在面试或实际业务中,我们常常会面对这样的挑战:如何将海量数据高效地导入到数据库中。今天我们深入探讨一个具体场景:如何以最快的速度将10亿条数据插入到 MySQL 中。
首先,我们需要与需求方(或面试官)明确边界和约束条件。假设经过沟通,我们明确了以下前提:
- 10亿条数据,每条数据大小约为1 KB。
- 数据内容是非结构化的用户访问日志,需要先解析再写入数据库。
- 数据存储在HDFS或S3这类分布式文件系统中。
- 10亿条数据并非单个巨型文件,而是被近似切分为100个文件,并且文件名后缀标明了顺序。
- 要求数据有序导入,并且尽量避免重复。
- 目标数据库是MySQL。
明确了这些约束,我们就有了设计方案的起点。
数据库单表能支撑10亿数据吗?
答案是不能。业内普遍建议的单表数据量上限是2000万以下。这个数字是怎么来的?
MySQL的索引数据结构是B+树,全量数据存储在聚簇索引(即主键索引)的叶子节点上。B+树的插入与查询性能与其层数直接相关。通常,数据量在2000万以下时,B+树为3层;超过2000万则可能达到4层,索引层数的增加会直接影响性能。
我们知道,InnoDB中每个页的大小是16KB。假设每条数据正好是1KB,那么一个叶子页大约能存放16条数据。非叶子页同样为16KB,但它只存储主键和指向子节点的指针。假设主键为BigInt类型(8字节),指针为6字节,那么每个非叶子节点可以存储大约 16 * 1024 / 14 = 1170 个索引项。
由此,我们可以计算出B+树不同层数能承载的数据量:
- 2层:1170 * 16 = 18,720
- 3层:1170 1170 16 ≈ 2190万 (约为2000万)
- 4层:1170 1170 1170 * 16 ≈ 256亿
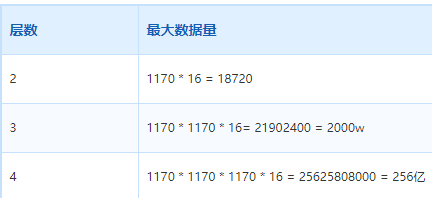
从上表可以清晰看到,当数据量达到2000万以上时,索引层数就会增加到4层。为了获得更好的性能,我们应设计单表容量在1000万级别。对于10亿条总数据,我们可以计划将其分散到约100张表中。
如何高效地将数据写入数据库?
单条逐次插入数据库的性能非常低下,批量插入是提升写入速度的关键手段。我们可以设定一个可动态调整的批量大小,例如每次批量写入100条数据。
批量写入如何保证原子性?我们可以利用 MySQL InnoDB存储引擎的事务特性,将一批数据的插入操作包含在一个事务内,保证要么全部成功,要么全部失败。
为了保证鲁棒性,写库逻辑需要支持重试机制。如果批量插入失败,可以尝试重试N次。若重试多次仍失败,可以退化为单条插入,并将失败的数据记录到日志中,允许少量数据丢失,以保证整体导入任务能够继续推进。
此外,按照主键ID的顺序写入能获得最佳性能。如果主键是乱序的,会导致频繁的页分裂与索引结构调整,严重拖慢插入速度。因此,在设计时最好先不创建任何非主键索引,待所有数据导入完成后再创建,以最大化插入阶段的性能。
能否并发写入同一张表?
不建议这样做,原因有二:
- 并发写入很难保证数据在主键维度上的有序性,从而影响插入性能。
- 通过增大批量插入的阈值(比如一次插入1000条),已经在一定程度上利用了并发能力(数据库内部处理),无需再引入应用层的多线程写同一张表。
MySQL存储引擎的选择
在历史版本中,MyISAM存储引擎的插入性能通常优于InnoDB,但它不支持事务。这意味着在使用MyISAM进行批量插入时,如果中途失败或重试,可能会导致部分数据重复插入。不过,如果纯粹追求导入速度,MyISAM可以作为一个备选方案。
那么实际性能差距有多大呢?我们参考一份性能测试数据:

从测试结果可以得出几个关键结论:
- 批量插入的性能远优于单条插入。
- 对于InnoDB,
innodb_flush_log_at_trx_commit 参数对性能影响巨大。当其设置为0或2(每秒刷新日志到磁盘)时,批量插入性能与MyISAM相差不大。
- 总体来说,MyISAM在插入场景下仍有一定性能优势。
innodb_flush_log_at_trx_commit 参数详解:
- 默认值
=1:每次事务提交都刷新日志到磁盘,安全性最高,但性能最差。
- 设置为
=0 或 =2:每秒刷新一次日志到磁盘,在系统或MySQL崩溃时可能丢失最近1秒的数据,但性能更好。
考虑到InnoDB在调整日志刷盘策略后性能尚可,且具备事务支持,我们可以优先选择InnoDB(前提是生产环境允许调整该参数)。如果线上集群策略严格,再考虑使用MyISAM。最终决策应在线上环境进行实际性能对比测试后做出。
需要进行分库吗?
