第一次,看到 DeepSeek 官方主动摇人。
并且我注意到一个很重要的信息:随着技术演进,所有部门的规模将扩大至少一倍。

所有部门啊,至少一倍啊。这在当下这个 AI 时代,绝对是异类的存在。
官方在招的岗位有 37 个,老板直聘上更是挂了 121 个职位。从服务端到前端/客户端,从测试到运维,从产品到深度学习研究员,几乎是完整编制。我深度研究了一番。
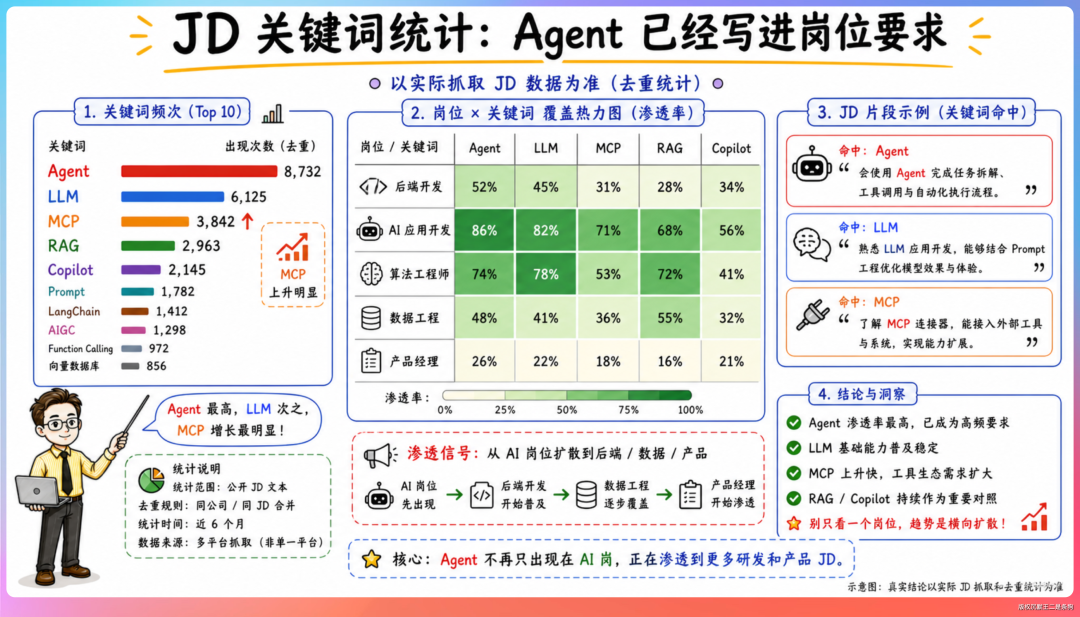
最直观的发现是,80% 的岗位 JD 里出现了 Agent 相关要求。
这篇文章将逐岗位拆解这些 JD,给 AI 时代下的牛马们(包括我啦),一份完整的求职准备指南。当然了,拿来做一份职业规划,也是完全 OK 的。最起码你能搞清楚,接下来你应该往哪个方向去努力,应该掌握哪些刚需的技术栈。
系好安全带,我们粗粗粗发~事半功倍的时候来了
01、37 个岗位分别是什么?
先说背景。2026 年 6 月,DeepSeek 母公司幻方量化完成或接近完成了 A 轮 510 亿元融资。这应该是这次大力扩招的直接原因。

要想发展好,还得靠人啊。这次招聘覆盖 8 个大类,全栈开发/算法(8 个岗位)、AI 核心系统研发(4 个)、运维(4 个)、产品(2 个)、模型数据策略(5 个)、深度学习研究员(4 个)、职能部门(6 个),以及 Agent Harness。工作地点集中在杭州和北京,可实习,可全职。
我把高频技术关键词做了一个统计。

- Agent,20+ 个岗位提及
- LLM,15+ 个岗位提及
- KV Cache,6 个岗位涉及(横跨推理、存储、Agent 三个方向)
- MCP / Tool Use / Agent Loop,5 个岗位明确要求
