最近在分析一道来自2016年Flare-On挑战赛决赛的CTF逆向题目 smokestack.exe,其中包含了一套自定义的虚拟机字节码,这让我对VM保护机制有了更深入的理解。
与我们熟悉的x86或ARM这类硬件指令集不同,VM字节码(Virtual Machine Bytecode)是一种由软件自定义的“中间指令集”。其执行流程通常是:源代码被编译成字节码,然后由一个内嵌的“解释器/虚拟机”循环读取操作码(Opcode),查表并执行对应的C/C++函数(或即时编译成机器码)。简单来说,它就像Java的.class文件或Python的.pyc文件,只不过这里的“迷你CPU”是由程序作者自己实现的。
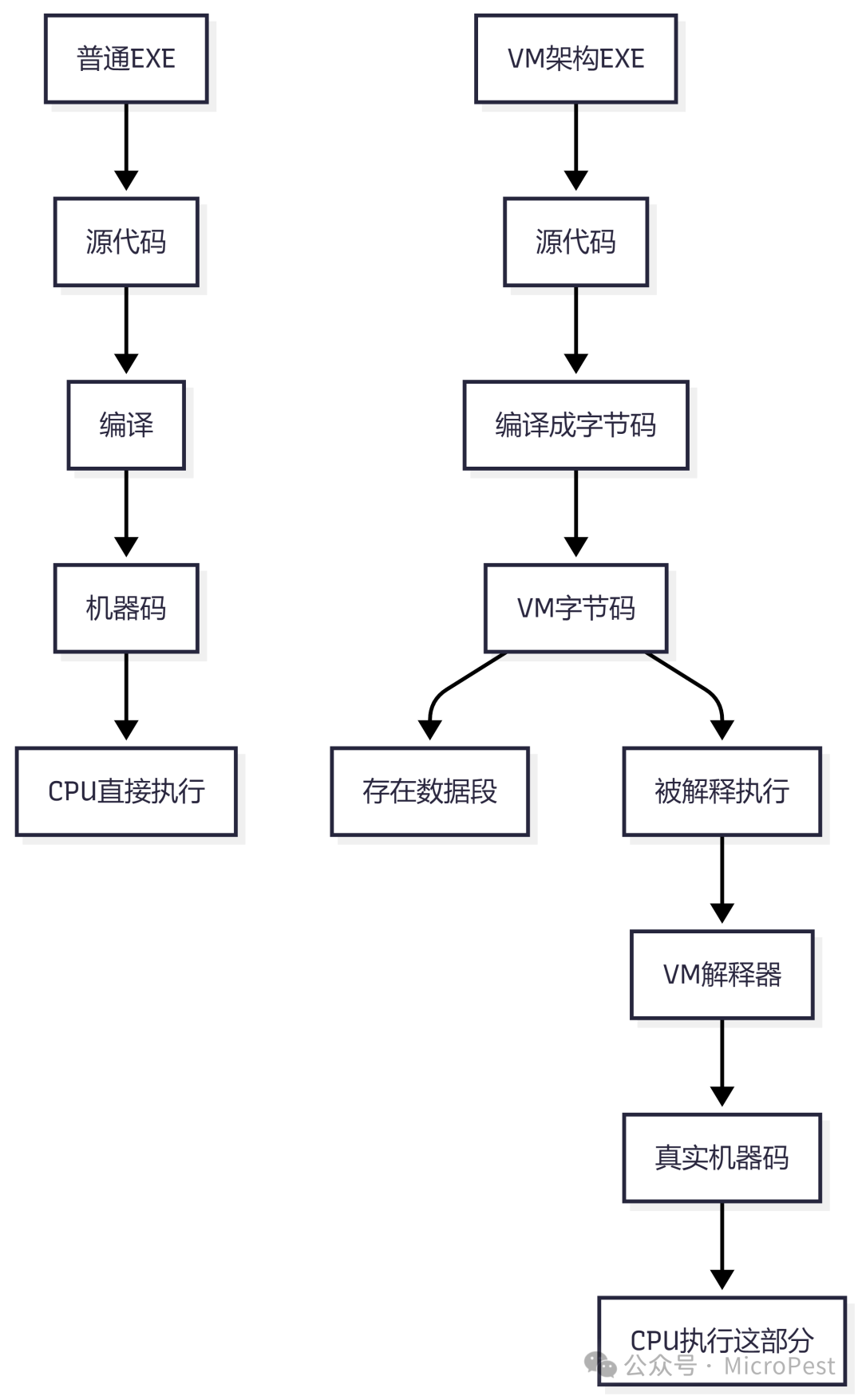
VM字节码的应用价值
- 体积小与跨平台:只需携带一个2-3 KB的解释器,同一份字节码就可以在不同平台上运行。
- 增加逆向分析难度:自定义的操作码无法被IDA等工具直接识别。分析者必须先编写反汇编器来解析字节码逻辑。
- 常用于CTF与恶意软件:将关键算法(如flag校验、许可证检查)隐藏在字节码中,迫使分析者必须完成“逆向解释器”和“逆向字节码”两个步骤,这在安全/渗透/逆向领域是一种常见的技术。
指令集与执行模型
这个自定义VM的指令格式固定为2字节:
+--------+-----------------------+
| opcode | 可选立即数 / 寄存器编号 |
+--------+-----------------------+
其指令集包含14条RISC风格的指令:
0 push imm16 ; 把16位常数压栈
1 pop ; 弹栈
2 add ; 栈顶两数相加
3 sub ; 相减
4 trm1 ; 作者自定义运算
5 trm2 ; 同上
6 xor ; 异或
7 not ; 按位取反
8 eq ; 栈顶两数相等?置0/1
9 sel ; 三目选择
10 jmp imm16 ; 无条件跳转
11 push reg16 ; 把ax/bp/sp/ip压栈
12 mov reg16, ST(0) ; 栈顶值写到寄存器
13 nop
执行模型基于三个寄存器(ax, bp, sp, ip,其中ip为字节码偏移)和一条用于push/pop操作的小栈。解释器核心就是一个 while(1) { fetch(); switch(opcode) { ... } } 的大循环。
编写字节码反汇编器
为了分析隐藏在字节码中的逻辑,我们需要编写一个反汇编器,将二进制字节码转换为可读的汇编指令。以下是核心的C++实现代码,它涉及了底层的计算机基础知识和C/C++编程技巧:
#include <iostream>
#include <fstream>
#include <vector>
#include <stdexcept>
#include <string>
#include <iomanip>
const std::vector<std::string> mnemonics =
{
"push", "pop", "add", "sub",
"trm1", "trm2", "xor", "not",
"eq", "sel", "jmp", "push",
"mov", "nop"
};
//{这个数组定义了14个VM操作码对应的助记符:
// 索引0 = "push"
// 索引2 = "add"
// 索引10 = "jmp"
// 等等...}
int main(int argc, char* argv[]);
const char* GetRegisterName(std::uint16_t register_id);
int main(int argc, char* argv[])
{
static_cast<void>(argc);
static_cast<void>(argv);
//参数检查
if (argc != 2)
{
std::cout << "Usage:\n";
std::cout << "smokestack_disasm dump" << std::endl;
//需要一个参数:字节码文件路径
return 1;
}
//读取字节码文件到内存
std::vector<std::uint8_t> buffer;
try
{
std::fstream input_file;
input_file.open(argv[1], std::ios_base::in |
