迈向通用人工智能需要能够同时“理解”与“生成”文本、图像、视频和音频等多种模态信息的AI系统。
尽管近期GPT-5.2、Gemini 3 Pro等闭源模型表现出色,开源社区也出现了BAGEL、Emu3等进展,但开源统一多模态基础模型整体上仍落后于闭源对手。
本文基于一篇涵盖754篇文献的最新综述《统一多模态理解与生成综述:进展与挑战》,系统梳理该领域的技术脉络。
一、 为什么要追求“统一”?
传统技术路线将“理解”和“生成”任务割裂:
- 理解端:如CLIP、LLaVA、Qwen-VL,专门处理图像到文本的理解。
- 生成端:如Stable Diffusion、Sora、FLUX,专门处理文本到图像/视频的生成。
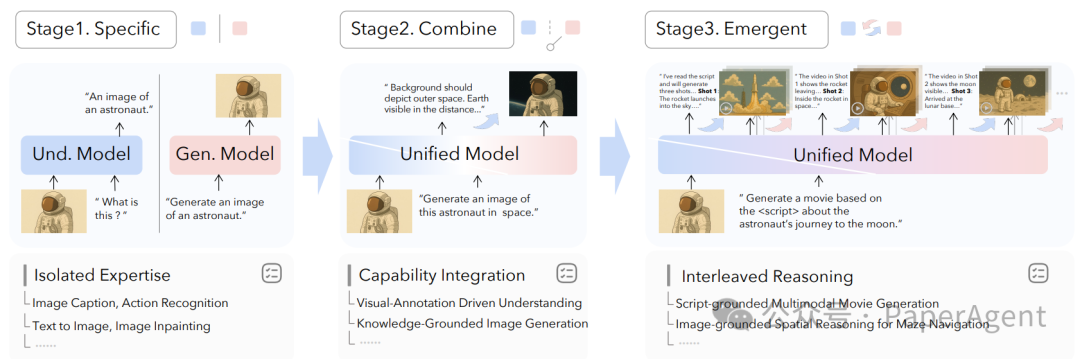
图1:从“专才”到“通才”再到“涌现”的三阶段演化
这种割裂带来了明显的痛点:
- 能力天花板:复杂的跨模态任务(例如“根据剧本生成电影片段”)需要同时具备深度理解和连续生成能力,单一模型难以胜任。
- 效率与性能损失:维护多套模型导致参数冗余、世界知识重复存储,且级联推理会带来高延迟和误差累积。
理解与生成本应是一个互相增强的闭环,正如费曼所言:“我不能创造的东西,我就不理解。”
二、 什么是“统一多模态大模型”(UFM)?

