之前搭了个网络攻击行为监控系统,最近对它的分析结果有点怀疑。比如针对某台云服务器的 Web 攻击,当前系统给出的分类长这样:
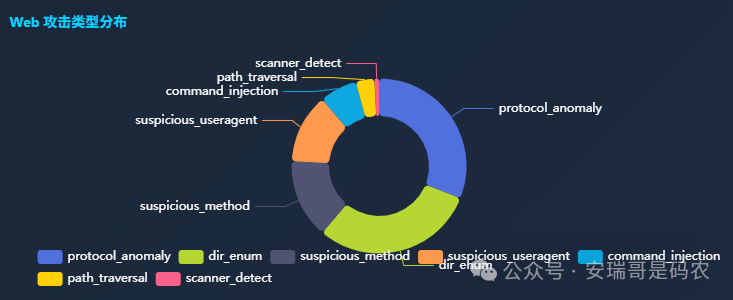
这些攻击名或类型是怎么得出来的呢?靠的是请求体里的「关键字匹配」——URL 里包含 /bin/sh、cmd=、wget 就判为 command_injection(命令注入);出现 ../、%2e%2e 就叫 path_traversal(路径遍历)。问题就在于,这种规则太糙了,准确度不够。
怎么提高准确率?我想到了一个办法:让见多识广的大模型来干这事。类似的操作 7 年前我用 Spark 流式任务做过一回,这次换成 Flink,直接从 Kafka 里读出外部 Web 请求数据,把 URL 扔给 大模型(LLM API) 做判别,然后 Flink 把返回结果规整成固定 schema,再写入库。整体架构长这样:
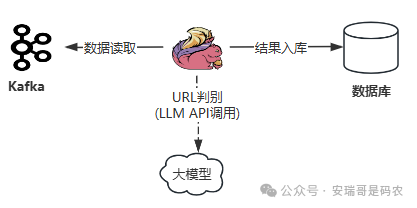
因为 LLM API 属于外部调用,不需要额外功能支持,所以不挑 Flink 版本,只要能跑就行。我就沿用项目里在用的 Flink 1.20。
想法有了,具体编码自然扔给 AI 去做。
1. 设置 Prompt
编码里最有意思的大概就是这个 prompt 的设置了,分两部分:系统提示词和问题提示词。
系统提示词长这样,核心是给大模型约定一个回答边界和输出模板:
req.addProperty("system",
"你是网络安全告警分析专家。判断每条告警的真实性。\n" +
"分类:REAL_ATTACK(真实攻击)/ FALSE_POSITIVE(误报)/ " +
"SUSPICIOUS(疑似)/ BENIGN_SCAN(正常扫描)\n" +
"输出严格JSON:{\"verdict\":\"...\",\"confidence\":0.0-1.0," +
"\"reason\":\"理由\",\"action\":\"block_ip|whitelist|investigate|ignore\"}");
最终扔给大模型的 HTTP 请求体长这样(后面通过 HTTP 接口调用):
{
"model": "deepseek-v4-flash",
"max_tokens": 512,
"system": "你是网络安全告警分析专家...",
"messages": [{
"role": "user",
"content": "告警详情:\n时间: ...\n来源IP: 66.132.195.52\n..."
}]
}
2. 推理返回
大模型返回的内容结构类似下面这样,content 字段里 type 为 text 的部分就是我们需要的结果:
{
"id": "693809de-...",
"type": "message",
"role": "assistant",
"model": "deepseek-v4-flash",
"content": [
{
"type": "thinking",
"thinking": "PRI方法用于HTTP/2探测,状态码400表明请求无效..."
},
{
"type": "text",
"text": "{\n \"verdict\": \"BENIGN_SCAN\",\n \"confidence\": 0.7,\n \"reason\": \"PRI方法用于HTTP/2探测...\",\n \"action\": \"ignore\"\n}"
}
],
"stop_reason": "end_turn",
"usage": {"input_tokens": 150, "output_tokens": 80}
}
然后解析 text 里的 JSON,得到模型推理结果,再通过 HTTP 方式写入 ClickHouse。
3. 踩坑实录
这个 Flink 任务的逻辑虽然不复杂,但跑起来还是踩了不少坑,AI 和我一起折腾了好几个小时才搞定。不知道是不是因为最近把模型从 GLM-5.2(号被封了)换成了 DeepSeek-v4,能力似乎有点跟不上。
3.1 坑01——异步改同步
本来想着调用外部大模型肯定耗时,为了不阻塞上游 Kafka 数据流入,LLM API 请求必须用异步方式。但重试几次发现不行:
- 在 executor 里发 HTTP 请求时,线程会卡在
HttpURLConnection.connect();
AsyncDataStream 的 timeout(60 秒 / 180 秒)一到,就触发 completeException;- 此时 executor 线程还在等 HTTP 响应,永远不会
complete resultFuture。
这个状态反复出现,异步方案怎么都跑不通,最后只能改回同步。好在当前的数据流量和处理并行度还撑得住。
3.2 坑02——用 Gson 代替 Jackson
不得不换,是因为又遇到了 jar 包冲突。项目引入的 Jackson 版本跟 Flink 1.20 自带的版本不兼容,直接报了错:
Caused by: java.lang.ClassNotFoundException: com.fasterxml.jackson.databind.ObjectMapper
at java.net.URLClassLoader.findClass(Unknown Source) ~[?:?]
果断换成 Gson,万事大吉。
3.3 坑03——ClickHouse JDBC 协议不匹配
这个坑我是第一次遇见。以前往 ClickHouse 写数据一直用的 JDBC,跑过无数 Flink 任务都没问题,这次却怎么都不行。错误长这样:
java.io.IOException: Magic is not correct - expect [-126] but got [-67]
AI 给出的解释是:ClickHouse JDBC 驱动 0.6.0 默认使用 native 协议(端口 9000),但我的 ClickHouse 实际跑在 8123 端口(HTTP 协议)。JDBC 尝试用 native 协议去连 HTTP 端口,收到的第一个字节就是 HTTP 响应的魔术字,校验失败。
解决办法是弃用 JDBC,直接走 ClickHouse 的 HTTP 接口,用 FORMAT TabSeparated 批量写入:
POST http://42.xx.xxx.xx:8123/?query=INSERT INTO alert_triage FORMAT TabSeparated
虽然我对这个解释半信半疑,但跑通之后也懒得再深究了。
最后
一番折腾后,Flink 调用外部 LLM 的链路总算跑通了,攻击数据经过大模型推理后顺利入库。不过这过程真的费劲,期间要不是我几次打断 AI 让它按我的思路来,估计还要耗更久。经这几次测评,感觉现阶段哪怕是编程能力顶级的国产模型,在面对 Flink 这种稍复杂的组合任务时,第一次交付的结果还是不能让人完全满意。
 发表于 3 小时前
|
查看: 5|
回复: 0
发表于 3 小时前
|
查看: 5|
回复: 0
