近期,MinIO官方宣布其社区版进入维护模式,未来将不再接受新功能,并将UI等高级管理功能转向企业版。这一变化促使许多技术团队重新评估其云原生存储方案的长期可用性与成本,并积极寻找替代方案。在主流的选型对比中,Ceph、RustFS以及 CubeFS 是常见的评估对象。
1 主流云原生存储方案对比
| 项目 |
Ceph |
RustFS |
CubeFS |
| 特点 |
功能最全、成熟度高 |
轻量新兴、性能不错 |
云原生友好、协议全面 |
| 部署难度 |
高(复杂) |
低 |
中 |
| 运维成本 |
高 |
中 |
中低 |
| 云原生适配 |
一般 |
弱 |
强(CSI + CRD) |
| 协议支持 |
RBD / CephFS / S3 |
基础文件/对象 |
S3 + POSIX + HDFS |
| 扩容体验 |
较重,需要 rebalance |
简单 |
无需 rebalance,平滑扩展 |
| 适合场景 |
大型企业/重存储场景 |
小规模或轻量项目 |
大部分云原生场景 |
一句话总结:
- Ceph:功能强大但部署运维复杂,适合重负载场景。
- RustFS:轻巧易用但生态和协议支持较弱。
- CubeFS:在云原生适配、协议支持与运维复杂度间取得了良好平衡,是多数团队的优选。
下面将重点介绍 CubeFS 的架构,并演示如何在 Kubernetes 集群中部署它。
2 CubeFS 架构解析
CubeFS 采用“元数据与数据分离”的经典分布式架构。其核心组件与协作流程如下:
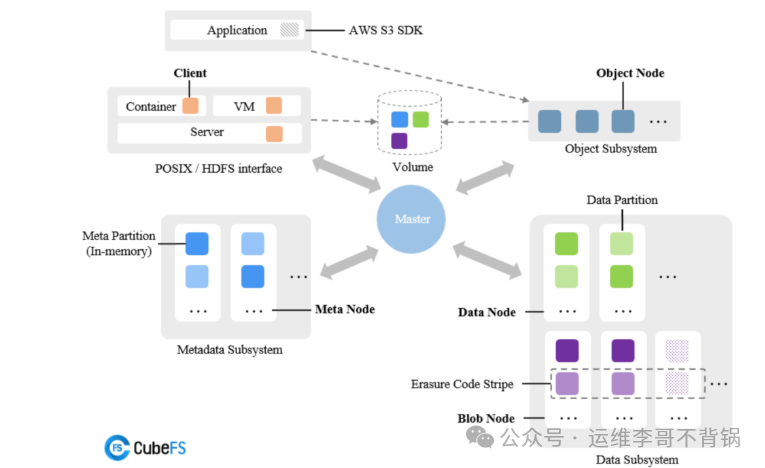
- Master:作为集群大脑,负责管理卷、元数据分区与数据分区的全局调度。客户端仅在初次访问时需要与 Master 协商,后续直接与其他节点通信,这极大提升了系统的扩展性。
- MetaNode:负责管理目录结构、文件 inode 等元数据。元数据以分区的形式常驻内存,以实现高速访问。
- DataNode:存储文件的实际数据内容。数据被分片并分布在不同节点上,可通过多副本或纠删码机制保障可靠性。
- BlobNode:底层负责真实数据块的存储管理。
- ObjectNode:为系统提供 S3 兼容的对象存储接口。这意味着,无论是通过 POSIX 文件系统、HDFS 还是 S3 协议访问,最终都操作同一份数据池。
总结来说,CubeFS 通过 Master 集中管控、MetaNode 与 DataNode 各司其职、ObjectNode 提供标准对象接口,实现了高性能、高并发且对云原生环境友好的分布式存储能力。
3 部署前准备
我们将使用 Helm 将 CubeFS 部署到 Kubernetes 集群中,组件采用主机网络模式,磁盘通过 hostPath 映射。
3.1 部署架构规划
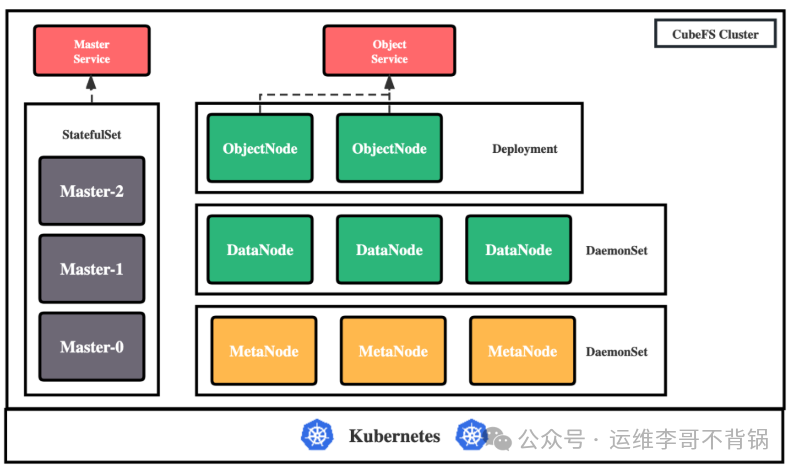
部署主要涉及以下四个组件:
- Master: 资源管理节点,以 StatefulSet 形式部署。
- DataNode: 数据存储节点,需挂载物理磁盘,以 DaemonSet 形式部署。
- MetaNode: 元数据节点,以 DaemonSet 形式部署。
- ObjectNode: 提供 S3 协议转换,以 Deployment 形式部署。
3.2 节点规划与标签
你需要一个至少包含 3 个节点(建议 4 个以上以容灾)的 Kubernetes 集群。通过为节点打标签来指定其角色:
# 标记 Master 节点 (至少3个,建议奇数个)
kubectl label node <nodename> component.cubefs.io/master=enabled
# 标记 MetaNode 节点 (至少3个)
kubectl label node <nodename> component.cubefs.io/metanode=enabled
# 标记 DataNode 节点 (至少3个)
kubectl label node <nodename> component.cubefs.io/datanode=enabled
