系统突发OOM崩溃或服务无响应时,许多开发者会首先排查应用层代码,却容易忽略Linux内核内存布局这一底层基石。对Linux而言,内核内存的分区规划、地址分配与资源调度策略,直接决定了整个系统的稳定性与性能。作为连接硬件与应用程序的中间层,内核需要同时承载代码执行、设备映射与进程管理等核心任务,而内存布局正是这些任务得以有序进行的“空间宪法”——代码段、数据段及各类映射区域的划分,直接影响着内存访问效率与资源冲突风险。
运维人员常遇到的“物理内存充足,内核却频繁杀进程”的困境,根源往往在于对内存布局认知不足,导致内核空间被不合理占用或碎片化。本文将深入拆解Linux内核内存布局的核心逻辑,阐明各内存区域的功能边界、地址范围与访问规则,并解析布局设计如何从源头上规避内存泄漏、地址冲突等风险。理解这些底层机制,不仅能帮助您快速定位内存相关故障,更能从系统层面进行优化,为高负载业务稳定运行筑牢基础。
一、Linux内核内存布局核心概念
1.1 全景概览:用户空间与内核空间
为了直观理解Linux内核内存布局,我们首先通过一张全景图来建立整体认知:
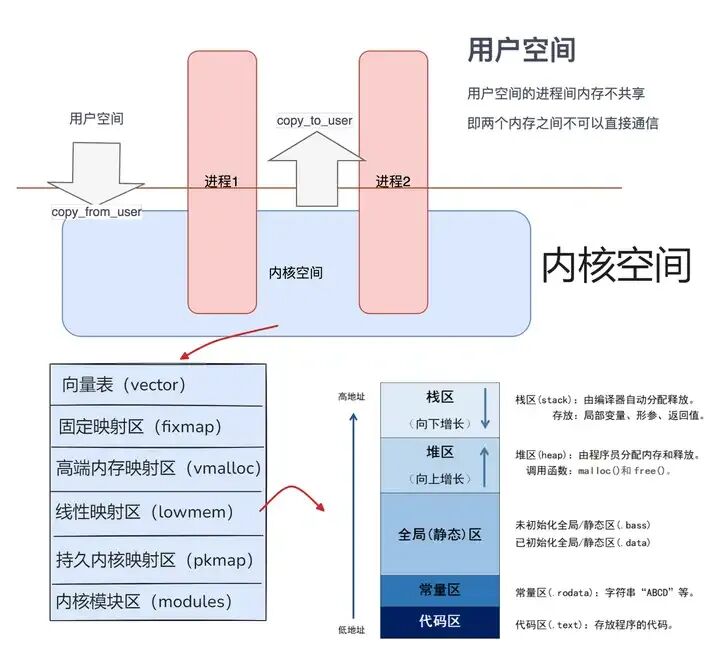
如图所示,整个系统的虚拟地址空间被清晰地划分为两大区域:用户空间和内核空间。
- 用户空间是普通应用程序的运行沙箱。每个用户进程都拥有自己独立的用户空间实例,它们彼此隔离,互不干扰,如同公寓楼里每个住户的独立房间。
- 内核空间则是操作系统核心代码与数据的驻地,是所有进程共享的“公共区域”。它直接管理硬件资源,并提供系统服务。
在内核空间内部,又根据功能被精细划分为若干子区域:
- 向量表:存放异常与中断处理程序的入口地址,是系统应对突发事件的“应急指挥中心”。
- 固定映射区:用于在系统启动早期或特殊场景下,固定映射某些必须的物理地址(如硬件寄存器),映射关系在编译时即确定。
- 高端内存映射区:主要用于通过
vmalloc()分配虚拟地址连续但物理地址不一定连续的大块内存,例如文件缓存。
- 线性映射区:这是内核最核心、访问最频繁的区域。它通过简单的偏移(
PAGE_OFFSET)将大部分物理内存直接映射到内核虚拟地址空间,包含了内核自身的代码段(.text)、初始化段(.init)、数据段(.data)和BSS段(.bss)。
- 持久内核映射区:用于建立高端物理内存页到内核虚拟地址的长期映射。
- 内核模块区:动态加载的内核模块(
.ko文件)被加载到此区域运行,增强了内核的扩展性。
1.2 架构差异:ARM64与ARM32的设计哲学
在64位Linux系统中,用户态与内核态的地址空间有着如“楚河汉界”般分明的界限。这种划分深度体现了安全与性能的平衡。
从安全角度看,用户态进程无法直接访问或篡改内核空间数据,必须通过严格的系统调用“网关”。历史上,某嵌入式设备就因驱动错误访问内核地址,导致虚拟地址越界,最终引发系统Panic。
从性能角度看,内核态拥有直接、高效访问物理内存的特权。例如在ARM64架构中,通过固定的PAGE_OFFSET偏移量,内核能像访问数组一样快速寻址物理内存。而用户态程序则必须通过系统调用接口,请求内核代为操作。
不同的处理器架构在内存布局设计上也各具特色:
