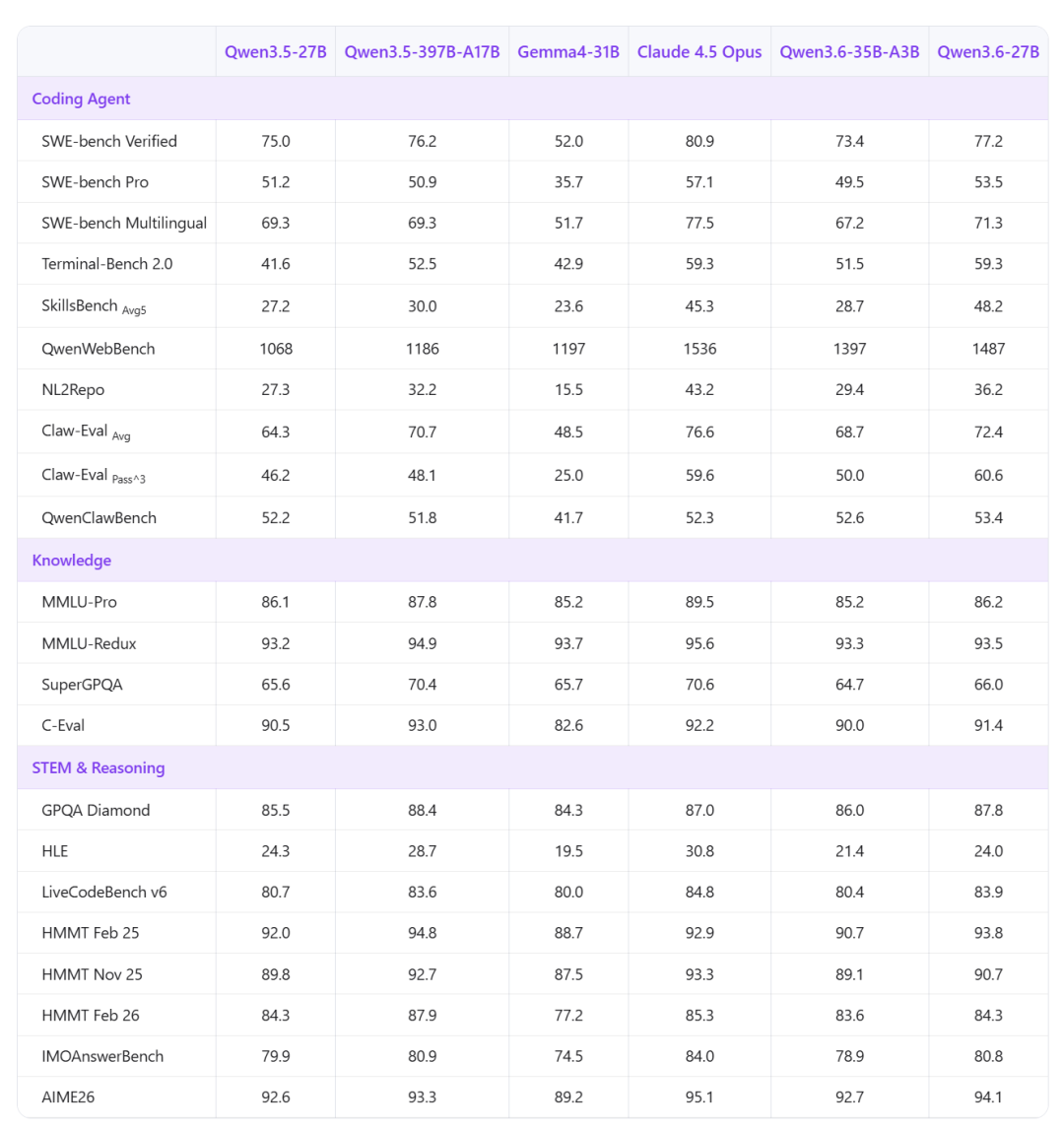
阿里通义千问团队于4月23日发布并开源了Qwen3.6-27B——一款270亿参数的稠密多模态模型,支持思考与非思考模式。与上一代旗舰Qwen3.5-397B-A17B相比,Qwen3.6-27B以仅1/15的参数规模,在多项编程基准上实现了反超,并展现出较强的文本和多模态推理能力。
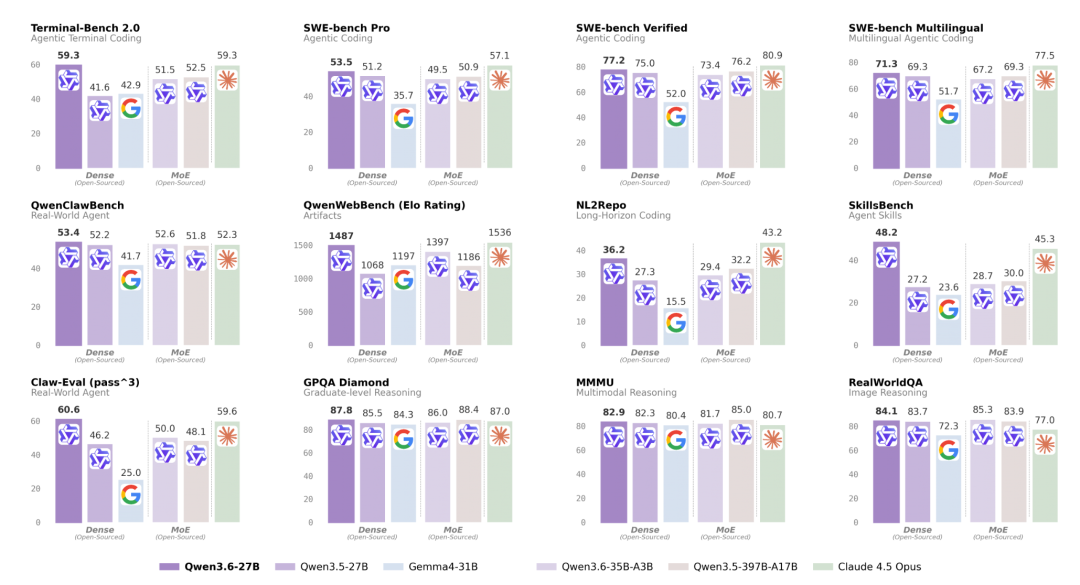
在SWE-bench Verified、SWE-bench Pro、Terminal-Bench 2.0以及SkillsBench等测试中,Qwen3.6-27B大幅领先同尺寸的Gemma 4-31B模型。