“Kafka太重?Pulsar太复杂?那试试Walrus吧——一头用Rust写的、会游泳还会扛流量的海象。”
最近在技术社区,一个名为Walrus的项目引起了广泛关注。它自称是“High Performance Kafka alternative written in Rust”,短短一句介绍,就包含了巨大的信息量:
- Kafka替代品 → 旨在解决现有流式处理平台的痛点
- High Performance → 性能是其核心优势
- Written in Rust → 依托于内存安全、零成本抽象和无畏并发的现代语言
今天,我们就来深入探讨这头“海象”的设计理念与技术实现,分析它为何敢于挑战消息队列领域的领导者,以及Rust语言在其中扮演的关键角色。它的架构能否真正兼顾高性能、高可用与简单性?更重要的是,它是否适用于我们的实际场景?
一、为什么需要新的流式处理引擎?
或许有人会问:“Kafka不是挺好的吗?为何要重复造轮子?”
这个观点在五年前或许成立。然而,随着云原生、Serverless和边缘计算的快速发展,传统Kafka的“重量级”架构在某些场景下开始显现出局限性。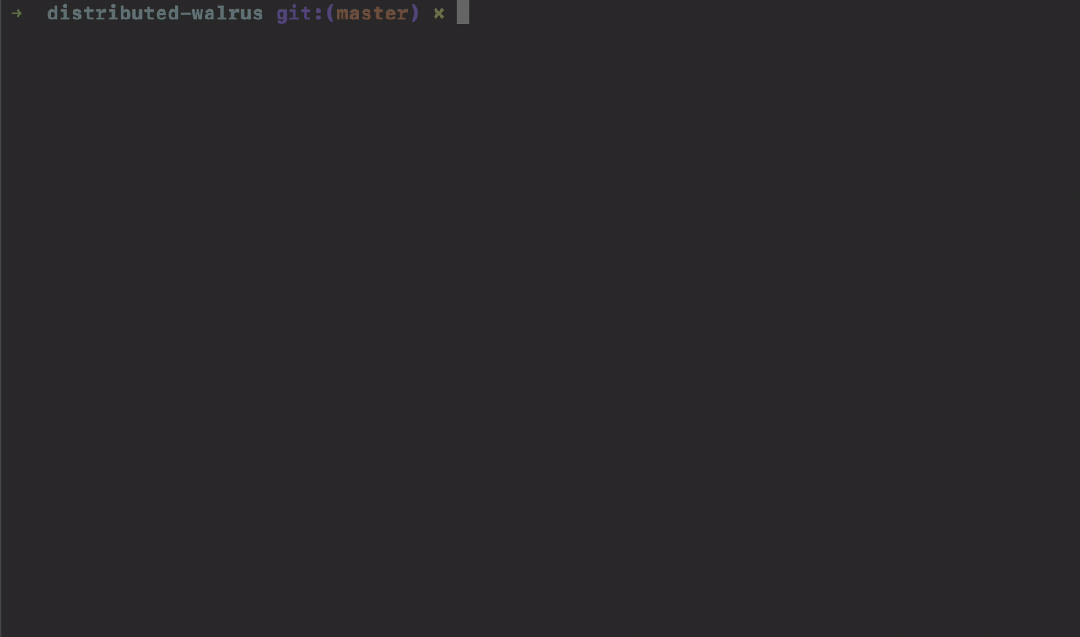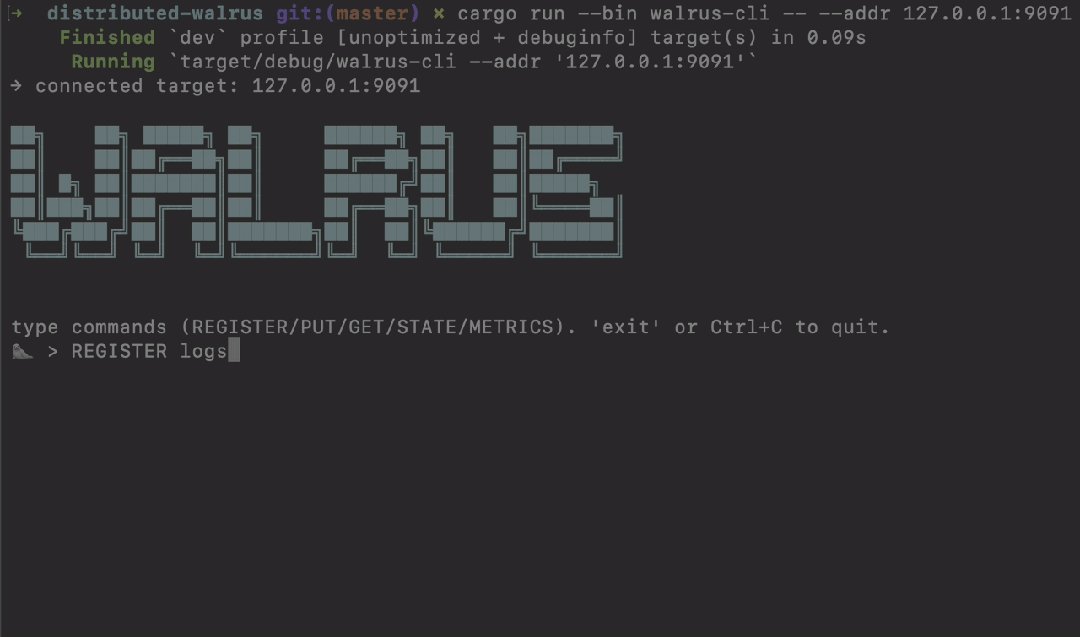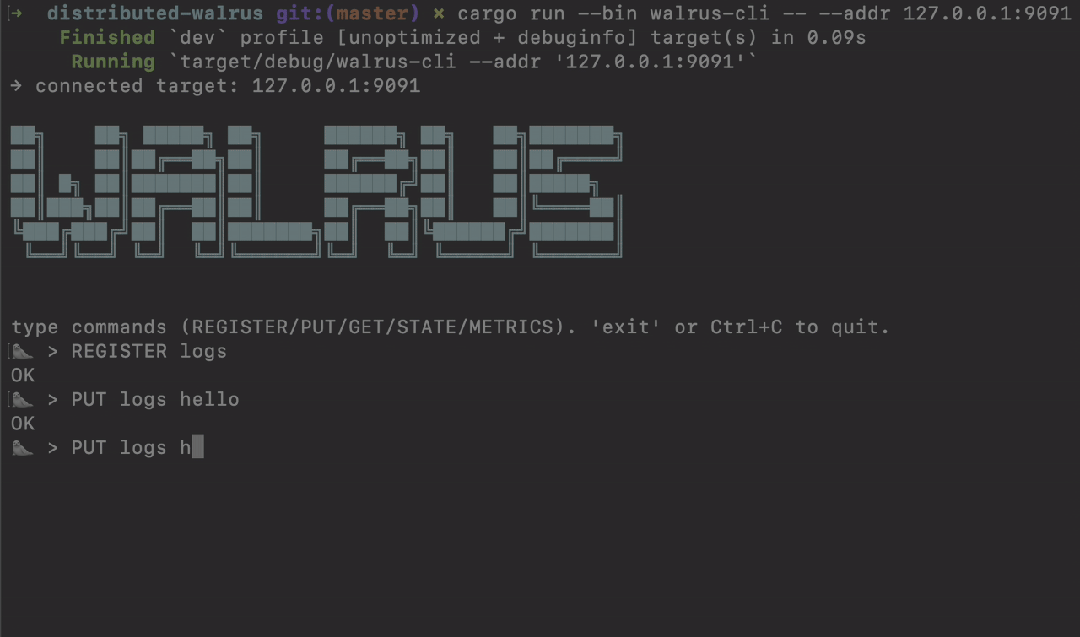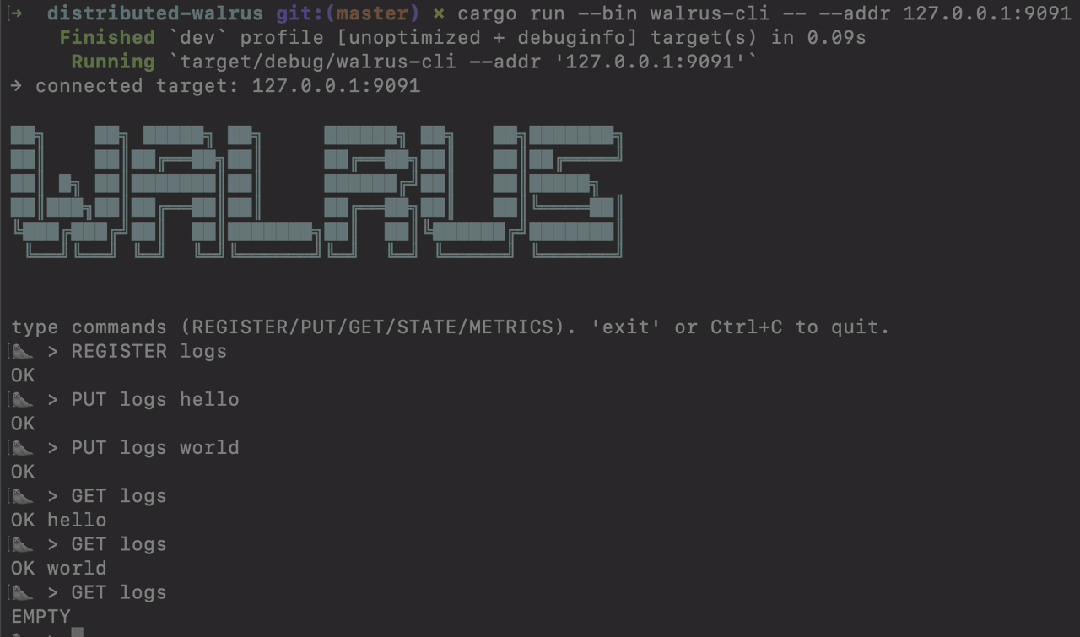