1. ARM64架构:简洁高效
ARM64采用了一种更为简洁的设计。它通常拥有一个巨大的线性映射区(如128TB),能够直接覆盖全部物理内存,无需复杂的高端内存映射机制,大大简化了内核访问物理内存的路径。同时,其vmalloc区域也非常庞大,便于分配用于DMA缓冲等需要大量非连续物理内存的场景。
2. ARM32架构:复杂与限制
ARM32的内存布局则相对复杂。在有限的1GB内核空间中,仅有一部分(如768MB)用于线性映射低端内存。当物理内存较大时,超出部分需要通过pkmap等机制动态映射,容易造成映射资源竞争。在物理内存超过一定阈值时,频繁的kmalloc失败可能导致服务中断,这在小内存嵌入式系统中是需要重点关注的系统优化点。
二、用户空间内存布局详解
用户空间内存布局是单个进程运行时内存资源的组织蓝图,它定义了程序代码、数据、堆栈等的存放位置。
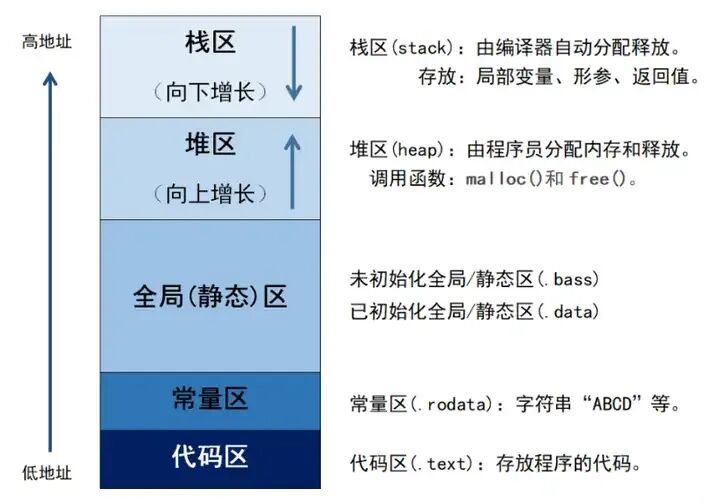
2.1 代码段与数据段
- 代码段:存放编译后的机器指令,属性为只读,防止程序意外修改自身代码。
- 数据段:存放已初始化的全局变量和静态变量。
- BSS段:存放未初始化的全局和静态变量,在程序加载时由系统自动初始化为零。
2.2 堆与栈
- 堆:用于动态内存分配,通过
malloc/free等函数管理,方向由低地址向高地址增长。
- 栈:用于存放函数调用的现场信息,如局部变量、参数、返回地址等,方向由高地址向低地址增长。
2.3 内存映射段
这是进程与外部资源交互的桥梁,通过mmap系统调用创建,主要用于文件映射和动态库加载。
动态库加载示例:
// 1. 编写动态库 libmath.cpp
extern “C” {
int add(int a, int b) { return a + b; }
int multiply(int a, int b) { return a * b; }
}
// 编译:g++ -fPIC -shared -o libmath.so libmath.cpp
// 2. 主程序动态加载
#include <dlfcn.h>
int main() {
void* handle = dlopen("./libmath.so", RTLD_LAZY); // 映射到内存映射段
int (*add_func)(int, int) = (int (*)(int, int))dlsym(handle, "add");
printf("Result: %d\n", add_func(10, 20));
dlclose(handle); // 解除映射
return 0;
}
关键点:编译动态库需使用-fPIC(位置无关代码)和-shared选项;mmap的权限不能超过文件打开模式;使用后需用munmap和dlclose释放资源,避免内存泄漏。
三、内核空间内存布局(32位系统视角)
在32位系统中,内核空间通常占据虚拟地址空间的最高1GB(0xC0000000 ~ 0xFFFFFFFF)。
3.1 线性映射区
这是内核的“高速通道”,虚拟地址与物理地址呈简单的线性关系(虚拟地址 = 物理地址 + PAGE_OFFSET)。内核核心代码、数据及task_struct、mm_struct等高频访问的数据结构都位于此区域。其最大优势是访问速度极快,无需复杂页表查询。
