作为跨架构仿真与虚拟化的基石,QEMU是理解所有虚拟化方案的关键。它不仅能实现从指令集到设备驱动的全栈软件仿真,还能通过与KVM/XEN等硬件加速模块、VirtIO高性能设备模型的协作,达到接近物理硬件的性能水平。本文将从QEMU的生命周期管理、TCG跨架构仿真原理、设备驱动模拟以及中断机制四个方面,深入剖析其核心工作原理。
一、什么是 QEMU?—— 从「软件仿真器」到「虚拟化加速器」
1.1 QEMU 的核心定位
QEMU(Quick Emulator)是一款开源的跨平台硬件仿真器,同时也是云原生/IaaS生态的核心用户态组件,其核心价值体现在两点:
- 纯软件模式仿真能力:无需依赖硬件虚拟化支持,纯软件实现对CPU指令集、内存、外设(如串口、网卡、存储控制器)的完整仿真,支持跨架构运行(如x86宿主机运行ARM Guest)。这对车载场景的「异构ECU仿真测试」至关重要。
- 虚拟化加速协作:可与KVM(Linux内核虚拟化模块)、XEN、Hyper-V等硬件加速层结合,将Guest的特权指令、内存访问等核心操作交给硬件直接执行,仅保留外设仿真等非性能敏感逻辑在用户态处理,实现「准硬件性能」。
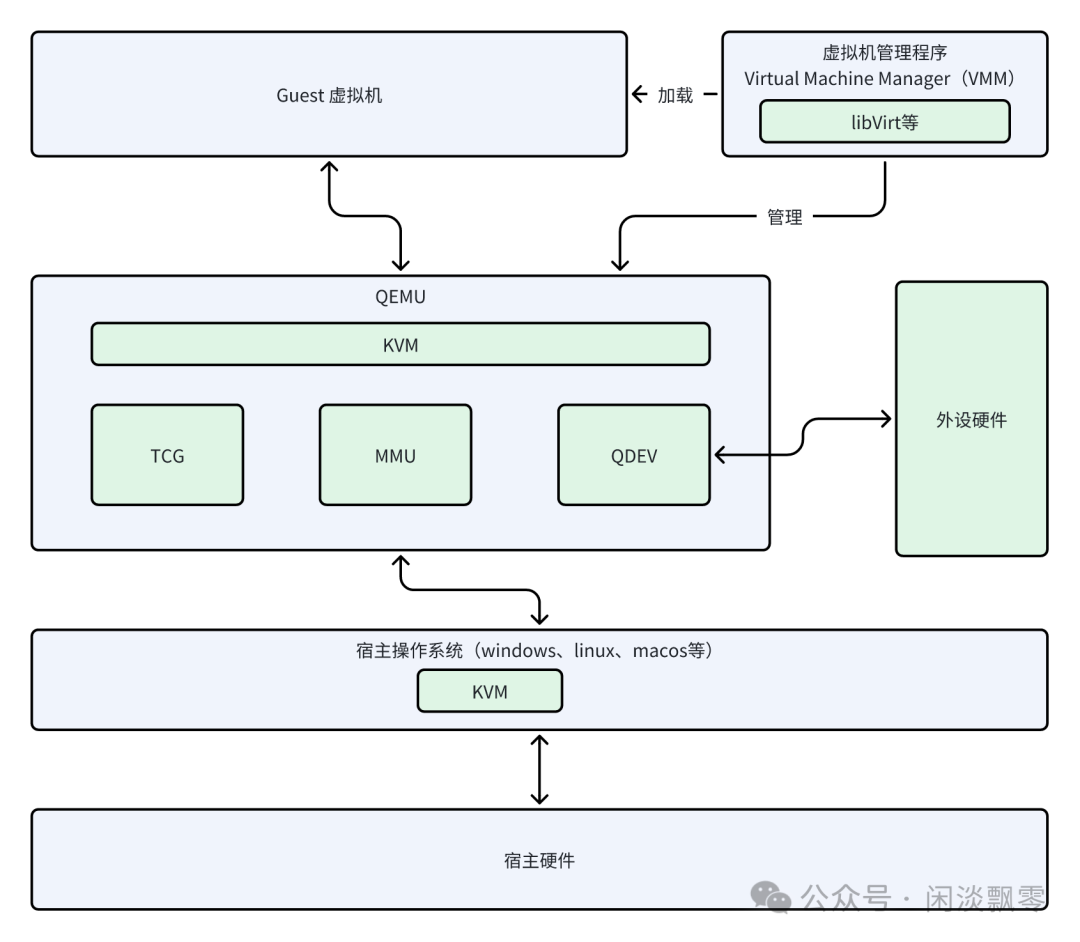
需明确:QEMU本身并非虚拟化内核,而是「仿真 + 虚拟化调度器」。当开启硬件加速时,它负责Guest生命周期管理、设备仿真、中断处理,而指令执行由KVM等内核模块接管;无硬件加速时,则通过TCG二进制翻译实现纯软件仿真。
1.2 QEMU 是 Guest 虚拟机全生命周期的总协调员
无论是否使用KVM等硬件加速手段,QEMU都是虚拟机的创建者、加载者和设备模拟的提供者。KVM等的引入,并没有改变QEMU作为“总协调员”的地位,只是让QEMU从繁重的“CPU和内存模拟”工作中解放出来,专注于设备模拟和系统协调。下图以KVM加速模式的场景,描述下QEMU对guest虚拟机的管理流程。
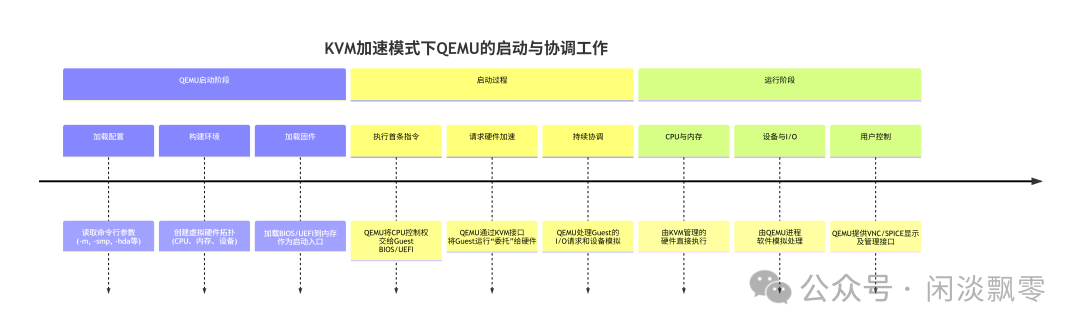
- 启动流程完全由QEMU掌控:从解析你的命令行参数、分配虚拟内存、创建虚拟CPU线程、加载BIOS/UEFI固件,到将控制权交给Guest的第一条指令,整个流程都由QEMU进程主导完成。
- KVM是QEMU调用的“加速引擎”:在启动过程中,QEMU通过Linux的
/dev/kvm 设备文件与KVM内核模块交互。它告诉KVM:“我创建了一个虚拟机,它的内存在这里,CPU状态是这些,现在请你用硬件来加速执行它的代码。”
- 分工明确:启动后,就进入了之前说的分工模式:
- QEMU:继续模拟I/O设备、处理图形显示、响应你的管理命令(如暂停、保存)。
- KVM:管理Guest的CPU状态和内存访问,让它们在物理硬件上高速执行。
可以从命令上直观地看到,QEMU始终是那个你直接调用的程序,而KVM只是它的一个加速选项:
# 纯软件模拟(慢)
qemu-system-x86_64 -m 2048 -hda guest_os.img
# 启用KVM硬件加速(快)
qemu-system-x86_64 -m 2048 -hda guest_os.img -enable-kvm
