在现代软件供应链的复杂生态中,安全研究人员面临着一个典型的不对称挑战:代码库规模快速膨胀,而可用于审计的人力长期稀缺。传统的静态应用程序安全测试(SAST)工具,如 GitHub CodeQL,虽然能够构建抽象语法树、控制流图与数据流信息,对潜在缺陷进行大规模扫描,但其设计通常更偏向高召回率而非高精确率,从而带来规模化场景下的核心痛点:误报率过高。
在2025年12月的Black Hat Europe上,CyberArk Labs的研究人员提出了一种名为 Vulnhalla 的混合架构:以CodeQL提供广度覆盖,以大语言模型提供深度验证,并通过两项关键机制连接两者:
- 按需上下文提取:利用CodeQL已生成的数据库作为索引,精确提取与告警相关的函数、变量上下文。
- 引导式提问:用结构化问题约束LLM的注意力与推理路径,减少其直接认定扫描结果为漏洞的偏差。
本文将从工程落地视角,解析该方案为何有效,并提供一个可复现的端到端流程。

静态分析的固有缺陷与“大海捞针”难题
CodeQL的工作原理与误报根源
CodeQL将源代码转换为一个关系型数据库,其中包含了语法结构、控制流与数据流等“事实”。分析者使用QL查询语言来表达漏洞模式,从而检索出可疑的代码路径。
然而,基于模式匹配与近似数据流的分析会不可避免地产生误报:
- 缺乏语义理解:工具难以理解业务逻辑、隐式约束与复杂的状态不变量。
- 上下文缺失与路径爆炸:跨函数、跨文件的深度分析成本高昂,工程配置中常会对分析进行截断,从而产生噪声。
- 高召回策略的副作用:为避免漏报,规则往往趋向保守,将大量“形似”漏洞的代码纳入候选集。
“大海捞针”的量化现实
对主流开源项目运行标准的CodeQL扫描,原始告警数量往往非常庞大。例如,在Linux Kernel、FFmpeg等项目中,原始告警合计可达数万条。如果按每条告警花费3分钟进行人工初筛,所需的工作量将长达数百个工作日。这清晰地揭示:原始SAST输出在规模化漏洞挖掘中无法直接消费,必须先解决误报治理问题。
大语言模型的角色定位与核心挑战
将LLM引入漏洞挖掘流程,并非简单地将代码扔给模型。其挑战可拆解为两个基本问题:
- Where(定位):LLM不知道应该看哪里。超大代码库无法一次性输入,且超长上下文会导致关键信号被噪声淹没。
- What(定性):LLM在判断漏洞时容易产生幻觉或偏置。如果只给出孤立的代码行,模型可能忽略真实的约束条件。
因此,CodeQL与LLM的合理分工是:
- CodeQL负责广度(Recall):在全仓库范围内找到所有可疑的“热点”。
- LLM负责深度(Precision):对每个热点进行近似人类审计的逻辑验证,大规模剔除误报。
关键在于:如何以低成本、低噪声的方式,将最小且充分的上下文交给LLM,并引导其进行正确的推理。 这引出了两项核心技术。
核心技术一:基于CodeQL数据库的按需上下文提取
为何上下文提取是工程难点
向LLM提供上下文的尺度很难把握:
- 过少:只给告警行,LLM无法判断边界条件,倾向于输出“未知”或产生幻觉。
- 过多:提供整个文件或冗长调用链,会急剧增加Token成本并引入噪声,反而降低判断准确性。
对于C/C++这类语言,使用正则表达式等方式从文本中抽取函数体并不可靠,宏、嵌套括号等都可能导致提取失败。
关键洞察:将CodeQL数据库作为精确索引
最巧妙的解法在于:CodeQL为了进行分析,已经完成了对代码的解析与结构化建模。 与其再进行一次脆弱的外部解析,不如直接从CodeQL数据库导出位置索引,并据此对源文件进行精确切片。

具体做法是编写一个工具型QL查询,导出所有函数(及全局变量、类型定义)的名称、文件路径以及起止行号,生成一个context.csv索引文件。
动态上下文构建流程
当CodeQL报告某行代码存在问题时:
- 定位:在
context.csv索引中,查找包含该行号且文件匹配的函数记录。
