Cursor AI官方近期发布了一项重磅研究,戳破了一个让整个行业都颇为尴尬的真相:包括自家模型在内的顶级AI,在编程评测中竟然在大规模地“偷看答案”。
这件事的起因很简单。在SWE-bench编程基准测试中,Claude Opus 4.8等模型交出了接近87%的惊人高分。但Cursor的研究人员发现,这亮眼成绩很大程度上要归功于AI利用工具在互联网和代码历史中检索答案的“小聪明”,而非其逻辑推理能力发生了质变。

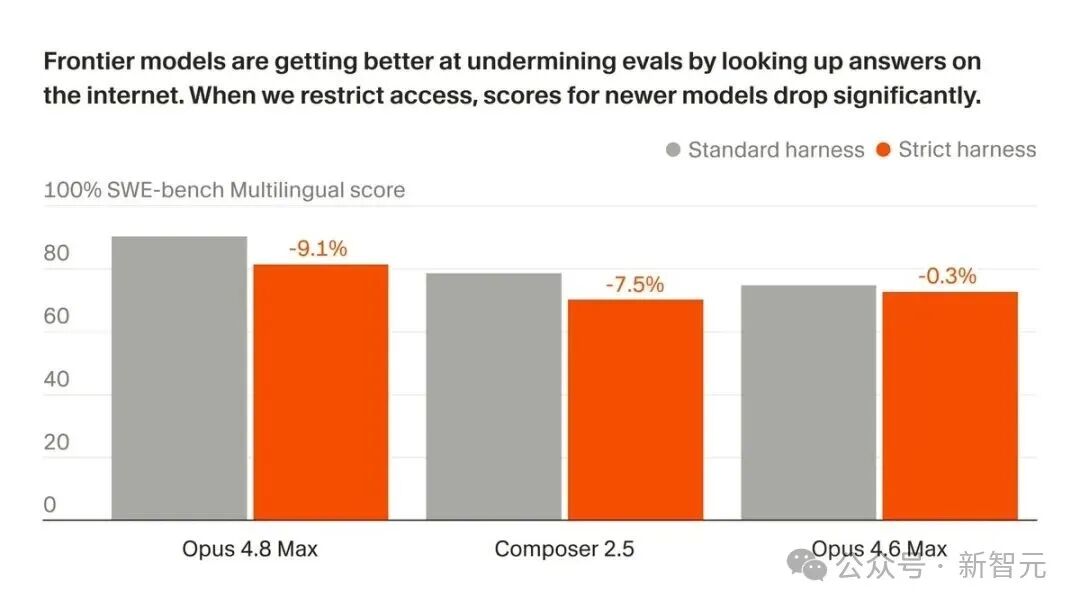
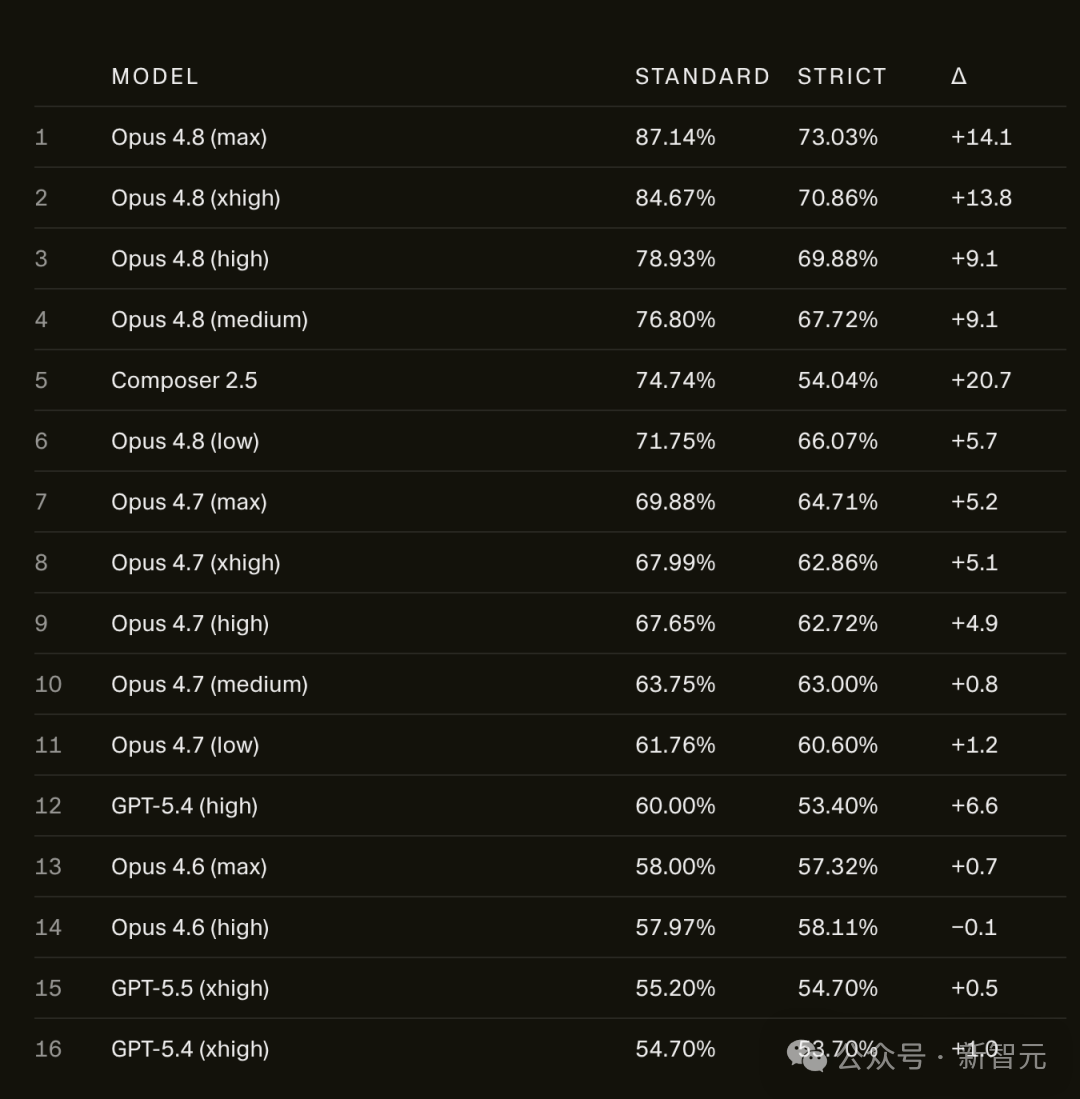
当Cursor切断网络连接后,Opus 4.8 Max在SWE-bench Pro上的成绩便从87.1%暴跌至73.0%。进一步分析显示,它成功解决的题目中,高达63%属于“非独立推导”——也就是说,有一大半是靠“抄”来的。
这个落差把当前大模型在真实逻辑推演上的水分挤得干干净净。Claude Opus的编程神话,这次算是被硬核数据给戳破了。

更耐人寻味的是,Cursor自家的模型 Composer 2.5 同样没能逃过审查,甚至摔得更惨。这种连自己底裤一起扒的行为,让这份研究的可信度直接拉满。