# 或更常见的简写(取决于版本)
qemu-system-x86_64 -m 2048 -hda guest_os.img -accel kvm
-accel kvm这个参数,本质上是QEMU在对自己说:“我要启动一个虚拟机,并且这次请使用KVM来加速它的CPU和内存访问。”
二、纯软件模式,跨架构仿真:TCG、软件 MMU 与 QDEV
QEMU 最强大的能力是「跨架构运行 Guest 系统」(如 x86 宿主机运行 ARM Guest),其底层依赖三大核心技术:TCG 二进制翻译(解决指令集差异)、软件 MMU(解决内存地址映射差异)、QDEV 设备模型(解决外设接口差异)。
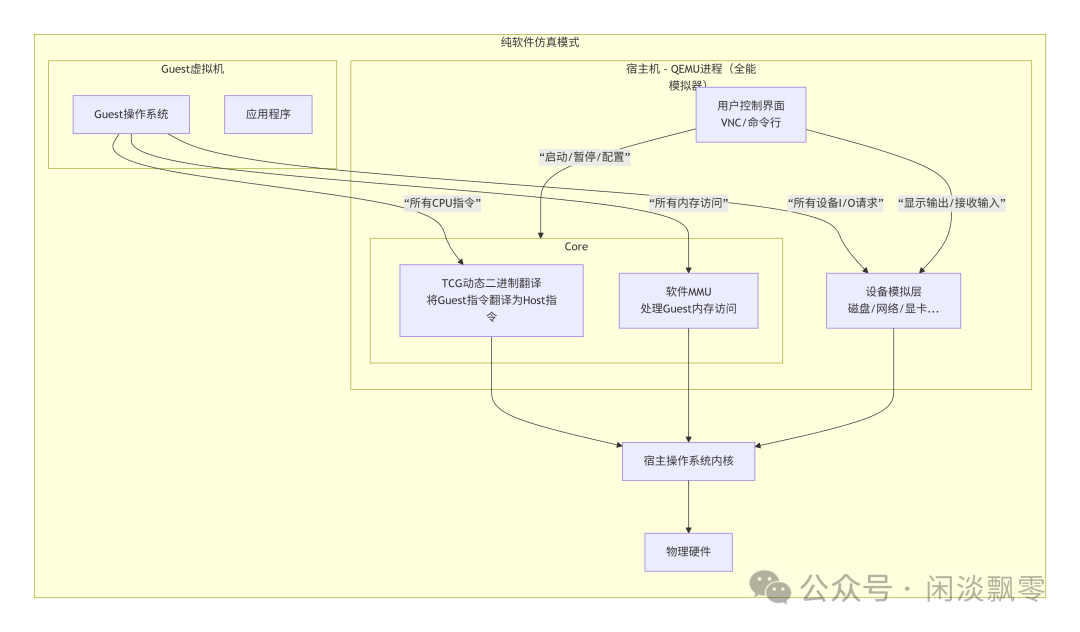
2.1 TCG:二进制翻译的「指令转换器」
TCG(Tiny Code Generator)是 QEMU 纯软件仿真的核心,本质是「动态二进制翻译引擎」—— 将 Guest 指令集(如 ARM)翻译为宿主机指令集(如 x86),再交给宿主机 CPU 执行,流程如下:
Guest指令 → TCG中间表示 → Host指令
↓ ↓ ↓
ARM/POWER 与架构无关 x86/ARM等
等原始指令 的中间码 主机指令
2.1.1 TCG 翻译流程(三阶段)
- Guest 指令解码:QEMU 的 CPU 仿真模块(如
arm_cpu_exec())读取 Guest 内存中的指令,解析为「中间表示(IR)」(TCG 自定义的与架构无关的指令集,如 tcg_gen_addi、tcg_gen_store);
- IR 优化:对 IR 进行优化(如常量折叠、死代码消除),减少冗余操作;
- Host 指令生成:将优化后的 IR 翻译为宿主机原生指令(如 x86 的
addl、movl),并缓存翻译结果(避免重复翻译),最终通过 tcg_exec() 执行。
2.1.2 跨架构适配的关键:寄存器映射与特权指令处理
- 寄存器映射:不同架构的寄存器数量、功能不同(如 ARM 有 16 个通用寄存器,x86 有 8 个),TCG 通过
CPUState 结构体维护 Guest 寄存器与宿主机内存的映射关系(如 ARM 的 r0 映射到宿主机的某个内存地址),翻译时通过加载 / 存储宿主机内存实现 Guest 寄存器的读写;
- 特权指令处理:Guest 的特权指令(如修改 CPU 模式、访问 IO 端口)无法直接在宿主机用户态执行,TCG 会将其翻译为「陷阱(Trap)」,触发 QEMU 模拟执行(如模拟 ARM 的
SVC 指令,调用 QEMU 实现的系统调用处理逻辑)。
2.1.3 TCG 与硬件加速的切换
当宿主机支持硬件虚拟化(如 Intel VT-x、AMD-V)时,QEMU 会自动切换到「KVM+TCG 混合模式」:
- 非特权指令:直接交给 KVM 执行(硬件加速,无翻译开销);
- 特权指令 / IO 操作:触发 VM-Exit,由 QEMU 通过 TCG 模拟执行。
2.2 软件 MMU:模拟内存地址映射
Guest 系统的内存地址是「虚拟地址」,需要经过「Guest 虚拟地址→Guest 物理地址→宿主机虚拟地址→宿主机物理地址」的四级映射。在无硬件虚拟化支持时,这一映射完全由 QEMU 的「软件 MMU」实现:
