在 AI Agent 飞速发展的今天,我们越来越多地看到它们被用于解决复杂的真实世界任务——从数据处理、文档操作,到系统运维和科学计算。
然而,当前大多数 Agent 仍然缺乏一种关键能力:长期积累并复用自己学到的“技能”。现有技能方案普遍把能力当作孤立静态脚本,无法跟随任务持续沉淀,既做不到跨任务复用,也缺少自动校验和迭代优化机制,智能体只能单次执行、无法自我成长。
针对上述问题,字节跳动的研究团队提出了 MUSE-Autoskill 框架,以全生命周期技能管理为核心,定义创建、记忆、管理、评估、优化五阶段统一范式,实现智能体自主进化。
实验结果表明,在包含 51 个真实世界任务的 SkillsBench 基准上,MUSE-Autoskill 在使用人类技能时,准确率领先其他 Agent,达到 68.40%。使用自我生成的技能时,在 35 个任务上准确率高达 87.94%,甚至超越了人类编写技能的上限。
对于想深入了解 Agent 自进化与技能生命周期管理的开发者,云栈社区持续追踪该领域的最新论文与实践。

方法
MUSE-Autoskill 的核心设计理念是:将技能视为拥有完整生命周期的资产,而非一次性生成产物。整个系统围绕五个环节构建:创建、评估、精炼、记忆、管理。
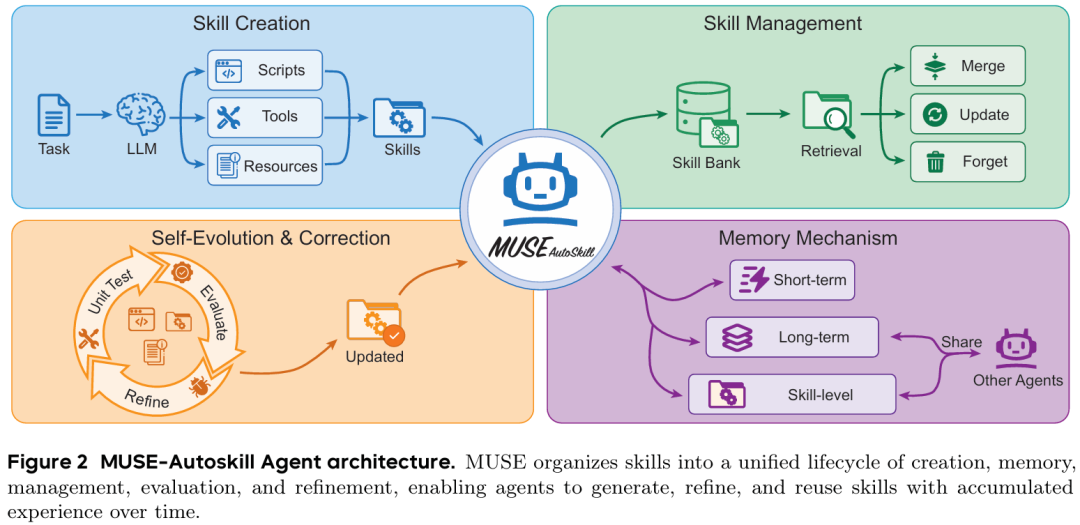