论文给出了形式化定义:一个真正的UFM,其任务集合必须同时包含至少一项理解任务和一项生成任务。模型经过统一预训练后,对于这个集合中的任意任务输入,都能直接输出合法结果。
三、 三大技术建模范式
根据模型内部耦合度的不同,当前技术路线主要分为三类:
| 路线 |
耦合度 |
代表工作 |
核心思路 |
| A. 外挂专家 |
最松 |
Visual-ChatGPT, HuggingGPT |
以大语言模型(LLM)作为“调度中枢”,调用Stable Diffusion、Whisper等独立模型的API。 |
| B. 模块化联合 |
中等 |
NExT-GPT, DreamLLM |
LLM输出中间表示(如Prompt或特征),外部扩散模型负责解码生成。 |
| C. 端到端统一 |
最紧 |
Emu3, Janus-Pro, Chameleon, BAGEL |
所有模态均被转换为Token,由同一个Transformer骨干进行解码,无需外部生成模型。 |
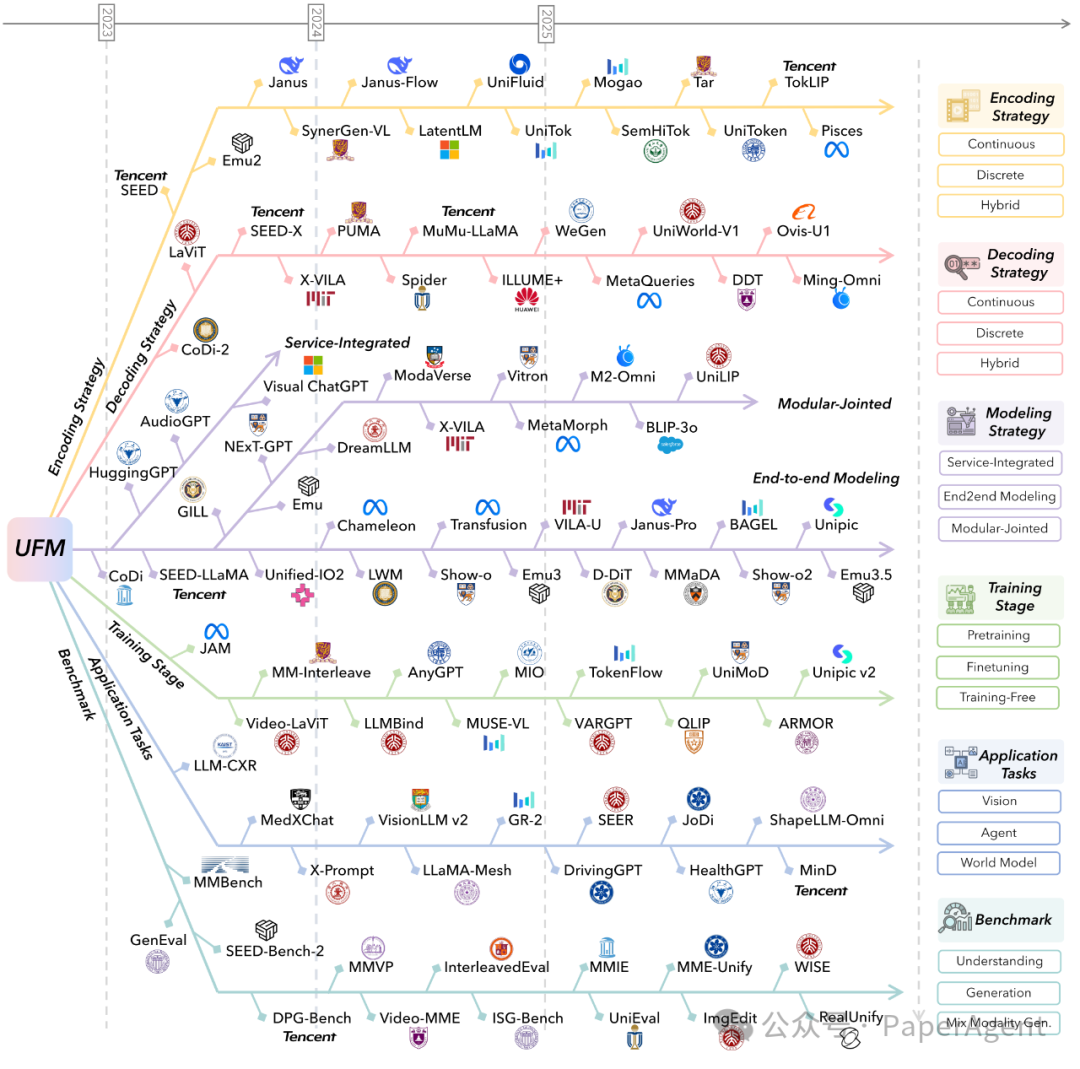
图2:研究论文脉络图,按编码/解码/建模/训练/应用五大维度整理
四、 编码策略:将多媒体转换为Token
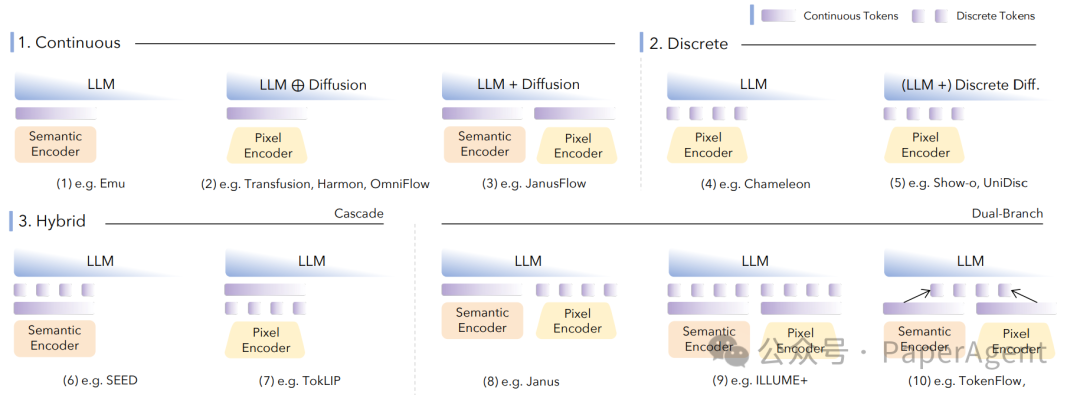
将图像、视频、音频等连续信号转换为模型可处理的离散Token是关键第一步,主要策略包括:
| 表示类型 |
