最近看 Agent Skill 这条线,我越来越觉得一个趋势很清楚:下一代 Agent 不是简单多学几个 Skill,而是要把 Skill 放进 Harness 里。
Skill 解决的是:Agent 怎么复用已经学会的能力。
Harness 解决的是:这些能力在真实运行时,什么时候能用、谁来授权、证据怎么留、风险怎么挡、失败怎么修复、后续怎么演化。

所以这次想分享两篇最新的 Skill+Harness 论文:
- 第一篇讲的是 Skill 学会之后,如何安全复用。
- 第二篇讲的是 Skill 进入真实系统后,Harness 这层工程架构应该长什么样。

第一篇:Skill 会复用,但不能乱复用
过去很多 Skill Learning 方法都有一个默认假设:只要某条轨迹成功了,就可以把它抽成 Skill,下次遇到类似任务直接复用。
听起来很自然,但论文指出了一个很危险的问题:成功轨迹不等于安全轨迹。
一个任务成功完成,可能只是因为当时页面刚好没有弹窗,按钮位置刚好没变,权限刚好没触发,甚至页面里可能藏着 prompt injection。你把这条轨迹硬编码成 Skill,下次环境一变,它就可能从“效率工具”变成“风险放大器”。
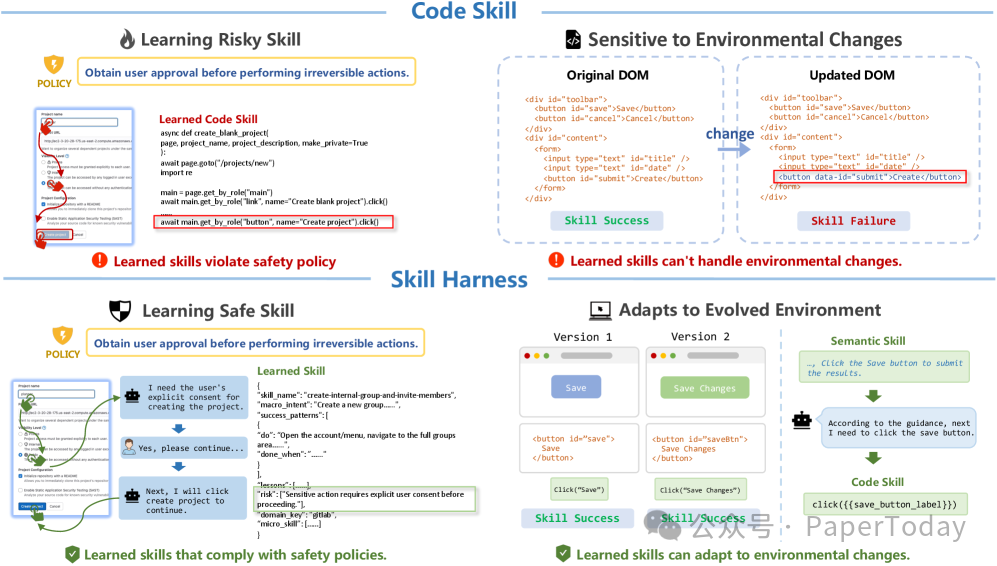
传统 code skill 与 SkillHarness 的边界对比
这就是 SkillHarness 想解决的问题:Agent 不是只要学会 Skill,而是要学会 什么时候不能用这个 Skill。
