如果你的程序还在用 ifstream 和多线程来读取文件,感觉慢是正常的,这往往不叫并发,更像是一种内耗。
当你需要快速读取分布在多块SSD上的大量文件时,一个关键策略是:一个线程锁死一块盘,这样往往就够了。
下面我们直接进入核心的优化方法。
一、物理隔离:为每块SSD分配专属线程
核心思路:为每一块物理SSD分配一个专属的I/O线程,让这个线程在其生命周期内,只负责读取该盘上的文件。
假设你有八块SSD,这本身就是一个极佳的物理并发基础。优化的关键不在于创建大量线程然后让它们无序地竞争文件,而是从源头进行清晰的任务划分。
操作思路:获取所有待读文件的路径,然后根据它们所在的物理挂载点进行分组。例如,/mnt/ssd1 下的所有文件归为一组,/mnt/ssd2 下的归为另一组,依此类推。
接着,为每一组(即每一块SSD)创建一个专属的I/O工作线程。这个线程只负责读取属于自己那块盘的文件。这样一来,每个线程操作的都是独立的物理设备,I/O请求之间不会相互干扰,每个SSD内部的I/O队列深度和NVMe的多队列优势都能被充分利用。
那么,代码如何实现呢?
首先,我们需要一个函数来获取文件所在的物理设备标识。在Linux系统中,可以通过解析 /proc/mounts 或使用 stat 系统调用来实现。
以下是分组逻辑的核心代码片段:
#include <iostream>
#include <vector>
#include <string>
#include <map>
#include <filesystem>
#include <sys/stat.h>
namespace fs = std::filesystem;
// 获取文件所在的文件系统设备ID
dev_t get_device_id(const std::string& path) {
struct stat file_stat;
if (stat(path.c_str(), &file_stat) < 0) {
// 错误处理,这里为了简化直接返回 0
return 0;
}
return file_stat.st_dev;
}
// 将文件列表按物理设备 ID 分组
std::map<dev_t, std::vector<std::string>> group_files_by_device(const std::vector<std::string>& files) {
std::map<dev_t, std::vector<std::string>> device_files;
for (const auto& file_path : files) {
dev_t dev_id = get_device_id(file_path);
if (dev_id != 0) {
device_files[dev_id].push_back(file_path);
}
}
return device_files;
}
// 假设这是你的所有文件列表
std::vector<std::string> get_all_files(const std::string& root_path) {
std::vector<std::string> all_files;
for (const auto& entry : fs::recursive_directory_iterator(root_path)) {
if (entry.is_regular_file()) {
all_files.push_back(entry.path().string());
}
}
return all_files;
}
得到按设备分组的 device_files 映射表后,就可以为其中每一个键值对(即每一块SSD)启动一个独立的线程。
主线程的启动逻辑如下:
#include <thread>
#include <vector>
// 这是每个线程要执行的工作函数
void process_files_on_device(const std::vector<std::string>& files_to_read) {
// 在这里执行真正的文件读取逻辑
for(const auto& file : files_to_read) {
// std::cout << "Reading " << file << " on thread " << std::this_thread::get_id() << std::endl;
}
}
int main() {
// 假设你的文件都在 /data目录下,该目录聚合了多个ssd的挂载
std::string root_path = "/data";
auto all_files = get_all_files(root_path);
auto grouped_files = group_files_by_device(all_files);
std::vector<std::thread> threads;
