运营团队制定了半年的增长目标:DAU要冲击30万。随之而来的是一个严峻的技术挑战——预计届时每天的对话消息量将超过5千万条。在周一的技术评审会上,后端负责人老张指出了核心问题:当前存储消息的message表数据量还不到9千万,但如果按照日增5千万的预期计算,半年后数据总量将飙升到60亿。
更紧迫的是,最近的几次压力测试表明,单表数据量突破1亿后,查询延迟从稳定的50ms暴涨到了300ms。如果真等到数据积累到60亿,系统必然崩溃。
作为后台技术负责人,我深知“提前布局”在架构设计中的重要性。后台架构最忌讳“临时抱佛脚”,等到数据压力迫在眉睫时再进行分库分表,不仅迁移风险极高,还可能直接拖累业务的快速增长。然而,业务团队的要求同样明确:当前系统每日服务着上百万活跃用户,分表过程必须做到 “零停机、不影响现有数据”,并确保架构能平滑支撑半年后60亿的数据规模。

经过团队为期三周的反复测算、验证与技术预演,我们最终设计并实施了一套 “按数据语言垂直分片,再按用户对话水平分片” 的分层方案。这套方案不仅解决了眼前的性能隐患,也为未来海量数据预留了充足的弹性扩容空间。下文将从后台开发的视角,详细拆解这套“提前布局”的分表架构,并分享我们在压测和迁移过程中踩过的关键坑点。
一、架构前瞻:为何必须“提前分表”?
项目启动初期,有同事提出:“目前才9千万数据,可以先用着,等快到2亿再分表也来得及。”这个想法被我们当即否定。原因在于:等待数据增长到2亿再开始规划方案、开发、实施迁移,整个周期至少需要一个月。而按照每日5千万的增长速度,迁移还没完成,单表就可能因数据过载而性能崩盘。
更重要的是,这张message表有一个核心的业务属性——language字段(存储如繁体中文、英文、日语等多语言数据)。超过80%的查询都是 “按语言+用户ID+对话ID” 的条件组合进行筛选,例如“查询用户A在英文对话B中的所有历史消息”。如果等到数据量巨大时才仓促分表,将会面临两个更棘手的问题:
- 跨表扫描风险:如果只简单地按
userId做Hash分表,那么查询特定语言的消息时,将不得不扫描所有分表,性能反而会更差。
- 迁移成本激增:数据量从9千万增长到2亿,数据迁移时间可能从几天延长至数周,在此期间业务还需保持正常运行,风险呈倍数增长。
因此,我们确定了 “先按语言垂直分片,再按用户对话Hash水平分片” 的核心分层策略。其目标是提前适配业务属性,为未来的数据洪峰铺平道路:
- 业务隔离:不同语言的消息存入独立的表集群(如
message_zh_hant、message_en)。当前查询可以精准路由,未来各语言数据量增长也不会相互干扰。
- 弹性扩容:各语言数据量预期差异大(繁中60%、英文30%、日语10%),独立集群可以按需单独扩缩容。例如,当繁体中文数据率先达到36亿时,可以仅对该集群进行加表扩容,无需变动英文和日语集群。
- 查询友好:
userId + dialogId是查询的核心条件,对此进行Hash分片能确保同一对话的所有消息集中存储。即便未来数据量达到60亿,查询特定对话的历史记录也无需跨表。