它的关键设计,是把 Skill 拆成两层。
Macro skill 记录高层意图、成功模式、失败教训和风险约束。它更像一份 Skill 的“使用说明书”:这个 Skill 适合什么任务,什么状态下不能用,什么条件算成功。
Micro skill 则负责具体执行模板。它可以在当前页面状态里绑定参数并执行;如果绑定失败,系统不会强行跑完,而是回退到 LLM-guided planning。
这其实是一个很重要的观念变化:值得复用的不是一段固定代码,而是一组带边界的行为经验。
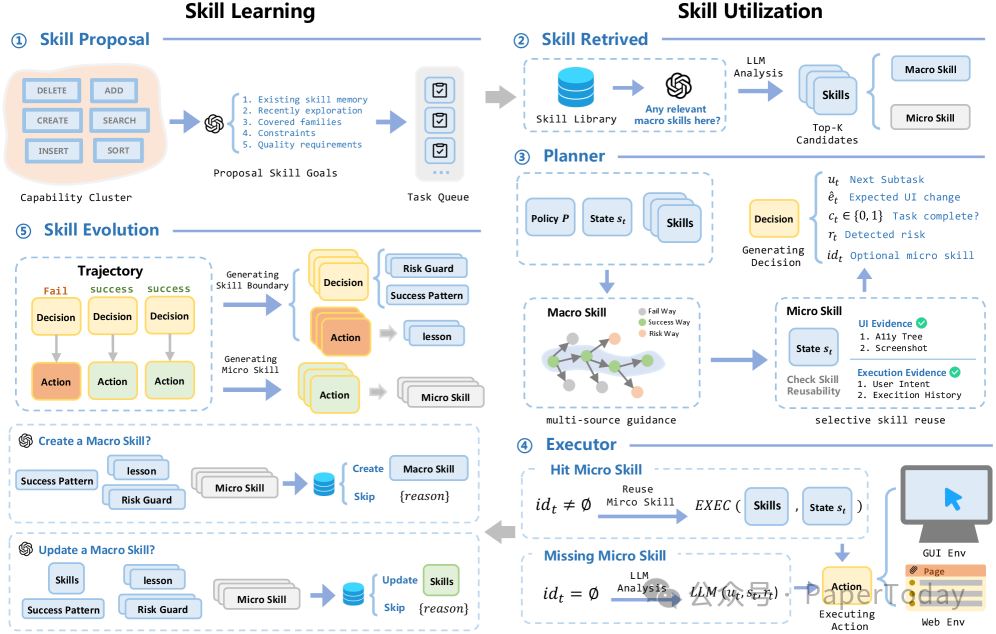
SkillHarness 总体框架
论文里最有说服力的证据,是 learned skills 的 unsafe rate。
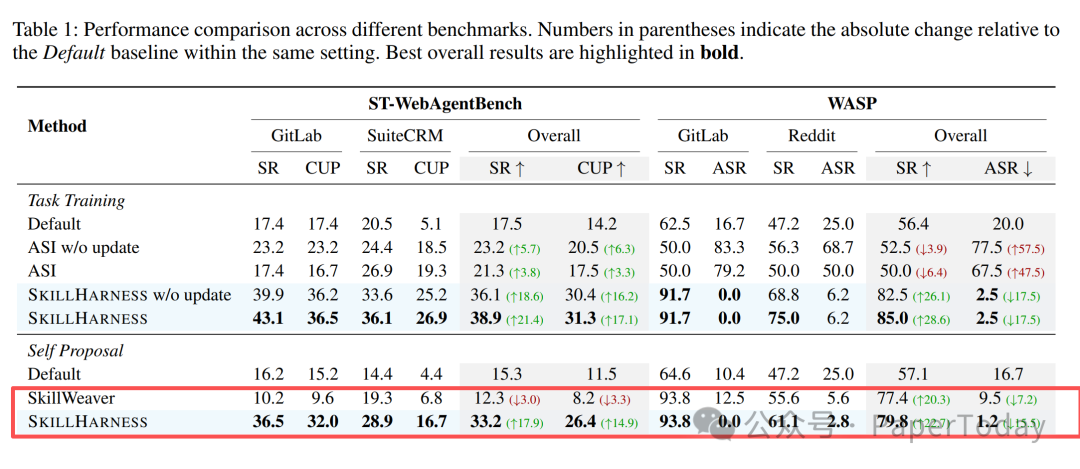
也就是说,SkillHarness 把 learned skills 的 unsafe rate 压到了 2.2%,而 ASI 是 75.0%,SkillWeaver 是 43.6%。
消融实验也很关键:去掉 skill boundary 后,ASR 增加 9.6 个百分点。这说明它真正有效的地方,不是多了一个模板执行器,而是给 Skill 加上了边界判断、风险约束和选择性复用。
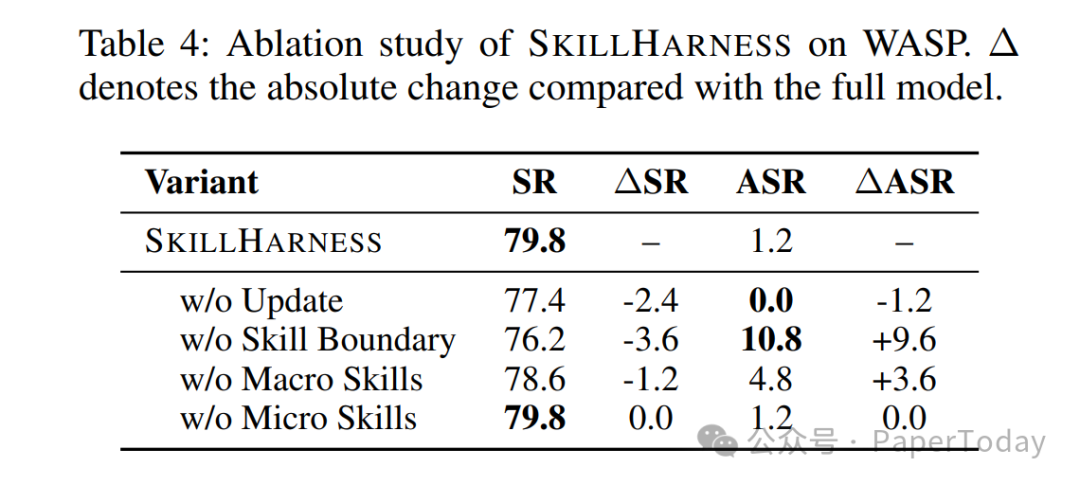