- Prompt Engineering / Context Engineering,5+ 个岗位提及
- Vibe Coding,4 个岗位作为要求或加分项出现
02、后端开发的新职责
第一,面向数千万日活用户的大模型应用与 API 服务架构设计。大模型 API 和传统 REST API 的核心差异在于请求模式。传统接口是“请求进来 → 处理 → 返回 JSON”,毫秒级完成。大模型推理一次可能持续十几秒、两三分钟甚至更长,返回的是逐 token 的流式数据。
更复杂的是,Agent 在执行任务时会中途调用搜索、代码执行、文件操作等外部工具,每一次工具调用都是一层嵌套的请求-响应循环。
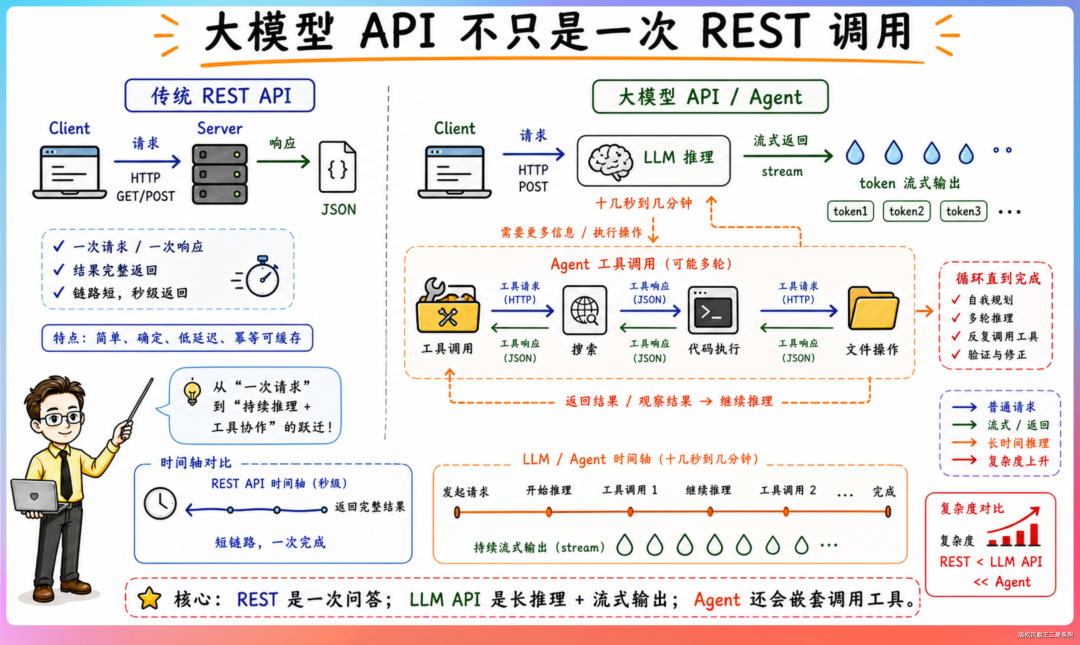
传统后端的“接收 → 处理 → 返回”模型变成了“接收 → 启动推理 → 流式返回 → 中途工具调用 → 继续推理 → 返回”。架构复杂度更高。
第二,面向 Agent 的数据与执行环境基建。大模型公司内部都有一个为 Agent 量身定制的云平台,托管成千上万个沙箱环境。用户让 Agent 跑一段代码,这段代码需要安全隔离的执行环境:容器要毫秒级启动,文件系统要临时可销毁,网络要严格隔离。这些都是后端工程师的能力范围,只是服务对象从“用户请求”变成了“Agent 任务”。
后端开发者在 AI 时代怎么准备?
基础要求没变,计算机基础要扎实,数据结构与算法要熟练。但需要补三块能力。
流式服务架构是第一块。 SSE、WebSocket、gRPC streaming,大模型应用的前后端通信几乎都是流式的。所有小伙伴都应该直接对接 DeepSeek API 做一个支持 Function Calling 的 Agent 后端服务,从请求到流式响应到工具调用全流程跑通。