传统方案的挑战
- 架构复杂性与运维成本:老版本Kafka重度依赖ZooKeeper进行元数据管理,部署和运维复杂。尽管新版本已用KRaft协议取代ZK,但整体架构依然庞大。
- 资源消耗较高:作为JVM应用,Kafka的内存占用相对较高,且难以完全避免垃圾回收(GC)带来的停顿。在资源受限的边缘设备或成本敏感的环境中,运行完整的Kafka集群可能并非最佳选择。
- 学习曲线陡峭:Topic、Partition、Replica、ISR等一系列概念,以及众多的性能调优参数,对初学者和运维人员都构成了不低的门槛。
因此,社区开始呼唤一种更轻量、更简单、高性能且内置共识机制的新一代流式处理引擎。Pulsar和Redpanda等项目都进行了有益的尝试,但它们要么架构复杂,要么因过度兼容而限制了创新空间。
Walrus的出现,仿佛为这个领域带来了一股“极简主义”的新风。
二、Walrus的核心设计哲学:少即是多
Walrus的设计哲学可以归结为三点,看似简单,却巧妙地避开了许多分布式系统的经典陷阱:
- 元数据走Raft共识,消息数据不走Raft。
- 以Segment(段)作为分片单位,并自动轮转以实现负载均衡。
- 任何节点均可接入,请求自动转发,对客户端透明。
架构全景:四大核心组件
每个Walrus节点都包含以下四个核心模块:
| 组件 |
职责 |
关键特性 |
| Node Controller |
请求路由与租约管理 |
每100ms同步元数据,自动将写请求转发至Leader节点 |
| Raft Engine (Octopii) |
元数据共识 |
仅同步元数据,不处理实际消息数据 |
| Cluster Metadata |
全局状态机 |
存储Topic、Segment与Leader节点的映射关系 |
| Storage Engine |
日志存储 |
基于自有引擎,支持io_uring以提升I/O性能 |
请注意“仅同步元数据”这一关键设计——这是Walrus实现高性能的秘诀。
- 对比Kafka:每条消息写入都需要经过ISR(同步副本)的确认,延迟较高。
- 对比Pulsar:BookKeeper的Quorum Write机制也存在开销。
- 而Walrus:消息数据直接写入本地磁盘,只有元数据变更(如Leader切换)才需要经过Raft共识。这使得其数据写入路径几乎免除了共识开销。
这个设计就好比物流系统:
- Kafka要求“每件包裹都必须由三个仓库同时签收才算送达”。
- Walrus则是“包裹直接存入本地仓库,然后通知其他仓库‘这里有新货’即可”。
效率差距,显而易见。
三、基于Segment的分片与自动负载均衡
Walrus最精妙的设计之一是其基于Segment的分片与自动轮转机制。
什么是Segment?