随着Qwen3.6-27B的加入,阿里宣布Qwen3.6系列已完整发布,涵盖开源模型Qwen3.6-35B-A3B和闭源模型Qwen3.6-Plus、Qwen3.6-Max-Preview。
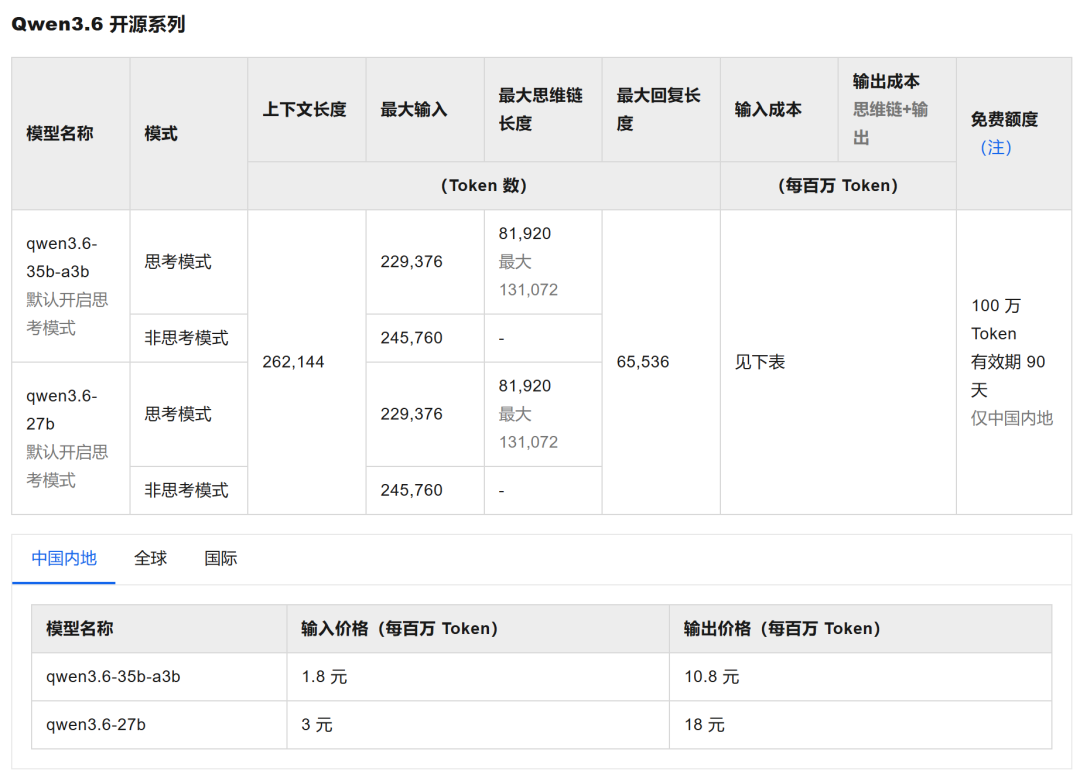
价格方面,阿里云百炼平台显示Qwen3.6-27B每百万Token输入价格3元,输出价格18元。由于是稠密模型,成本不算低。该模型已在Qwen Chat、Hugging Face和ModelScope开源,将接入OpenClaw、Claude Code等主流编程助手。体验地址和开源地址如下:
- 体验:
https://chat.qwen.ai/
- 开源:
