大语言模型从本质上讲是无状态的。发送一条消息,得到一个回复,每次新的对话都像面对一块白板。
这是因为模型本身就是一个巨型函数:输入进去,Token 出来。其模型权重中没有任何一种持久化存储,能够在多个会话之间保留对话历史。
对于简单的聊天机器人来说,这可能无关紧要。让它写一封求职信,写完任务就结束了,不需要连续性。
但智能体(Agent)所面对的情况截然不同。它们需要处理长期运行的任务,在时间的推移中学习用户偏好,并跨多个会话与其他 Agent 进行协作。无状态性,在这里构成了一个根本性的障碍。没有人会接受一个每周一早上都需要重新自我介绍的“个人助理”。
常见误区:仅仅依赖上下文窗口
大多数人第一次思考 Agent 的记忆问题时,往往会本能地给出一个最简单的答案:往上下文窗口里塞进更多东西。上下文窗口,就是模型当前能“看到”的全部信息。看起来,想让 Agent 记住什么,直接粘贴进去,问题似乎就解决了。
但上下文窗口就是终极答案吗?显然不是。
首先,上下文窗口是有限的。目前最长的上下文大约在 100 万到 200 万 Token 之间。这个数字听起来很大,但一个长期运行的自主 Agent 所能积累的状态量,完全可以远远超过这个上限。
更关键的是,在触及容量上限之前,还有一个更深层的问题:模型在处理那些深埋于冗长上下文中的信息时,表现会明显下降,其注意力分布并不均匀。而且,上下文是临时性的,会话一结束就消失了。为了保持连续性,你不得不在每个新会话开始时,重新注入完整的历史记录,这既代价高昂又容易出错。
其实,我们可以从计算机的存储体系架构中获得一个更贴切的类比。计算机不会把所有数据都塞进 RAM(内存)里,而是采用一种层次化的存储结构:快速、小容量的即时内存(RAM)用于处理当前工作;较慢、大容量的持久化存储(硬盘)则用于存放其余数据。系统会智能地决定加载什么、保留什么、释放什么。
Agent 的记忆系统,遵循着完全相同的逻辑。

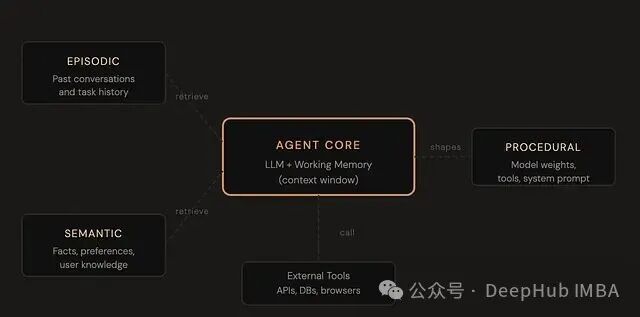
Agent 记忆的四层体系
Agent 的记忆并非一个单一概念,而是一个由四层组成的体系,每一层都服务于不同的目的。
第一层:工作记忆
这对应着 Agent 当前正在处理的内容,也就是它的上下文窗口:包括用户的消息、对话历史,以及已经注入的文档或工具调用结果。它的访问速度极快,但完全是临时性的,会话结束即消失。
第二层:情景记忆
这记录了“发生过的事情”:包括过去的对话、已完成的任务、做出的决策及其背后的原因。它存储在外部的存储系统中,并按需检索。你可以把它理解为 Agent 的日记,这赋予了它一种个人历史感,例如,让它能想起“两周前我们讨论过同样的话题”。
第三层:语义记忆
这是关于事实性的知识:例如用户的名字、偏好、角色、所在公司的技术栈等。这类知识不绑定于任何特定对话,是 Agent 学到并持久存储的独立事实。它最接近我们常说的“用户画像”或“知识库”的概念。
第四层:程序记忆
这一层关乎“怎么做”:包括可用的工具、需要遵循的工作流、塑造 Agent 行为的系统提示词。甚至,模型权重本身也可以视为程序记忆的一种形式——那数万亿的参数编码了推理、写作和响应的基本方式。这一层变化最少,但最具基础性。
这四种记忆类型,也清晰地映射到了技术栈的不同组件上。工作记忆对应上下文窗口;情景记忆和语义记忆对应外部数据库(如向量存储、关系型数据库、键值存储);程序记忆则对应模型权重和系统提示词。
记忆系统的实际运作机制
在划分了记忆的类型之后,我们来看看一个 Agent 的记忆系统在机制层面是如何实际运作的。这个过程主要包含三个环节:写入、检索和遗忘。
写入
在会话结束时,或者在进行中的关键节点,Agent(或其背后一个独立的记忆管理进程)需要判断哪些信息值得被保留下来。这个判断并不简单,因为你不可能把一切都存下来,否则检索会变得异常缓慢且杂乱无章。
真正需要被保留的,是那些在未来某个时刻可能被证明有用的内容:例如做出的关键决定、用户明确表达的偏好、以及那些不容易被重新推导出来的上下文。
因此,通常需要一次额外的大语言模型(LLM)调用,专门来进行摘要和关键信息提取。将原始对话作为输入,输出结构化的记忆条目——事实、观察、事件等。随后,这些条目会被写入到向量数据库或键值存储中,并被打上时间戳、主题等元数据标签。
检索
当一个新的会话开始,或者 Agent 接到一个新任务时,它会向自己的记忆存储发起查询,以获取相关的上下文。向量搜索是目前非常常见的做法:将当前的查询或对话情境编码为一个向量(Embedding),然后在存储中检索语义相似度最高的已存储记忆。
检索到的内容会与新对话一起被注入到上下文窗口之中。这样一来,Agent 就获得了对过去经历的“访问”能力,而无需逐一重读每一个历史会话。类比一下,就像你在开会前快速翻阅一遍自己的笔记,而不是试图凭空回忆起所有细节。
遗忘
“遗忘”这个环节受到的关注往往最少,但其重要性却丝毫不低。任何一个健壮的记忆系统,都必须包含某种衰减机制。旧的、低相关性的记忆应当逐渐淡出;相互矛盾的记忆(比如用户之前说偏好 Python,后来又说要切换到 Go)也需要被适时清理。否则,整个知识库会随着时间推移变得陈旧且自相矛盾。
部分系统采用基于时间的显式过期策略;另一些则使用“近期性”和“访问频率”作为信号。少数更精细的方案甚至借鉴了“间隔重复”的学习原理:持续被检索到的记忆会保持活跃,而那些长期未被调用的记忆,则会逐渐消退。