MySQL单库的并发写入存在性能瓶颈,通常达到5000 TPS就已经是较高的水平了。
磁盘类型是关键影响因素:
- HDD(机械硬盘):虽然顺序读写速度快,但它不支持真正的并发写入。如果一个库下有10张表在并发写入,由于数据物理位置不同,HDD的磁头需要频繁寻道,性能会急剧下降。因此,对于HDD,应尽量避免单库并发写入多张表。
- SSD(固态硬盘):不同厂商、型号的SSD并发写入能力差异很大(如支持500MB/s或1GB/s,支持4或8个并发通道)。在未进行线上实测前,我们无法预知其确切表现。
因此,我们的系统设计需要保持灵活性,支持动态配置:
- 支持配置数据库(分库)的数量。
- 支持配置每个库并发写入表的数量。(例如,如果是HDD,可以设置为1,即同一时间只写入一个表)。
通过这种可配置的方式,我们可以灵活适配不同的硬件环境(HDD/SSD)和具体的磁盘性能,通过调整配置来持续优化导入速度。
文件读取策略
10亿条数据,每条1KB,总量约931GB,接近1TB。通常不会生成这么大的单一文件,所以假设数据已被切分为100个约10GB的文件。
为什么不切成1000个文件以增加读取并发呢?因为整个系统的瓶颈在于数据库写入。磁盘的读取速度远高于写入速度,况且写入操作还涉及SQL解析、事务、索引维护等复杂开销。写入的并发度上限受限于我们规划的表数量(100张),因此读取文件的并发度无需超过100。
更重要的是,让读取任务数量等于分表数量,可以简化模型设计:100个读取任务,对应100张写入表。
如何保证数据有序写入?
既然文件被切分为100个,我们可以设计一个规则,将文件与数据库表一一映射,确保同一个文件的数据写入同一张表,从而保证表内有序。
例如,我们可以根据文件名的后缀来分配目标库表:
index_90.txt -> database_9库, table_0表index_67.txt -> database_6库, table_7表
通过“数据库后缀 + 表名后缀”的组合,可以实现整体数据的有序性。
如何更快地读取文件?
一个10GB的文件显然不能一次性加载到内存中。常见的文件读取方式有:
Files.readAllBytes(一次性加载)FileReader + BufferedReader(逐行)File + BufferedReader(逐行)Scanner(逐行)Java NIO FileChannel(缓冲区)
下图展示了对一个3.4GB文件使用不同方法读取的性能对比:

从结果看,使用 Java NIO FileChannel 的性能优势明显。但是,FileChannel 是基于缓冲区的读取,不支持按行截断。如果缓冲区末尾恰好截断了一行数据,处理起来会非常麻烦。
相比之下,BufferedReader 虽然性能稍逊,但能天然支持按行读取,且其性能(约10秒读取10GB)对于整体以写入为瓶颈的导入任务来说,是完全可接受的。因此,我们选择使用 BufferedReader 方案。
如何协调读取与写入任务?
最初的设想是将读取和写入解耦:100个读取任务将数据投递到消息队列(如Kafka),再由写入任务消费并入库。但这带来了顺序性问题。
为了保证有序消费,需要将同一文件的数据路由到Kafka的同一个Partition。如果Partition数量少于文件数(比如10个),会导致多个文件的数据混入同一个Partition。此时,若该Partition对应的数据库因并发限制不能同时写入多张表,就会产生冲突,设计将变得异常复杂。
因此,我们放弃了解耦方案,也放弃了引入Kafka。最终方案简化为:一个任务既负责读取文件,也负责写入对应的数据库。即读取一批,写入一批。
如何保证任务的可靠性?
如果任务执行到一半,进程崩溃或需要发布重启,如何保证能从断点恢复,避免数据重复?
我们曾考虑为每条记录生成一个唯一主键ID(格式:文件后缀_行号),通过主键实现插入幂等。但这种方法在分布式多任务场景下,ID生成规则会变得复杂(需加入任务ID),且可能因长度问题引发冲突。
更优的方案是:使用Redis记录每个任务的当前处理进度。
如何控制任务并发度?
为了避免单个数据库实例因并发写入过多表而导致性能下降,我们需要限制同时执行的任务数。由于任务已合并了读写,限制任务并发度就等于限制了数据库写入并发度。
我们设计一个任务表来管理这100个子任务。表结构设计如下:

关键字段说明:
id:子任务ID。parentTaskId:总任务ID。filePath:对应的文件路径。databaseIndex/tableIndex:分配的目标库表后缀。status:任务状态(待执行、执行中、完成、失败等)。offset:当前处理进度。
那么,如何让多个工作节点来协作执行这100个任务,并控制并发度呢?
