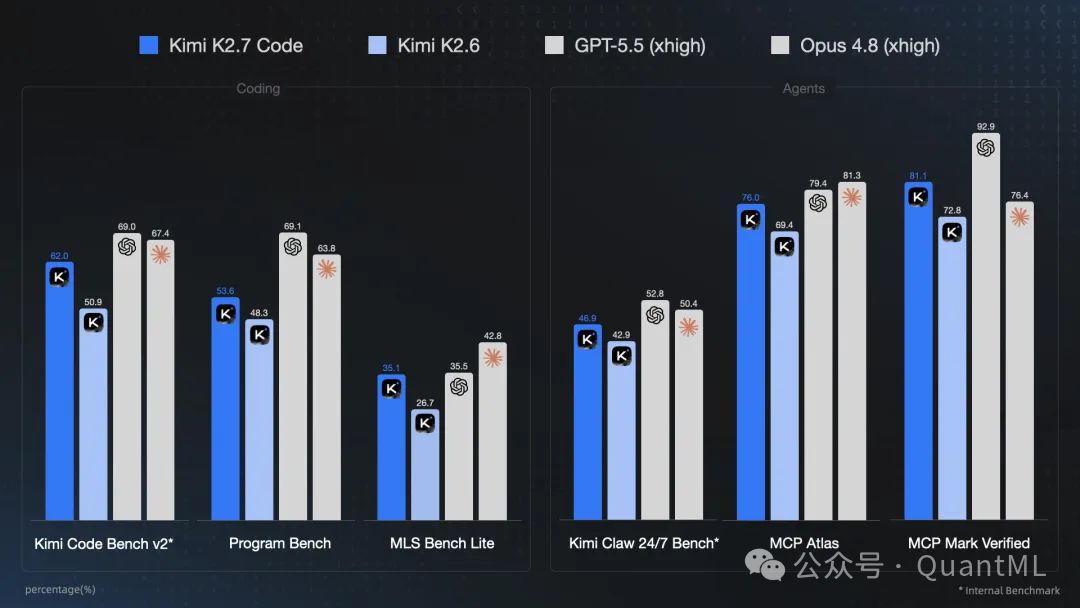
关于 AI 的选择,我一直是 Kimi 的重度用户,平时读 paper、处理长文档都用它。最近 K2.7 在长上下文编程场景上进步很明显,尤其是 Kimi K2.7 Code 这个版本,指令跟得准、长程任务不容易跑偏,token 效率也高。配合 Kimi Code 的 CLI,可以直接操作文件、执行命令、读输出。这次选择 Kimi 来调用 SKILL,主要是看重模型能力和输出稳定性。
自进化因子挖掘 SKILL
很多人以为用大语言模型做因子挖掘就是「给一句提示词,让它生成因子表达式或者计算代码」。但真要这么操作,你大概率会得到一个平平无奇的反转因子或者小市值因子。资深研究员真正值钱的地方不只是知识储备,而是能把一次次失败转化为经验,下次不再踩同一个坑。所以这次设计的 SKILL 核心就在于此——让 AI 也能「长记性」,不断进化。
整套 SKILL 分成三块:
第一块,BRAIN API 交互手册。 让 AI 学会完整的交互流程:字段表、算子文档、FASTEXPR 模板、怎么提交 alpha、怎么查 simulate 状态、怎么看 PnL、怎么判断 ACTIVE 状态。目的是让 AI 真正学会跟 BRAIN 打交道,而不是只会写公式。需要注意的是,想在 SKILL 中完整装入所有信息,这注定了提示词会很长。如果模型上下文只有 200k,运行 Agent 时很容易截断或丢失关键信息,导致模型忘了刚才查过什么字段,或者重复犯已经记录过的错。K2.7 的长窗口优势可以让 AI 同时看到「当前要挖的因子」「历史哪些过了」「哪些字段容易报错」「相关性约束是什么」,减少上下文丢失的情况。
第二块,Alpha 因子经验库。 哪些字段和表达式结构的 Fitness 比较高?什么样的结构容易触发 SELF_CORRELATION?常见报错怎么诊断?换手和 decay 怎么平衡?这些经验原本都需要在长期试错中不断积累。好在 Kimi Code 提供了 Kimi Datasource 插件和联网搜索能力。Kimi Datasource 是 Kimi Code 官方提供的数据插件,无需申请账号或 API,即可通过自然语言查询金融行情、宏观经济、企业工商信息和学术文献。借助历史论文检索与互联网信息搜索,KIMI 可以快速学习和沉淀已有的因子挖掘经验,从而显著降低试错成本。