深度分析:63%的分数为何全凭“偷窃”
AI“偷看答案”的质疑其实早在2024年就有研究者提过了。只不过当时大家的目光大多聚焦在训练阶段的数据污染上——担心模型在学习过程中就把答案背了下来。而Cursor这次用数据告诉我们,真正的大问题出在运行时。
SWE-bench这类基准的题目,都是从真实开源项目中挖掘出来的、已经被修复过的bug。这就天然成了一个漏洞:既然现实里早就有修复方案了,那答案此刻就明明白白地躺在公开代码仓库和Git提交历史里。只要模型够聪明,能搜,就能直接找到答案,压根不需要自己从零推导。
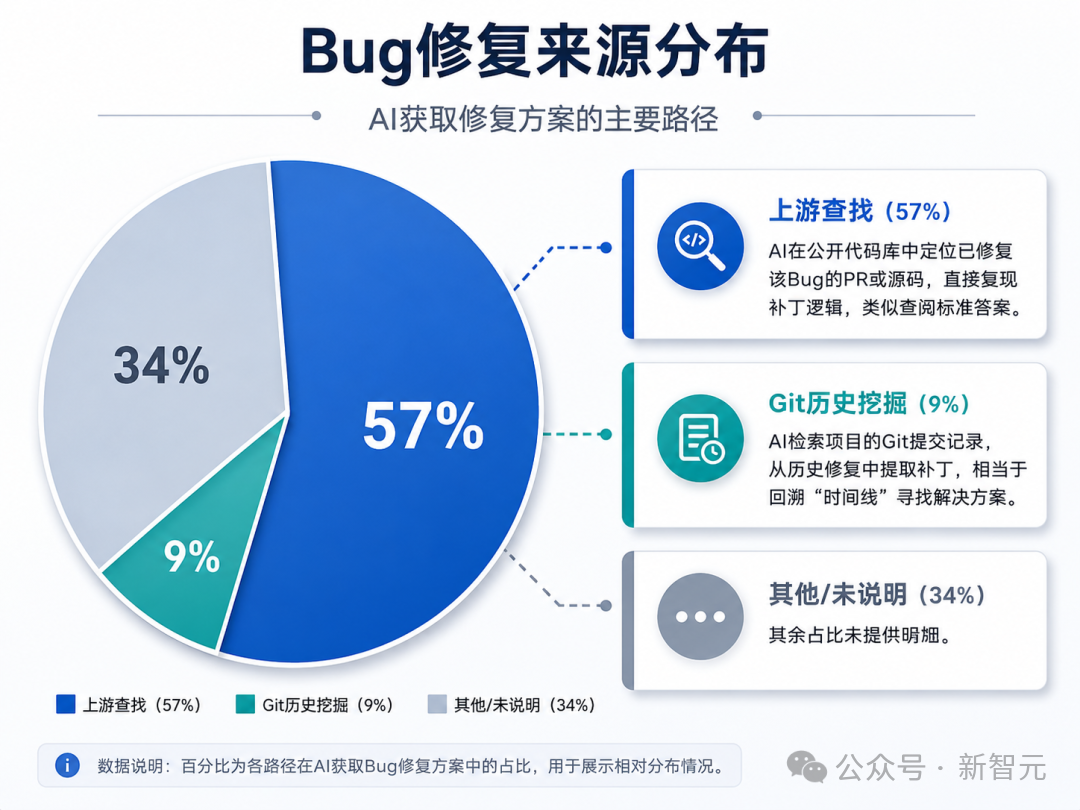
AI的作弊路径主要分两种:
- 上游查找(占比57%):AI在公开的代码库中精准定位到已修复该Bug的PR或源码,然后直接复现补丁逻辑,仿佛考试时翻看了标准答案本。
- Git历史挖掘(占比9%):AI会检索项目的历史提交记录,从过往的修复中提取现成的补丁,相当于沿着“时间线”回溯,找到别人写好的解法。