图1 MUSE-Autoskill 整体架构图
上图展示了系统的整体结构。五个模块围绕技能库协同工作,Agent 运行于中间的循环中,所有技能均在此循环中被调用或生成。
一、技能创建
当现有技能无法满足当前任务需求时,Agent 调用内置的创建工具,提交一份功能规格说明——描述所需技能的目的、输入及预期输出。
系统依据该规格说明自动生成标准化的技能包,包含三个核心组件:
- 接口定义文件:声明技能的调用方式与使用规范
- 可执行脚本:实现具体功能的代码
- 单元测试:用于验证技能正确性的测试用例
这种结构化封装确保了技能的可读性与可移植性。
二、技能评估与精炼
技能生成后,需通过评估方可入库。整个流程如图 2 所示。
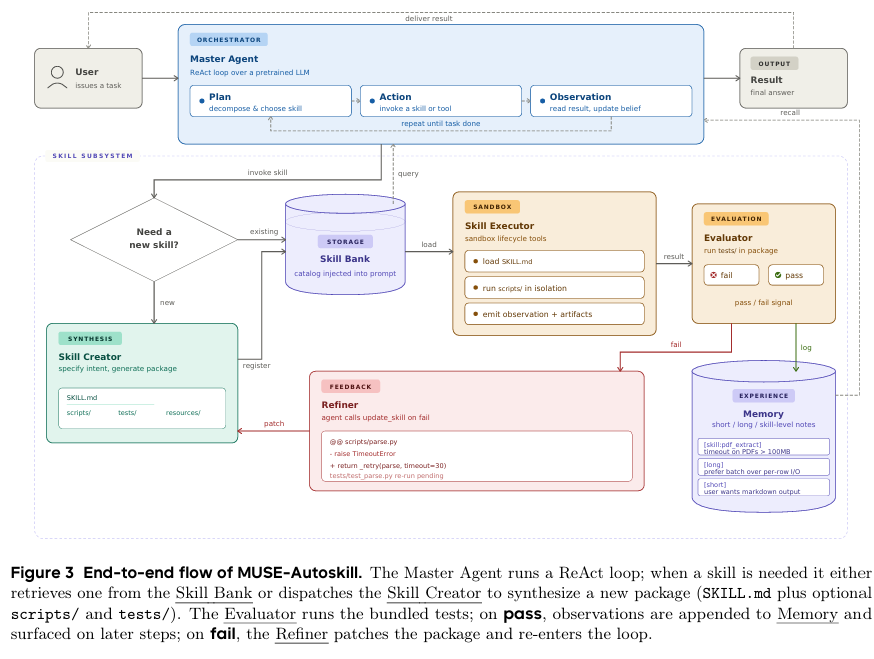
图2 MUSE-Autoskill 端到端流程图
评估系统执行技能自带的单元测试:
- 全部通过:技能被正式注册至技能库,供后续复用
- 存在失败:触发精炼模块,Agent 分析错误信息并自动修复代码,随后重新进入评估循环,直至通过或达到重试上限
这一先验证、后入库的设计,确保了技能库中每一项能力都经过可靠性检验。
三、技能级记忆
除了评估与精炼,MUSE-Autoskill 还有一个区别于现有工作的核心设计——技能级记忆。
每个技能附带一个独立的记忆文件,Agent 每次调用技能后,将本次执行的经验、注意事项及失败模式追加写入该文件。