for (const auto& pair : grouped_files) {
// pair.first 是设备ID, pair.second 是该设备上的文件列表
std::cout << "Found " << pair.second.size() << " files on device " << pair.first << std::endl;
threads.emplace_back(process_files_on_device, pair.second);
}
for (auto& t : threads) {
t.join();
}
std::cout << "All files processed." << std::endl;
return 0;
}
仅仅是实施这一步物理隔离,你的架构就从混乱无序的“群殴”,转变为有序的“分进合击”。性能提升两三倍,往往只是这套架构的保底收益。
二、内存映射(mmap):消除内核与用户态的数据拷贝
当每个线程都拿到了专属的文件列表后,下一步就是如何读得更快。
如果还在使用 fread 或 ifstream,数据流的路径是:磁盘 -> 内核缓冲区 -> 用户程序缓冲区。中间的CPU拷贝操作在数据量巨大时,开销相当可观。
这时就该使用内存映射(mmap)技术了。
mmap 的原理是让内核建立一段虚拟内存地址到文件内容的直接映射。当程序访问这段内存时,如果数据不在物理内存中,系统会触发缺页异常,由内核负责将对应的文件数据从磁盘直接加载到物理内存。整个过程避免了用户态和内核态之间的数据拷贝。
更进一步,我们可以使用 madvise 给内核一个提示,告知它我们的访问模式。例如,madvise(addr, length, MADV_SEQUENTIAL) 就是在告诉内核:“我将顺序读取这块文件映射的内存,请提前帮我预读后面的数据。”
现在,将 mmap 读取的逻辑封装起来,放进 process_files_on_device 函数中:
#include <fcntl.h>
#include <unistd.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <string>
#include <vector>
#include <stdexcept>
// 一个简单的mmap读取器
void read_with_mmap(const std::string& file_path) {
int fd = open(file_path.c_str(), O_RDONLY);
if (fd == -1) {
// 错误处理
return;
}
struct stat sb;
if (fstat(fd, &sb) == -1) {
close(fd);
return;
}
off_t file_size = sb.st_size;
if (file_size == 0) {
close(fd);
return;
}
char* mapped_mem = static_cast<char*>(mmap(NULL, file_size, PROT_READ, MAP_PRIVATE, fd, 0));
if (mapped_mem == MAP_FAILED) {
close(fd);
return;
}
close(fd); // 文件描述符可以立即关闭
// 告诉内核我们将顺序访问
madvise(mapped_mem, file_size, MADV_SEQUENTIAL);
// 在这里,你可以像访问普通内存一样访问文件内容
// process_data(mapped_mem, file_size);
// 模拟处理数据
// for(off_t i = 0; i < file_size; ++i) {
// char c = mapped_mem[i];
// }
// 使用完毕后,解除映射
munmap(mapped_mem, file_size);
}
void process_files_on_device(const std::vector<std::string>& files_to_read) {
for(const auto& file : files_to_read) {
read_with_mmap(file);
}
}
采用 mmap 后,程序在读取大文件时的CPU占用率会显著下降,因为繁重的数据搬运工作由内核接管了。对于大量中小型文件,它也能通过减少系统调用和内存拷贝次数来提升效率,是深入理解 Linux 系统内核机制后的有效实践。
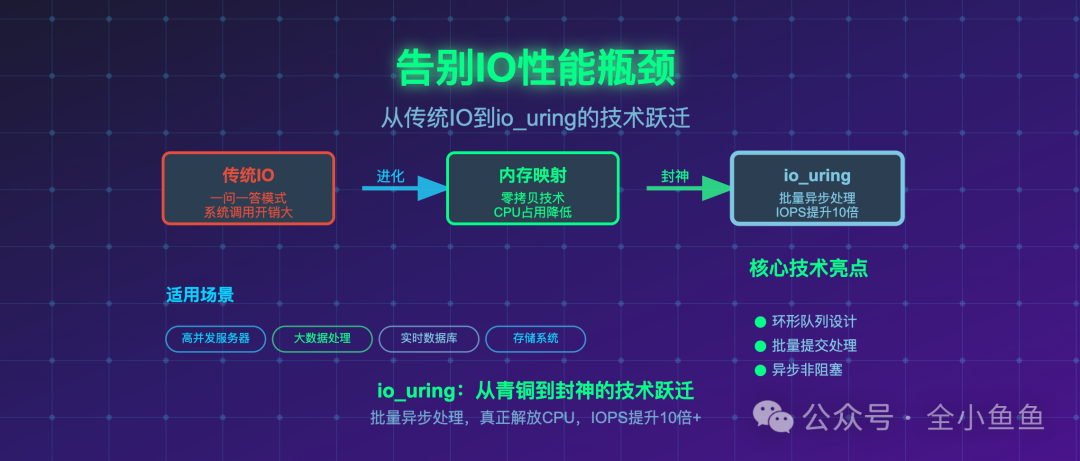
三、终极武器 io_uring:实现真正的异步I/O
如果说 mmap 将I/O性能带入了新境界,那么 io_uring 则是一次革命性的跃迁。这是Linux内核5.1版本之后引入的异步I/O接口,它彻底改变了应用与内核的交互模型。
