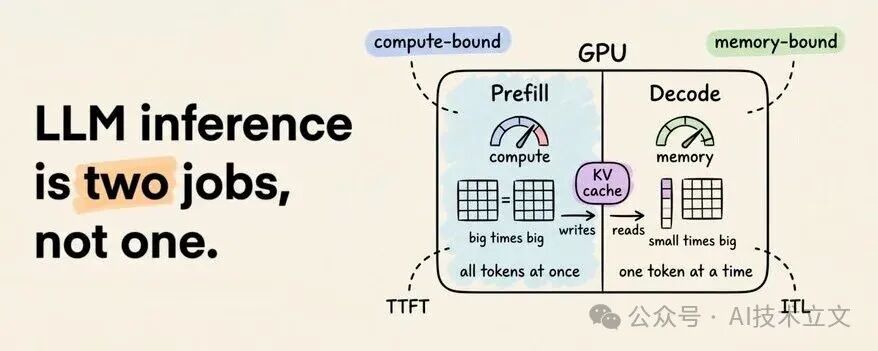
每次调用 LLM 的 generate() 函数,都会在同一块 GPU 上经历两个截然不同的计算阶段:
- prefill:处理你的输入 prompt,主要受计算能力限制;
- decode:逐个生成 token,主要受内存带宽限制。
大多数推理优化手段都只针对其中一个阶段发力。想让部署真正快起来,第一步就得诊断清楚——瓶颈到底卡在哪一步。
这篇文章会从分词后的输入一路讲到流式输出,把整条流水线走通,同时看清每个阶段的时间都消耗在哪里。
1. 分词与嵌入
Byte Pair Encoding(BPE)这类 tokenizer 会把原始文本转换成词表里的整数 ID。词表规模通常在 50,000 个 token 左右。
prompt = "How does inference work?"
ids = tokenizer.encode(prompt)
# ids -> [2437, 1374, 32278, 670, 30]
每个 ID 会映射到词嵌入表中对应的一行。Embedding Table 是一个形状为 [vocab_size, hidden_dim] 的可学习矩阵。对于 hidden dimension 为 4,096 的模型,每个 token 会变成一个 4,096 维的向量。
# embedding_table has shape [vocab_size, hidden_dim]
vectors = embedding_table[ids] # shape: [num_tokens, 4096]
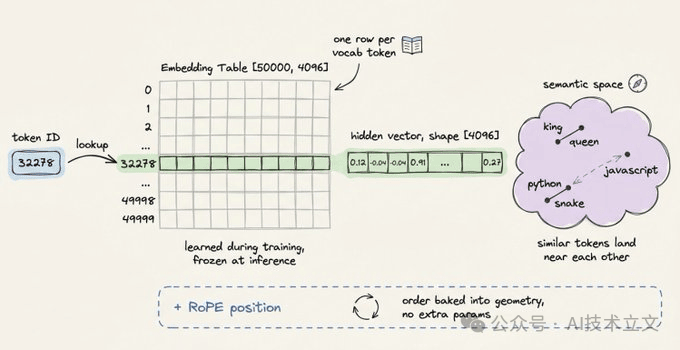
位置信息也会在这一步注入。多数现代架构使用 Rotary Position Embeddings(RoPE),它不会额外增加位置向量,而是通过旋转 embedding 向量来编码位置信息。
嵌入后的序列会穿过一组 Transformer 层,层数通常在 32 到 80 以上,取决于模型规模。每一层依次执行两个操作。
1. Self-attention
通过可学习的权重矩阵,为每个 token 计算三组投影:Query Q、Key K 和 Value V。