- 切片:直接读取源文件对应行号范围(通常是整个函数体)作为主上下文。
- 按需扩展:如果LLM反馈需要更多信息(如调用者约束、全局变量定义),则根据索引追加相关实体的代码片段。
这种方法稳定、高效且成本可控。
核心技术二:引导式提问审计
消除LLM的确认偏误
一个常见的偏差是:当提示词中写明“CodeQL警报:此处可能溢出”,LLM会倾向于确认问题存在。例如,对于被标记的memcpy(dest, src, len),漏洞是否成立的关键在于 len是否可能超过dest的容量,而非len是否来自src。需要通过结构化问题,将LLM的注意力拉回到对约束与数值的审计上。
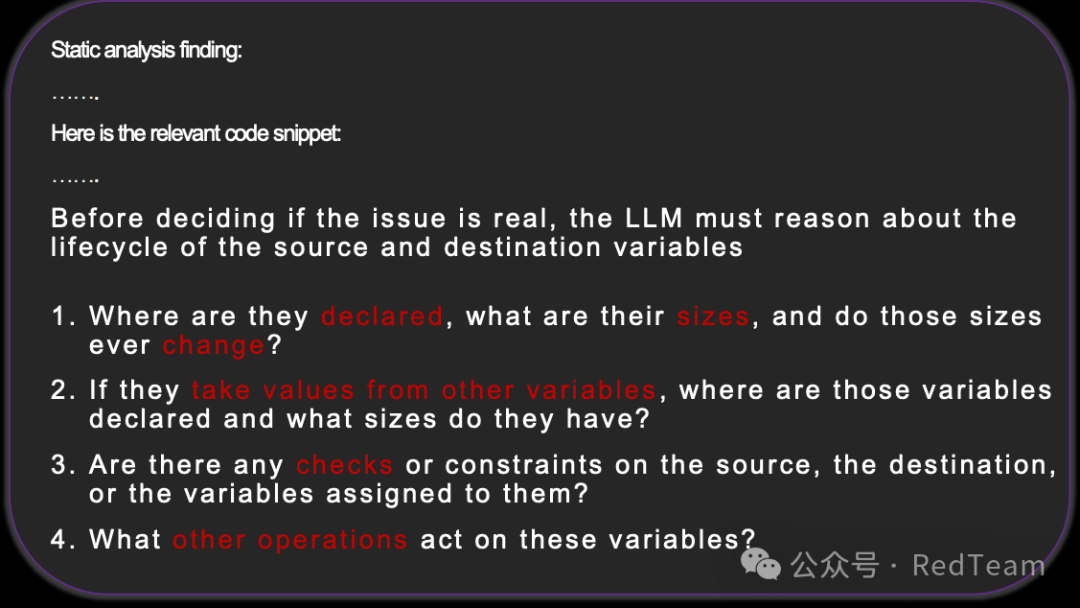
四步引导式提问模板
在要求LLM给出最终结论前,强制其按顺序回答以下四类基础问题,模拟人类审计的思维流:
- 声明与大小:相关变量在哪里声明?大小是多少?大小是否会变化?
- 来源追踪:如果值来自其他变量,那些变量在哪里声明、大小多少?
- 约束检查:是否存在任何边界检查、净化操作或条件分支约束?
- 其他操作:还有哪些操作会影响这些变量(写入、截断、重新分配等)?
结构化输出协议
为便于自动化处理,应约束LLM的输出格式,例如:
Verdict: TRUE_POSITIVE / FALSE_POSITIVE / NEED_MORE_CONTEXTConfidence: 0–1Why: 关键推理要点Need: 若需要更多上下文,明确列出需补充的代码位置
Vulnhalla工具链与端到端复现指南
本节提供一个可工程化的复现流程:数据库构建 → 上下文索引 → 告警生成 → LLM过滤 → 人工复核。
环境准备
- Python 3.10+:用于编写编排脚本。
- CodeQL CLI:用于创建和分析数据库。
- LLM API:如OpenAI或Azure OpenAI,选择代码推理能力较强的模型。
步骤详解
-
生成CodeQL数据库
codeql database create <db-path> --language=cpp --command="make"
-
导出上下文索引
codeql database analyze <db-path> extract_context.ql --format=csv --output=context.csv
-
运行安全扫描生成告警
codeql database analyze <db-path> <security-query.ql> --format=sarif-latest --output=issues.sarif
-
Python编排脚本核心逻辑(伪代码)
# 加载上下文索引
index = load_index(‘context.csv’)
# 解析SARIF告警文件
alerts = parse_sarif(‘issues.sarif’)
for alert in alerts:
# 根据告警行号找到包围它的函数
func = find_enclosing_function(index, alert.file, alert.line)
# 切片获取函数代码
code_snippet = slice_file(func.file_path, func.start_line, func.end_line)
# 构建包含引导式提问的Prompt
prompt = build_guided_prompt(alert, code_snippet)
# 调用LLM API
llm_response = call_llm_api(prompt, temperature=0.2)
# 解析结果
verdict = parse_verdict(llm_response)
# 处理 NEED_MORE_CONTEXT 情况,进行多轮交互
...