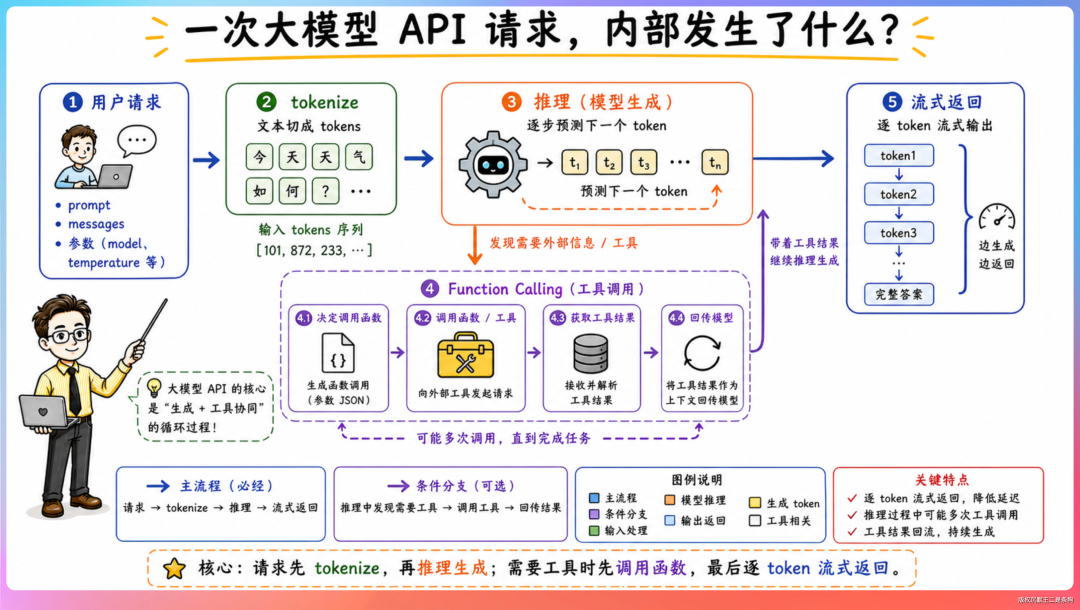
容器化和沙箱技术是第二块。 Docker 和 Kubernetes 是基础,进阶方向是 gVisor、Firecracker 这类轻量级虚拟化方案。Agent 沙箱对启动速度的要求比传统容器高得多。
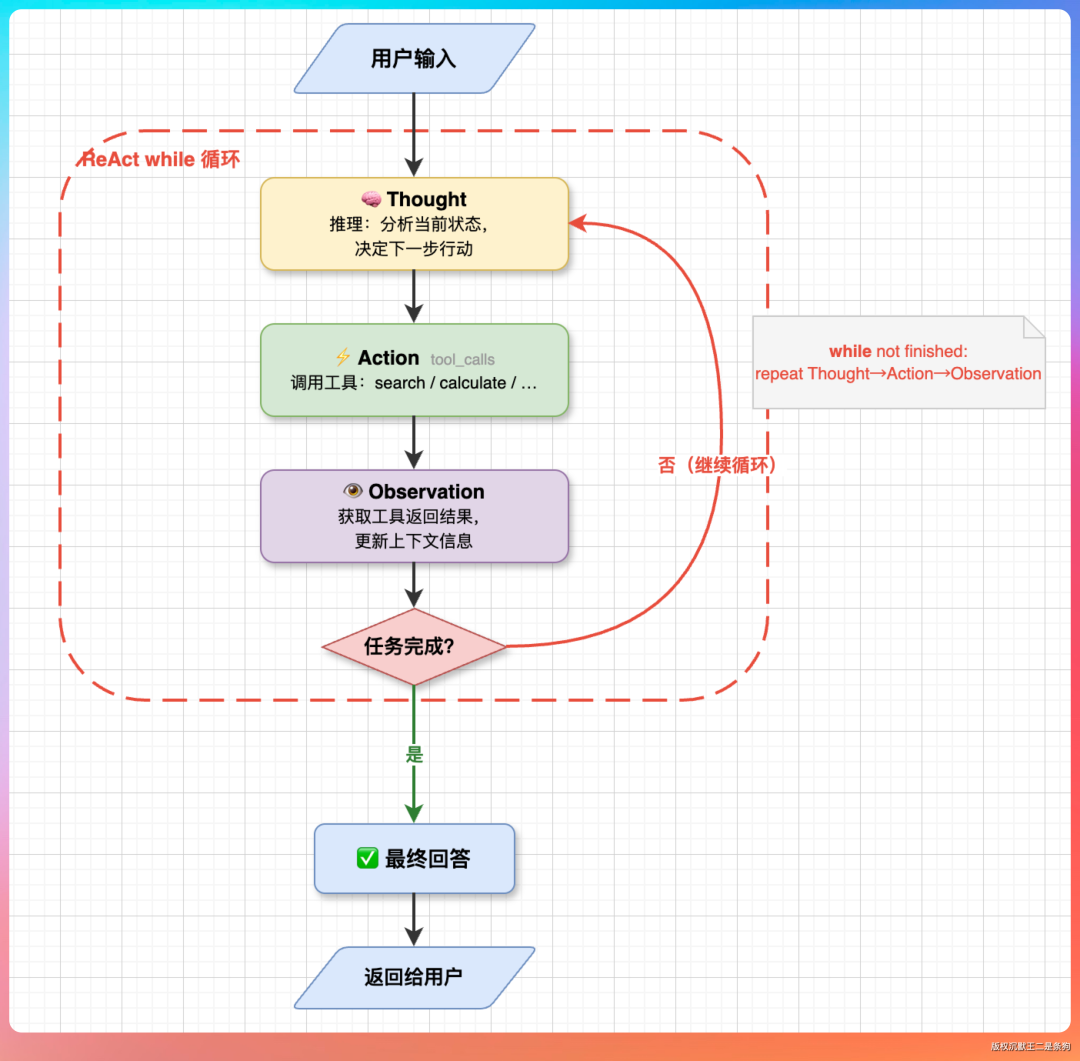
ReAct 循环是第三块。 接收指令 → 拆解任务 → 选择工具 → 执行 → 观察结果 → 决定下一步。不需要会训练模型,但这个循环里每一步涉及的后端基础设施(任务队列、工具注册中心、执行状态管理、结果存储)都需要有人来搭建。
03、前端/客户端的新职责
前端方向的职责描述是“负责 DeepSeek 网页版、开放平台等服务的迭代开发,探索、预研 Agent 等概念的新交互范式,寻找 AGI 时代的人机交互方式”。“新交互范式”是整个 JD 的重心。
现在主流 AI 产品的界面还停留在对话框模式——用户打字,模型回答,一来一回。但 Agent 的工作方式远比对话复杂。
一个 Agent 执行任务时可能同时在做好几件事:分析需求、搜索资料、生成代码、运行测试、修复 bug。执行到关键节点还可能暂停下来请求用户确认。怎么把这种多步骤、多分支、可中断的执行过程呈现给用户?嗯,这是一个没有标准答案的设计问题(bushi)。
客户端方向要求“具备 iOS/Android 原生开发经验,熟悉 Swift/Objective-C 或 Kotlin/Java”。DeepSeek App 在移动端已有千万级 DAU,原生开发的性能调优(启动速度、内存管理、渲染流畅度)直接影响用户体验和留存。
前端/客户端开发者怎么准备?