# 标记 ObjectNode 节点 (可选)
kubectl label node <nodename> component.cubefs.io/objectnode=enabled
注意事项:如果您的 Master 节点存在污点(Taint),可能导致 Pod 无法调度。需要移除污点或在 Helm 配置中增加容忍(Toleration)。
# 检查污点
kubectl describe node k8s-master | grep -i taints
# 移除 control-plane 污点(如存在)
kubectl taint node k8s-master node-role.kubernetes.io/control-plane-
3.3 挂载数据盘
在标记为 DataNode 的每个节点上,需要挂载数据盘。本例为三个节点各添加一块 50G 磁盘 (/dev/sdb)。
- 查看磁盘:
fdisk -l 或 lsblk
- 格式化磁盘:
mkfs.xfs /dev/sdb
- 创建并挂载目录(目录名必须为
data0, data1... 格式):
mkdir /data0
mount /dev/sdb /data0
- 配置开机自动挂载:
echo '/dev/sdb /data0 xfs defaults 0 0' >> /etc/fstab
mount -a # 立即生效
3.4 安装 Helm
在 Master 节点上安装 Helm(若已安装可跳过):
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
helm version
4 部署 CubeFS
4.1 获取 Chart 包
git clone https://github.com/cubefs/cubefs-helm.git
cd cubefs-helm/cubefs
4.2 调整 Helm 配置
编辑 values.yaml 文件,根据需求调整关键配置:
# 关闭非必需组件以简化部署
component:
client: false # 不部署独立客户端
csi: false # 不部署 CSI 驱动(可按需开启)
monitor: false # 不部署监控
ingress: false # 不部署 Ingress
# 设置 Master 副本数 (必须奇数)
master:
replicas: 3
resources: # 生产环境应提高资源配置
requests:
memory: "512Mi"
cpu: "200m"
limits:
memory: "2Gi"
cpu: "2000m"
# 设置 MetaNode 可用内存 (建议主机内存的80%)
metanode:
total_mem: "6871947000" # 约 6.4GB,按需计算 (6.4*1024^3)
resources:
requests:
memory: "512Mi"
cpu: "200m"
limits:
memory: "2Gi"
cpu: "2000m"
# 配置 DataNode 数据盘及预留空间
datanode:
disks:
- /data0:2147483648 # 挂载点:预留空间(字节),此处预留2GB
resources:
requests:
memory: "512Mi"
cpu: "200m"
limits:
memory: "2Gi"
cpu: "2000m"
4.3 执行部署
使用 Helm 在 cubefs 命名空间中部署:
helm upgrade --install cubefs . -n cubefs --create-namespace
部署完成后,检查所有 Pod 是否运行正常:
kubectl get pods -n cubefs
当所有 Pod 状态均为 Running 时,表示 CubeFS 集群已成功部署。后续可基于此集群创建存储卷,或通过其 S3兼容的接口 进行对象存储操作。
 发表于 2025-12-14 21:31:46
|
查看: 336|
回复: 0
发表于 2025-12-14 21:31:46
|
查看: 336|
回复: 0