https://huggingface.co/Qwen/Qwen3.6-27B , https://modelscope.cn/models/Qwen/Qwen3.6-27B
编程能力实测:跑酷游戏、记账应用与新闻站
官方数据显示,Qwen3.6-27B在编程基准上全面超越Qwen3.5-397B-A17B:SWE-bench Verified 77.2 vs 76.2、SWE-bench Pro 53.5 vs 50.9、Terminal-Bench 2.0 59.3 vs 52.5、SkillsBench 48.2 vs 30.0。推理能力上,GPQA Diamond得分为87.8(略低于397B的88.4)。
为了直观感受,我们首先让其制作一个包含多层复杂需求的横版跑酷游戏。提示词要求实现跳跃/二段跳/下滑、自动滚动地图、多种障碍物与可拾取道具、敌人AI、HP与分数UI等,全部写在一个HTML文件。
模型耗时约四分钟,输出超过1200行代码。实际运行后,游戏核心要素基本到位:二段跳、障碍物(无人机、针刺)、能量电池、金币、磁铁吸附等均有效果,血量、分数、距离显示正常,低多边形霓虹风美术也符合设定。
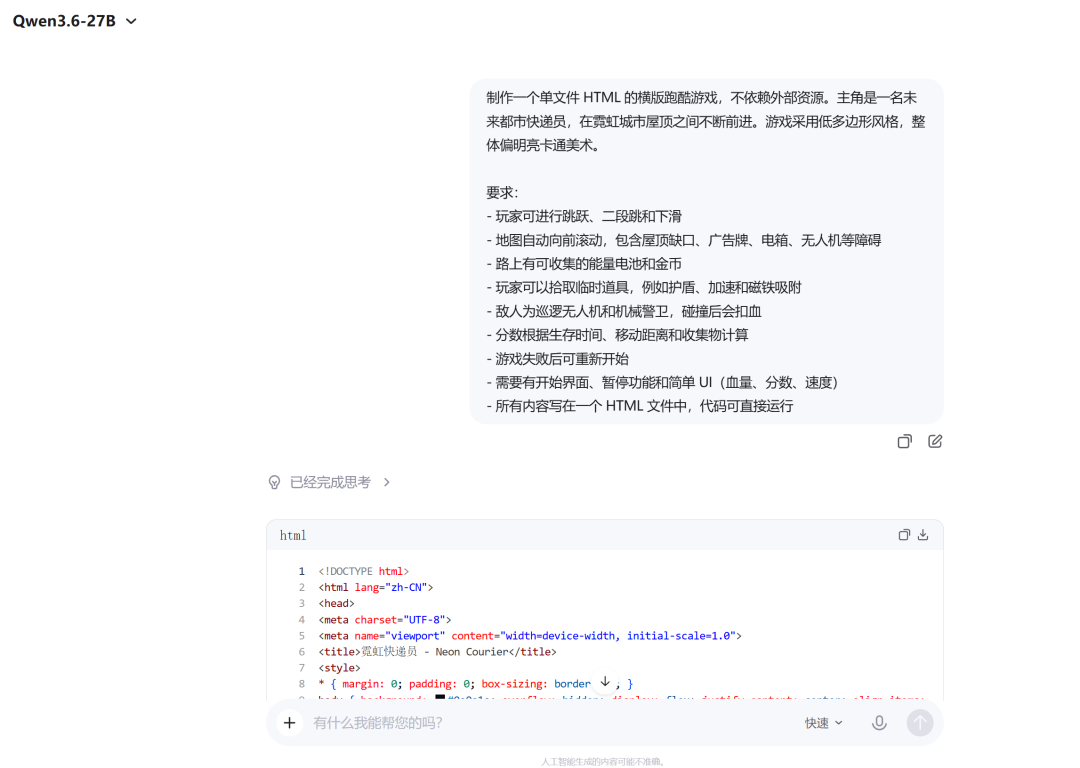

细微不足在于:有些针刺悬浮在空中,拾取电池后缺少能量条反馈,撞到障碍物未扣血——但这些属于细节调整范畴,整体可玩性已相当高。
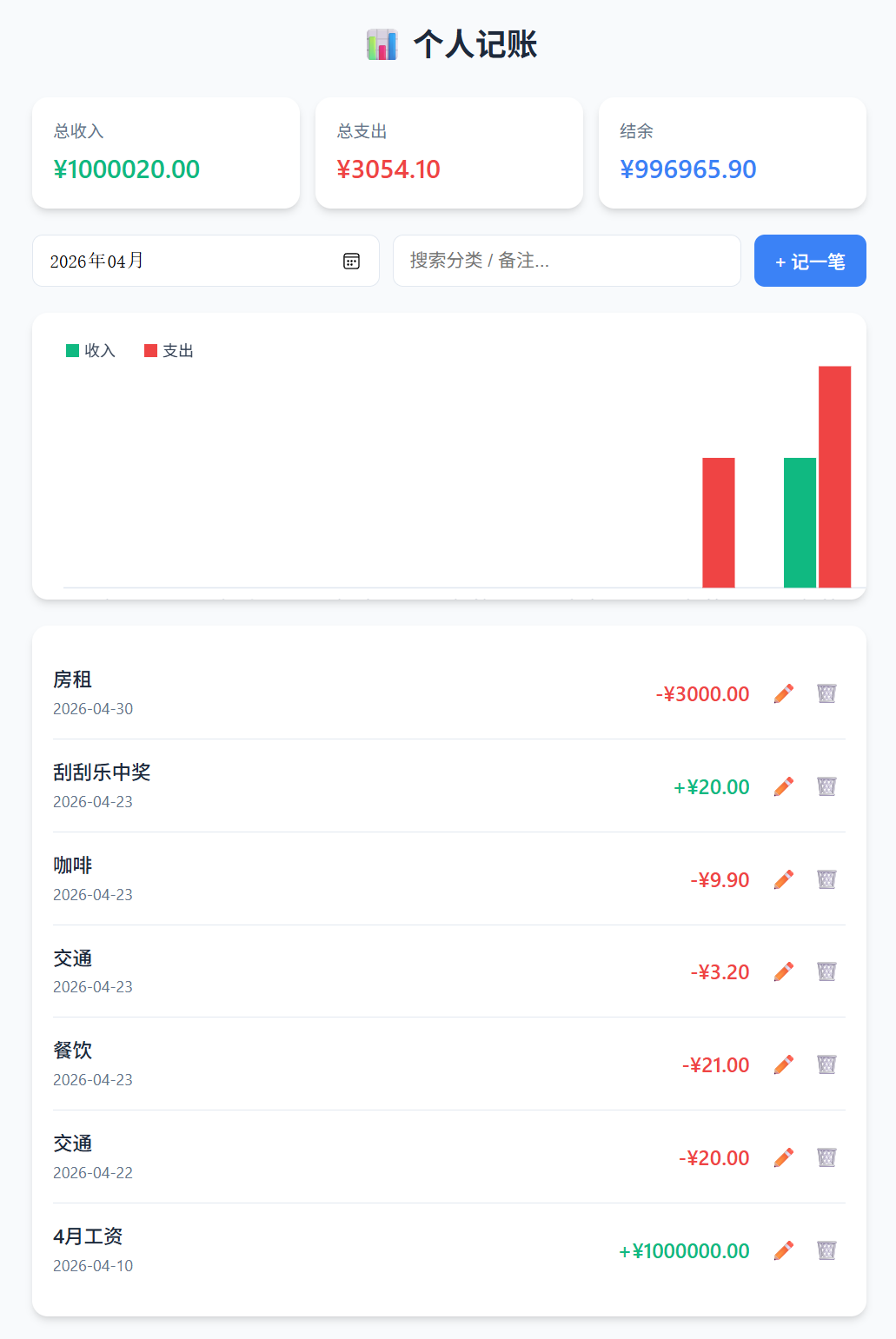
接着,我们让模型开发一个个人记账应用,以考察其对业务逻辑、数据持久化和异常输入的理解。