举例说明:当前一条英文消息(language='en', userId=123, dialogId=456),会先被路由到message_en集群,再通过hash(‘123_456’)计算,落入该集群对应的物理分表中。
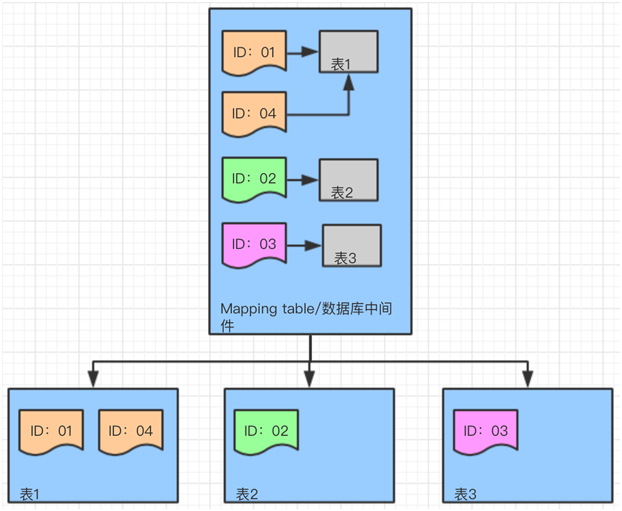
半年后数据量增长至60亿,这条消息的路由逻辑保持不变,唯一的变化是message_en集群的分表数量从4个扩展到了8个,对查询体验毫无影响。
二、核心参数设计:面向60亿数据量的测算
提前分表的核心在于 “基于未来预期数据量来设计参数”,绝不能只盯着当前的9千万数据。否则,半年后必然面临二次扩容,更加麻烦。我们所有的关键参数都围绕“支撑半年后60亿数据”的目标进行测算。
2.1 分表数量:为单表预留4.5亿行的安全空间
我们的数据库环境以“8核16G实例、机械硬盘”为主(考虑到60亿数据全用SSD成本过高)。根据历史性能数据,我们确定了单表容量红线:
- 单表≤5000万行:查询延迟可稳定在50ms内。
- 单表≤4.5亿行:即便在数据量满载的未来,查询延迟也能控制在100ms内(预留了5000万行冗余,避免频繁触发扩容)。
结合60亿总数据量及各语言占比,我们计算出各语言集群的初始分表数:
- 繁体中文:60亿 × 60% = 36亿 → 分 8 张表(36亿 ÷ 8 = 4.5亿/表,刚好触及性能上限)。
- 英文:60亿 × 30% = 18亿 → 分 4 张表(18亿 ÷ 4 = 4.5亿/表)。
- 日语:60亿 × 10% = 6亿 → 分 2 张表(6亿 ÷ 2 = 3亿/表,为未来预留了1.5亿行的扩容空间,可平滑扩至4张表)。
这里我们曾踩过一个坑:最初打算为繁中集群分配更多分表(如16张),但运维团队提醒,单个MySQL实例承载的分表数最好不超过32个。因此,我们将繁中的8张表分散到2个数据库实例(每个实例4张表)。未来即便需要扩容到16张表,也只需增加2个新实例即可,无需重构整体架构,成本与复杂度都更可控。
2.2 虚拟节点:每个物理表100个,根治数据倾斜
在早期压测中我们发现,即便当前只有9千万数据,日语集群的2个分表也存在数据分布不均的问题(一个表5200万行,另一个3800万行)。可以预见,当数据量达到6亿时,这种差距将演变为3.5亿 vs 2.5亿,导致严重的性能热点。
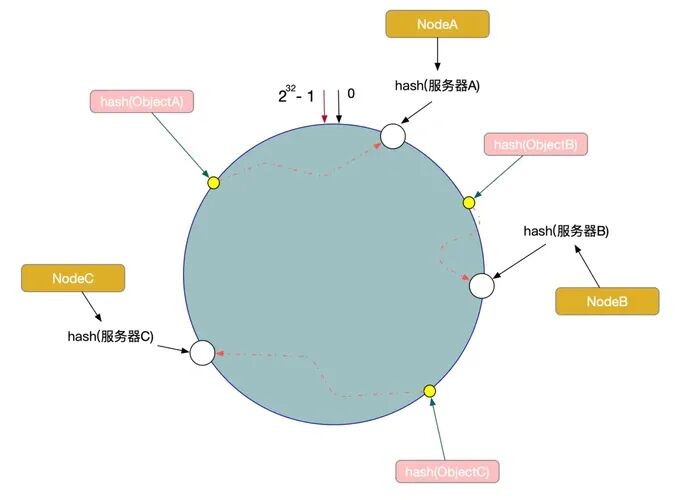
解决方案是引入 “虚拟节点”——为每个物理分表映射多个虚拟节点,使它们在一致性Hash环上分布更均匀,从而提前规避未来可能的数据倾斜。我们最终设定 “每个物理表对应100个虚拟节点” ,依据如下:
- 倾斜率可控:在9千万数据量下,倾斜率从15%降至3%以内;模拟推算,即便到60亿数据量,倾斜率也能稳定在5%以下。
- 路由开销小:100个虚拟节点的Hash计算与路由查找耗时在微秒级,对当前查询性能的影响可忽略不计。
- 扩容兼容性好:未来新增分表时,只需为新表生成100个虚拟节点并加入现有Hash环即可,无需调整旧节点的映射关系。
