开源代码已放出:https://github.com/MoonshotAI/Kimi-K2.5
还在为你的AI Agent处理复杂任务时“慢如蜗牛”而头疼吗?传统的顺序思考模式,在面对需要广泛信息收集和深度推理的复杂场景时,效率瓶颈日益凸显。
今天,一个颠覆性的思路出现了:为什么不让一群Agent同时为你工作?
Kimi团队开源的K2.5模型,不仅实现了文本与视觉能力的深度融合,更提出了“Agent群”这一创新框架。它让一个主Agent像导演一样,动态分解任务,同时指挥多个子Agent并行工作。在测试中,该系统将广泛搜索任务的延迟降低至单Agent的1/4.5,关键性能指标(Item-F1)还从72.8%逆势提升至79.0%。
这不仅是一次速度的飞跃,更是对AI顺序执行范式的重构。接下来,我们将深入剖析“Agent群”如何实现智能的并行化编排,以及K2.5如何通过反直觉的“视觉强化文本”策略实现联合优化。
❓ 核心痛点:为什么顺序Agent走到了尽头?
我们早已习惯了AI Agent的工作模式:接收指令 → 思考 → 调用工具 → 观察结果 → 继续思考… 如此循环。
这套“顺序执行”范式在简单任务上尚可,但一旦面对需要广泛信息收集、多分支深度推理的复杂场景,瓶颈立刻显现:
- 延迟爆炸:步骤数线性增长,完成时间长得令人无法接受。
- 上下文臃肿:漫长的思考链和工具调用历史会塞满模型的上下文窗口,导致信息丢失或被迫截断。
- 能力天花板:单个Agent的“思维带宽”和“工具调用带宽”有限,难以驾驭超大规模、异构的子问题。
现有的优化方案,如“丢弃历史”等上下文管理技巧,本质上是被动、损失性的压缩,治标不治本。问题的根源在于架构——我们是否必须让一个“大脑”处理所有事情?
Kimi K2.5的答案是否定的。它通过“Agent群”与“文本-视觉联合优化”两大核心设计,从根本上规避了传统方案的缺陷。其核心技术架构如下图所示:
图:Kimi K2.5核心技术架构思维导图,清晰展示了“文本-视觉联合优化”与“Agent群”两大支柱及其协同关系
接下来,我们逐层拆解图中的关键模块,探究其实现智能“降本增效”的奥秘。
🧠 第一支柱:文本-视觉联合优化,何以实现“1+1>2”?
传统多模态模型常被诟病“偏科”:视觉能力上去了,文本能力就受损。K2.5却通过一套精妙的“联合优化”组合拳,让两种模态相互增强。
💡 反直觉的预训练策略:早期融合胜于后期猛补
多模态预训练有个经典难题:在固定的总计算预算下,何时、以多大比例混合视觉数据效果最好?
传统思路认为,应该先让大语言模型学好语言,后期再高比例注入视觉数据。但K2.5的实验结果颠覆了这一认知。
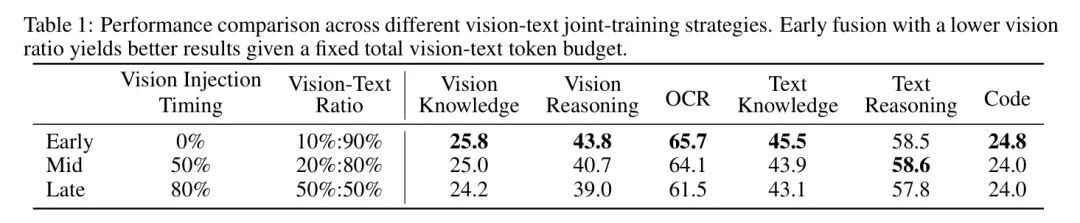
表:不同视觉比例和融合时机下的性能对比,早期低比例融合表现更优
核心发现:在总Token数固定的前提下,视觉比例对最终性能影响极小,但融合时机至关重要。早期就以恒定、适中的比例混合视觉数据,让模型从一开始就学习跨模态表征,效果远好于后期“恶补”。
这就好比学一门外语,从婴儿时期就沉浸在双语环境(早期融合),远比成年后再报突击班(后期融合)更自然、更扎实。K2.5采用的正是这种“原生多模态预训练”策略。
💡 零视觉SFT:用纯文本数据激活视觉能力
预训练后的模型还不会基于视觉使用工具。通常需要人工标注大量“看图说话”的指令数据来微调,成本高、多样性差。
K2.5提出了一个巧妙的“零视觉监督微调”方法:仅使用纯文本的指令数据进行微调。在这个阶段,所有对图像的操作(如“裁剪”、“识别图中文字”)都被描述为IPython中的编程操作。
神奇的是,经过这种纯文本“培训”后,模型竟然能泛化到真实的视觉任务上,如物体定位、计数和OCR。这说明联合预训练已经建立了极强的跨模态对齐,语言指令能直接“唤醒”视觉推理能力。
💡 视觉强化学习,竟能反哺文本性能?