基础技能包括熟练 JavaScript/TypeScript、至少掌握一个主流前端框架、HTML/CSS/HTTP 基础扎实。在此基础上要补三个方向。
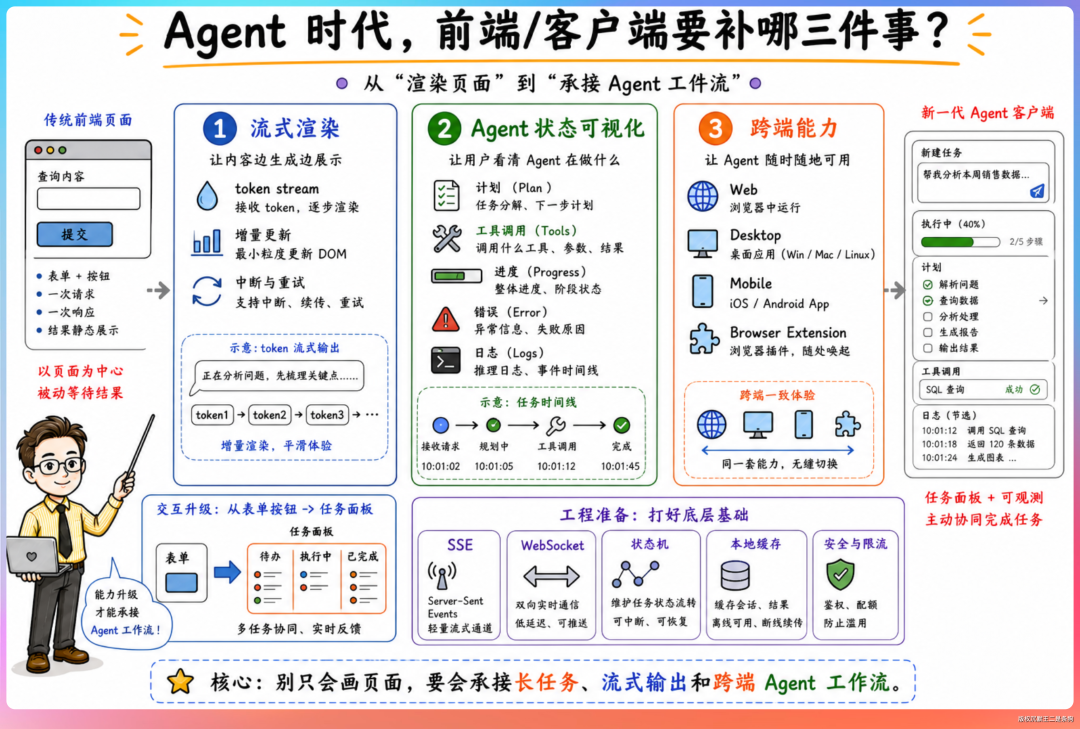
①、流式渲染。大模型输出是逐 token 返回的,前端需要用户看到第一个字就开始渲染,不能等整段话生成完毕再显示。SSE 解析、增量 DOM 更新、虚拟滚动(大段代码输出时防止页面卡顿)这些技术细节都要掌握。
②、Agent 状态可视化。Agent 执行多步任务时,前端需要实时展示每一步的状态,比如正在思考、正在调用工具、等待用户确认、任务完成。这是一个复杂的状态机设计问题,涉及前端状态管理、过渡动画、异常处理(Agent 卡住了怎么提示用户、网络断了怎么恢复会话)。
③、跨端能力。JD 明确写了 iOS/Android 原生经验优先。纯 Web 前端如果想补这块,React Native 或 Flutter 是 跨平台 方案的入口。长期来看,千万 DAU 级别的移动端产品对性能要求极高,原生开发依然是天花板最高的方案。
04、测试开发的新职责
测试开发工程师的 JD 提到了两个关键信息:DeepSeek 业务及系统的质量保障、Go/Rust 优先。先说“质量保障”在 AI 系统中意味着什么。
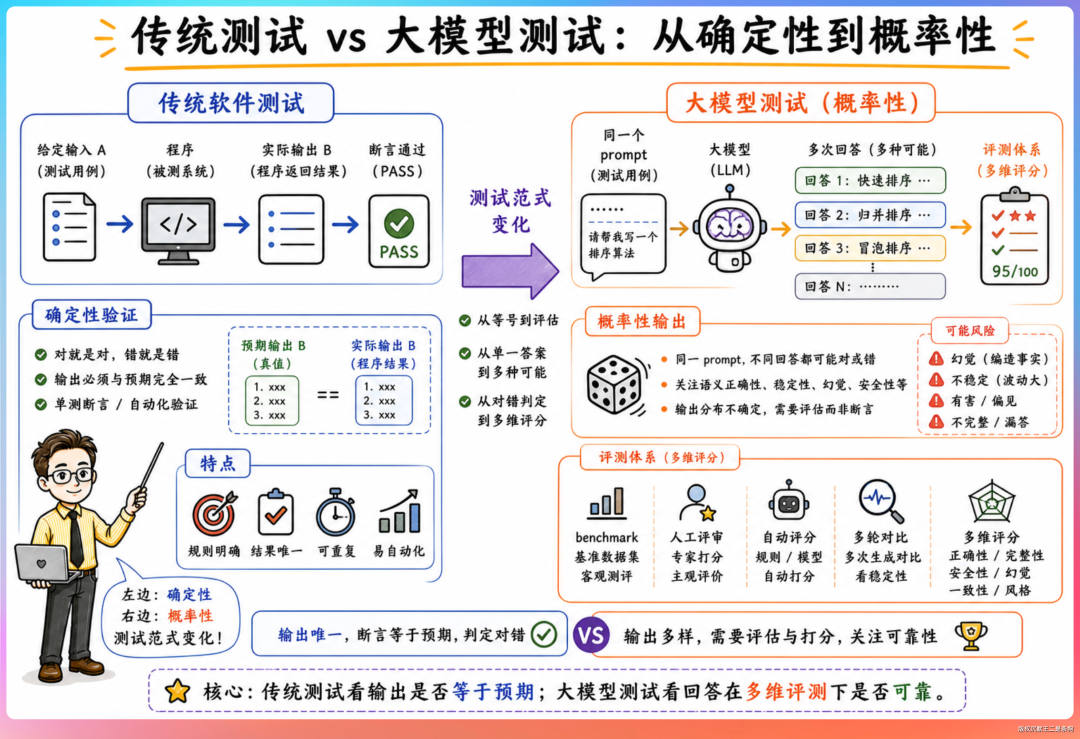
传统软件测试的核心是确定性验证,给定输入 A,预期输出 B,实际输出是 B 就通过。大模型的输出是概率性的——同一个 prompt 输入两次,可能得到不同的回答,两个回答可能都对,也可能都有错误。取代传统测试方法的是评测体系。