std::ios_base::binary);
if (!input_file)
throw std::runtime_error("Failed to open the input file");
input_file.seekg(0, std::ios_base::end);
if (!input_file)
throw std::runtime_error("Seek failed");
std::streamsize input_file_size = input_file.tellg();
if (!input_file)
throw std::runtime_error("Failed to get the file size");
input_file.seekg(0);
if (!input_file)
throw std::runtime_error("Seek failed");
buffer.resize(input_file_size);
if (buffer.size() != input_file_size)
throw std::runtime_error("Memory allocation failed");
input_file.read(reinterpret_cast<char*>(buffer.data()),
input_file_size);
if (!input_file)
throw std::runtime_error("Failed to read the file");
input_file.close();
}
catch (const std::exception& exception)
{
std::cout << exception.what() << std::endl;
return 1;
}
//逐条解析字节码
const std::uint8_t* ptr = buffer.data();
//解析并输出每条指令
while (ptr < buffer.data() + buffer.size())
{
//计算当前指令地址(以16位字为单位)
std::uint32_t instruction_pointer = (ptr - buffer.data()) / 2;
//输出格式:地址+操作码+助记符
std::cout << std::hex << std::setfill('0') << std::setw(4)
<< instruction_pointer; //地址
std::cout << "\t\t";
std::cout << std::hex << std::setfill('0') << std::setw(2) <<
static_cast<int>(*ptr); //操作码
std::cout << "\t" << mnemonics[*ptr] << " "; //助记符
// opcodes that require immediate parameters needs to
// increment the instruction pointer twice
switch (*ptr)
{
// push <immediate>
case 0:
{
ptr += 2; //跳过操作码,指向参数
//读取16位立即数
std::uint16_t value =
*reinterpret_cast<const std::uint16_t*>(ptr);
std::cout << "0x" << std::hex << std::setfill('0') <<
std::setw(4) << value;
// 如果是可打印ASCII字符,显示字符形式
if (value >= 0x20 && value <= 0x7D)
{
std::cout << " ; '" << static_cast<char>(value)
<< "'";
}
break;
}
// push <register_id>
case 11:
{
ptr += 2;
std::uint16_t value =
*reinterpret_cast<const std::uint16_t*>(ptr);
std::cout << GetRegisterName(value); //转换寄存器ID为名称
break;
}