第三块,自进化机制。 每次提交或者查询之后,Kimi 都会自动把新 alpha 的指标、相关性、失败原因写回 SKILL。跑的时间越长,这个 SKILL 会越聪明,本质上是一种 人工智能 在特定领域的持续微调。
自进化机制怎么跑
为了验证 Kimi K2.7 和这套 SKILL 的效果,第一天晚上我给 Kimi 下了一个任务:用 wq-alpha-research 这个 SKILL,连续跑 20 轮因子挖掘。第二天看日志,发现它的学习曲线非常明显。
前几轮,Kimi 最先从 technical 类型下手——动量、反转、波动率。前三轮提交了 14 个 alpha,结果惨不忍睹:6 个 Turnover 超过 50%,4 个 Fitness 不到 0.5,剩下几个被 SELF_CORRELATION 打回。唯一一个 Sharpe 过 1.5 的,换手率高达 73%。
第四轮,它切换到 profitability,情况好了一点。一个 operating_income / equity 加 cashflow_op / cap 的混合因子,Sharpe 2.1,Fitness 1.6,换手率 12%。
第五轮,它试了一个 analyst 预期调整因子,结果字段写错了——把 analyst_est_eps 当成了 analyst_eps_estimate,BRAIN 返回 400。这个错误被 evolve_skill.py 自动记下来,写进了 SKILL.md:「analyst 簇字段命名容易混淆,提交前务必查字段表。」下次再遇到同类因子,它就会先核对字段表。
从第六轮开始,Kimi 有了明显改善。它不再死磕单一结构,开始往 quality/leverage、cashflow + 分析师修正、sentiment 这些复合结构试探。到第十轮的时候,它甚至会用 SKILL 里的组合规则自我审查:「这个新 alpha 和已有 ACTIVE 的相关性会不会太高?」
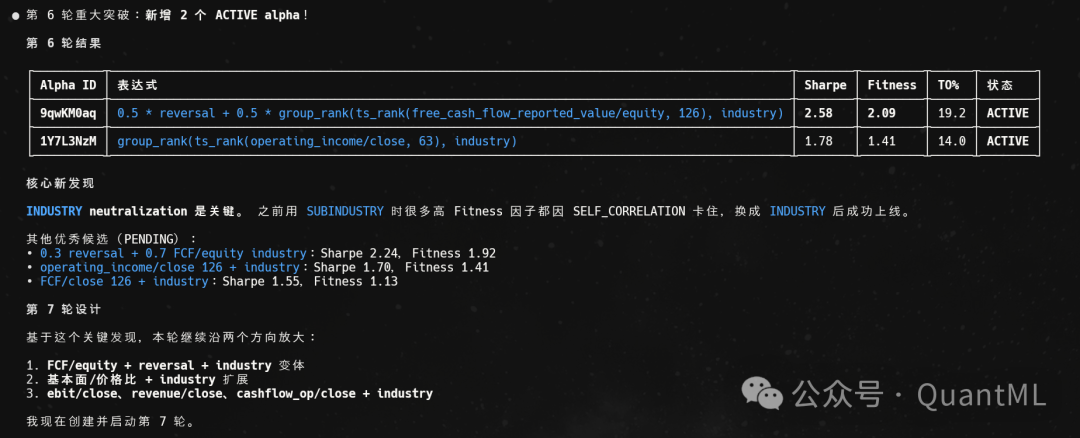
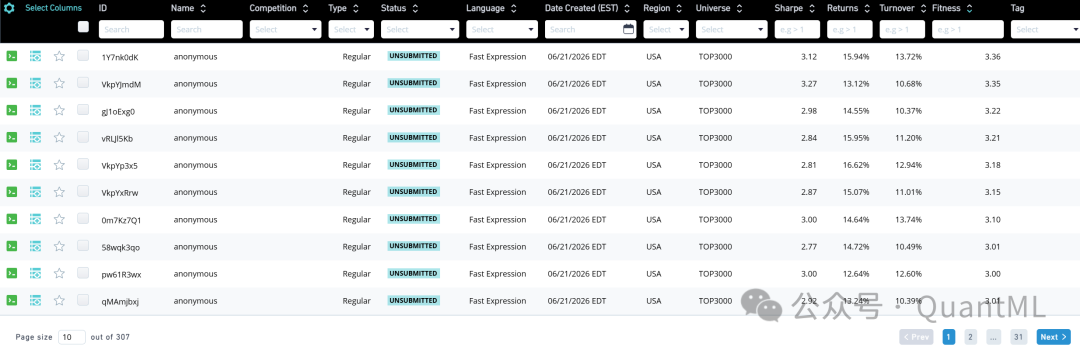