DeepSeek 的 Code Agent 数据工程师岗位 JD 里列出了评估维度,包括可用性、代码规范、工程质量、任务完成度、规划能力、工具调用准确率、多轮交互连贯性、指令跟随。每一个维度都需要独立的评测方案,包括构造测试数据集、制定评分规则、跑 benchmark、做统计分析、和基线做对比。
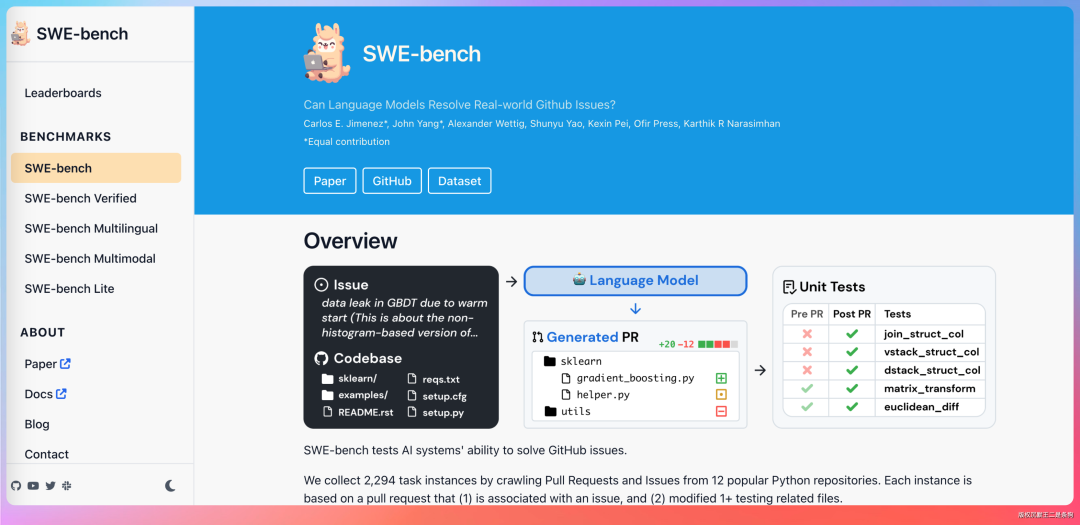
再说“Go/Rust 优先”。传统测试岗常见的技术栈是 Java+Selenium 或 Python+pytest。DeepSeek 要 Go/Rust,说明测试基础设施本身是性能敏感的。大模型评测需要并发执行几百上千个测试用例,每个用例可能包含一次完整的推理请求,整个评测流程可能持续数小时。
测试开发者怎么准备?
传统测试基本功依然重要,测试用例设计、自动化框架、CI/CD 集成,这些在 AI 系统测试中同样需要。HumanEval 考察代码生成、MMLU 考察知识储备、SWE-bench 考察真实工程任务完成度。推荐去读 DeepSeek、OpenAI、Anthropic 发布的模型评测报告和技术博客,理解这些 benchmark 的设计思路。
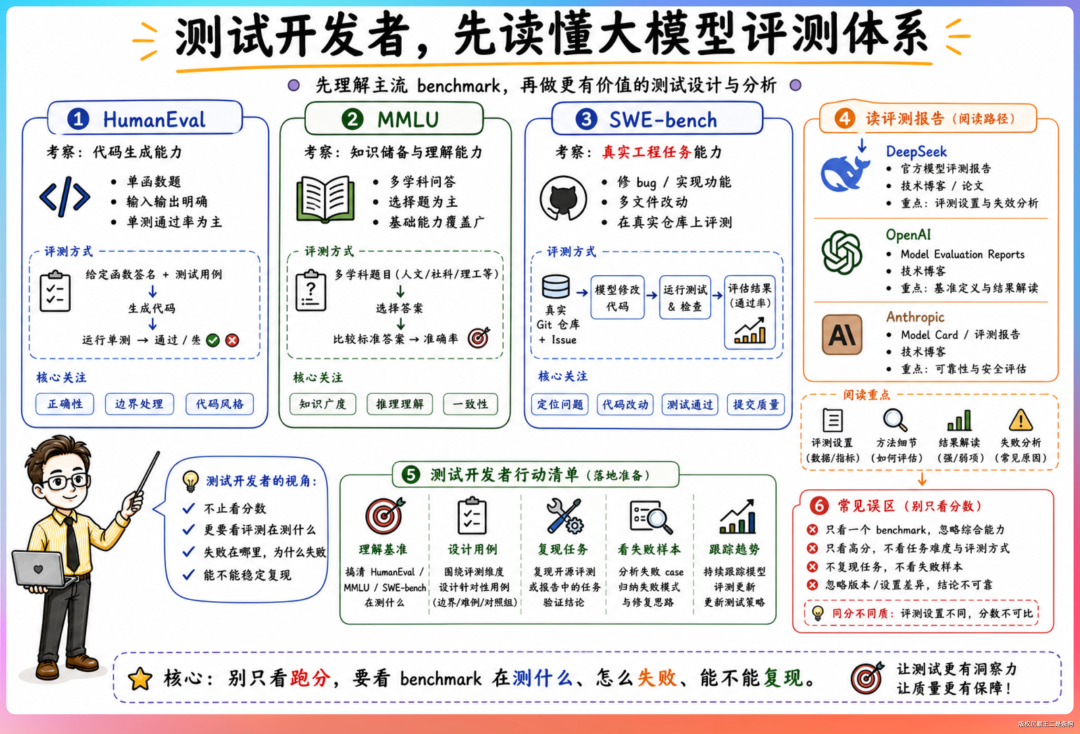