后续任务再次调用同一技能时,Agent 会优先读取这份跨任务积累的记忆,从而规避已知问题、提升调用效率。
结合短期记忆(当前任务的推理上下文)与长期记忆(跨会话的通用经验),三者构成了完整的多层次记忆体系。
四、技能管理
随着技能库规模增长,高效检索成为关键。MUSE-Autoskill 采用两阶段检索策略:
- 第一阶段:任务启动时,系统仅将各技能的“名称”与“一句话描述”注入 Agent 提示——该目录体积很小,技能数量增长仅带来线性增加的低开销
- 第二阶段:Agent 根据目录筛选出候选技能后,再通过读取工具加载完整接口定义文件并执行
这种渐进式披露机制,使技能库规模扩大时不会导致上下文窗口溢出。
五、自适应上下文压缩
在长任务场景下,上下文窗口压力是另一个挑战,MUSE-Autoskill 为此设计了自适应上下文压缩机制,实现了如图 3 所示的两级压缩机制。
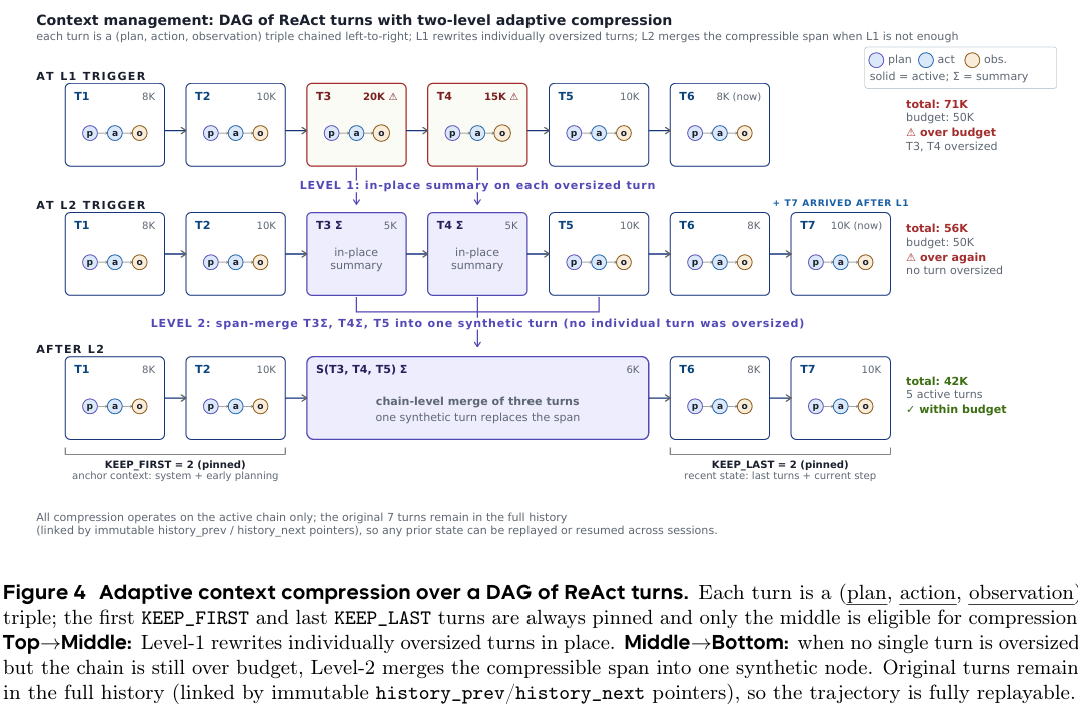
图3 自适应上下文压缩示意图
对话历史被组织为链式结构,固定保留前 5 轮与后 5 轮,仅中间部分进入压缩流程:
- 一级压缩:将单个体量过大的节点替换为紧凑摘要
- 二级压缩:若整体仍超阈值,将连续一段节点合并为一个合成摘要节点,并重新接入活动链