3.2 vmalloc动态映射区
此区域用于分配虚拟地址连续、物理地址可不连续的大块内存,通过vmalloc()接口分配。它非常适合分配DMA缓冲区、加载大型内核模块或解决物理内存碎片化问题。但由于需要遍历页表查找物理页,其访问速度低于线性映射区。
3.3 高端内存映射区
当物理内存大于线性映射区容量时,超出部分即为“高端内存”。内核需要通过kmap等函数将高端内存页临时映射到此区域才能访问,用完后需kunmap解除映射。
3.4 Fixmap固定映射区
这是一个在编译时就预留好虚拟地址的“特殊车位”,用于在系统启动早期(MMU未完全就绪时)映射必须访问的物理地址,如用于临时页表操作或映射PCI设备寄存器。其地址固定,需小心使用以避免冲突。
3.5 持久内核映射区
用于建立高端内存到内核虚拟地址的长期、稳定映射,方便内核持续访问高端内存页。
四、核心内存管理机制
4.1 页表与地址转换
页表是虚拟地址转换为物理地址的“地图”。以x86_64为例,采用四级页表结构(PGD->PUD->PMD->PT)。每次内存访问,MMU都通过页表进行查表转换。每个进程拥有独立的页表,这是实现进程间内存隔离的基础。页表项中的权限位(读/写/执行)则实现了精细的内存保护。
4.2 内存分配与回收
内核提供了不同特点的内存分配接口:
kmalloc():分配物理地址连续的小块内存,基于Slab分配器,速度快,常用于驱动开发。
char *buf = kmalloc(1024, GFP_KERNEL);
if (buf) { /* 使用缓冲区 */ kfree(buf); }
vmalloc():分配虚拟地址连续的大块内存,物理地址可不连续,适用于大块非频繁访问内存。
void *large_buf = vmalloc(1024*1024);
if (large_buf) { /* 使用 */ vfree(large_buf); }
当系统内存紧张时,内核回收机制启动,主要回收干净的文件页和将不活跃的匿名页交换到Swap分区。
五、布局失衡:典型故障模式
5.1 内存碎片化
- 外部碎片:频繁分配释放不同尺寸内存,导致空闲内存支离破碎,无法满足大块连续内存请求。Linux的伙伴系统通过2的幂次方块的合并与分割来缓解此问题,但极端情况下仍可能触发OOM Killer。
- 内部碎片:Slab分配器为特定内核对象(如
dentry)预分配固定大小内存块,当对象尺寸小于块大小时产生浪费。长期运行后,累积的内部碎片可能拖慢系统。
5.2 地址空间隔离失效
- 用户态越界:若因页表错误导致用户程序能访问内核空间,可篡改内核数据结构(如调度队列),甚至植入rootkit,造成安全灾难。
- 内核模块冲突:动态加载的内核模块若与现有内核区域地址重叠,会导致模块失效或引发内核Panic。
六、真实生产案例复盘
6.1 案例一:dentry泄漏导致内存耗尽
背景:某电商负载均衡集群内存使用率莫名飙升至90%以上。
排查:通过slabtop发现dentry(目录项缓存)对象异常增长。溯源发现是健康检查脚本使用的curl旧版本(7.19.7)中,其依赖的NSS库存在Bug:访问HTTPS证书文件后,未调用dput()释放dentry引用计数。