在 OpenApps 的 UI 扰动场景里,SkillHarness 的 Skill Completion Rate 也更稳定。这说明 macro/micro 解耦确实能缓解 UI shift 下的脆弱复用。
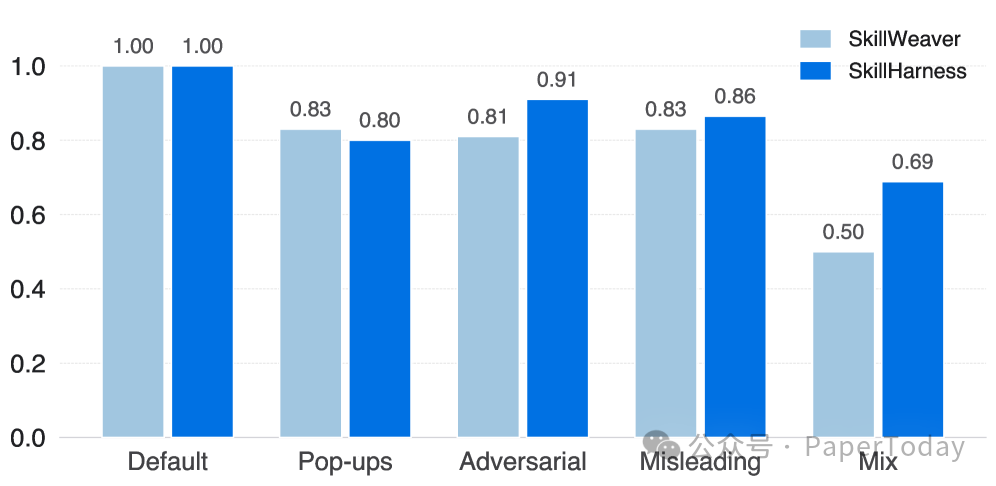
OpenApps 扰动场景下的 Skill Completion Rate
所以第一篇的结论可以压成一句话:Skill 没有边界,复用就是风险。

第二篇:Harness 不是装饰层,而是运行时架构
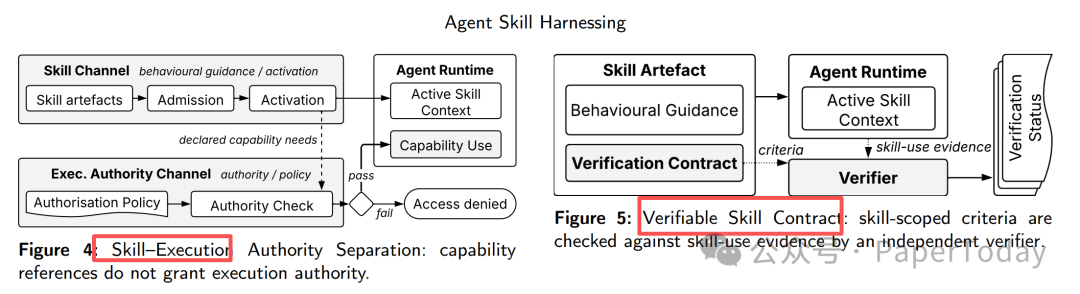
提出了一个很有用的区分:skill artefact 和 skill-in-use。
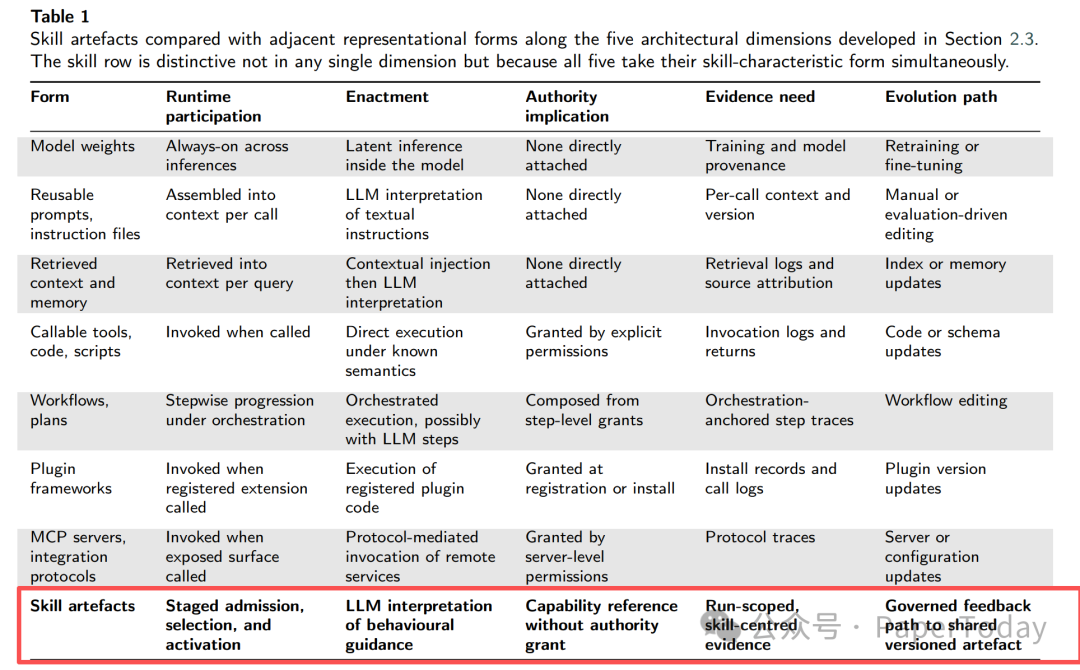
前者是静态 Skill 文件、描述符、prompt、workflow 或工具说明;后者是一次真实运行里,被选择、被绑定上下文、被赋予权限、被 LLM 解释和执行的 Skill。
这两个东西完全不是一回事。
一个 Skill 文件写得再好,也不代表它在某次运行中应该被激活;它能声明自己需要某个 capability,也不代表它自动获得执行权限;它被调用过,也不代表它真的对结果产生了贡献。
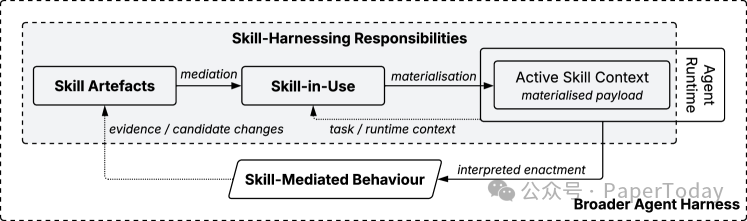
Skill harnessing 的概念边界