核心思想 |
优点 |
缺点 |
| 连续特征 |
使用CLIP、EVA-CLIP等模型提取特征 |
语义对齐好,利于理解任务 |
无法直接用于生成像素 |
| 离散码本 |
通过VQ-VAE/VQGAN学习码本进行量化 |
兼容LLM词表,生成直接 |
存在量化损失,细节可能丢失 |
| 混合编码 |
双分支分别提取语义特征和像素细节 |
兼顾理解与生成 |
模型架构相对复杂 |
五、 解码策略:从Token还原为多媒体
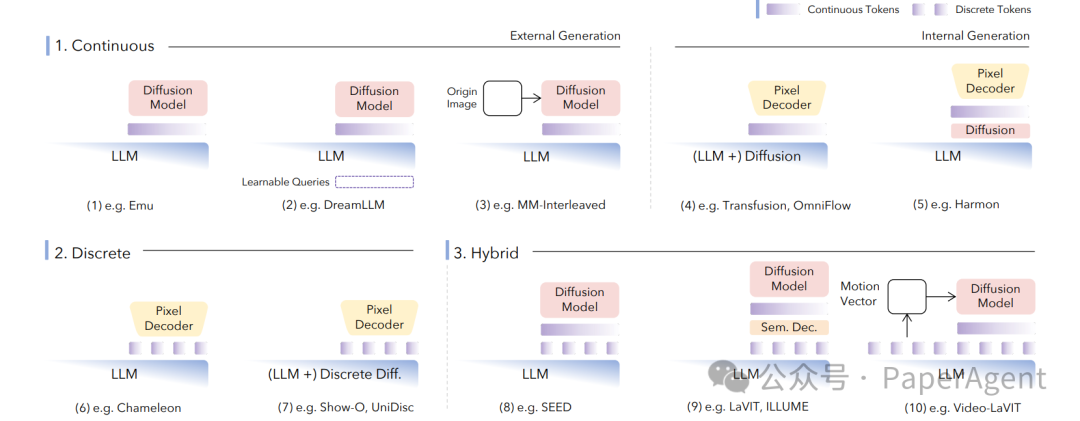 |
策略 |
代表模型 |
关键点 |
| 外部扩散 |
Emu2, MetaMorph |
LLM输出条件,冻结的SDXL/FLUX等扩散模型负责生成,训练轻量Adapter。 |
| 内部扩散 |
Transfusion, Show-o |
将扩散头直接插入LLM内部,进行端到端训练。 |
| 离散自回归 |
Emu3, Chameleon |
纯Next-Token Prediction,无扩散过程,推理速度快,但生成细节可能稍逊。 |
六、 训练流程:构建UFM的三阶段

- 编码-解码预训练:让Tokenizer学会如何将各种模态编码为Token并能初步还原。
- 多模态对齐:通过对比学习、Q-Former等技术,将不同模态的表征拉到同一语义空间。