当前的进展与关键项目
AI Agent 的记忆系统是一个快速发展的领域,目前已经有一些值得关注的项目和框架。
Mem0
这大概是目前应用最广泛的记忆层方案之一。它介于 Agent 和底层数据库之间,自动处理写入、检索、遗忘等逻辑——将其接入技术栈后,它就能帮你管理情景记忆和语义记忆。其 API 设计得非常简洁:保存记忆、搜索记忆,剩下的复杂工作交给它来处理。
Letta(前身为 MemGPT)
这个项目走了一条更有主见的技术路线。它通过工具调用(Tool Calling)的方式,将记忆的控制权显式地交给了 Agent 自身——由 Agent 来决定何时写入、写入什么、以及删除什么。这种方式的复杂度更高,但透明度也更高:Agent 是自己记忆管理的主动参与者,而不是被动的接收方。
主流框架的支持
像 LangChain 和 LlamaIndex 这些主流的 LLM 应用开发框架,同样提供了内置的记忆模块。此外,越来越多的前沿模型提供商(如一些闭源模型API)也开始将持久化对话能力直接内置于其服务中,让对话历史能够在会话之间原生地延续。
技术的发展方向已经清晰:记忆正在从一个需要各团队自行解决的、高度定制化的工程问题,演变为 Agent 技术栈中拥有标准接口和专用基础设施的“一等公民”。
与 MCP 和 A2A 的关系:构建完整智能体的三层架构
要构建一个功能完整的智能体,我们通常需要关注三个核心层次,而记忆是其中不可或缺的一块。
MCP:处理“当下”
MCP(Model Context Protocol)解决的是 Agent 与外部工具、数据源之间的通信问题。它定义了 Agent “此刻”能访问什么。
A2A:处理“协作”
A2A(Agent to Agent)解决的是多个 Agent 之间如何相互通信与协调的问题。
记忆:处理“过去”
记忆系统则解决 Agent 如何在时间维度上维持自身的连续性与历史。它关乎“从前次的交互中,我们留下了什么”。

这三者结合在一起,就构成了一个能够行动(通过MCP)、能够协作(通过A2A)、并且能够在时间跨度上维持记忆和自我意识的完整系统。这样的智能体,其能力远不止是对单个提示词做出响应那么简单。
总结
底层的大语言模型本身每几个月都在飞速进步,上下文窗口的容量也在持续增大。但我们必须清醒地认识到,记忆作为一个完整的系统——包含精心设计的写入、检索和衰减逻辑——并不会随着模型规模的增长而自动获得。
它是一个需要被刻意设计、专门搭建的工程层。这也正是为什么,在当下这个时间点,深入理解和关注 Agent 记忆架构的设计与实践,显得尤为重要且具有前瞻性。在云栈社区,你可以找到更多关于人工智能和Agent架构的深度讨论与实践分享。

 发表于 2026-3-20 04:25:17
|
查看: 136|
回复: 0
发表于 2026-3-20 04:25:17
|
查看: 136|
回复: 0
