一、Kafka消费慢的常见表现
当你的Kafka消费者应用出现以下情况时,就需要警惕了:
- 消费滞后(Lag)持续增大,迟迟无法追上。
- 消息从产生到被消费的延迟越来越高。
- 消费者端的CPU使用率却很低,看起来“很闲”。
很多人遇到这类问题,第一反应可能是:“Kafka是不是不行了?” 但其实,更多时候问题出在消费者的配置上,而不是Kafka集群本身。错误的配置会极大地限制消费者的吞吐能力,导致“有力使不出”。
二、理解Kafka Consumer的工作流程
要解决问题,得先理解原理。Kafka Consumer采用的是 “拉模型(Pull Model)” ,整个过程如下图所示:
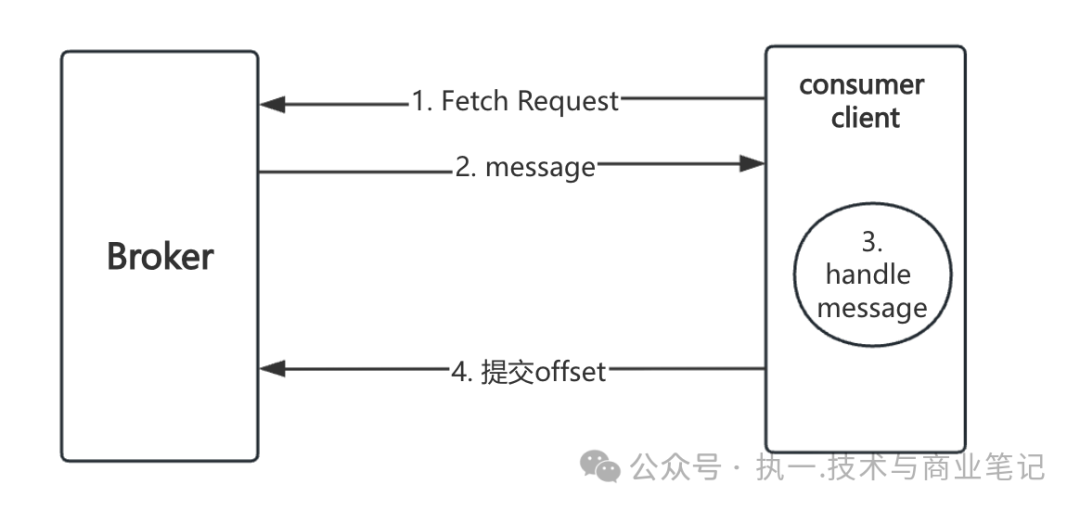
核心流程可以概括为四个步骤:
- Fetch Request:消费者客户端向Broker发起拉取请求。
- Broker返回消息:Broker将符合条件的消息返回给消费者。
- 客户端处理消息:消费者在本地处理这批消息。
- 提交Offset:处理完成后,消费者向Broker提交消费位移。
这个“拉”的模式意味着,消费者的吞吐能力很大程度上取决于它每次能从Broker拉取多少数据,以及拉取的频率。而这正是接下来要讲的几个关键参数所控制的。
三、导致消费慢的3个关键参数(及配置误区)
以下三个参数如果配置不当,会直接拖慢你的消费速度,它们是性能调优的重中之重。
1. fetch.min.bytes
2. max.poll.records
3. max.partition.fetch.bytes
四、一套推荐的配置策略
将上述参数组合起来,我们可以得到一套旨在减少网络请求、提高单次拉取效率的优化配置:
# 等待Broker累积至少1MB数据再返回
fetch.min.bytes=1048576
# 最多等待500ms,即使数据未达1MB也返回(避免长时间阻塞)
fetch.max.wait.ms=500
# 每个分区每次最多可拉取8MB数据
max.partition.fetch.bytes=8388608
# 单次poll最多返回2000条记录
max.poll.records=2000
这套配置能带来什么效果?
- 显著减少网络往返(RTT)次数:通过
fetch.min.bytes和max.partition.fetch.bytes配合,让每一次网络请求都“满载而归”,而不是“跑空车”。
- 提高单次处理吞吐量:
max.poll.records和max.partition.fetch.bytes保证了每次poll()能拿到足够多的数据供业务逻辑处理,压满CPU。
- 平衡延迟与吞吐:
fetch.max.wait.ms为拉取操作设置了一个最长等待时间,在数据量小的时候也不会无限制地等下去,兼顾了低延迟场景。
五、总结与思考
一句话总结:Kafka消费者变慢,十有八九是配置问题,而非Kafka集群的性能瓶颈。 优化之路始于对消费者工作模型的理解,核心在于调整拉取行为的几个“控制阀”。
本文重点剖析了 fetch.min.bytes、max.poll.records 和 max.partition.fetch.bytes 这三个关键参数。当然,完整的Kafka消费者调优还涉及其他参数(如会话超时、心跳间隔、反序列化器等)和外部因素(如网络、资源限制)。但把握好这三个核心,你已经能解决绝大部分因配置不当导致的消费性能低下问题了。
如果你对消息队列或分布式系统的其他性能调优话题感兴趣,欢迎在云栈社区与更多开发者交流探讨。 |  发表于 2026-3-17 05:00:25
|
查看: 95|
回复: 0
发表于 2026-3-17 05:00:25
|
查看: 95|
回复: 0