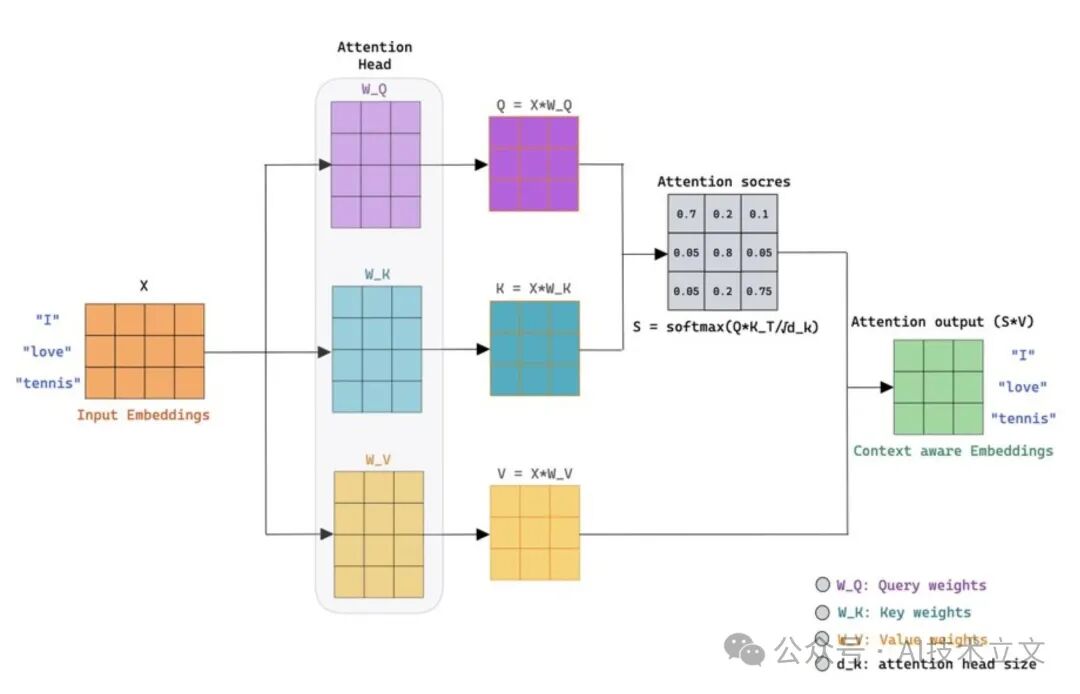
每个 token 的 Query 会和其它所有 token 的 Key 计算相似度分数。分数经过 scaling 和 softmax 之后,决定了各 token 的 Value 以多大权重混合进当前 token 的表示中。
# scores: how much each token attends to every other token
Q, K, V = x @ Wq, x @ Wk, x @ Wv
scores = (Q @ K.T) / sqrt(d_k)
weights = softmax(scaled) # one row per token, sums to 1
attn_output = weights @ V
2. Feed-forward network(FFN)
用两层 MLP 独立处理每个 token 的向量。你可以这么理解:Attention 负责在不同位置之间传递信息,而 FFN 负责变换每个位置上的表示。
最后一层结束后,模型把最后一个 token 的 hidden state 投影回词表大小,即 [hidden_dim, vocab_size],再做 softmax,从得到的分布里采样出第一个输出 token。
3. Prefill:计算受限阶段
处理输入 prompt 是第一阶段。所有 token 会并行处理:每个 token 的 Q、K、V 同时算好,attention 以大型矩阵乘矩阵(matmul)的形式运行。
这是一个 compute-bound 的工作。瓶颈在于 GPU 的算术吞吐量,GPU 利用率通常很高。衡量这个阶段的指标叫 TTFT(Time to First Token),也就是从请求发出到第一个输出 token 出现的延迟。
prefill 阶段还会顺便填满 KV cache:每一层的 K 和 V 张量都会存进 GPU 显存,供后续反复读取。
# Prefill: process the whole prompt in one shot
hidden = embed(prompt_tokens) + positions