后果:数百万未释放的dentry对象累积,Slab内存占用突破60%,最终触发OOM Killer,导致服务节点批量下线。
核心代码逻辑模拟:
// 有Bug的NSS库模拟:获取dentry后未释放
void access_cert_file(const string& path) {
Dentry::dget(path); // 引用计数+1
// ... 使用证书文件,但忘记调用 Dentry::dput(path);
}
// 循环的健康探测脚本导致dentry缓存池不断膨胀
教训:动态库需与内核内存管理机制良好兼容;应用层需监控底层资源(如Slab)使用情况。
6.2 案例二:内存碎片引发嵌入式设备重启
背景:某ARM32工控设备定时崩溃,日志显示“out of memory”。
排查:设备频繁调用vmalloc分配网络缓冲区,导致动态映射区碎片率超80%。物理内存虽有空闲,但已无足够连续的128KB内存块满足实时任务需求。
后果:伙伴系统合并失败,关键实时任务内存分配失败,直接导致内核Panic。
教训:在内存受限的嵌入式环境中,必须审慎使用vmalloc,并考虑采用预分配内存池、限制分配频率等策略来避免碎片积累。
七、攻防之道:从设计到调优
7.1 预防优先:构建稳健布局
- 碎片控制:
- 优先使用栈或静态内存,减少动态分配。
- 内存分配与释放尽量在同一作用域内完成。
- 按2的幂次方申请内存,适配伙伴系统。
- 内核参数调优:
- 调节
/proc/sys/vm/max_map_count,限制进程虚拟内存区域数。
- 设置
vm.overcommit_memory=2,严格限制超额提交,防止vmalloc区被挤占。
7.2 动态监控:捕捉异常信号
- 工具链:
slabtop:实时监测Slab缓存,定位dentry、inode_cache等异常增长对象。cat /proc/iomem:查看内核空间各区域占用,排查地址冲突。perf mem:追踪页错误与TLB失效,量化布局缺陷的性能影响。
- 深度调试:
ftrace:跟踪__alloc_pages调用栈,定位分配热点。crash工具:分析崩溃现场的内存结构体。- KASAN:编译时插桩,检测内核内存越界、释放后使用等错误。
7.3 架构优化:面向复杂场景
- NUMA优化:在NUMA架构下,使用
numactl将进程绑定到本地内存节点,并启用CONFIG_NUMA让伙伴系统按节点管理内存,减少远程访问延迟与碎片扩散。
- 大页技术:为数据库缓冲区、JVM堆等分配2MB或1GB的大页,能极大减少页表项数量,降低TLB压力,提升性能并减少碎片。例如,Redis启用大页后,内存分配延迟可降低40%,碎片率从35%降至5%。
理解并善用Linux内核内存布局,是每一位追求系统稳定与性能极致的开发者和运维工程师的必修课。从基本概念到架构差异,从机制原理到实战案例,再到监控调优,构建起系统性的认知,方能在复杂场景下运筹帷幄,确保服务基石坚如磐石。
 发表于 2025-12-15 09:09:34
|
查看: 194|
回复: 0
发表于 2025-12-15 09:09:34
|
查看: 194|
回复: 0