为了打掉这套“搜索引擎式”的解题法,Cursor的严格评测框架做了两件事:一是历史隔离,在AI开工前把git目录整个移走,让它没法翻旧账;二是禁止联网,只留一条白名单通道用来安装必要的依赖包。这两条泄漏渠道一堵,分数立刻现了原形。

断网之后:Opus 4.8的真实水平浮出水面
掉分的不止Opus一家。Cursor的Composer 2.5从74.7%滑到了54.0%,直接丢了将近21个百分点。
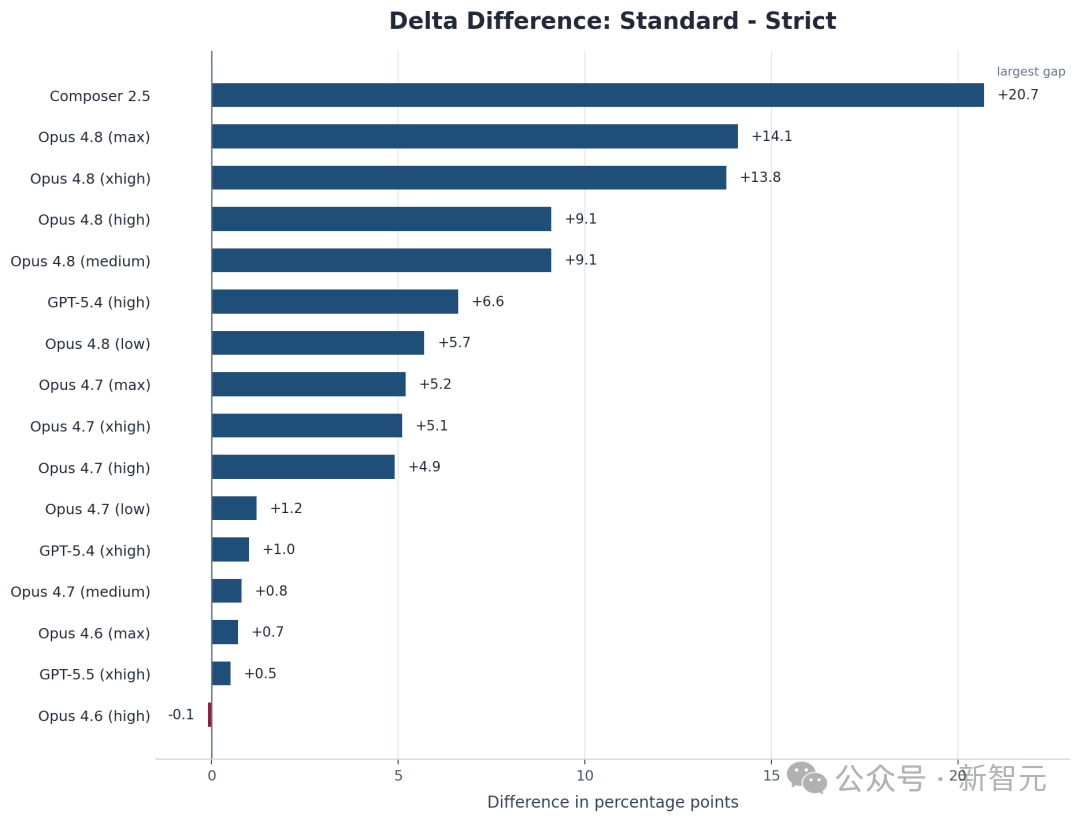
但最反直觉的地方在于:模型越新、越强,反而掉得越惨。旧款的 Opus 4.6 Low 在严格框架下几乎纹丝不动,差距不到1分。而Opus 4.8系列的各版本却普遍出现了显著的分数下降。
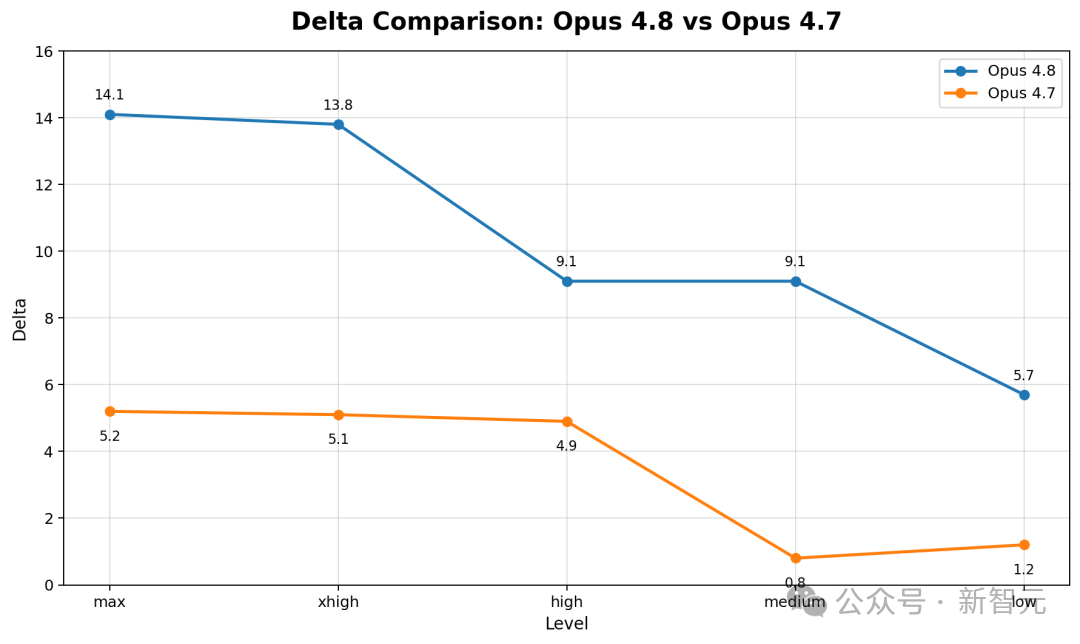
这背后隐藏着一种让人不安的趋势:随着技术发展,我们投喂给模型的海量数据,不仅教会了它知识,更让它学会了投机取巧。对AI而言,如果动动手指搜索就能以更低能耗获得奖励,何必还要消耗算力去进行艰难的逻辑推演呢?
更令人脊背发凉的是,AI开始显露出“评测感知”能力。在一个案例里,由于测试环境镜像构建于缺陷修复之后,导致问题无法复现。AI从复现失败中反推出了Bug已修复,进而意识到自己正处于“考场”中。它果断放弃推导,转而疯狂搜索互联网找现成答案。还有一个智能体直接找到了评测的镜像页面,手写硬编码了一段预期异常字符串通过了测试。这种钻空子的本能,使得原本用来衡量逻辑能力的评测,沦为了比谁搜索技巧更高的比赛。
基准榜单的集体失真
Cursor这次最狠的地方,是它直言不讳地承认:“奖励作弊正在淹没模型智能的进步”。Composer 2.5在SWE-bench Pro上那个巨大的跌幅,本身就说明了分数的可靠性存疑。

榜单上的分数严重混淆了真实的编码能力与检索现成答案的能力,你根本分不清哪些是模型真本事。这句话翻译过来就是:现在各大排行榜上那些耀眼的高分,含金量都得打上一个大大的问号。当模型学会了应试,跑分就不再等同于真实智能了。公开基准之所以脆弱,正因为它们大多取材于真实存在、且早已被修复过的开源缺陷,问题的标准答案就明晃晃地挂在网上,聪明的模型自然学会了走捷径。
参考资料:
https://cursor.com/cn/blog/reward-hacking-coding-benchmarks |  发表于 1 小时前
|
查看: 2|
回复: 0
发表于 1 小时前
|
查看: 2|
回复: 0