for layer in model.layers:
Q, K, V = project(hidden) # for ALL tokens at once
hidden = attention(Q, K, V) + hidden
hidden = feedforward(hidden) + hidden
cache_kv(layer, K, V) # save for later
first_token = sample(project_to_vocab(hidden[-1]))
4. Decode:内存受限阶段
第一个 token 生成后,模型便切换到逐个 token 生成的模式。对每个新 token,模型只计算这个 token 的 Q、K、V——之前的 K 和 V 已经在缓存里了。
# Decode: one token per iteration
token = first_token
steps = 0
while token != STOP and steps < MAX_STEPS:
x = embed(token) + position(steps)
for layer in model.layers:
q, k, v = project(x)
K_all, V_all = caches[layer].append(k, v) # cached history + new
x = layer.forward(q, K_all, V_all, x) # attention + FFN, residuals
token = sample(project_to_vocab(x))
steps += 1
yield token
每一步的算术量都很小。它只用一个 query 向量跟缓存里的 key 矩阵做运算,不再是完整的矩阵乘法。但 GPU 仍然要为这次“小计算”从显存中加载所有权重矩阵,以及完整的 K/V 缓存。瓶颈就从计算吞吐切换到了内存带宽。
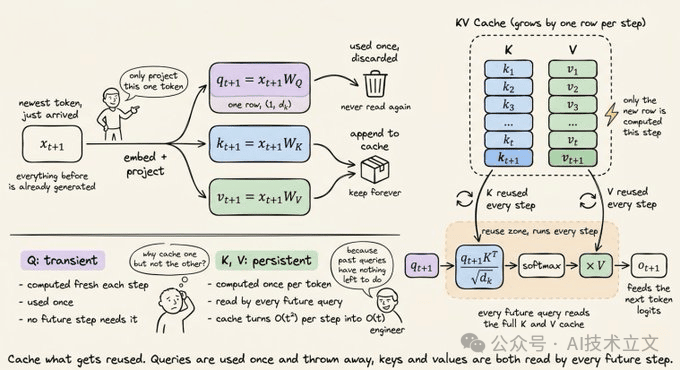
衡量这个阶段的指标是 ITL(Inter-Token Latency),也就是连续两个输出 token 之间的时间。ITL 越低,模型的响应就越流畅,用户体感越“丝滑”。