生成的应用支持记录的增删改查、按月筛选、总收入/支出/结余统计以及近7天收支趋势图表;数据通过 localStorage 存储,刷新不丢失。唯一瑕疵是刷新后7日柱状图曾瞬间消失,再记一笔后恢复——属于异步渲染时机的小问题。
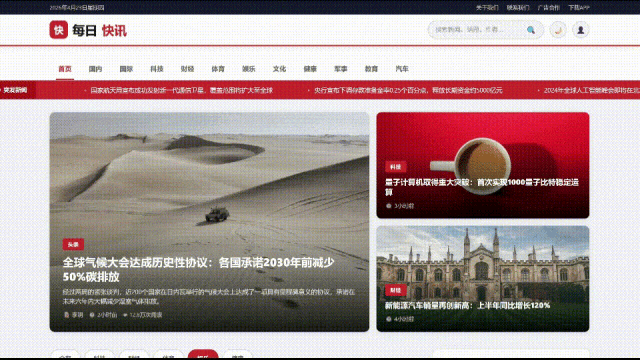
最后的新闻网站前端设计任务中,模型自动规划了科技、财经、体育、娱乐、健康五大板块,包含国内外新闻、热门排行、标签云,甚至预留广告位并展示北京天气,界面布局合理、信息完整。说明它对“一个完整的新闻站点”有成熟的前端认知。
多模态测试:验证码识别与找不同
作为原生多模态模型,Qwen3.6-27B支持视觉语言思考/非思考模式,覆盖视觉推理、文档理解等场景,能力与上一代旗舰相当。