Guest虚拟地址 → Guest物理地址 → Host虚拟地址
↓ ↓ ↓
通过仿真的 通过设备/内存 通过QEMU内存
TLB/页表转换 映射关系 管理映射到
2.2.1 软件 MMU 的核心逻辑
- Guest 页表解析:QEMU 模拟 Guest 的 MMU 功能,解析 Guest 内核维护的页表(如 ARM 的页表项、x86 的页目录项);
- 地址转换:当 Guest 访问内存时,软件 MMU 按 Guest 页表规则将「Guest 虚拟地址」转换为「Guest 物理地址」,再通过 QEMU 维护的「Guest 物理地址→宿主机虚拟地址」映射表,最终转换为宿主机可访问的地址;
- TLB 缓存:为减少页表解析开销,软件 MMU 实现了「虚拟 TLB(Translation Lookaside Buffer)」,缓存近期的地址转换结果,命中时直接返回转换后的地址。
2.2.2 与硬件 MMU 的区别
硬件 MMU 由宿主机 CPU 硬件实现地址转换,开销极低;而软件 MMU 是纯软件模拟,开销较高(约为硬件 MMU 的 1/10 性能),但胜在无需硬件支持,可跨架构灵活适配。
三、QEMU 设备驱动仿真实现:核心是 “硬件行为建模”
QEMU并不直接“仿真驱动程序”,而是通过精准模拟硬件的物理行为、寄存器交互、总线协议和异步事件(中断/DMA),让目标系统的原生驱动程序无需修改,就能像在真实硬件上一样正常工作。其核心逻辑是:驱动的所有硬件操作(寄存器读写、中断请求、数据传输),都能被QEMU模拟的硬件“正确响应”,从而让驱动完成自身功能。
3.1 驱动仿真的核心前提:QEMU不碰驱动代码,只做“硬件替身”
- 目标系统的驱动程序完全不变,其逻辑仍是“通过操作硬件寄存器/总线实现功能”;
- QEMU的角色是“硬件替身”:模拟驱动依赖的所有硬件特性,接收驱动的所有硬件访问请求,并返回符合硬件手册的响应;
- 核心目标:驱动与QEMU模拟硬件的交互逻辑,和驱动与真实物理硬件的交互逻辑完全一致。
3.2 驱动仿真的核心框架:QDev设备模型(硬件仿真的“底座”)
QEMU所有设备的仿真都基于QDev(QEMU Device Model)框架——这是一个面向对象的硬件抽象层,为驱动与硬件的交互提供统一接口。
QDev框架的核心作用
- 定义硬件的“抽象接口”:所有模拟设备都继承QDev的核心接口,确保驱动与不同设备的交互方式统一。
- 管理设备生命周期:初始化(init)、状态保存/恢复(save/load)、热插拔(hotplug)。
- 实现设备间通信:通过总线(如CAN、SPI、PCI)将设备挂载到系统中,模拟真实硬件的拓扑结构。
QDev设备的核心接口(驱动交互的关键)
| 接口 |
功能描述 |
驱动交互场景 |
read() |
处理驱动对设备寄存器的“读请求”,返回模拟的硬件状态 |
驱动查询设备状态(如CAN发送是否完成) |
write() |
处理驱动对设备寄存器的“写请求”,更新模拟硬件的状态 |
驱动配置设备(如CAN波特率)、发送数据 |
interrupt() |
向中断控制器发送中断请求,触发驱动的中断服务程序(ISR) |
设备异步事件(如CAN帧接收完成) |
dma_transfer() |