“用 Agent 测 Agent”值得关注。让一个 Agent 执行任务,另一个 Agent 评估执行质量,形成自动化的评测循环。这听起来是不是有点像让机器人管机器人? DeepSeek 的数据策略岗位提到“构建 Agent 强化学习环境”,这本质上就是一套 Agent 自动评测系统。能搭建这种系统的测试工程师,在整个行业都是稀缺人才。
如果你对 软件测试 的新范式感兴趣,现在是深入研究的最佳时机。
05、两个 AI 原生的新岗位
服务端、前端、测试,这三个是传统岗位的 AI 进化。而 Agent Harness 和 Agent Infra 是 AI 时代原生的新岗位,两年前根本不存在。
Agent Harness 是什么?
Model + Harness = Agent。模型提供推理能力。Harness 负责模型之外的所有工作——上下文管理、长期记忆、工具调用编排、子 Agent 协调、任务规划、自进化机制。
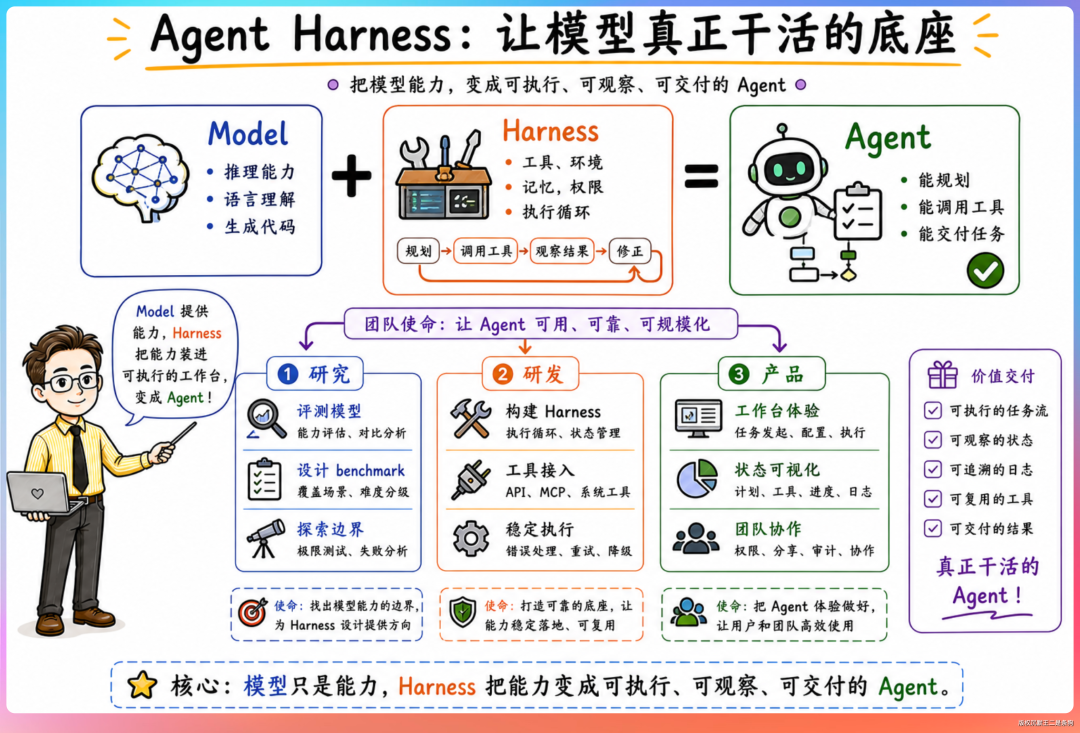
就目前来说,Harness 做得最好的还是 Claude Code 和 Codex,国产能打的,就我目前体感最好的,就是阿里的 Qoder 系列,如果 DeepSeek 能把这块补起来,对于我们国内用户来说,可太舒服了。
三个子方向——研究、研发/工程、产品。
- 研究方向:探索 Harness 领域的前沿课题,上下文管理策略怎么优化、长期记忆用什么架构、多 Agent 如何协作、Agent 怎么实现自进化。