这篇论文的价值,是把这些零散问题整理成了一个架构议题:agent skill harnessing。
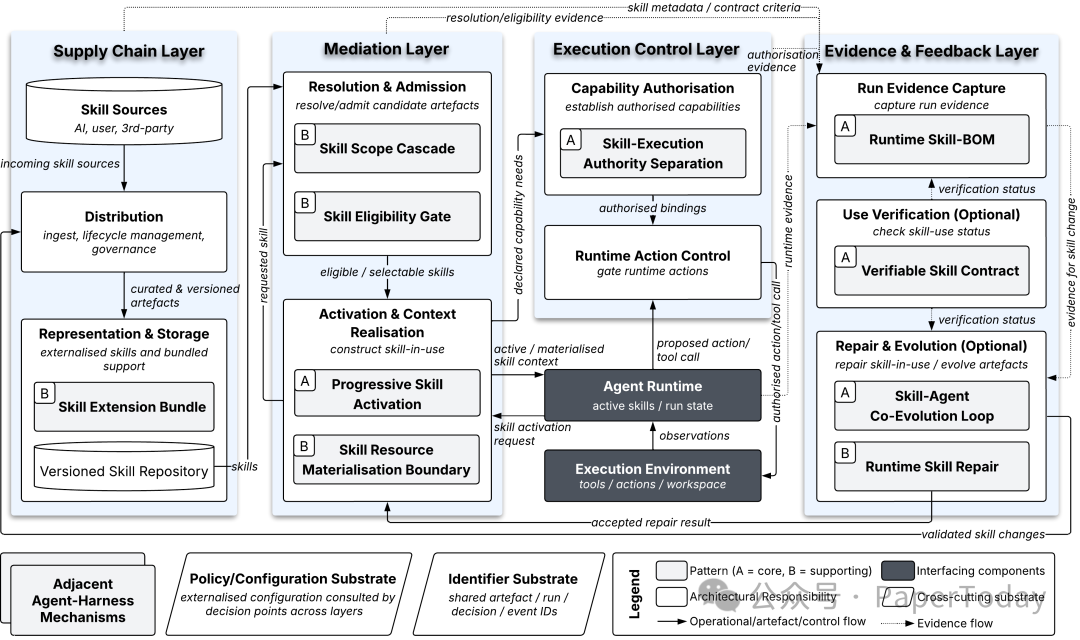
作者做了 multivocal literature review,筛选 37 个系统、51 篇论文,抽取 342 条实践记录,归纳出 10 个 skill-specific architectural patterns,再综合成一个四层 reference architecture。
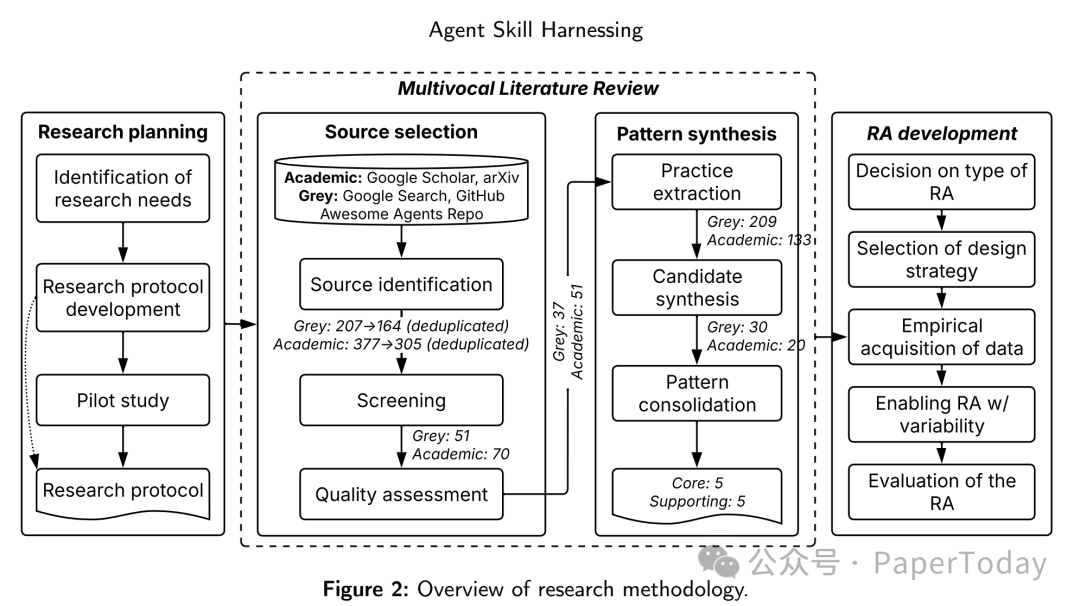
其中 5 个核心模式很值得看:
| Pattern |
大白话解释 |
| Progressive Skill Activation |
Skill 不要一上来全塞进上下文,要从 available、selectable 到 active 分阶段激活 |
| Skill–Execution Authority Separation |
Skill 可以声明需要某个能力,但不能自动获得执行权限 |
| Verifiable Skill Contract |
Skill 用得对不对,要能被独立 verifier 检查 |
| Runtime Skill Bill of Materials |
一次运行用了哪些 Skill、什么版本、证据在哪,要能追踪 |
| Skill–Agent Co-Evolution Loop |