在零视觉监督微调之后,模型还需要通过强化学习来优化其视觉推理的可靠性和精确性。通常,大家会担心专门优化视觉任务会损害文本能力。
但K2.5带来了第二个反直觉的发现:基于结果的视觉强化学习,竟然显著提升了纯文本基准测试的成绩!

表:视觉强化学习后,MMLU-Pro、GPQA-Diamond等纯文本基准测试性能均得到提升
如上表所示,在视觉强化学习之后,MMLU-Pro从84.7%提升至86.4%,GPQA-Diamond从84.3%提升至86.4%。视觉训练让模型在需要结构化信息提取和精确推理的文本任务上,变得更加“严谨”和“校准”。
这彻底打破了“模态冲突”的魔咒,证明了深度联合优化下,模态间可以实现真正的能力迁移和增强。基于此,K2.5最终采用了联合多模态强化学习,让模型在不同能力的维度上共同进化。
这个“视觉强化文本”的发现,或许意味着在未来多模态模型的训练中,视觉数据将成为提升通用推理能力的“催化剂”。
🚀 第二支柱:Agent群——从“流水线工人”到“导演与剧组”
如果说联合优化是“修炼内功”,那么Agent群就是“革新生产关系”的外功。它让AI从“单线程思考”跃迁至“并行化协作”。
💡 核心架构:解耦的编排器与冻结的子Agent
Agent群的核心是一个可训练的协调器(导演) 和多个从固定预训练权重实例化的、冻结的子Agent(演员)。
为什么要“冻结”子Agent?这是为了规避多智能体强化学习中两大顽疾:信用分配模糊(最终结果好,不代表每个子步骤都完美)和训练不稳定。
通过解耦,协调器只学习高层任务分解与调度策略,将子Agent的输出视为环境反馈。这大大降低了学习难度,实现了稳定收敛。训练时,先用小尺寸子Agent快速训练协调器,再切换到大模型,极大提升了训练效率。
💡 三重奖励设计:防躺平、防作弊、保效果
训练一个聪明的“导演”绝非易事。K2.5为并行Agent强化学习设计了精妙的PARL奖励函数:
- 性能奖励 (R_perf):评估最终解决方案的质量,这是核心目标。
- 并行奖励 (R_para):专门激励协调器去创建子Agent,防止它偷懒,永远只用一个Agent干活(局部最优的“串行崩溃”)。
- 完成奖励 (R_done):奖励成功完成的子任务,防止协调器为了刷“并行指标”而疯狂创建大量不做实事的子Agent(“虚假并行”)。
超参数 λ_para 和 λ_done 会在训练中逐渐衰减至零,确保模型最终专注于核心任务性能。
💡 关键步骤:衡量真正的时间成本
在并行世界中,步骤总数不再等于耗时。K2.5引入了“关键步骤”这一核心指标,它类比于计算图中的关键路径:关键步骤数 = 阶段1最慢子Agent耗时 + 阶段2最慢子Agent耗时 + ...