模拟DMA传输(无需CPU干预,直接读写内存) |
驱动通过DMA读写大尺寸数据(如Flash擦写) |
四、QEMU靠「内存区域映射+地址拦截」实现驱动仿真
QEMU能截获“直接寄存器地址访问”的本质,是“地址空间的接管与映射”:
- QEMU提前注册模拟外设的地址范围(MMIO/PIO),绑定读写回调;
- 驱动直接读写该地址时,被QEMU或KVM拦截(根据模式);
- QEMU计算地址偏移,映射到对应的模拟寄存器;
- 执行寄存器的仿真逻辑(如更新状态、触发中断),返回符合硬件规范的响应。
以车载场景最常用的MCP2515 CAN控制器(SPI接口)为例,拆解QEMU如何实现驱动仿真的全流程:
4.1、关键前提:QEMU先“注册”模拟外设的地址范围
驱动直接读写的“寄存器地址”(如0x90000000),本质是外设的内存映射I/O(MMIO)地址。QEMU要截获这些访问,第一步是「提前注册内存区域」,明确告知:“某段地址是我模拟的外设,所有对这段地址的访问都要通知我”。这个过程通过QEMU的MemoryRegion机制实现:
4.1.1 核心概念:MemoryRegion(内存区域)
MemoryRegion是QEMU用于管理“地址空间”的核心结构体,作用是:
- 「圈地」:声明一段连续的地址范围(如
0x90000000 ~ 0x90000FFF),绑定到模拟设备(如 MCP2515);
- 「绑定回调」:给这段地址绑定「读回调函数」和「写回调函数」(即设备的
read()/write() 逻辑);
- 「挂载」:将该内存区域挂载到系统的全局地址空间(如ARM的系统地址空间),让驱动能通过地址访问到。
4.1.2 代码示例:注册内存区域
添加MCP2515驱动内存区域注册逻辑(驱动直接访问0x90000000即可触发):
// 新增:MCP2515 设备初始化时注册内存区域
static void mcp2515_init(Object *obj) {
MCP2515State *s = MCP2515(obj);
SPIDevice *spi = SPI_DEVICE(obj);
DeviceState *dev = DEVICE(obj);
// 1. 初始化 SPI 传输回调(原有逻辑)
spi->transfer = mcp2515_spi_transfer;
qdev_init_gpio_out(dev, &s->irq, 1);
// 2. 注册 MMIO 内存区域:模拟 MCP2515 的寄存器地址段
// 假设 MCP2515 的 MMIO 基地址为 0x90000000,地址长度 0x1000(4KB)
memory_region_init_io(&s->mmio_region, obj, &mcp2515_mmio_ops, s,
"mcp2515-mmio", 0x1000); // 最后一个参数是地址长度
// 3. 将内存区域挂载到系统地址空间(基地址 0x90000000)
sysbus_init_mmio(SYS_BUS_DEVICE(dev), &s->mmio_region, 0x90000000);
}
// 新增:MMIO 读写回调(驱动直接读写地址时触发)