你可以将一个Topic(主题)想象成一条无限长的日志。Walrus会将其切割成一个个固定大小的Segment,默认每个Segment容纳100万条消息(可配置)。
- 每个Segment都有一个Leader节点,专门负责接收该Segment的写入请求。
- 当一个Segment被写满后,系统会自动触发Rollover(滚动),创建一个新的Segment。
- 新Segment的Leader节点会在集群节点间轮转。
示例:
假设集群有A、B、C三个节点,Topic logs的写入流程如下:
- Segment 0 → Leader = A
- Segment 1 → Leader = B
- Segment 2 → Leader = C
- Segment 3 → Leader = A
- ……
结果就是:写入压力被自动、均匀地分布到了集群中的所有节点上!
这比Kafka需要手动分配Partition、Rebalance可能导致服务中断、以及Leader节点负载不均等问题,显得更加优雅和自动化。
此外,已被“Sealed”(封存)的旧Segment依然可以被读取。任何拥有该Segment副本的节点都能提供读服务,这为系统带来了天然的读扩展能力。
四、基于租约的写隔离:预防脑裂的利器
分布式系统最令人头疼的问题之一是Split-Brain(脑裂)——即两个节点都认为自己是Leader,同时进行写入,导致数据不一致。
Walrus采用租约(Lease)机制来有效解决这个问题。
工作原理:
- Raft元数据中记录:Segment X的当前Leader是Node Y。
- Node Y获得一个100ms有效期的写租约(通过每100ms同步元数据来刷新)。
- 只有持有有效租约的节点,才被允许向该Segment写入数据。
- 如果发生网络分区,旧的Leader节点在其租约过期后将自动失效,无法继续写入。
这相当于为每个Segment配备了一把“限时钥匙”,时间一到自动报废。即便旧的Leader节点因网络问题仍然存活,它也失去了写入权限。
关键点在于:租约的有效性依赖于Raft元数据的一致性,而非传统的心跳机制。这意味着只要集群的Raft元数据达成一致,租约状态就是一致的,从而从根源上杜绝了脑裂的可能性。
五、极简的客户端协议
Walrus的客户端协议简洁得令人惊讶,采用了“长度前缀 + UTF-8文本命令”的格式:
[4字节长度][UTF-8 命令]
仅支持五个核心命令:
REGISTER logs # 创建Topic
PUT logs "hello" # 写入消息
GET logs # 读取下一条消息(共享游标)
STATE logs # 查询元数据(返回JSON)
METRICS # 查询集群指标(返回JSON)
响应也只有三种类型:
OK [payload]
EMPTY
ERR <message>
没有引入Protobuf、gRPC或复杂的二进制编码。你甚至可以直接使用nc(netcat)工具与Walrus服务器对话:
echo -n -e "\x0f\x00\x00\x00PUT logs hello" | nc 127.0.0.1 8080
这种“复古”的设计极大地降低了客户端的开发门槛和集成成本。无论是嵌入式设备、各种脚本语言,还是通过WebAssembly运行的浏览器环境,都能轻松接入。
当然,官方也提供了CLI工具和Rust客户端库,但底层协议的极简性确保了整个生态的开放与灵活。
六、性能与正确性:不仅追求速度,更确保可靠
一个常见的质疑是:“设计如此简单,是否会牺牲一致性?”