这个公式意味着,一个阶段的耗时取决于该阶段内最慢的那个子Agent。协调器会被引导去均衡各个子任务的工作量,以缩短关键路径,而不是盲目增加并发数。这才是真正优化端到端延迟的智能调度。
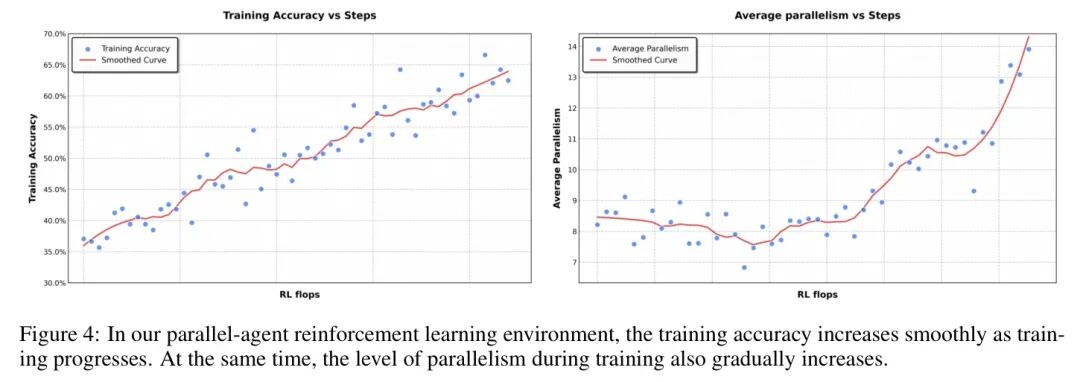
图:PARL训练过程中,累积奖励平稳上升,协调器成功学会了有效的并行化策略
📊 实验验证:数据不说谎,群殴就是强
理论再美,还需实战检验。K2.5在涵盖推理、编码、视觉、Agent任务等数十个权威基准测试中进行了全面评估。
🏆 全能战士:各项指标全面领先
在需要深度推理的数学竞赛、知识问答、复杂编码、长视频理解乃至真实的计算机使用任务中,K2.5均达到了与顶级闭源模型媲美甚至超越的水平。
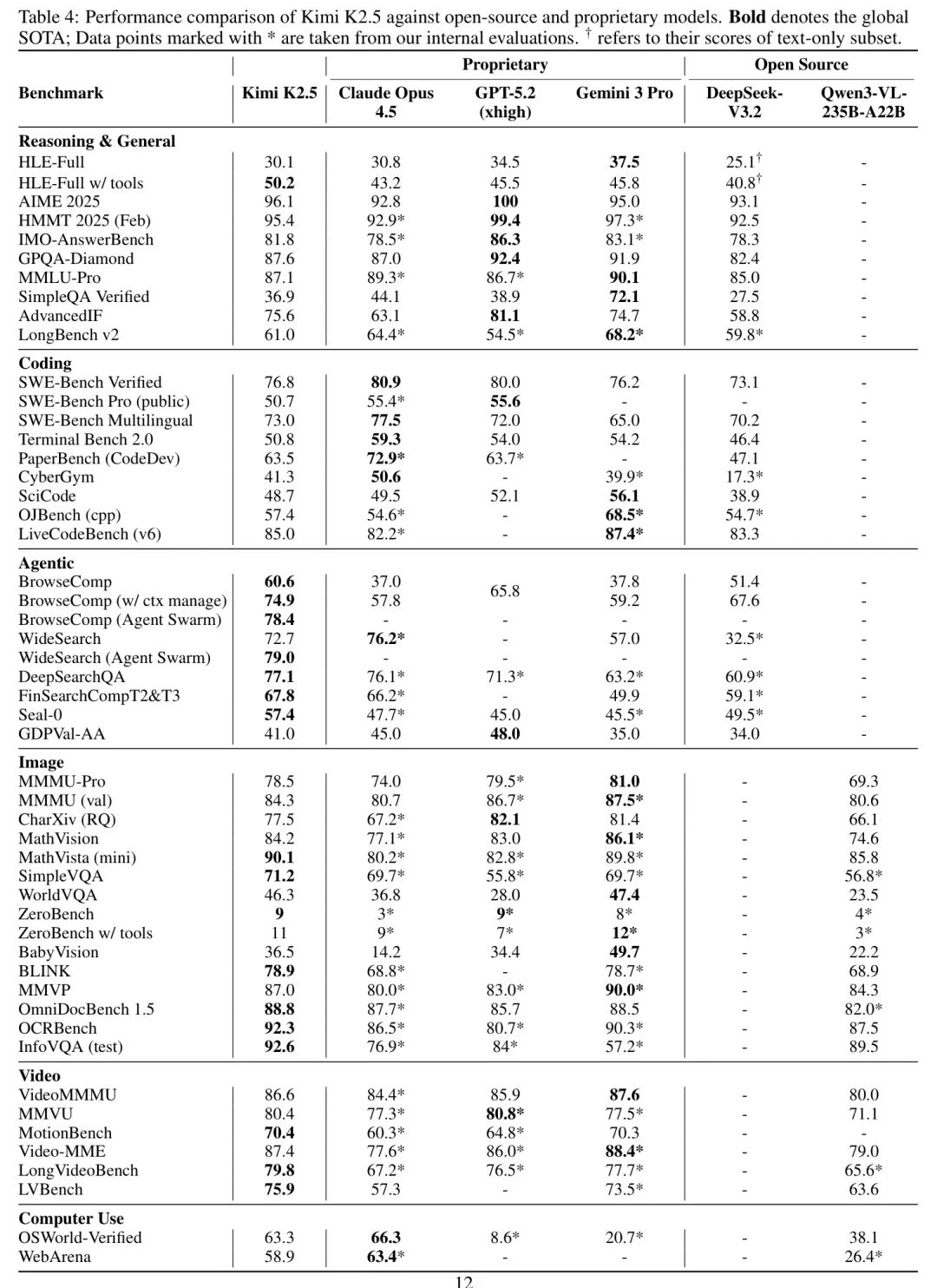
表:Kimi K2.5在多项基准测试中与顶尖专有及开源模型的对比结果,表现全面领先
尤其值得称道的是其自主Agent能力。在需要多步搜索、信息综合的BrowseComp任务中,单Agent K2.5准确率已达60.6%,而启用Agent群后,准确率提升至78.4%,显著超过了其他模型。
🔬 Agent群的威力:又快又好
Agent群的终极价值,在于其“降本增效”的能力。在WideSearch基准测试中,效果展现得淋漓尽致。
性能提升:Item-F1分数从单Agent的72.7%提升至79.0%,绝对提升达6.3%。