- 统一骨干训练:使用混合训练目标(如下一Token预测、扩散损失、对齐损失),让骨干模型同时掌握理解和生成能力。
七、 微调与人类偏好对齐
- 通用任务微调:使用LLaVA-Instruct等多任务指令数据,以统一的损失函数进行微调。
- 多任务/领域微调:针对医学影像、3D点云等特定领域数据,可采用分阶段或专家混合策略缓解任务冲突。
- 人类偏好对齐:引入DPO/GRPO等技术,利用三元组数据对模型的理解和生成结果进行联合奖励建模,迭代优化。
八、 数据工程:质量是关键

高质量数据是训练UFM的基石。一篇全面的数据工程方案包括:
- 来源多样化:公开爬取数据(如LAION-5B)、精品标注数据(如COCO)、私有数据以及大模型合成数据(如GPT-4o生成)。
- 严格清洗流程:去重 → 过滤NSFW内容 → 美学评分 → CLIPScore语义过滤。
- 指令数据构造:改写旧数据集、用大模型合成复杂指令、人工精标与众包收集偏好数据。
九、 评测基准:全面评估UFM
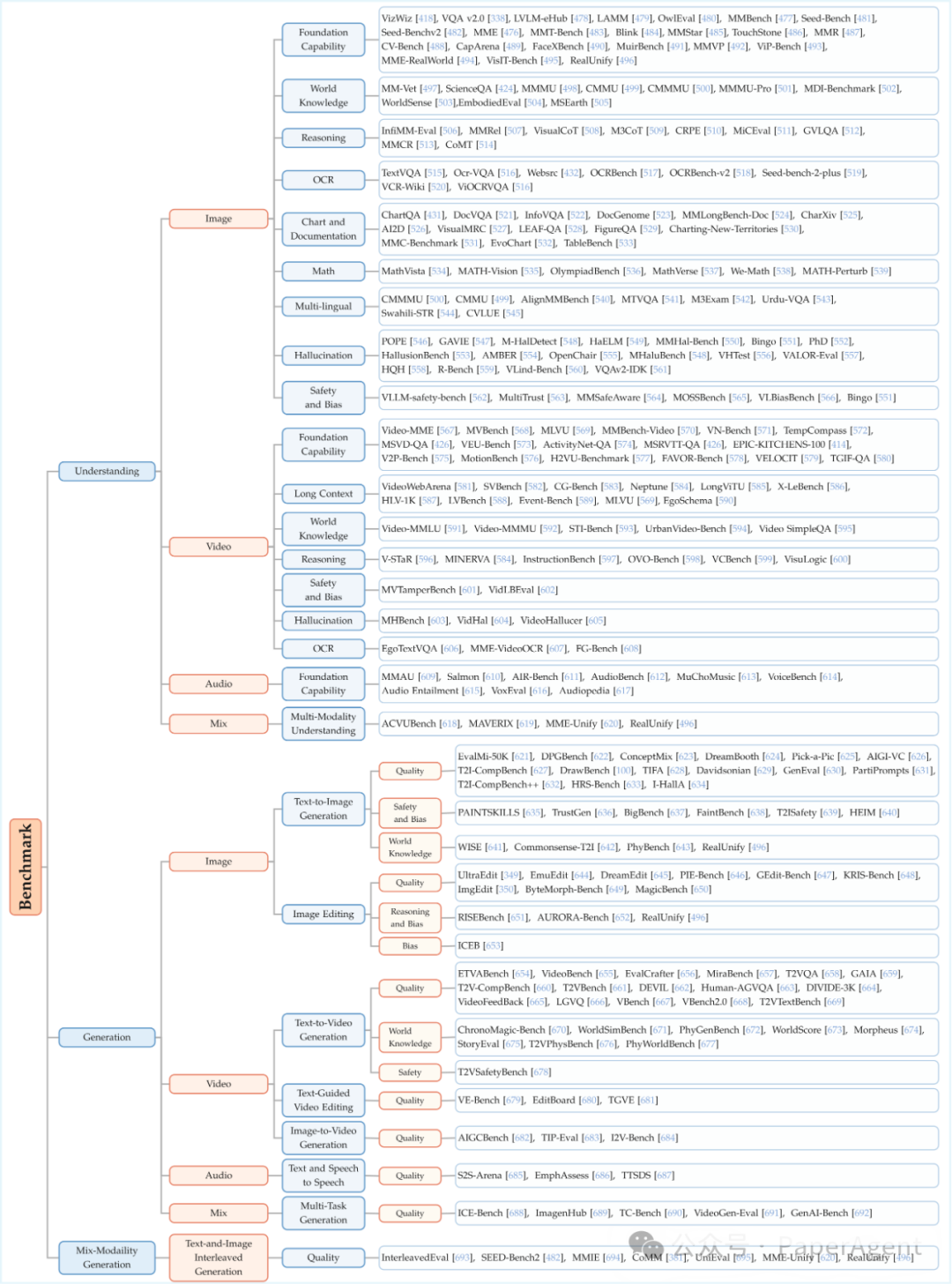 |
评估维度 |
代表基准 |
侧重点 |
| 理解能力 |
MMBench, MMMU, MathVista |
细分技能,多选择题,支持自动评分。 |
| 生成能力 |
GenEval, T2I-CompBench |
组合生成、编辑、物理一致性等复杂要求。 |