5. KV 缓存
如果没有缓存,生成一个 1,000-token 的回答,每一步都得在持续增长的完整序列上重新计算 attention,计算复杂度会变成平方级。
KV cache 把每一层的 K 和 V 张量存下来,并在生成时增量追加。对于长输出,这通常能带来 5 倍甚至更高的提速。
代价也很直接——缓存会随序列长度线性增长,而且每一层都有自己的专属缓存。拿 13B 参数的模型来说,每个 token 的缓存大约消耗 1 MB。一个 4K-token 的上下文,光 KV cache 就能吃掉 4 GB 显存。这也就是长上下文为啥昂贵。
缓存会直接跟 batch size 争夺 GPU 内存。单个请求占的缓存越多,同一块 GPU 能承载的并发请求就越少。
常见的缓解手段包括:把缓存量化到 INT8 或 INT4;使用 sliding window attention 丢弃窗口之外的过时 token;用 grouped-query attention(GQA)让多个 attention head 共享 K/V 以压缩缓存量;以及 vLLM 背后的 PagedAttention,像操作系统管理虚拟内存那样分页管理缓存,从而消灭碎片。
6. 围绕缓存重新设计注意力
量化和分页策略都把 KV cache 看作一项需要管理的固定成本。而 2026 年 4 月 24 日发布的 DeepSeek V4 Preview 走了另一条路:直接重新设计注意力机制,让缓存从骨子里变得更小。

V4 混合了两种压缩注意力机制:
- Compressed Sparse Attention (CSA):先用 softmax-gated pooling 将 KV 条目压缩 4 倍,再做 sparse attention。
- Heavily Compressed Attention (HCA):更激进,把 128 个 token 的 KV 合并成一条压缩条目,在压缩表示上执行 dense attention。