// mov <register_id>, stack[sp]
case 12:
{
ptr += 2;
std::uint16_t value =
*reinterpret_cast<const std::uint16_t*>(ptr);
std::cout << GetRegisterName(value);
std::cout << ", ST(0)";
break;
}
default:
break;
}
std::cout << std::endl;
//跳转指令后添加空行,增加可读性
if (*ptr == 10) //操作码10 = jmp
{
std::cout << std::hex << std::setfill('0') << std::setw(4)
<< instruction_pointer << std::endl;
}
ptr += 2;
}
return 0;
}
const char* GetRegisterName(std::uint16_t register_id)
{
switch (register_id)
{
case 0:
return "ax";
case 1:
return "bp";
case 2:
return "sp";
case 3:
return "ip";
default:
throw std::runtime_error("Invalid register id");
}
}
这个程序的核心功能是将二进制的VM字节码文件转换成可读的汇编指令,从而大幅降低逆向分析的难度。
使用方法
- 提取字节码:从
Smokestack.exe 的虚拟地址 0x0040A140 处提取VM字节码数据段,保存为独立文件(如 vm_bytecode.bin)。
- 编译反汇编器:使用C++编译器编译上述代码。
g++ smokestack_disasm.cpp -o smokestack_disasm
- 运行反汇编:执行生成的反汇编器程序,处理字节码文件。
./smokestack_disasm vm_bytecode.bin > disassembly.txt
反汇编输出示例
运行后,你将得到类似以下的可读指令序列:
0000 00 push 0x0021
0002 02 add ; \ adds 0x21 to the last character in the
0003 00 push 0x0091 ; / program argument
0005 08 eq
0006 00 push 0x0016
0008 00 push 0x000c ; \ this is what we should take. last char
000a 09 sel ; / is: 0x91 - 0x21 = 'p'
000b 0a jmp
000b
通过分析这些指令,可以清晰地看出VM正在执行的运算逻辑,例如对输入字符进行加法、比较和选择操作。
逆向策略对比:普通EXE vs VM保护EXE
| 目标 |
普通EXE |
VM保护EXE |
| 工具 |
IDA Pro直接反编译 |
需要先理解VM架构 |
| 难度 |
中等 |
高 |
| 方法 |
直接分析汇编 |
1. 识别VM 2. 提取字节码 3. 写反汇编器 4. 分析虚拟汇编 |
| 调试 |
直接下断点 |
需要在VM引擎解释循环处下断点 |
总结
这个为 smokestack.exe 自定义VM编写的反汇编器,本质上就是它的专用“IDA Pro”。其核心价值在于:
- 降低分析难度:将晦涩的二进制数字转化为可理解的代码。
- 理解程序逻辑:清晰地展示VM执行的每一步运算。
- 辅助手工求解:根据反汇编结果推导出约束方程。
- 验证理解正确性:确认我们对自定义指令集的解读是否准确。
VM架构的本质是“程序中的程序”——一个用真实机器码实现的软件CPU,用以运行另一套自定义的指令集。这正是解决此类逆向题目的关键:必须首先理解VM的架构和工作原理,然后才能通过工具揭开其内部逻辑。希望这次对2016 Flare-On赛题 smokestack.exe 的探讨,能为你理解VM保护技术提供一个实用的切入点。在云栈社区,你还可以找到更多关于逆向工程和其他底层技术的深度讨论与资源分享。
 发表于 2026-1-31 04:05:56
|
查看: 160|
回复: 0
发表于 2026-1-31 04:05:56
|
查看: 160|
回复: 0