无论采用哪级压缩,原始节点均通过不可变指针完整保留于全量历史中,确保信息可回溯——压缩仅影响活动上下文,不造成信息永久丢失。
以上五个模块相互衔接,构成了技能从创建到复用、从验证到进化的完整闭环。
实验结果与分析
一、实验设置
实验基于 SkillsBench 51 项真实世界任务,覆盖四大领域:科学工程、数据分析、文档处理、运维规划;统一采用 GPT-5.5 作为基座模型,对比 MUSE-Autoskill、Codex、Hermes 三大智能体。
二、实验核心结果与分析
(1)性能基准对比

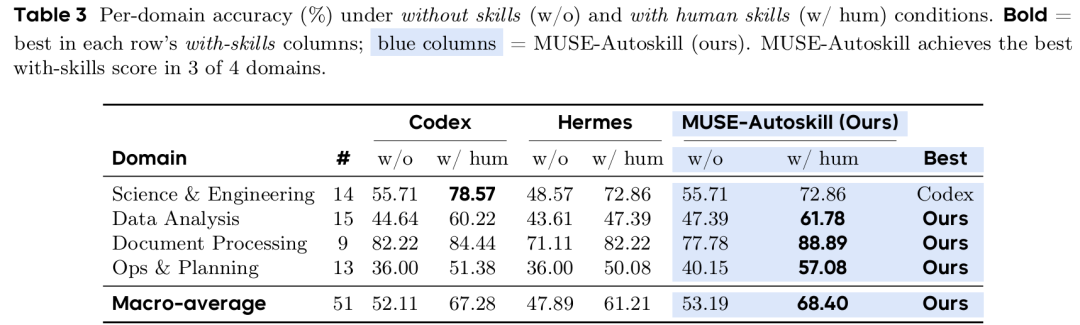
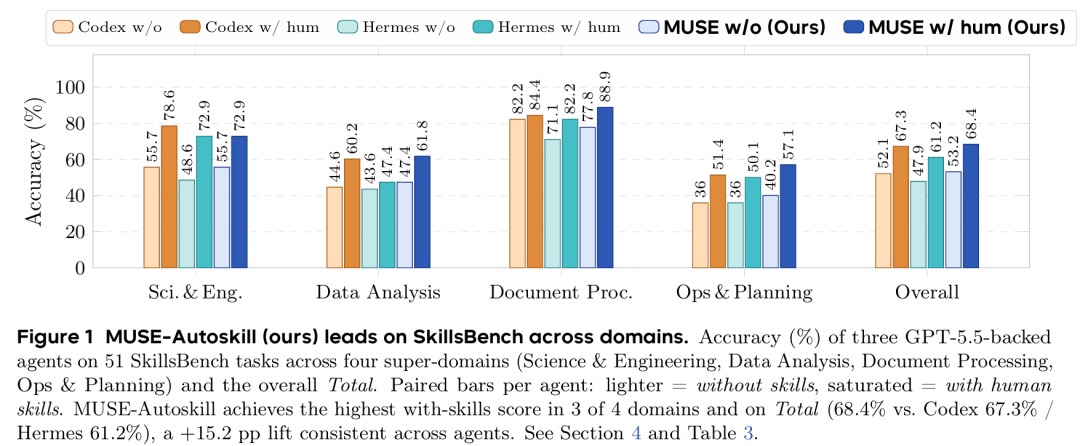
图4 各智能体在 SkillsBench 多领域任务上的精度表现
所有智能体引入人工技能后准确率均提升 13~15.21 个百分点;MUSE-Autoskill 无技能基线 53.19%、有人工技能达 68.40%,整体及 4 个领域中 3 个均领跑对比模型,仅工程科学领域略低于 Codex,证明该框架更擅长解析与落地技能逻辑。
(2)自主技能生成能力

表3 MUSE-Autoskill 不同技能配置下准确率
MUSE-Autoskill 在 51 项任务中成功为 35 项生成有效技能,35 项任务准确率达 87.94%,超越人工技能上限;整体 51 项平均准确率 60.35%,未生成技能的 16 项多集中在专业运维、数值仿真领域,瓶颈为任务基线求解能力而非技能生成质量。