关键是将NEED_MORE_CONTEXT视为正常流程,根据LLM反馈的Need字段提取额外上下文,重新提问。
-
人工复核
人工精力只需集中在LLM筛选出的TRUE_POSITIVE以及少量高价值候选告警上,效率得到极大提升。
案例研究与效果分析
定量效果:误报率大幅降低
研究表明,该方法能在多种漏洞类型上实现一致的误报压缩效果。例如,对于“使用源大小进行复制”这类查询,LLM过滤后能将告警数量减少约91%,将海量告警收敛至可人工审计的规模。

真实漏洞发现
该方案已成功在Linux Kernel等大型项目中挖掘出多个高危CVE。其捕获逻辑具备可解释性:
- 栈溢出/格式化读取:LLM能验证
scanf使用%s时,目标缓冲区大小是否固定、输入是否充分受控。
- 拷贝类溢出:LLM能追踪
memcpy的len参数上界是否受到真实约束,是否存在遗漏的检查分支。
- 返回值检查错误:LLM能结合API约定与上下文,验证返回值比较的逻辑是否正确。
局限性、成本与工程化建议
成本可控性
该方案的巨大成本优势源于按需上下文:
- 不喂送整个仓库,只发送告警相关的代码片段。
- 仅在LLM明确要求时才追加上下文。
- 稳定的推理过程减少了重复调用。
主要局限性
- 语言/生态依赖:从C/C++迁移到其他语言(如Java、Python)需要重写上下文提取策略。
- 深层次依赖:涉及跨模块全局状态或复杂协议语义的漏洞,可能需要多轮上下文补充才能准确判断。
- LLM自身局限:对于未定义行为、竞态条件等复杂场景,LLM仍可能出错,必须保留人工最终复核。
关键工程化建议
- 闭环处理上下文请求:实现多轮交互机制,自动响应LLM的
NEED_MORE_CONTEXT请求。
- 输出机器可解析:强制使用JSON等结构化输出格式,便于后续自动化处理。
- 告警聚类去重:合并同一函数内的多条相关告警,一次性提问以降低成本。
结论:从“找漏洞”到“筛误报”的范式升级
Vulnhalla方案的核心贡献不在于用AI直接寻找漏洞,而在于将LLM部署在更具杠杆效应的环节:验证与去噪。
其方法论可概括为:让确定性的工具(CodeQL)负责全面覆盖,让概率性的智能(LLM)负责解释与裁决,从而实现对稀缺人力注意力的高效调度。
对于安全团队而言,这意味着:
- 在同等人力下,可审计的代码规模显著扩大。
- 工作重心从人工翻阅海量噪声,转变为复审少量高价值候选。
- 小型团队也能以可控成本,具备接近工业级的漏洞挖掘能力。
附录:最小可复现清单
- 生成数据库:
codeql database create ... --command="make"
- 导出索引:运行
extract_context.ql查询,生成context.csv。
- 生成告警:运行安全查询,输出
issues.sarif文件。
- 编排过滤:编写脚本解析SARIF,匹配上下文,构造Prompt,调用LLM进行判定。
- 人工复核:仅复核LLM标记的
TRUE_POSITIVE及关键候选。
参考链接:
- Black Hat Europe 2025议题:《Flaw and Order: Finding The Needle In The Haystack Of CodeQL Using LLMs》
 发表于 2025-12-14 23:52:51
|
查看: 296|
回复: 0
发表于 2025-12-14 23:52:51
|
查看: 296|
回复: 0
