在软件开发的漫长周期中,代码库的腐化与“技术债”的堆积几乎是不可避免的。为了帮助开发者量化这一棘手问题,一款名为 Fuck-U-Code 的开源工具应运而生。它能够自动检测代码的“混乱等级”,并以一份视觉化的报告直观展示分析结果,旨在帮助团队识别并优先处理那些亟待重构的代码区域。
该工具支持 Python、Java、Go 等多种主流编程语言,其核心功能是通过扫描指定项目目录,深入分析代码的结构复杂性、命名规范、注释覆盖率、依赖关系等多个维度。最终,它会生成一份清晰且带有一定幽默感的评估报告,让开发者对项目的“健康度”一目了然。

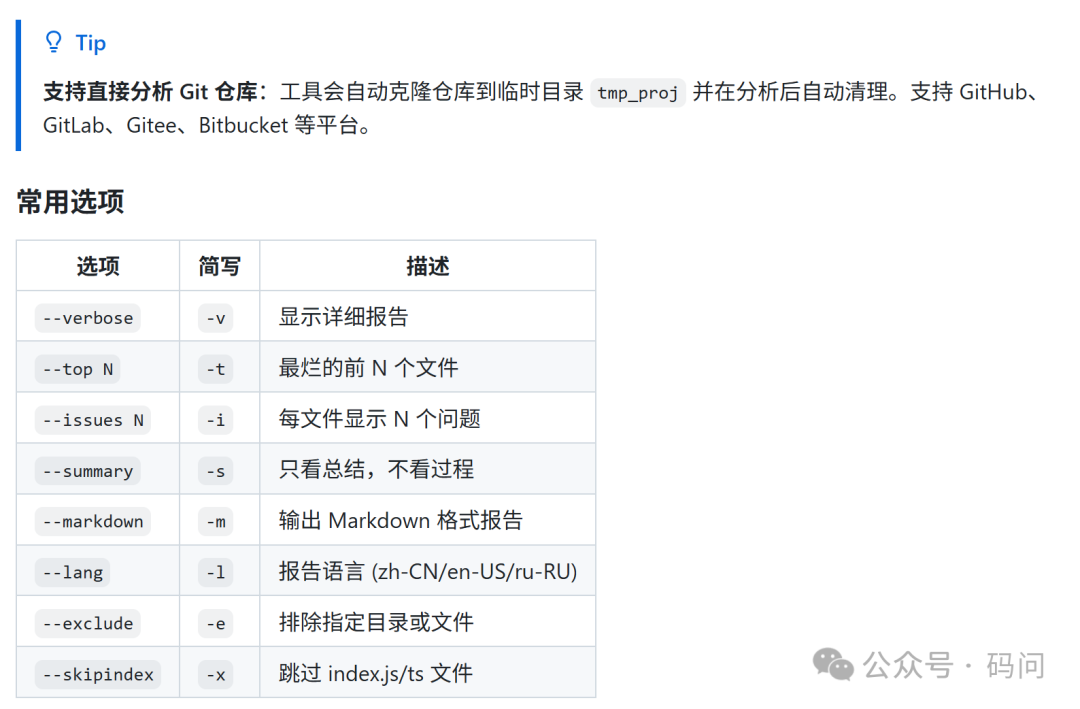
核心特性与使用场景
- 多语言支持:并非局限于单一生态,它能对包含多种后端语言与技术栈的混合项目进行统一分析,这对于管理大型历史遗留系统尤为有用。
- 自动化扫描:通过简单的命令行指令即可启动,无需复杂的配置,能够轻松集成到CI/CD流程中,实现代码质量的持续监控。
- 可读性报告:分析结果并非枯燥的数字,而是转化为等级(如“屎山指数”)和可视化图表,让技术债务变得可见、可讨论、可管理。
- 定位问题代码:报告通常会指向具体的文件、类或方法,帮助开发者快速定位高复杂度的模块,从而有针对性地进行代码重构与优化。
快速开始
工具基于 Python 开发,安装和使用都非常简便:
# 通过pip安装
pip install fuck-u-code
# 进入你的项目目录并运行扫描
cd /path/to/your/project
fuck-u-code .
执行后,工具会在当前目录或指定输出路径生成一份HTML格式的报告,你可以直接在浏览器中打开查看详细的分析结果。
对于追求代码长期可维护性与团队开发效率的团队而言,定期使用此类静态分析工具进行“体检”是一个良好的工程实践。它不仅能暴露现有问题,更能通过量化的数据,推动团队建立更科学的代码评审与架构治理标准。
项目地址:https://github.com/Done-0/fuck-u-code
|  发表于 2025-12-15 01:18:30
|
查看: 244|
回复: 0
发表于 2025-12-15 01:18:30
|
查看: 244|
回复: 0