Walrus团队显然考虑到了这一点。他们不仅实现了代码,还使用TLA+(一种形式化规约语言)对系统的核心逻辑进行了建模和验证。
已验证的系统属性包括:
- 单写者原则:每个Segment在同一时刻有且仅有一个有效的写入者。
- 不可变性:一旦Segment被Sealed(封存),其内容永远不会再改变。
- 游标安全:消费者的读取游标不会越界或跳过消息。
- 顺序保证:在同一个Segment内,消息的顺序是严格保持的。
更值得称道的是,他们还验证了系统的活性属性:
- 已写满的Segment最终一定会触发Rollover。
- 可被消费的消息最终一定会被消费者读取到。
这意味着Walrus不仅仅“跑得快”,更重要的是“跑得稳”。在分布式系统领域,正确性永远应该优先于性能。通过TLA+等形式化方法对系统设计进行验证,是构建高可靠性软件的重要手段。
七、快速上手:三分钟搭建集群
Walrus的入门体验非常友好。假设你的环境已安装Docker和Make,只需几步:
git clone https://github.com/nubskr/walrus
cd walrus/distributed-walrus
make cluster-bootstrap
执行完毕后,一个包含3个节点的Walrus集群就已经在本地运行起来了(端口分别为9091~9093)。
接下来,启动命令行客户端:
cargo run --bin walrus-cli -- --addr 127.0.0.1:9091
在CLI中尝试以下命令,感受其简洁性:
> REGISTER logs
OK
> PUT logs "第一次写入"
OK
> GET logs
OK "第一次写入"
> STATE logs
{"segments": [{"id":0,"leader":"node-1","sealed":false,"entries":1}]}
> METRICS
{"raft_term":3,"raft_commit":12,"applied":12}
整个过程充满了“回归Unix设计哲学”的简洁美感。
八、Rust语言的威力:安全、并发与零成本抽象
最后,我们来谈谈语言选择。为什么是Rust?
- 内存安全:无垃圾回收器(GC),无空指针解引用,无数据竞争——这些特性对于追求高可靠性的分布式系统至关重要。
- 零成本抽象:
async/await异步编程模型以及对io_uring等现代I/O接口的良好支持,使得实现高性能I/O成为可能。
- 成熟的生态系统:Tokio(异步运行时)、各类Raft实现(如
async-raft)、Serde(序列化/反序列化)等库一应俱全。
特别值得一提的是,Walrus在Linux系统上默认启用了io_uring。这是Linux 5.1及以上版本提供的高性能异步I/O接口,能够绕过内核缓冲区,实现应用与存储设备之间的直接数据交换。相比Kafka使用的Java NIO或Pulsar使用的Netty,io_uring在极高吞吐量的场景下具有显著优势。而Rust社区(例如tokio-uring库)已经提供了成熟、易用的io_uring封装,这充分体现了选择正确的系统级编程语言对于构建基础设施的重要性。
九、适用场景与当前局限性
Walrus非常适合以下场景:
- 中小规模的实时日志收集(可作为Fluentd + Kafka组合的轻量替代)。
- IoT设备数据汇聚(资源占用低,适合边缘环境)。
- 微服务间的事件总线(协议简单,易于集成)。
- 教学与原型开发(架构清晰,代码易于阅读和理解)。
当前版本的局限性:
- 超大规模集群(例如超过100个节点)的稳定性和性能尚未经过充分验证。
- 语义保证:目前主要提供At-Least-Once(至少一次)交付语义,尚不支持Exactly-Once(精确一次)语义。
- 生态系统:如果强依赖于Kafka庞大的周边生态(如Kafka Connect、KSQL等),则迁移成本较高。
需要注意的是,Walrus仍是一个处于快速发展初期的项目,上述局限性很可能在未来的版本中得到改善或解决。
十、结语:大道至简
Walrus的设计令人联想到“大道至简”的理念。在分布式系统领域,我们常常陷入“功能越多越强大”的思维定式。而Walrus则展示了另一种可能:通过大胆地削减非核心的复杂性,反而能够在可靠性、性能和使用体验上获得倍增的收益。
它没有追求对Kafka协议的100%兼容,没有堆砌琳琅满目的“企业级”功能,而是聚焦于消息流处理最核心的本质:可靠写入、高效读取与自动化的容错处理。
这,或许正是下一代流式处理引擎应有的姿态。
项目信息:
 发表于 2025-12-14 15:35:34
|
查看: 259|
回复: 0
发表于 2025-12-14 15:35:34
|
查看: 259|
回复: 0
