会写代码的 AI 越来越多,但真正能驾驭真实软件工程的 Coding Agent 仍然稀缺。
症结在于:仓库级修复远不止补全函数。它要求智能体读懂项目结构、精准定位 Bug、跨文件协同修改、通过测试验证,更要防止“修好旧 Bug,引入新回归”。要让模型具备这种硬实力,关键不是一味堆参数,而是训练任务本身必须足够真实、足够有针对性。
但现有方法大多停留在“静态造题”阶段,靠 Bug 注入、代码变异或规则合成来扩数据。它们始终回避了一个根本问题:模型当前到底弱在哪里,下一轮该练什么?
针对这一痛点,阿里 AI Data 与上海交通大学团队提出了面向 Coding Agent 的闭环自演化框架——Socratic-SWE。它不再把 Agent 的解题轨迹只当作一次性奖励,而是从成功与失败的完整链条里提炼 Agent Skills,再用这些技能反向生成新任务,形成“解题—轨迹—技能—造题—再训练”的闭环。
在同训练预算约束下,Socratic-SWE 经过 3 轮迭代后,SWE-bench Verified 达到 50.40%,较 Base Agent 提升 7.80 个百分点,并在 SWE-bench Lite、SWE-bench Pro 以及 Terminal-Bench 2.0 上全面超过主流自演化基线。

方法:轨迹提炼技能,技能反向造题
Socratic-SWE 的核心逻辑很简单:让模型从自己的解题过程里发现问题,再针对性地生成下一轮训练任务。
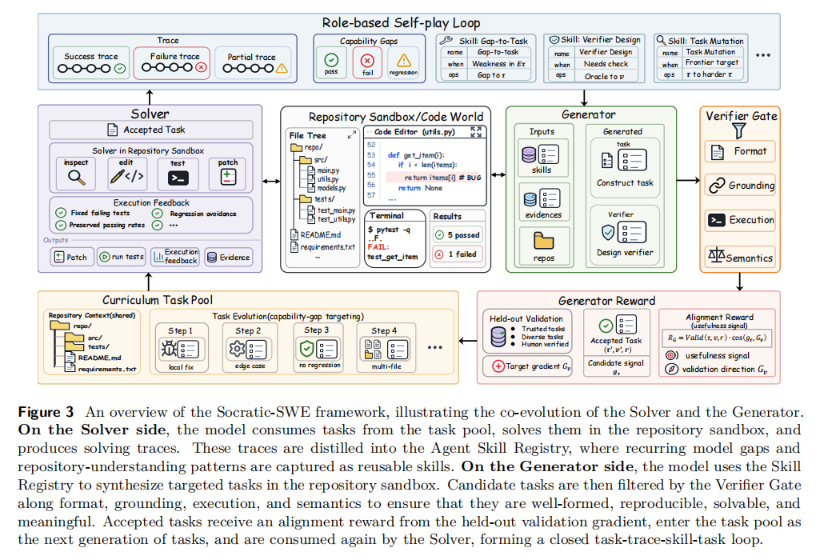
整个框架是一个清晰闭环:Solver 解题产生轨迹 → 轨迹被蒸馏成技能 → Generator 依据技能生成新任务 → 任务经严格验证后入池 → Solver 继续训练,催生新一轮轨迹。这就是“任务—轨迹—技能—任务”的自演化循环。
一、Solver:在真实仓库里跑通修复
在 Socratic-SWE 里,Solver 是真正冲在一线的 Coding Agent。
它拿到仓库级修复任务后,需在沙箱环境里完成完整闭环:检视文件、搜索代码、定位根因、编辑补丁、执行测试,再依据反馈持续修正。
这一过程的重点,不只是最终修对,而是记录下完整探索史。一次成功的修复,能沉淀出哪些搜索路径、修改策略和验证手段有效;一次失败的尝试,则能暴露模型在哪类场景下容易误判、漏改或引入回归。
