随着大型语言模型(LLM)和多模态检索方法的快速发展,如何科学、有效地评估它们在文档智能领域的真实表现,成为了一个关键的技术挑战。本文介绍的UniDoc-Bench,正是一个针对文档中心多模态检索增强生成任务而设计的统一基准测试工具,旨在解决当前该领域评估标准碎片化、缺乏综合性测试的问题。
研究背景
多模态检索增强生成已成为将大型语言模型(LLM)应用于真实世界知识库的核心方法之一。然而,现有的评估基准大多侧重于文本或图像的单一模态,缺乏对文档这种天然包含文本、图表、图片等多种元素的复杂对象的综合评估。为了填补这一空白,UniDoc-Bench基于超过70,000个真实的PDF文档页面,构建了一个全面且跨领域的评估框架。它涵盖了金融、法律、医疗等八个专业领域的数据,不仅能实现不同方法间的公平比较,还能深入探究视觉证据如何补充和增强文本信息,从而有力推动文档智能研究的发展。
研究方法
UniDoc-Bench采用了一套精心设计的分类过滤方案,用于从现实世界的PDF文档中提取高质量的多模态数据。通过解析文档中的文本、图表和图像,该工具构建了跨模态的知识图谱,从而支持高效的多模态问答对生成。最终,研究团队生成了1,600个高质量的问答对,覆盖了事实检索、比较分析、内容总结以及逻辑推理四种核心问题类型。整个评估过程使用统一的候选文档池、标准提示词和量化指标,确保了不同检索方法之间结果的可比性。
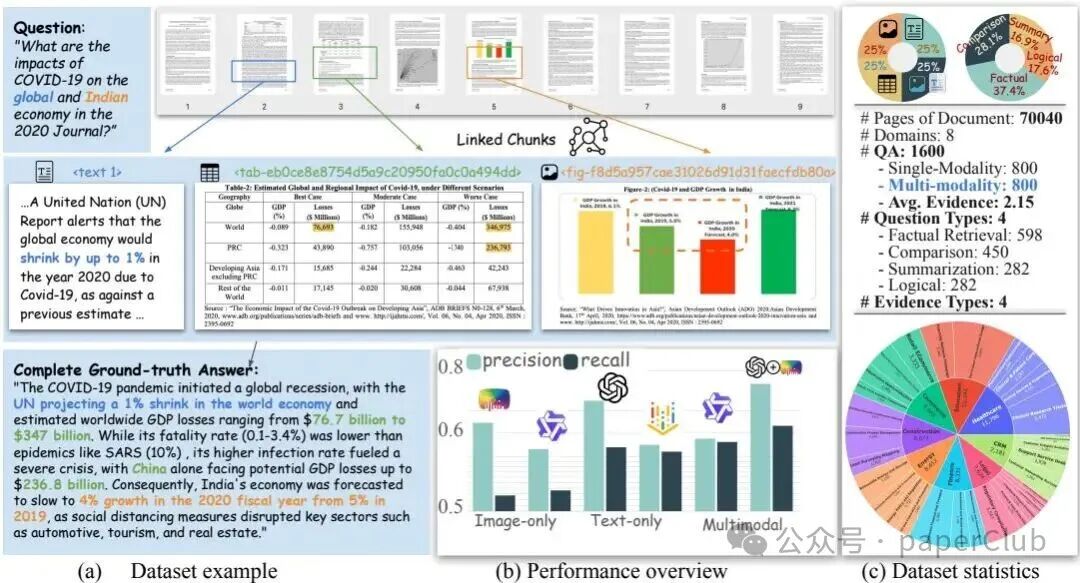
图1:UniDoc-Bench的完整工作流程,展示了从原始PDF文档到数据集构建与评估的全过程。
此外,为了保证数据集的可靠性,研究人员对其中20%的问答对进行了多重人工验证,确保每个答案的真实性与完整性。
研究结果
实验数据表明,采用文本-图像融合策略的RAG系统在答案的完整性和准确性上,显著优于仅使用单模态检索或简单联合多模态检索的系统。其中,文本-图像融合系统的平均完整率达到了68.4%。这一发现证实,在处理复杂查询时,尤其是当问题需要视觉证据支持时,单一模态的检索能力是远远不够的。同时,实验也揭示,仅依赖图像检索在捕获文本语义信息方面存在明显短板,未来RAG系统的改进需要更多地关注图像相关问题的处理。
| 模型 |
平均完整性 |
平均召回率 |
| 文本-图像融合系统 |
68.4% |
82.1% |
| 多模态联合检索系统 |
64.1% |
79.6% |
| 文本检索系统 |
65.3% |
76.3% |
| 图像检索系统 |
54.5% |
70.8% |
表1:不同RAG模型在UniDoc-Bench上的效果对比。数据显示,文本-图像融合方法具有明显优势。
UniDoc-Bench还支持对系统在不同文档特征和问题类型下的检索能力进行细粒度分析,为实际应用中的优化提供了切实可行的指导。
结论与展望
UniDoc-Bench不仅为文档中心的多模态RAG研究提供了一个标准化、可复现的评估平台,还通过详实的实验验证了文本与图像深度融合策略的显著优越性。这些成果对于推动下一代文档智能系统的开发与评估具有重要价值。未来的研究可以持续探索如何更有效地结合视觉与文本信息,以应对更加复杂和多样的真实应用场景。同时,通过此类基准测试,我们能更清晰地认识到当前RAG系统的局限性,从而为后续的技术演进指明方向。
📚 文献信息
|  发表于 2025-12-15 04:51:26
|
查看: 193|
回复: 0
发表于 2025-12-15 04:51:26
|
查看: 193|
回复: 0