(3)跨智能体迁移实验

表4 技能跨智能体迁移实验结果
将 MUSE-Autoskill 生成的技能直接注入 Hermes 智能体,Hermes 准确率从 47.89% 提升至 58.40%,弥补 79% 与人工技能的差距,且与 MUSE-Autoskill 同技能下准确率仅差 1.95 个百分点,验证生成技能是通用可迁移知识资产,不绑定单一智能体内部逻辑。
(4)效率与成本分析
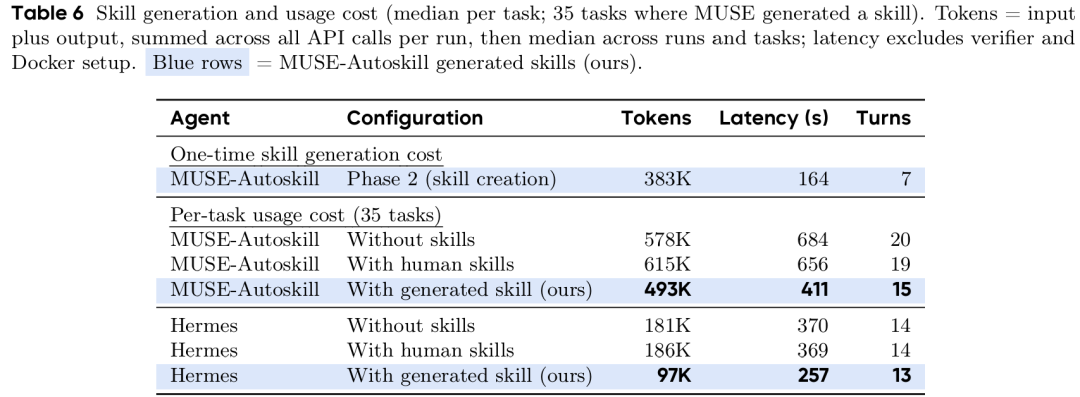
表5 技能生成与复用资源开销对比
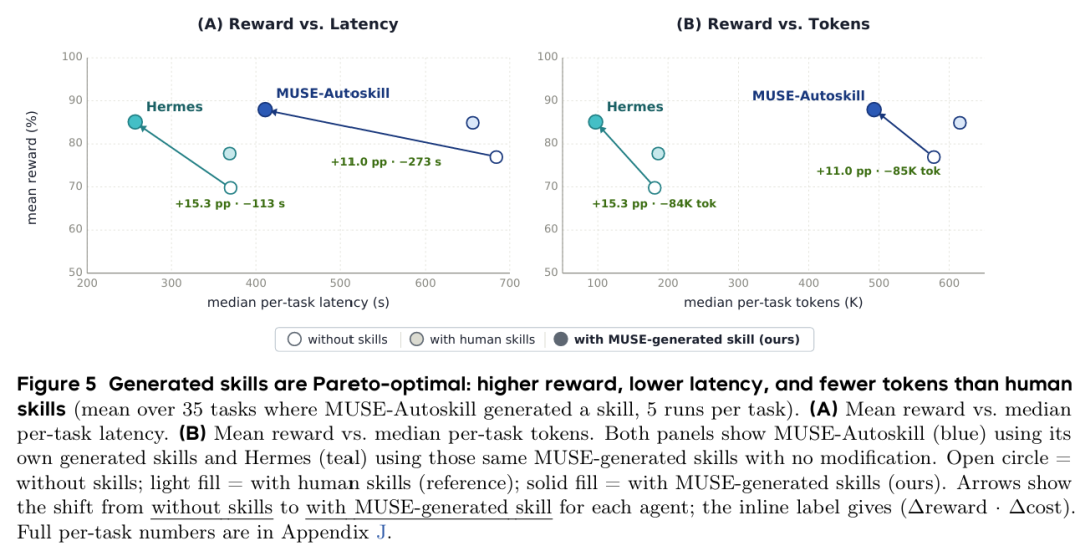
图5 不同方案下模型准确率、时延与 Token 消耗对比
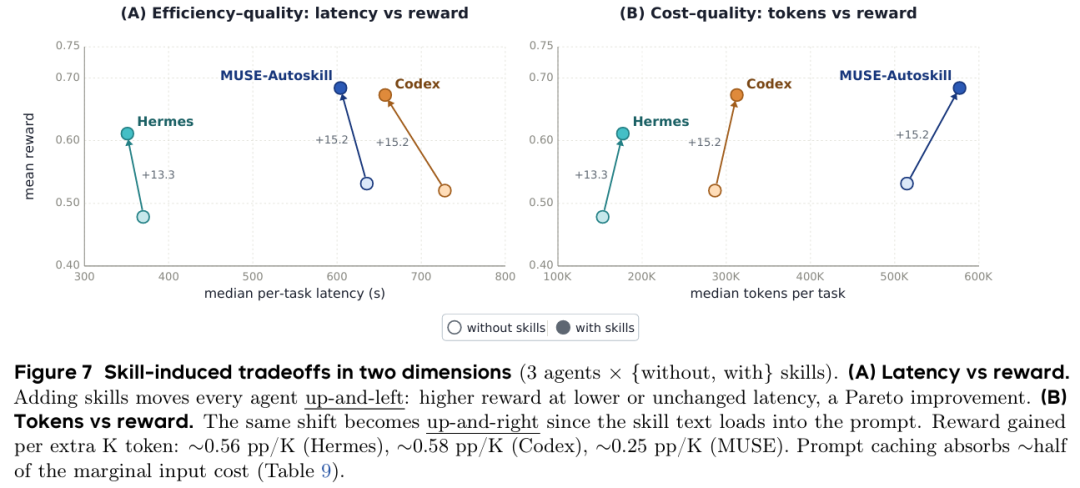
图6 时延、Token 开销与性能权衡关系
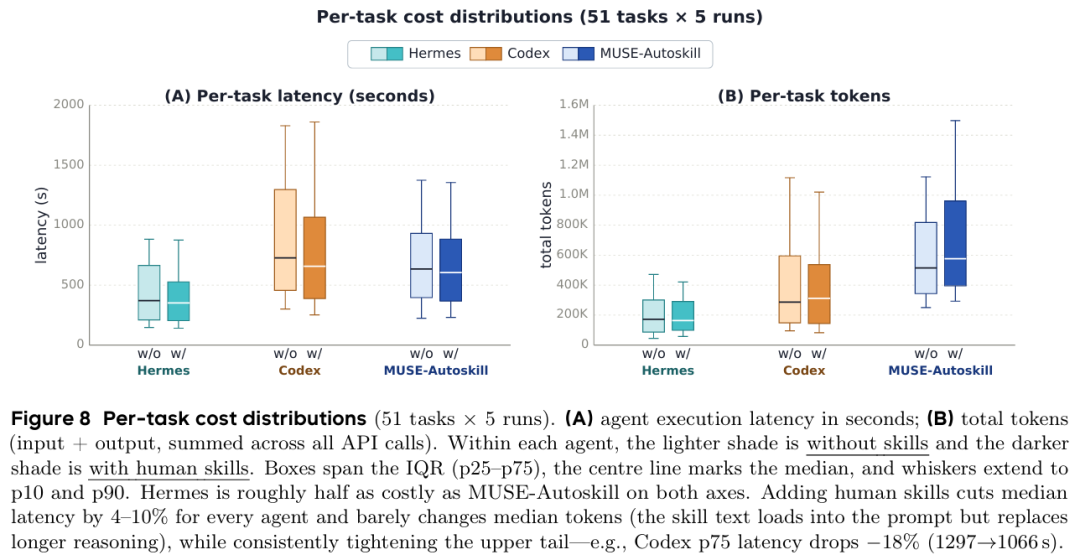
图7 各模型时延与 Token 消耗分布
生成成本与回本周期:一次性消耗约 383K token、164 秒。复用生成技能相比人工技能,MUSE-Autoskill token 降 20%、时延降 37%;Hermes token 降 48%、时延降 30%。3 次复用即可回本。