二、Agent Skill Registry:把轨迹变成结构化技能库
Socratic-SWE 最关键的设计,就是从历史求解轨迹中提炼出 Agent Skill Registry。这些结构化技能通常包含技能名称、适用条件、行为说明和操作步骤,方便后续 Generator 按需调用。
与人工编写规则完全不同,这类技能更贴近模型的真实短板,因为它是从 Agent 实际搜索、编辑、测试、失败到修复的完整经验中抽取出来的,而不是研究者凭经验拍脑袋总结的。
三、Generator:围绕能力缺口生成新任务
技能库就位后,Generator 不再随机造题,而是基于这些技能生成针对性极强的仓库修复任务。
如果 Solver 在多文件联动场景反复失败,Generator 就会侧重产出跨文件理解的任务;如果 Solver 总修好一个测试却打坏原有功能,Generator 就会倾向生成更强调回归测试的任务。
换句话说,训练数据从“静态供给”变成了“动态适配”。模型越训练,短板暴露越清晰;短板越清晰,下一轮任务就越精准。
四、四级验证门:拦截伪任务
当然,能生成任务不代表任务有价值。为避免模型造出看似合理、实际不可用的“伪任务”,Socratic-SWE 引入了四级验证机制:
(1)格式验证:任务描述和验证命令必须可解析。
(2)接地验证:任务引用的文件、函数、模块在仓库中真实存在。
(3)执行验证:验证命令必须能稳定跑通,不能只是环境报错。
(4)语义验证:任务要能区分错误状态和修复状态,并且至少存在一个可行修复。
只有连过四关的任务,才有资格进入训练池。
五、梯度对齐奖励:任务不仅得可执行,还得有价值
Socratic-SWE 的设计更进一步:Generator 产出的任务不但要可执行,还要真正助推 Solver 变强。
为此,研究团队引入了梯度对齐奖励(Solver-Gradient Alignment Reward)。系统会评估候选任务带来的模型更新方向,是否与可信验证集上的提升方向一致。若方向一致,说明这个任务更大概率有助于模型成长;若不一致,即便任务本身就很难、很复杂,也未必值得放进训练。
Socratic-SWE 追求的不是“多造题”,而是筛选出“最有训练价值的题”。在人工智能领域,这种闭环自演化的思路正为 Agent 训练打开新的可能性。