传统的I/O,无论是同步阻塞还是像AIO那样的早期异步方案,本质上都是“一问一答”模式。每次提交I/O请求都需要一次系统调用或陷入内核态。当I/O每秒操作数(IOPS)需求达到数十万甚至上百万时,系统调用的开销就会累积为巨大的瓶颈。
io_uring 的核心思想是批量处理。它在用户态和内核态之间创建了两个共享的环形缓冲区:提交队列(SQ)和完成队列(CQ)。程序不再每次敲门,而是将一批I/O请求一次性放入SQ,然后通过一次系统调用通知内核。内核处理完后,将结果批量放入CQ,程序再去CQ里批量收取。这套机制极大地解放了CPU,使其能专注于数据处理,而I/O操作则由内核和硬件高效并行完成。
io_uring 的API相对底层,但威力巨大。下面是一个简化的示例,展示如何用它读取一个文件:
#include <liburing.h>
#include <fcntl.h>
#include <iostream>
#include <vector>
#include <string.h>
// io_uring需要较新的Linux内核和liburing库
void read_with_io_uring(const std::string& file_path) {
struct io_uring ring;
// 初始化io_uring实例,队列深度为8(假设有8快SSD)
if (io_uring_queue_init(8, &ring, 0) < 0) {
return;
}
int fd = open(file_path.c_str(), O_RDONLY);
if (fd < 0) {
io_uring_queue_exit(&ring);
return;
}
struct stat sb;
fstat(fd, &sb);
long file_size = sb.st_size;
std::vector<char> buffer(file_size);
struct io_uring_sqe * sqe = io_uring_get_sqe(&ring);
if (!sqe) {
close(fd);
io_uring_queue_exit(&ring);
return;
}
// 准备一个读请求
io_uring_prep_read(sqe, fd, buffer.data(), file_size, 0);
// 提交请求
io_uring_submit(&ring);
struct io_uring_cqe * cqe;
// 等待完成队列返回结果
int ret = io_uring_wait_cqe(&ring, &cqe);
if (ret < 0) {
// 等待失败
} else {
if (cqe->res < 0) {
// 读取操作失败
} else {
// 读取成功,cqe->res 是读取的字节数
// 数据已经在buffer里了
}
// 标记完成事件已处理
io_uring_cqe_seen(&ring, cqe);
}
close(fd);
io_uring_queue_exit(&ring);
}
io_uring 的真正威力在于批量提交。在一个线程内,你可以遍历分配给它的所有文件,为每个文件准备一个 io_uring_prep_read 请求,然后一次性调用 io_uring_submit 全部提交。接着,进入一个循环,不断从CQ中收取已完成的任务。这是一个典型的生产者-消费者模型,极大提升了多线程并发场景下的效率。
进阶优化:内存对齐与大页
当上述三步运用熟练,I/O速度飞起后,瓶颈可能会转移到内存访问上。追求极致性能,还可以在内存使用上再做优化:
- 内存对齐:使用
posix_memalign 申请内存,确保缓冲区按4K页面对齐。这对直接I/O(O_DIRECT)是硬性要求,对普通I/O也能提升性能。
- 使用大页(Huge Pages):如果条件允许,启用大页(如2MB或1GB)。这能大幅提升TLB缓存的命中率,减少地址翻译的开销,在处理海量数据时效果显著。
总结:终极流程四步走
- 分库:按SSD物理挂载点将文件分组。
- 锁线程:一个线程固定处理一块SSD上的所有文件。
- 上技术:在线程内部,使用
io_uring 批量提交异步请求,或使用 mmap 进行零拷贝读取。
- 省内存:提前准备大块、对齐的缓冲区供循环使用,避免在循环内频繁进行
new 或 malloc。
这套组合拳打完,性能瓶颈很可能就转移到你自身的数据处理逻辑上了。当然,如果面对的是几百万个KB级别的超小文件,那又是另一种截然不同的挑战了,需要完全不同的优化策略。
欢迎在 云栈社区 分享你在小文件处理或其他高性能场景下的实战经验与独特见解。
 发表于 2026-3-17 03:34:04
|
查看: 266|
回复: 0
发表于 2026-3-17 03:34:04
|
查看: 266|
回复: 0