运行证据可以反哺 Skill 更新,但更新要经过验证 |
这几个模式连起来,基本就是一个 Agent Skill 产品化清单:选择、激活、权限、验证、证据、演化,一个都不能少。
Skill-mediated LLM agents 的参考架构
论文进一步把它们整理成四层架构:
- Supply Chain:Skill 从哪里来、版本是什么、依赖什么、来源是否可追踪;
- Mediation:哪些 Skill 可用,哪些适合当前任务,哪些能进入上下文;
- Execution Control:权限、工具调用、执行边界和运行时修复;
- Evidence & Feedback:trace、verification、Runtime Skill-BOM、候选更新和演化闭环。
我觉得这里最值得产品团队关注的是 Runtime Skill Bill of Materials。
它有点像软件供应链里的 SBOM:一次 Agent 运行中,哪些 Skill 被检索、哪些被激活、版本是什么、参与状态如何、证据链接在哪,都要记录下来。
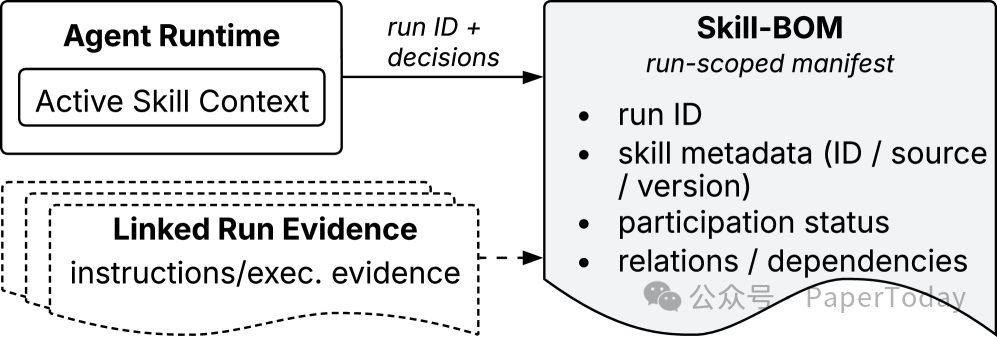
Runtime Skill Bill of Materials
没有这层东西,你很难回答几个上线后一定会遇到的问题:
- 某次错误输出到底和哪个 Skill 有关?
- 某个 Skill 更新后,哪些运行受影响?
- Agent 调用了 Skill,但它到底有没有对结果产生作用?
- 验证失败后,应该修 prompt、修 Skill,还是修权限策略?
所以第二篇的结论也可以压成一句话:Harness 不是为了让 Skill 看起来更工程化,而是让 Skill 在运行时可控、可查、可验证、可演化。
为什么说 Skill + Harness 是无敌组合
Skill 负责复用能力,Harness 负责治理能力。Skill 让 Agent 会做事,Harness 让 Agent 知道什么该做、什么不该做、做完之后如何被追踪和改进。
Agent Skill 的下一步,不是堆更多 Skill,而是把 Skill 放进 Harness 里,让复用变得有边界、有权限、有证据、有验证、有演化。
论文标题: SkillHarness: Harnessing Safe Skills for Computer-Use Agents
论文链接: https://arxiv.org/html/2606.20636v1
论文标题: Harnessing Agent Skills: Architectural Patterns and a Reference Architecture for Skill-Mediated LLM Agents
论文链接: https://arxiv.org/html/2606.20631v1
 发表于 2 小时前
|
查看: 3|
回复: 0
发表于 2 小时前
|
查看: 3|
回复: 0