实验结果与分析
一、实验设置
为了系统检验 Socratic-SWE 的有效性,研究团队在多个软件工程与终端智能体基准上进行了评测。
- 模型:Generator 与 Solver 均使用 Qwen3.5-9B;技能蒸馏使用 Qwen3.6-27B。
- 训练预算:所有自演化方法均训练 3 轮,每轮生成 1.2 万个验证通过的训练实例,总计 3.6 万实例。
- 评测基准覆盖四类任务:
- SWE-bench Verified:500 个人工验证的真实仓库问题。
- SWE-bench Lite:300 个过滤后的仓库级问题。
- SWE-bench Pro Public:731 个更复杂的企业级软件工程任务。
- Terminal-Bench 2.0:考察智能体在终端环境中的任务完成能力。
- 对比方法:Base Agent、R-Zero、SPIRAL、Absolute-Zero、Socratic-Zero 以及 SSR。所有方法采用相同 Solver 架构、执行框架与训练预算,力求对比的公平性。
二、主结果:四大基准全面领先
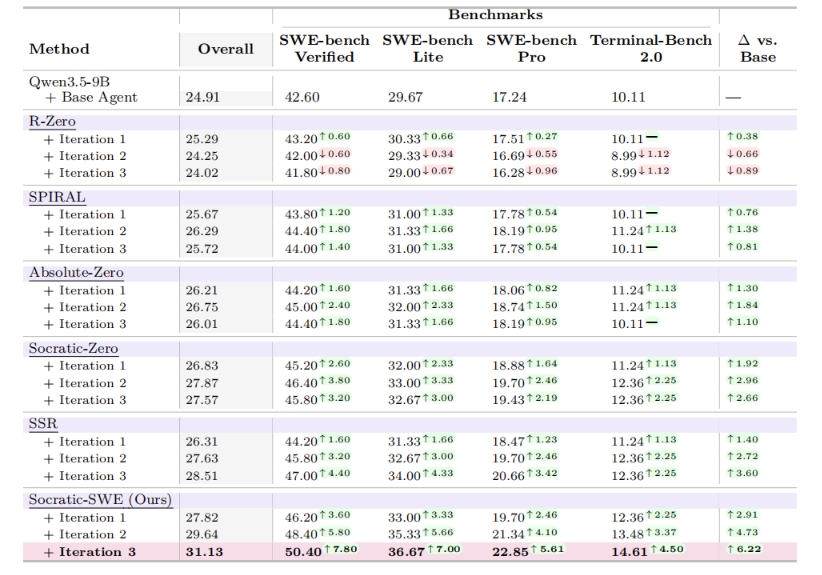
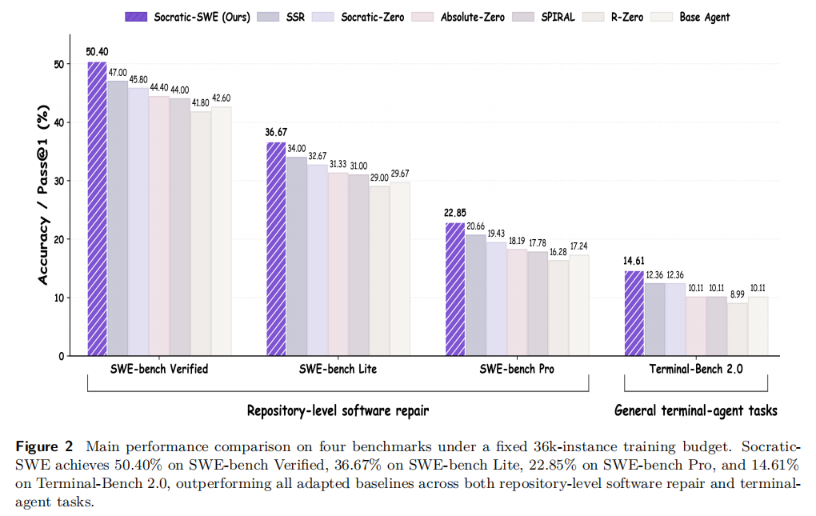
实验结果清晰显示,Socratic-SWE 在四个基准上都拿下了最强表现。
经过 3 轮训练,Socratic-SWE 在 SWE-bench Verified 上达 50.40%,较 Base Agent 提升 7.80 个百分点;SWE-bench Lite 上 36.67%,提升 7.00 个百分点;SWE-bench Pro 上 22.85%,提升 5.61 个百分点;Terminal-Bench 2.0 上 14.61%,提升 4.50 个百分点。
通用自博弈方法在 SWE 这类复杂任务上表现并不稳定,部分方法前期有所增长,后续却容易停滞甚至退化。
Socratic-SWE 的领先之处在于:它不是简单依赖自博弈造题,而是基于真实求解轨迹定位短板,再通过可执行性验证严格筛选,让每一轮训练都直指模型最需要补强的能力。
三、迭代扩展:Socratic-SWE 更晚达平台期
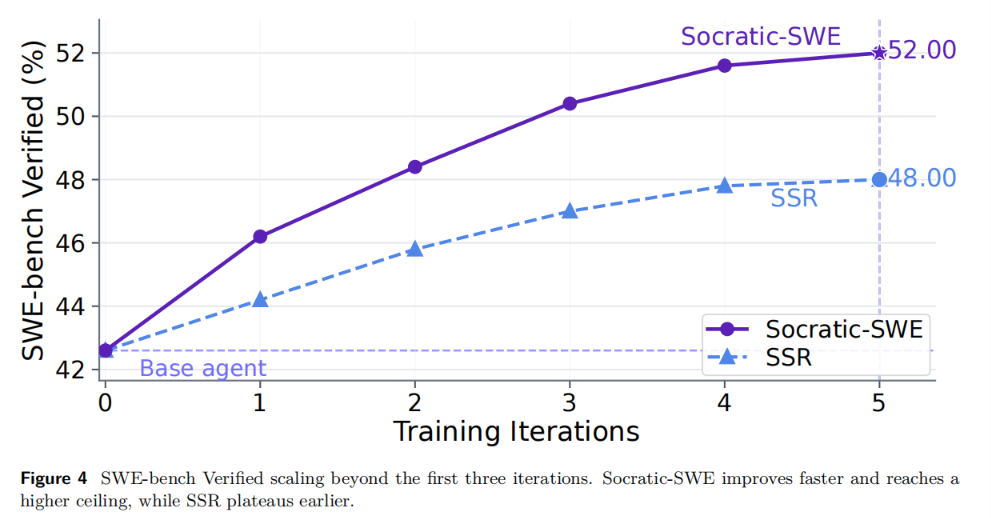