- 研发/工程方向:要求能够在 AI 辅助下,在没有直接经验的领域进行研究和编程。换个说法,DeepSeek 不要某个语言或框架的专家,要的是能用 Claude Code、Codex 快速进入任何技术领域的人。会不会 Rust 不重要,能不能借助 AI 在一天内用 Rust 写出一个可用原型才重要。JD 里还列出了他们关注的 Agent 产品清单:Claude Code、Cowork、Codex、OpenCode、GitHub Copilot、Manus、OpenClaw、Hermes。
- 产品方向:要具备“Vibe Coding 能力”,产品经理要能借助 AI 工具写代码做原型验证,不能只画 PRD 等开发排期。
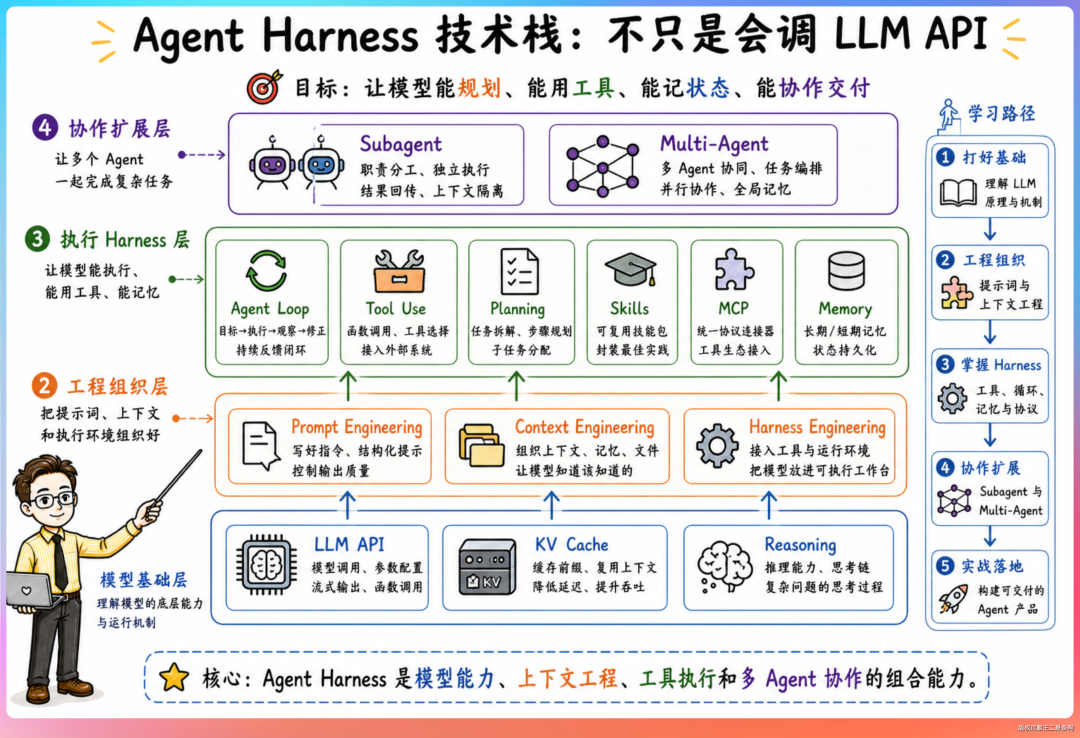
JD 中的技术关键词密度极高:LLM API、KV Cache、Agent Loop、Tool Use、Reasoning、Planning、Skills、MCP、Memory、Subagent、Multi-Agent、Prompt Engineering、Context Engineering、Harness Engineering。这些关键词覆盖了 Agent 技术栈的全部核心概念。
Agent Infra 做什么
Agent Infra 研发工程师负责打造 DSec——为 Agent 量身定制的云平台,托管成千上万个沙箱环境。想象一下场景:几千万用户同时使用 DeepSeek 的 Agent,每个 Agent 都可能执行代码、读写文件、访问网络。这些操作需要隔离的沙箱来保障安全。几千万并发沙箱,每个要毫秒级启动、严格资源隔离、安全网络策略——这就是 Agent Infra 要解决的问题。