全程运行三天,除了启动任务,没做任何人工干预,也没有报任何 400/429/4028 错误,这充分说明了 Kimi API 的稳定性。最终生成 300 多个模拟因子,提交通过 24 个,其中 Spectacular 级别的就有 20 多个。这是什么概念?手工挖因子,一个有经验的研究员一周能挖出来两三个 Spectacular 因子就算不错。这一下相当于一个人不眠不休干了两个月的活儿。
免费使用金融数据库
在因子挖掘之外,Kimi 用作其他金融场景的 coding agent 也非常好用。Kimi Code 是 Kimi 开源的 Coding Agent 产品。我自己用下来的感受是,它的开发团队迭代速度非常猛,几乎每日一更,十几个版本快速推进,不断推出新功能。看看隔壁 Gemini CLI 和 Code Assist 停止服务的消息,你就知道这种持续投入有多难得。
除了常规功能,有两个我强烈推荐的功能:
一个是 Swarm Mode。对于复杂任务,使用 /swarm 可以让多个 Agent 并行拆解同一目标,更智能地执行复杂任务。
另一个是 Kimi Datasource。这是 Kimi Code 官方提供的数据插件,不需要申请任何账号或者 API,可以直接通过自然语言查询金融行情、宏观经济、企业工商和学术文献。数据覆盖面非常广。对于 Python 技术栈的量化开发者来说,这种开箱即用的数据能力能省下大量前期搭建成本。
结语
Kimi 的能力已经足够驱动 BRAIN 的提交和状态监控。下一步我打算把因子计算和快速验证也放到本地完成,以提高提交的效率。
如果你也在做因子挖掘,可以问问自己:过去一个月挖的 alpha 里,有多少经验和教训是真正写下来的?有多少只是「我记得好像是这样」?把后者变成前者,就是我们这套 SKILL 最想解决的事情。而 Kimi K2.7 + Kimi Code 的组合,正好给了我们把这件事自动化起来的能力——长上下文装得下完整的知识体系,稳定的 API 撑得住长时间无人值守的任务,Kimi Code 的工具链让整个过程不需要人在旁边盯着。
项目已经开源,放在 云栈社区 经常讨论的 GitHub 上。欢迎测试,有问题可以直接提 issue,也欢迎 PR 一起完善这个 SKILL。
 发表于 前天 19:41
|
查看: 8|
回复: 0
发表于 前天 19:41
|
查看: 8|
回复: 0