延迟骤降:如下图所示,随着任务目标难度(Item-F1值)从30%提升到70%,单Agent的耗时呈线性急剧增长。而Agent群始终保持低延迟,最高将延迟降低至单Agent的1/4.5!
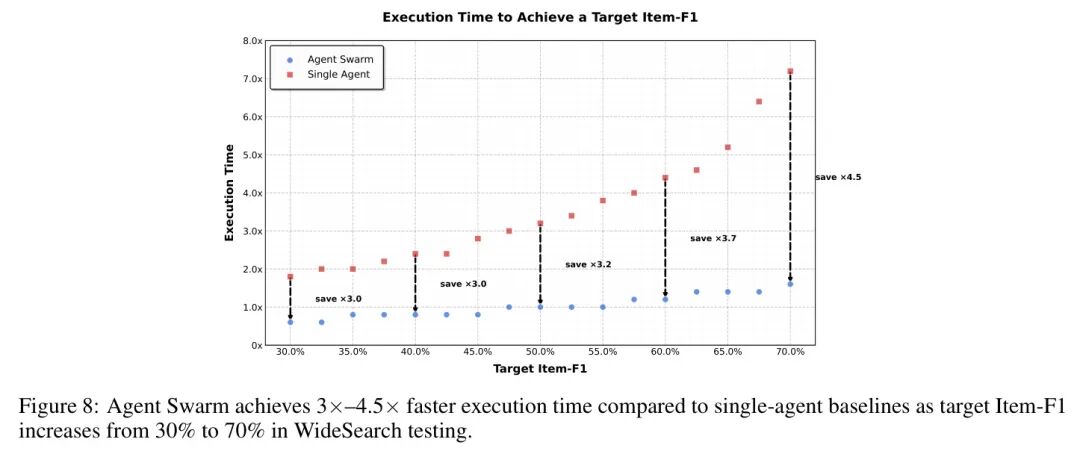
图:在WideSearch任务中,Agent群(蓝线)相比单Agent(红线)能大幅降低达到相同性能目标所需的执行时间
🔬 动态与主动:智能的体现
Agent群的智能还体现在其动态性和主动性上。

图:协调器在任务执行过程中动态创建异构的子Agent组,进行并行调度
如上图所示,协调器并非预先设定好固定数量的子Agent,而是根据任务进展动态实例化不同类型、不同数量的专家Agent,实现真正的自适应分解。
更重要的是,Agent群本身就是一种主动的上下文管理策略。它通过将长任务分解为独立的子任务,让每个子Agent在有限的局部上下文中工作,只将关键结果汇报给协调器。这避免了全局上下文的无限膨胀,实现了“上下文分片”,相比被动“丢弃历史”的方法,在效率和准确性上都有显著优势。
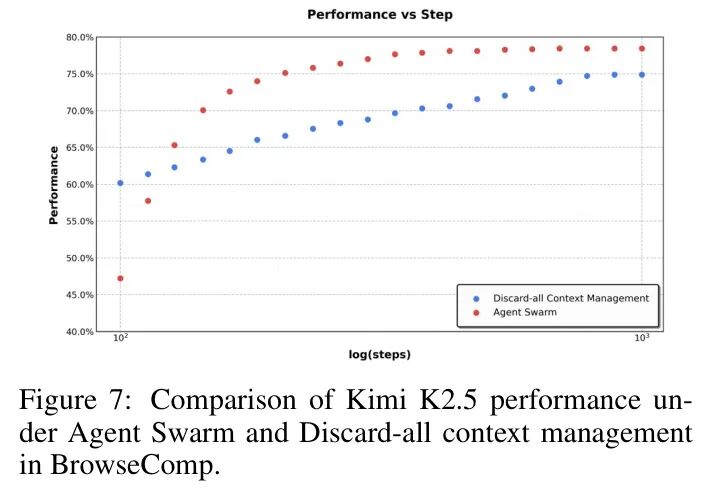
图:在BrowseComp任务中,Agent群(主动上下文管理)在准确率和效率上均优于“全部丢弃”的被动策略
⚖️ 客观评价
毫无疑问,Kimi K2.5及其“Agent群”框架是Agent进化路径上的一次里程碑式突破。它不仅在工程上实现了高效的并行训练与推理,更在理念上为处理超复杂任务提供了可扩展的架构蓝图。