在具体实现上,我们选用CRC32算法计算Hash值(相比MD5有约3倍的性能优势,更适合高频写入场景)。伪代码如下:
// 计算虚拟节点在Hash环上的位置
func calcVirtualNodeHash(tableName string, virtualIdx int) uint32 {
key := fmt.Sprintf("%s_%d", tableName, virtualIdx)
return crc32.ChecksumIEEE([]byte(key))
}
// 消息路由核心逻辑
func routeMessage(msg Message) string {
// 1. 按语言确定目标集群
cluster := getClusterByLanguage(msg.Language)
// 2. 根据 userId 和 dialogId 计算消息Hash值
msgHash := crc32.ChecksumIEEE([]byte(fmt.Sprintf("%s_%s", msg.UserId, msg.DialogId)))
// 3. 在Hash环上查找最近的虚拟节点,并映射到物理表
virtualNode := findNearestVirtualNode(cluster, msgHash)
return getPhysicalTable(cluster, virtualNode)
}
三、无停机迁移方案:当前与未来的平滑演进
提前分表虽然迁移压力相对较小,但“零停机”的要求丝毫不能放松。我们制定了“双写+灰度”的迁移策略,并将其拆分为两个阶段,以最小化对业务的影响。
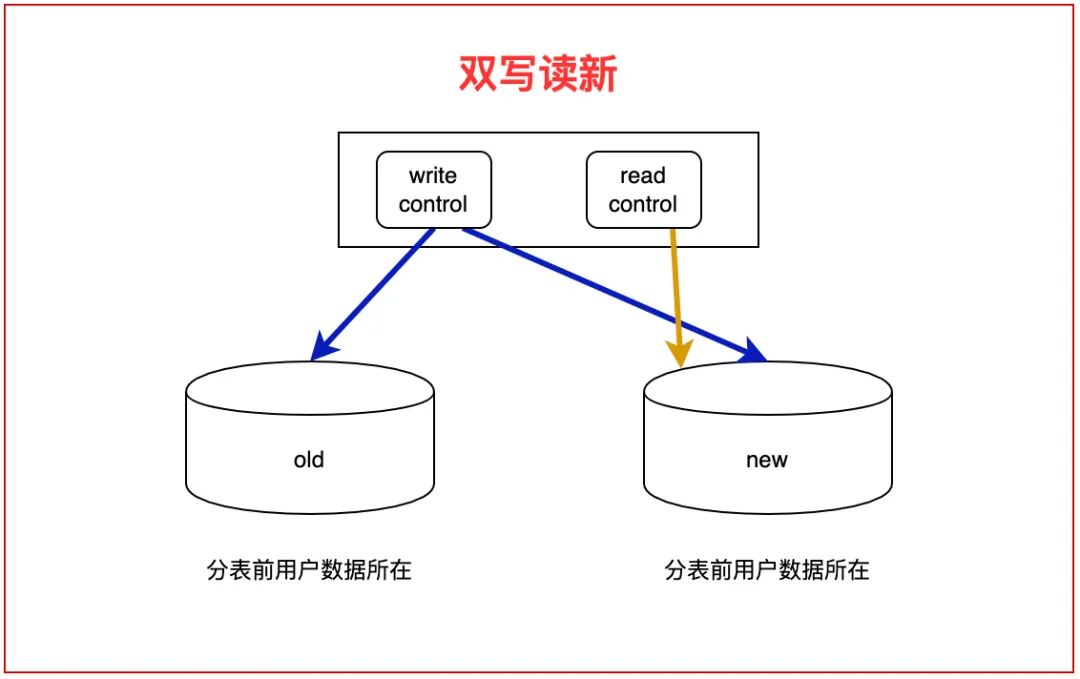
阶段一:当前9千万历史数据迁移(3天完成)
虽然当前数据量不大,但我们仍然严格执行了4个步骤,确保万无一失:
- 双写初始化(1天):开发路由中间件,所有新消息同时写入旧单表和新分表集群。通过Canal监听MySQL binlog,将9千万历史数据按语言拆分,异步迁移至对应分表。优化点:采用“分批次+错峰”同步,白天同步30%,凌晨业务低峰期同步70%。
- 数据校验(半天):进行“量”校验(核对各语言分表总行数)和“质”校验(随机抽样5万条数据对比)。同时,对线上TOP10的查询SQL进行性能校验,确认分表后响应时间符合预期。
- 灰度切换读流量(1小时):按5% -> 30% -> 100%的比例,逐步将查询流量从旧表切至新分表集群。每一步都观察20分钟,确保无异常。整个过程配备秒级回滚方案。
- 停写旧表与清理(1周后):确认分表集群稳定运行3天后,关闭双写,只写入分表。旧表设为只读保留7天,作为数据安全兜底,随后分批删除。
阶段二:未来扩容(例如繁中8表扩至16表)
当未来繁中数据增长至36亿,需要从8张表扩容到16张表时,一致性Hash的优势将充分体现——仅需迁移少量数据。
- 更新Hash环:新增8张物理表,每表配置100个虚拟节点,动态加入现有Hash环。路由中间件支持热加载配置,无需重启服务。