在 1M-token 上下文的场景中,相比 DeepSeek-V3.2,V4-Pro 的单 token 推理 FLOPs 只要 27%,KV cache 只需 10%。换算成直观数据:bf16 下 1M 上下文每条序列需 9.62 GiB 的 KV cache;同条件下 V3.2 风格的架构估算需要 83.9 GiB。若再叠上 fp4/fp8 量化,缓存还能再缩一半。
KV cache 已然成为硬约束,模型架构正在围绕它快速演进。
7. 量化
训练时为保障梯度稳定,通常使用 FP32 或 BF16。推理则不需要这种精度。降低 bit width 带来的内存节省是线性的:
- 7B 参数,FP32:28 GB
- 7B 参数,FP16/BF16:14 GB
- 7B 参数,INT8:7 GB
- 7B 参数,INT4:3.5 GB
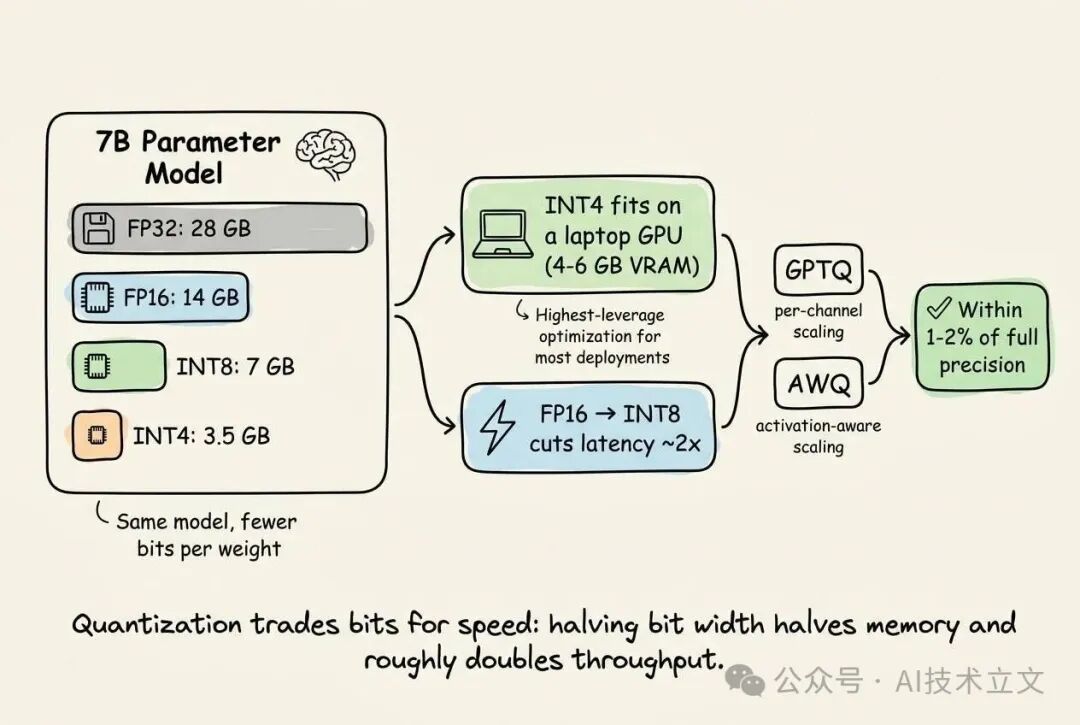
INT4 正是 7B 模型能够跑在 4~6 GB 显存的笔记本 GPU 上的原因。GPTQ 和 AWQ 等方法通过引入 per-channel scaling factors,尽可能弥补有损压缩带来的质量损失。做得好的 INT4 模型在标准 benchmark 上往往只比全精度模型低 1~2 个百分点。
从 FP16 降到 INT8,推理延迟通常能砍半,质量损失几乎可以忽略。对绝大多数部署场景来说,量化是投产比最高的优化手段。
8. 推理服务基础设施
现代推理服务器会在 prefill-decode 循环外围再加一组优化:
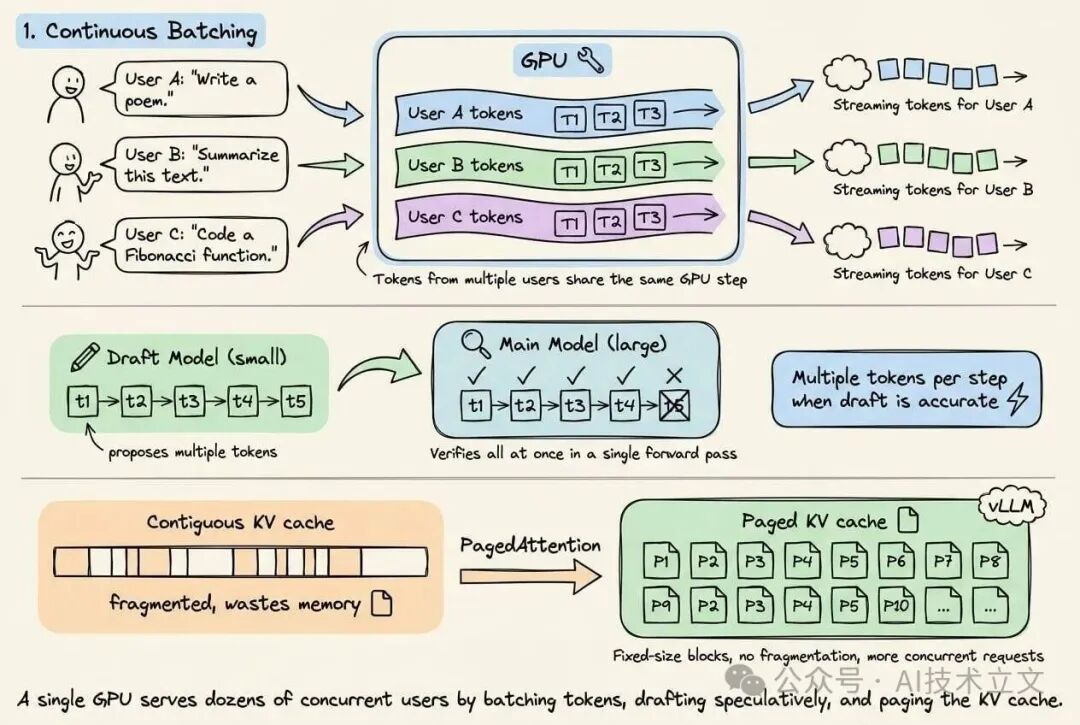
- Continuous batching 在同一个 GPU step 中交错处理多个请求的 token,即便处在 memory-bound 的 decode 阶段也能维持较高的利用率。
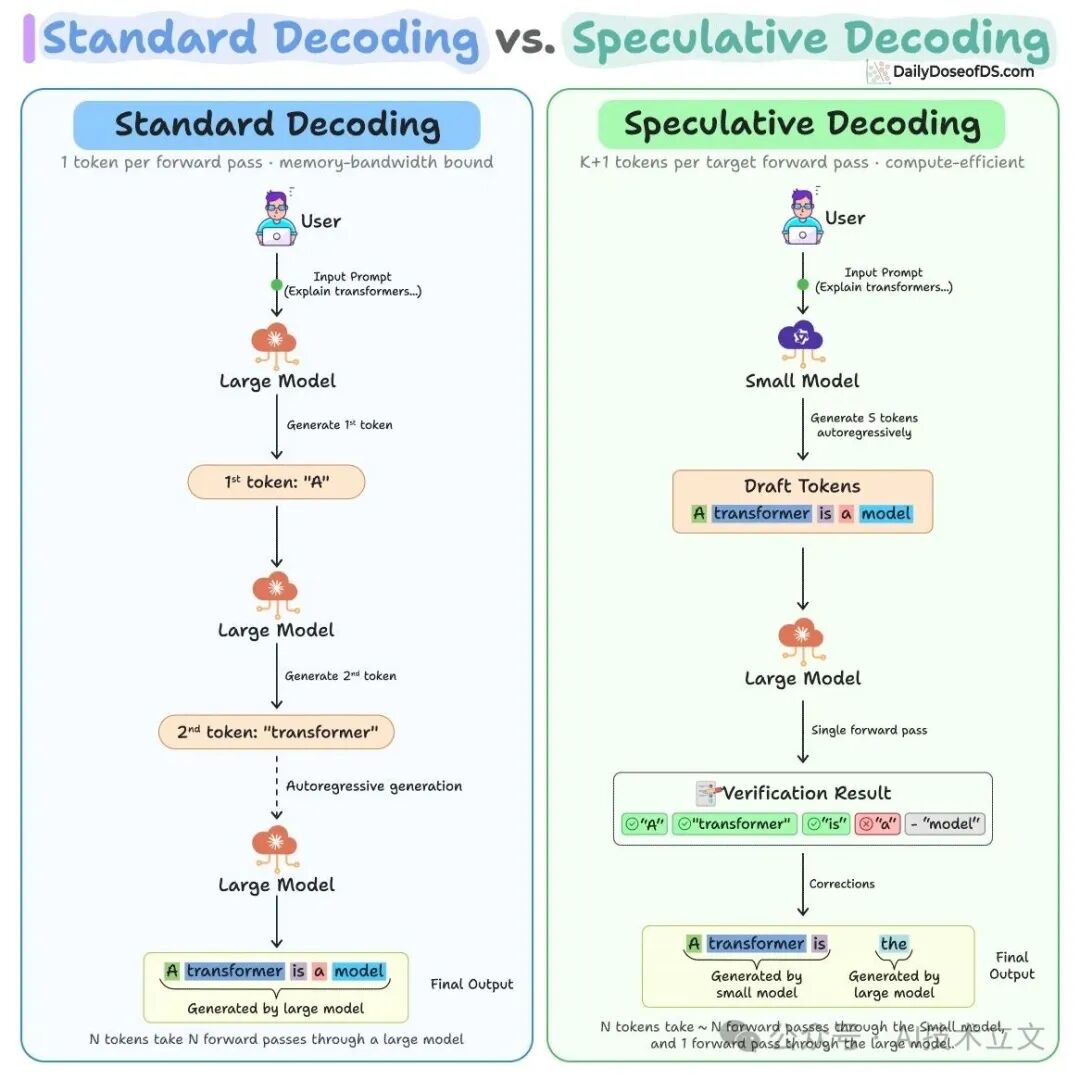
- Speculative decoding 先用小型的 draft model 提出一串候选 token,再由大模型在一次 forward pass 中统一验证。只要 draft model 的接受率够高,就能把多次串行的 decode step 压缩成一次并行验证。