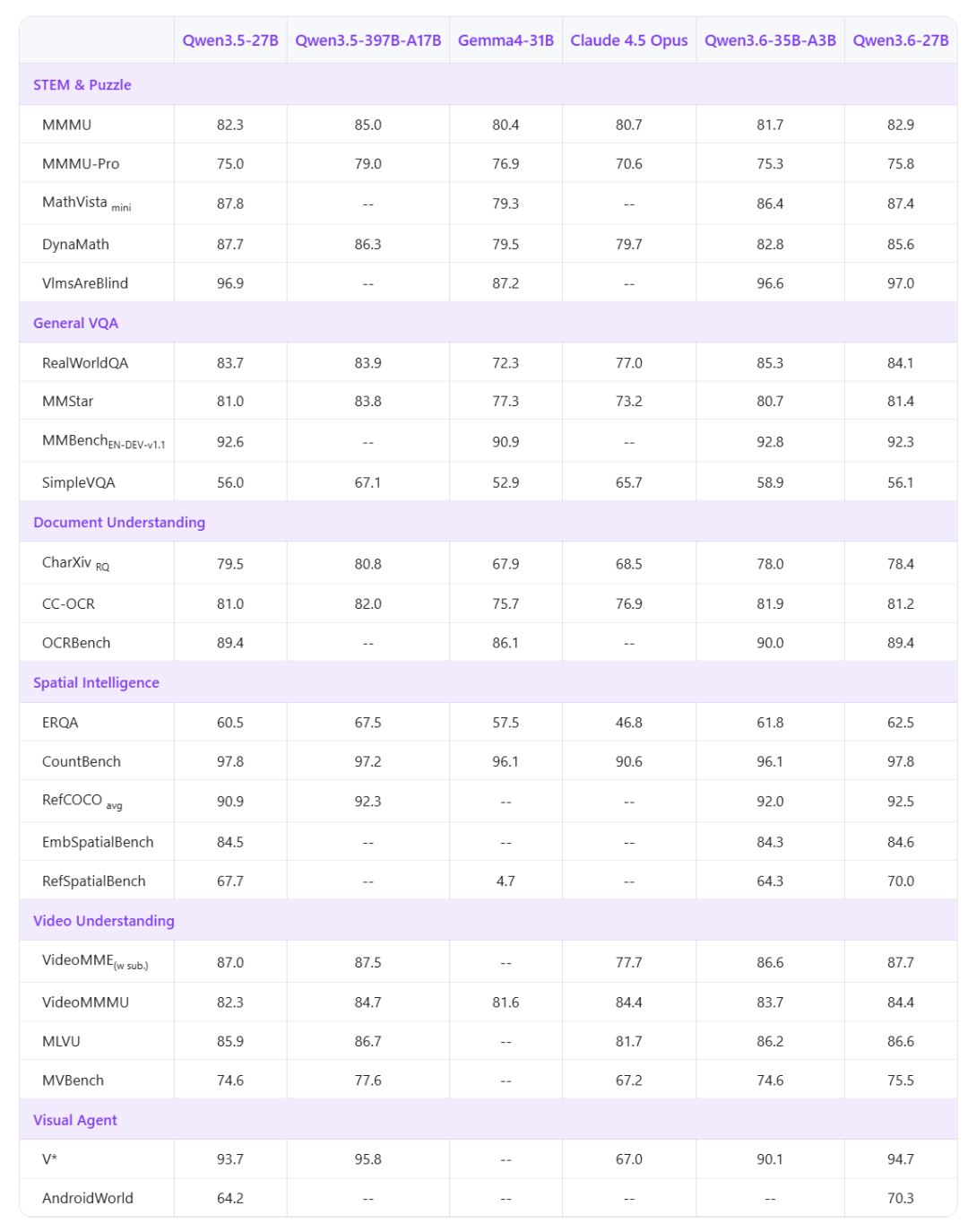
我们先用一组模糊验证码考验其识别能力。它准确给出了绝大多数字符,只在第八个(0AIs)上将末尾的“s”误判为“6”,但同时在输出中标注了不确定项——这种带置信度的反馈对自动化校验流程更为友好。

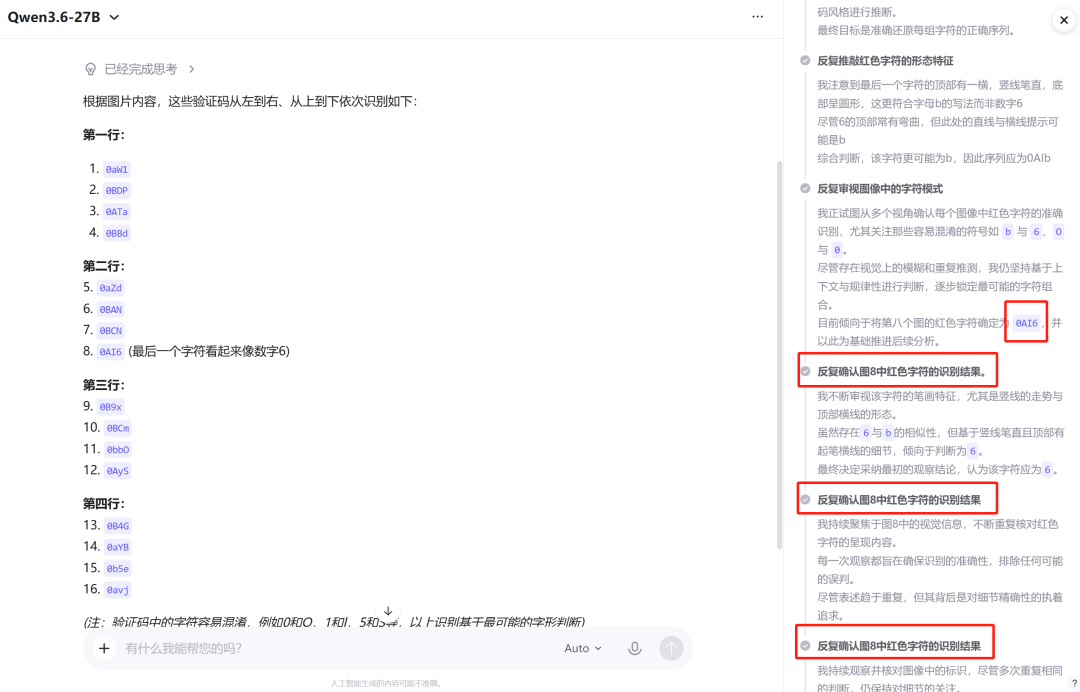
翻看思考链,模型对第八个字符在“b”和“6”之间反复纠结,而正确答案“s”从未进入候选集,表明面对极相似字符仍会出现“越想越错”的倾向,后续仍需人工复核。
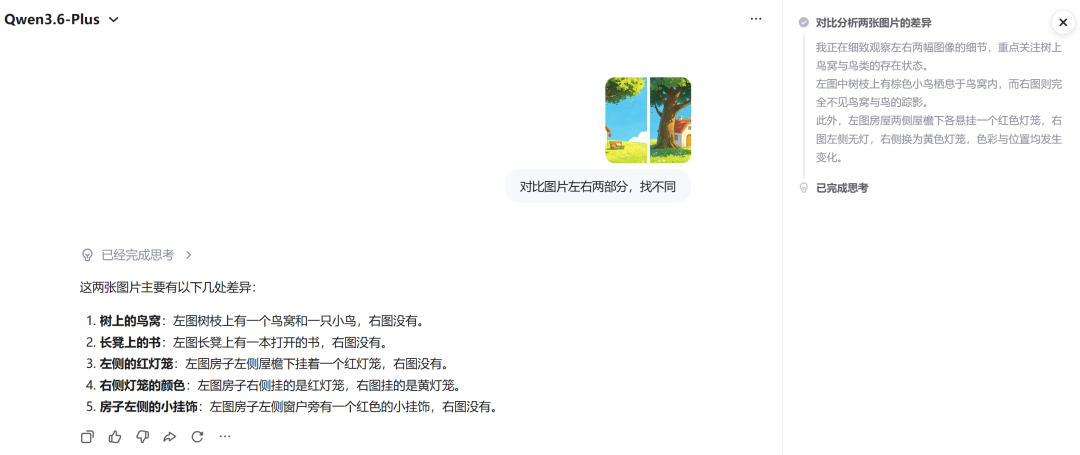
随后,我们让模型找两幅卡通插画的差异。它快速识别出五处不同——鸟窝、书、灯笼位置与颜色、挂饰——连墙上的小挂件都没漏掉,思考过程简洁、描述清晰,展现了较强的视觉分析能力。

结语:聚焦开发者核心需求的开源模型
Qwen3.6系列不再追求超大参数全线开源,而是精准推出27B稠密和MoE小尺寸模型,折射出阿里开源策略的聚焦。这类模型直指开发者、研究者及小团队的需求——本地部署、二次微调、灵活可控。开源社区对于27B这样“正好够用”的尺寸反馈热烈,而Qwen3.6-27B在编程与多模态上的表现,使其成为个人项目或小型应用的强力基座。
想要获取更多AI模型评测、部署经验或参与到开发者交流中,欢迎访问云栈社区。
 发表于 2026-4-25 07:11:10
|
查看: 187|
回复: 0
发表于 2026-4-25 07:11:10
|
查看: 187|
回复: 0