static uint64_t mcp2515_mmio_read(void *opaque, hwaddr addr, unsigned int size) {
MCP2515State *s = opaque;
uint64_t val = 0;
// addr 是驱动访问的“偏移地址”(相对于基地址 0x90000000)
// 例如:驱动访问 0x90000000 → addr=0x00(对应 CANCTRL 寄存器)
if (addr < sizeof(s->regs)) { // 仅允许访问寄存器地址范围
val = s->regs[addr]; // 返回对应寄存器的值
qemu_log_mask(LOG_DEBUG, "MCP2515: MMIO 读地址 0x9000%04X = 0x%02X\n",
addr, val);
} else {
qemu_log_mask(LOG_WARNING, "MCP2515: 非法 MMIO 读地址 0x9000%04X\n", addr);
}
// 处理不同访问宽度(驱动可能用 8/16/32 位读写)
return extract64(val, 0, size * 8);
}
static void mcp2515_mmio_write(void *opaque, hwaddr addr, uint64_t val, unsigned int size) {
MCP2515State *s = opaque;
if (addr < sizeof(s->regs)) {
// 按访问宽度写入(如驱动用 32 位写,仅取低 8 位写入寄存器)
s->regs[addr] = deposit64(s->regs[addr], 0, size * 8, val);
qemu_log_mask(LOG_DEBUG, "MCP2515: MMIO 写地址 0x9000%04X = 0x%02X\n",
addr, s->regs[addr]);
// 写 CANCTRL 寄存器时更新波特率(原有逻辑复用)
if (addr == MCP2515_REG_CANCTRL) {
mcp2515_update_baudrate(s);
}
} else {
qemu_log_mask(LOG_WARNING, "MCP2515: 非法 MMIO 写地址 0x9000%04X\n", addr);
}
}
// 新增:MMIO 操作表(绑定读写回调)
static const MemoryRegionOps mcp2515_mmio_ops = {
.read = mcp2515_mmio_read,
.write = mcp2515_mmio_write,
.endianness = DEVICE_LITTLE_ENDIAN, // 匹配车载 ARM 架构的小端模式
.valid = {
.min_access_size = 1, // 支持 8 位访问
.max_access_size = 4, // 支持 32 位访问(驱动常用)
.unaligned = false, // 不允许非对齐访问(符合硬件特性)
},
};
关键说明:
- 驱动访问的