- PagedAttention(vLLM) 将 KV cache 内存切成固定大小的 block,从根本上消除了碎片,让单块 GPU 能同时服务更多请求。
vLLM、TensorRT-LLM、Text Generation Inference(TGI)这类框架把这些技术组合在一起。因为 decode 阶段留出了大量闲置算力,continuous batching 就能拿其他请求的 token 来填满,一块 GPU 是可以实实在在地撑起几十个并发用户的。
9. 完整推理路径
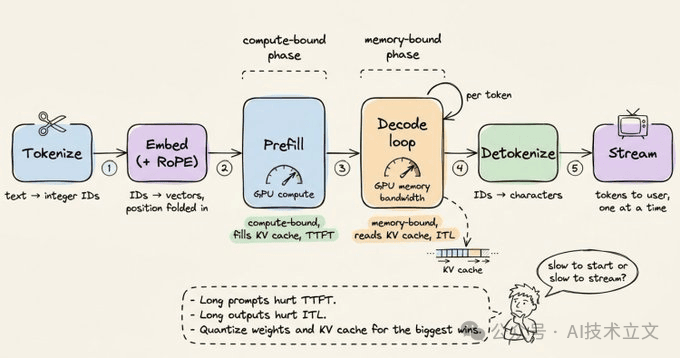
- Tokenize:文本经 BPE 变成整数 ID。
- Embed:ID 变成向量,RoPE 编码位置。
- Prefill:所有输入 token 并行经过每一层。compute-bound,填充 KV cache,并输出第一个 token。
- Decode loop:逐 token 生成。为新 token 投影 Q,对缓存里的 K/V 做 attention,跑 FFN,采样,并把新 K/V 追加进缓存。memory-bound。
- Detokenize:token ID 映射回文本字符并流式输出。
10. 一些实践结论
- 长 prompt 的成本主要表现为 TTFT,集中在 prefill 阶段。
- 长输出的成本主要表现为 ITL,集中在 decode 阶段。
- 这两个阶段消耗的是不同类型的硬件资源。
- 上下文长度并不免费。它会膨胀 KV cache,直接拉低并发处理能力(batch capacity)。
- decode 阶段即便服务器看起来已经满载,GPU 利用率也可能跌到 30%,因为瓶颈在内存带宽,不在计算单元。
- 解决方法往往不是堆更多算力,而是用更快的内存、更小的缓存,或者更高明的 batching 策略。
当有人抱怨“模型太慢了”,第一步诊断可以这样切入:它是启动慢,还是流式输出时一个字一个字往外蹦?启动慢多半是 prefill-bound,得从优化 TTFT 下手;流式输出卡顿多半是 decode-bound,那就该重点优化 ITL。
 发表于 5 小时前
|
查看: 4|
回复: 0
发表于 5 小时前
|
查看: 4|
回复: 0