- 增量数据迁移(约6小时):开启新、旧分表间的双写。计算并迁移Hash环上被新虚拟节点覆盖的、原属于旧表的数据范围。本例中,仅需迁移总数据量的约6.25%(36亿 × 1/16 = 2.25亿行),效率极高。
- 切换与清理:同样采用灰度策略切换读流量,稳定后停止写入旧表,并清理已迁移的数据。
四、关键注意事项与避坑指南
提前分表若细节处理不当,未来仍会隐患重重。我们从这次实战中总结了三个后台开发必须牢记的要点:
1. 索引设计:面向60亿数据的“最小必要”原则
起初我们计划为每个分表建立4个索引,但压测发现,在模拟的60亿数据量下,写入性能会下降30%。原因是每个索引都是一棵B+树,写入时需要维护所有索引树。最终,我们只为每个分表保留了2个“最小必要索引”:
- 主键:采用雪花ID,确保全局唯一,避免分表间主键冲突,且未来扩容无需改动。
- 联合索引:
idx_user_dialog_create (userId, dialogId, createTime)。这个索引覆盖了90%的查询场景(如“查询用户A在对话B中最近7天的消息”),查询时无需回表,效率极高。
2. 并发控制:提前引入分布式锁
在双写阶段,由于网络延迟,可能出现同一消息被重复写入分表的情况。随着未来日增数据量达到5千万,此问题会急剧放大。解决方案是提前引入Redis分布式锁:在写入分表前,以messageId为键,通过SETNX命令获取锁,写入成功后释放。这从根本上保证了数据一致性,为未来的高并发写入保驾护航。
3. 监控体系:按“集群-实例-分表”三级构建
单表监控模式在分表架构下完全失效。我们设计了三级监控体系,以适应未来60亿数据量的运维需求:
- 集群级:监控每个语言集群的总QPS、平均延迟、错误率。
- 实例级:监控每个MySQL数据库实例的CPU、IO使用率、连接数。
- 分表层:监控每个物理分表的行数增长、索引大小、慢查询数量。
此外,增加了增长趋势预测监控,根据每日增量数据,提前一个月预警某个集群或分表即将达到性能阈值,实现 proactive 扩容。
总结
这次“面向60亿预期数据”的分表项目,最大的收获并非技术参数本身,而是强化了一个核心理念:后台架构设计必须提前适配业务增长轨迹,用最小的当下成本抵御未来的最大压力。
- 策略贴合业务:分片策略必须基于未来的核心业务查询模式(如多语言、高频查询字段)设计,而非眼前的数据分布。
- 参数面向未来:所有关键参数(单表容量、实例负载)都应按预期数据量计算,并预留缓冲空间。
- 迁移形成范式:无停机迁移的“双写+灰度”流程,即便当前数据量小也应严格执行,为未来更大规模的数据迁移积累可靠经验。
目前,该分表方案已稳定运行超过6个月,message表总数据量已增长至1.5亿,平均查询延迟始终保持在30ms以下。一切迹象表明,这套架构足以平稳支撑半年后60亿数据量的挑战。
后台架构从来不是一劳永逸的“交钥匙工程”,而是伴随业务共同成长、持续优化的旅程。提前布局看似增加了前期复杂度,但却是规避未来系统性风险、实现长期成本最优的最可靠路径。
 发表于 2025-12-13 14:03:06
|
查看: 279|
回复: 0
发表于 2025-12-13 14:03:06
|
查看: 279|
回复: 0