| 理解-生成混合 |
MME-Unify, RealUnify |
首次要求理解与生成能力互相促进、协同完成任务。 |
十、 下游应用场景
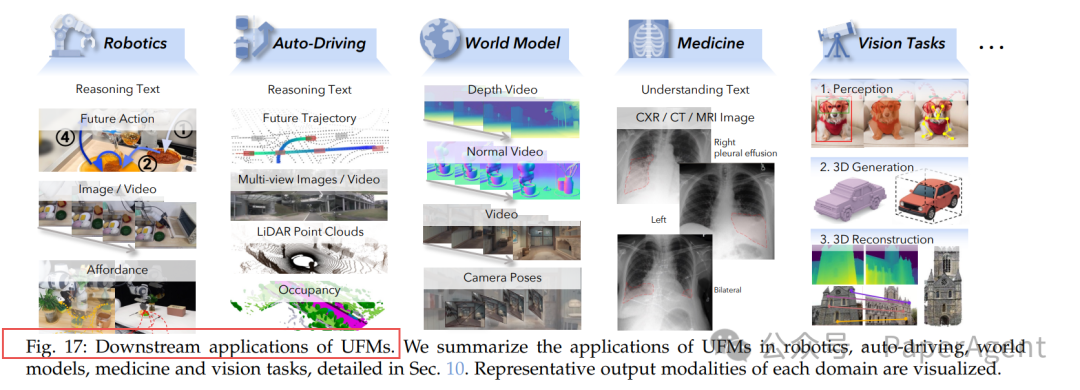
UFM的能力正推动多个领域变革:
- 机器人:GR-2、SEER等模型利用视频生成构建“世界模型”,实现零样本任务泛化。
- 自动驾驶:DrivingGPT等模型联合预测未来帧和轨迹规划,简化冗余的感知模块。
- 医疗影像:实现“胸片生成诊断报告”和“根据报告描述还原影像”的双向任务。
- 通用视觉:VisionLLM v2等模型用一个统一框架处理检测、分割、深度估计等多种视觉任务。
十一、 未来挑战与方向
- 建模架构:自回归与扩散的混合范式仍是主流,需要更精细的MoE路由策略。
- 统一Tokenizer:发展能够处理所有模态的“Omni-Tokenizer”。
- 训练优化:需要更精细的数据调度策略,并设计针对理解与生成任务的联合奖励函数进行强化学习。
- 评测体系:亟需量化评估“理解如何辅助生成,生成又如何反哺理解”的协同效应,而非孤立看待单项指标。
论文与资源链接:
|  发表于 2025-12-15 04:53:30
|
查看: 337|
回复: 0
发表于 2025-12-15 04:53:30
|
查看: 337|
回复: 0