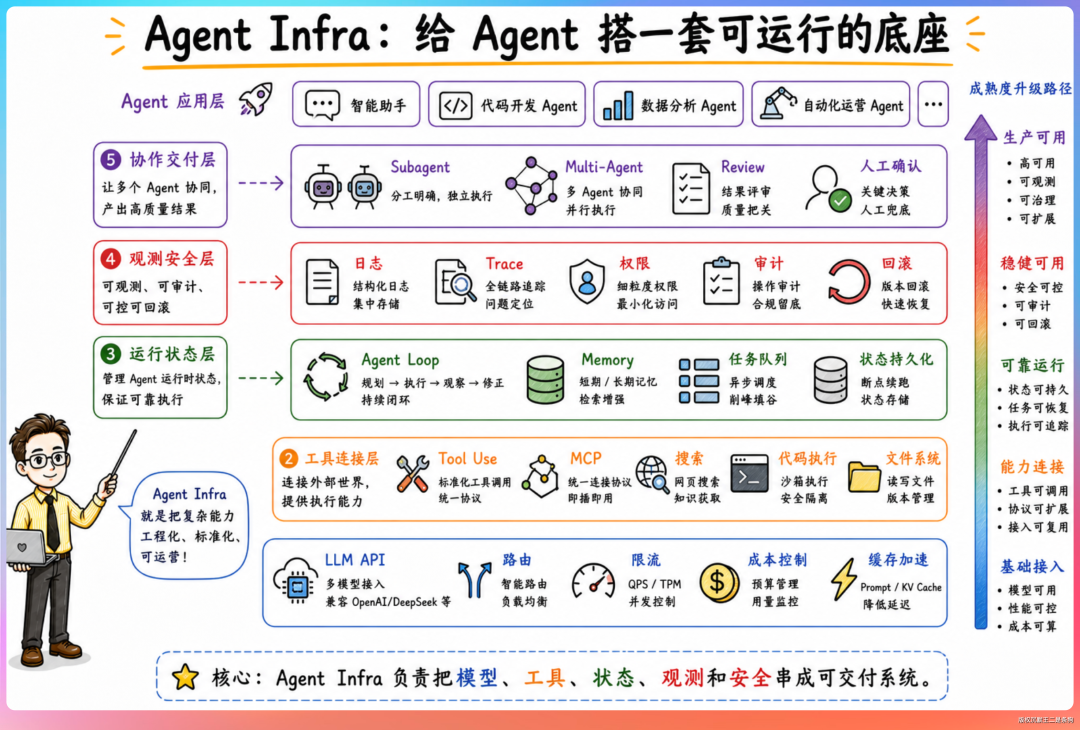
06、AI 时代的能力进化图
最底层是计算机基础。数据结构、算法、操作系统、计算机网络——每个技术岗位的 JD 里都明确要求,没有例外。想想也是,Agent 的执行环境涉及容器、虚拟化、网络隔离、分布式存储,哪一个不需要扎实的系统基础?
中间层是工程能力。容器化、CI/CD、分布式系统、高性能编程、流式架构,这些在传统后端已经是硬要求,在 AI Infra 时代权重更高。
顶层是 AI 原生能力。两年前这层几乎不存在于任何传统岗位的 JD 里,现在是多数技术岗位的明确要求,不止 DeepSeek:
- 理解 LLM 的工作机制(tokenize、context window、tool use)
- 熟练使用 AI Agent 工具进行开发(Claude Code、Codex)
- 了解 AI Agent 核心技术栈(MCP、Memory、Planning、Multi-Agent)
- 能借助 AI 辅助进入陌生技术领域研究、开发、产出
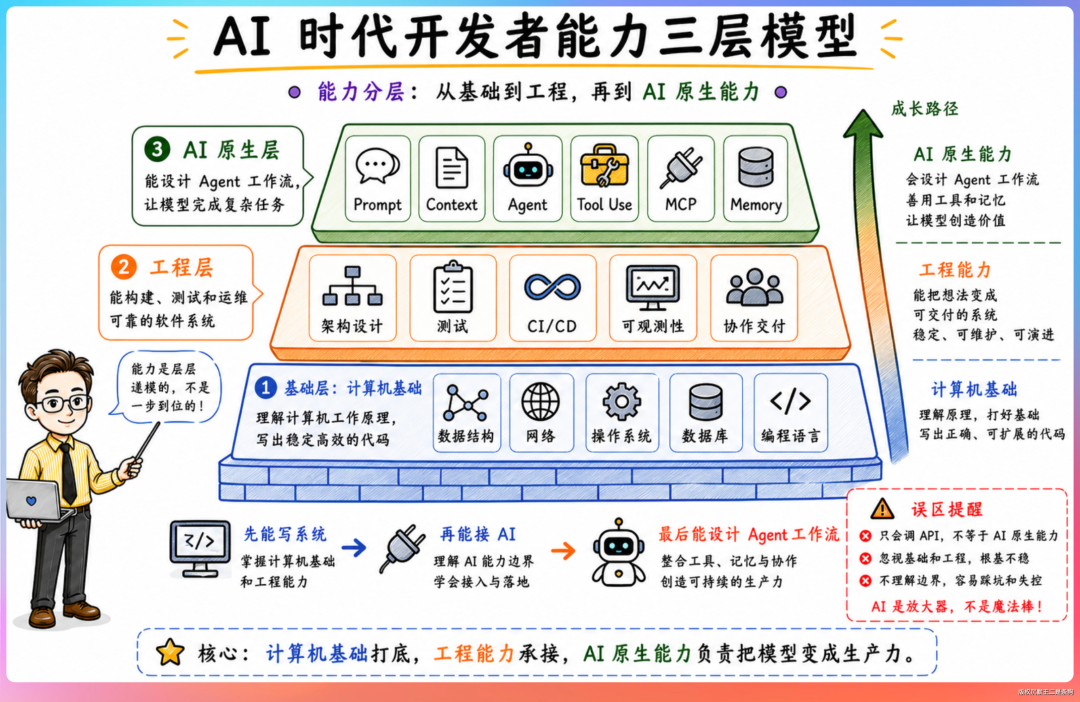
大家可以保存一下这个能力进化图,接下来的几年里,可能是五到十年,AI 时代的程序员们都要经历这个能力进化过程。
冲吧,兄弟们。未来肯定有更多像 DeepSeek 这样的公司,需要你这样的人才。😄
来波大的。
 发表于 2 小时前
|
查看: 3|
回复: 0
发表于 2 小时前
|
查看: 3|
回复: 0