0x90000000(基地址)+ 0x00(偏移)= 模拟的 CANCTRL 寄存器,QEMU 会通过 addr=0x00 找到对应的寄存器;
- 无论驱动是用
*(uint8_t *)0x90000000 = 0x05 还是 *(uint32_t *)0x90000000 = 0x05,QEMU 都会按访问宽度处理;
- 这段地址是「虚拟的」,不会映射到主机的真实物理内存。
4.2、核心流程:驱动直接读写地址 → QEMU 截获 → 仿真响应
以「驱动直接写 MCP2515 的 CANCTRL 寄存器」为例,完整流程如下:
场景 1:纯 QEMU(TCG 模式,无 KVM 加速)
- 驱动发起地址写:驱动代码
*(volatile uint32_t *)0x90000000 = 0x05;
- QEMU 地址翻译拦截:QEMU 模拟目标系统的「地址翻译单元(MMU)」,检查到
0x90000000 属于注册的 mcp2515-mmio 内存区域,触发拦截;
- 计算寄存器偏移:QEMU 用访问地址减去基地址,得到偏移
0x00;
- 执行仿真逻辑:QEMU 调用
mcp2515_mmio_write 回调,将 0x05 写入 s->regs[0x00],并触发波特率更新;
- 返回响应:QEMU 完成写操作后,继续执行驱动后续指令。
场景 2:QEMU-KVM 模式(硬件加速)
- 驱动发起地址写:驱动直接写
0x90000000;
- KVM 触发 VMEXIT:KVM 发现地址命中“模拟区域”,触发
VMEXIT,将控制权交还给 QEMU;
- QEMU 处理访问:QEMU 执行和纯 QEMU 一致的逻辑(计算偏移、调用写回调、更新寄存器);
- KVM 恢复 Guest 运行:QEMU 处理完成后,通知 KVM,KVM 触发
VMENTRY,将控制权还给 Guest。
| 两种场景对比: |
模式 |
拦截触发者 |
核心优势 |
嵌入式系统场景适用 |
| 纯 QEMU |
QEMU 自身 |
无硬件依赖,模拟精度高 |
ECU 早期开发、测试 |
| QEMU-KVM |
KVM + VMEXIT |
指令执行快,性能接近原生 |
域控制器虚拟化 |
4.3 结合 MCP2515 示例的实际验证
假设车载驱动代码如下:
// 驱动直接定义 MCP2515 寄存器地址(基地址 0x90000000)
#define MCP2515_CANCTRL ((volatile uint8_t *)0x90000000)
#define MCP2515_CANMSGID ((volatile uint32_t *)0x90000002)
#define MCP2515_CANMSGDATA ((volatile uint8_t *)0x90000006)
// 驱动配置波特率并发送 CAN 帧
void can_send_frame(uint32_t id, uint8_t dlc, uint8_t *data) {
*MCP2515_CANCTRL = 0x03; // 直接写 CANCTRL 寄存器,配置 BRP=3(500kbps)
*MCP2515_CANMSGID = id; // 直接写 CAN ID 寄存器
for (int i=0; i<dlc; i++) {