局限性:
- 协调器训练成本:虽然冻结子Agent降低了难度,但训练一个高效的协调器本身仍需大量的强化学习交互,成本不菲。
- 子Agent通信开销:在极度细粒度的任务分解下,子Agent间的结果同步与协调器决策可能带来额外的通信与计算开销,需要精细权衡。
- 任务普适性:目前展示的优势主要集中在信息检索、研究类任务上,对于强时序依赖、步骤间耦合极紧的任务,并行化的收益可能有限。
🌟 价值升华与行动号召
总结来看,Kimi K2.5带来了三重启示:
- 架构革新:智能的瓶颈可能不在“脑容量”,而在“工作模式”。从“顺序执行”到“并行编排”的范式转变,打开了性能与效率的新空间。
- 模态共生:“文本-视觉联合优化”证明,深度对齐的多模态训练可以实现真正的相互增强,而非此消彼长的权衡。
- 开源引领:将如此强大的模型权重在GitHub开源,极大地降低了社区研究和应用前沿Agent技术的门槛,将加速整个领域的发展。
Kimi K2.5的“Agent群”框架,向我们展示了未来智能系统协作与并行化的清晰蓝图。你认为这项技术最可能率先颠覆哪个应用场景?是自动化科研、超级个人助理,还是复杂的软件工程项目管理?欢迎在技术社区分享你的见解。
参考
KIMI K2.5: VISUAL AGENTIC INTELLIGENCE
 发表于 2026-3-17 03:37:28
|
查看: 338|
回复: 0
发表于 2026-3-17 03:37:28
|
查看: 338|
回复: 0