研究团队进一步将训练扩展到 5 轮,以对比 Socratic-SWE 和 SSR 的长期趋势。
结果十分明显:Socratic-SWE 前 3 轮快速拉升,第 4 轮仍在增长,第 5 轮达到 52.00%;SSR 则较早进入平台期,最终约 48.00%。这表明,在固定仓库池中,技能引导的任务生成方式能够更充分地挖掘数据价值。
四、消融实验:技能库贡献最大
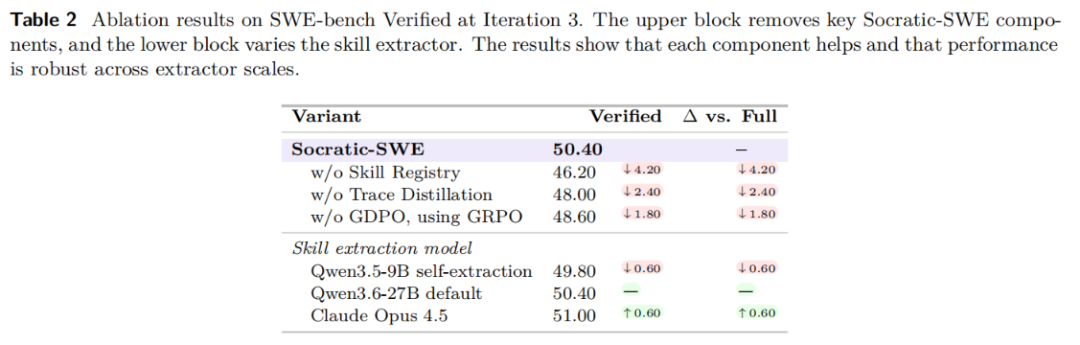
消融实验进一步量化了各个组件的贡献:
- 去掉 Skill Registry 后,SWE-bench Verified 从 50.40% 骤降至 46.20%,降幅高达 4.20 个百分点。这证实了技能库是性能提升的核心来源。
- 去掉 Trace Distillation、改用人工技能后,分数降至 48.00%。人工总结的规则远不如真实轨迹有效,因为模型自身的失败经验,往往比人类预设的分类更能反映真实能力边界。
- 将 GDPO 换为 GRPO 后,分数降到 48.60%。在软件修复场景中,不能只看最终是否通过测试,还必须区分部分修复、完整修复,以及是否引入回归。
- 技能提取模型的规模并非决定性因素。即使用 Qwen3.5-9B 自提取技能,也能达到 49.80%,仅比默认版本低 0.60 个百分点。这说明 Socratic-SWE 的核心优势源于框架设计本身,而非对更强蒸馏模型的简单依赖。
总结
Coding Agent 竞赛的下半场,关键已不仅是模型参数,更是如何持续打造贴合模型短板的高质量训练任务。
Socratic-SWE 把 Agent 的历史求解轨迹变成了训练燃料:从中提炼结构化技能,再反向塑造新任务,最终形成“解题—轨迹—技能—造题—再训练”的闭环。实验表明,在相同预算下,它全面超越了多种自演化基线,在 SWE-bench Verified 上冲至 50.40%,并能将能力迁移到 Terminal-Bench 2.0 等终端智能体任务。
这释放出一个明确的演进方向:未来的 Coding Agent,绝不只满足于“会写代码”,更要学会从自身失败中汲取经验,并据此给自己提出下一轮挑战。这种能力,或许正是通往更高阶软件工程智能的关键。
 发表于 3 小时前
|
查看: 6|
回复: 0
发表于 3 小时前
|
查看: 6|
回复: 0