MCP2515_CANMSGDATA[i] = data[i]; // 直接写数据寄存器
}
// 触发发送(假设某地址写 1 触发发送)
*(volatile uint8_t *)0x9000000E = 0x01;
}
QEMU 处理流程:
- 驱动写
0x90000000(CANCTRL)→ QEMU 拦截,调用 mcp2515_mmio_write,更新 BRP。
- 驱动写
0x90000002(CANMSGID)→ QEMU 计算偏移 0x02,写入 s->regs[0x02]。
- 驱动写
0x90000006~0x9000000D(数据寄存器)→ QEMU 写入对应偏移的寄存器。
- 驱动写
0x9000000E(发送触发地址)→ QEMU 触发 mcp2515_encode_can_frame,模拟 CAN 帧发送。
整个过程中,驱动完全是“直接地址操作”,但QEMU通过地址拦截和寄存器映射,完美模拟了硬件行为。
五、QEMU 的中断机制:Guest 调度与设备驱动的核心
中断是Guest系统调度、设备驱动协作的基础。QEMU需模拟Guest的中断控制器(如ARM GIC、x86 IOAPIC),并协调宿主机的中断资源,实现「Guest中断→QEMU捕获→宿主机处理→Guest响应」的闭环。
5.1 QEMU 支持的中断类型
- 外部中断:由外设触发(如网卡接收数据),通过中断控制器通知CPU。
- 内部异常:Guest执行错误指令触发,由CPU内部处理。
- 虚拟中断:由QEMU或宿主机内核注入,用于调度Guest进程。
5.2 中断控制器仿真
QEMU针对不同架构实现了对应的中断控制器仿真:
- x86架构:PIC(8259)、IOAPIC。
- ARM架构:GIC(Generic Interrupt Controller),车载ARM架构ECU常用GICv2。
- RISC-V架构:PLIC。
中断控制器的核心功能:管理中断源、优先级仲裁、中断屏蔽/使能、向CPU发送中断请求(IRQ)。
5.3 中断处理流程(以 KVM 加速为例)
- Guest外设触发中断:如虚拟串口设备调用
qemu_irq_raise(s->irq) 触发中断。
- QEMU中断控制器处理:GIC仿真模块接收中断,进行优先级仲裁,通过
kvm_irqfd() 接口向KVM注入中断。
- KVM中断调度:KVM内核模块将中断映射为宿主机的文件描述符(irqfd),触发宿主机中断处理。
- Guest响应中断:KVM触发VM-Entry,将中断信号传递给Guest CPU,Guest内核跳转到中断服务程序(ISR)处理。
- 中断结束:Guest处理完成后,通过EOI指令通知中断控制器,QEMU调用
qemu_irq_lower(s->irq) 清除中断状态。
5.4 中断在车载场景的意义
车载ECU的实时性依赖中断响应。QEMU对GIC等中断控制器的精准仿真,是「车载ECU软件在虚拟环境中保持实时性」的关键。例如,仿真CAN控制器的中断延迟需控制在微秒级,才能匹配物理ECU的行为。
 发表于 2025-12-15 06:42:48
|
查看: 259|
回复: 0
发表于 2025-12-15 06:42:48
|
查看: 259|
回复: 0