第一版方案:信号量争抢
每个工作节点定时扫描任务表,发现待执行任务后,尝试获取一个针对目标数据库的信号量(可使用Redisson实现)。获取成功则执行任务,执行完毕后释放信号量。
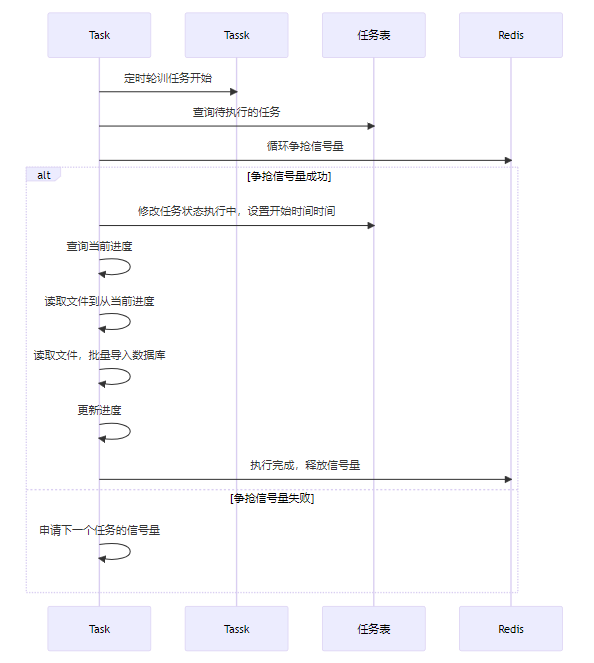
但这个方案有个致命问题:信号量超时。如果任务执行时间过长,信号量过期释放,其他节点可能抢到信号量并执行同一任务,导致重复执行。Redisson的信号量缺乏简便的“续约”机制。
第二版方案:主节点协调 + 分布式锁
我们引入一个通过ZooKeeper选举产生的主节点。由主节点负责轮询任务表,并根据当前“执行中”任务的数量和预设的并发度来分配任务:
- 情况1:执行中任务数 < 并发度。
- 主节点选取一个
待执行任务,将其状态改为执行中,并通过消息队列(如Kafka)发布任务消息。
- 任意一个工作节点消费到消息后,尝试获取以
任务ID为Key的分布式锁,获取成功则执行任务。利用分布式锁的看门狗机制实现自动续期,保证任务执行期间锁不会超时。
- 情况2:执行中任务数 = 并发度。
- 主节点检查各
执行中任务对应的分布式锁是否存活,若发现锁已丢失(说明节点崩溃),则重新将该任务置为待执行并发布。
- 情况3:执行中任务数 > 并发度(异常情况)。
此方案通过主节点集中调度避免了无序争抢,利用消息队列解耦任务分配与执行,并借助成熟的分布式锁机制解决了长任务执行期间的协调问题,鲁棒性更强。
总结
回顾整个10亿数据导入MySQL的设计,我们可以提炼出以下核心要点:
- 明确约束:设计之初必须澄清数据规模、格式、存储位置、有序性要求等所有边界条件。
- 分库分表:根据B+树原理评估单表容量,对10亿数据必须进行分表,通常也需分库以突破单库写入瓶颈。
- 批量插入:这是提升写入速度最有效的手段,需通过测试找到最佳的批量大小。
- 引擎与参数调优:在事务安全和插入性能间权衡,选择InnoDB或MyISAM,并调整如
innodb_flush_log_at_trx_commit等关键参数。
- 灵活配置:设计应支持动态调整分库数、分表数、写入并发度等,以适应不同的硬件环境和性能调优需求。
- 任务耦合:在强有序性和并发控制需求下,将文件读取与数据库写入耦合在同一个任务中,简化了系统设计。
- 状态与进度管理:利用Redis记录任务进度,是实现断点续传、避免数据重复的关键。
- 分布式协调:简单的信号量机制存在超时问题,采用“主节点选举 + 消息队列 + 分布式锁”的模式能更可靠地控制任务并发执行。
整个方案的性能最终取决于数据库磁盘I/O能力、分库分表的数量以及批量插入的阈值。这需要在线上环境中进行反复测试和调整,才能找到最优配置,实现真正意义上的“快速”导入。
在 云栈社区 中,我们经常讨论这类高并发、大数据量的系统设计难题,欢迎大家一起交流更多实战经验与优化思路。
 发表于 2026-2-1 02:10:31
|
查看: 222|
回复: 0
发表于 2026-2-1 02:10:31
|
查看: 222|
回复: 0