帕累托最优:使用自研生成技能时,两者同时实现更高准确率、更低时延、更少 token,优于无技能和人工技能配置。
开销分布:Hermes 资源最精简;MUSE-Autoskill 因推理回合更深,token 偏高,但自适应压缩有效控制溢出;技能引入显著降低高时延长尾问题。
(5)技能结构与质量剖析
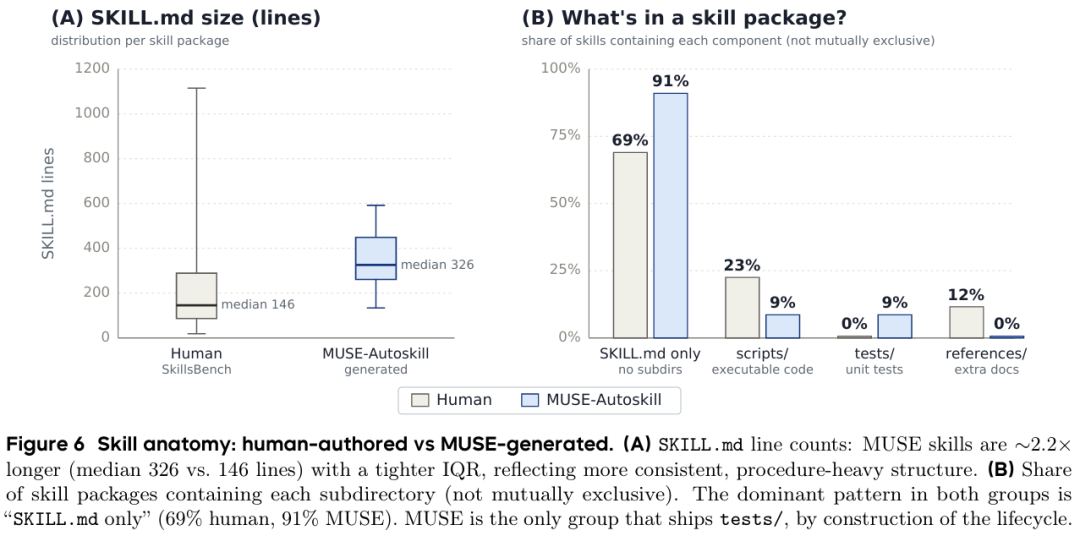
图8 人工技能与模型生成技能内容结构对比
MUSE-Autoskill 生成的技能文档长度是人工技能的 2.2 倍,流程、故障模式、输入输出规范描述更细致;且原生自带单元测试模块,而人工技能几乎无测试用例,在可验证性、鲁棒性上更具优势。
总结
MUSE-Autoskill 最大的突破,是把 AI 智能体从静态执行者变成终身学习者。不再依赖人类持续手写技能,智能体可以自己造、自己测、自己改、自己存、互相共享,形成闭环进化。
这也预示着下一代 Agent 的核心竞争方向:不再比拼大模型基座能力,而是比拼技能积累、记忆沉淀、自进化与生态复用能力。在 云栈社区,我们正见证着这股技术浪潮从研究走向工程落地。
END
 发表于 2026-5-30 03:52:56
|
查看: 130|
回复: 0
发表于 2026-5-30 03:52:56
|
查看: 130|
回复: 0
