美团最新开源的LongCat-Next模型,通过纯离散逻辑,成功统一处理图像、音频和文本,将多模态任务拉回到最成熟的下一词预测轨道。这背后是名为离散原生自回归(DiNA)的架构革新,它让一个激活参数仅3B的基座模型,展现出了跨级别的图音理解与生成能力。
所有的物理世界信号,最终都能收敛为同源的离散 token 吗?长期以来,视觉信号的连续性被视为自回归建模中一个难以处理的特性。为了兼容这种不规则的特征,目前的通用做法是在模型中引入复杂的空间编码或异构模块。这种架构上的妥协虽然见效快,但也让模型的逻辑统一性变得模糊。
美团 LongCat 团队开源的 LongCat-Next,选择回归最朴素的下一通证预测(NTP)范式。在它看来,无论是复杂的代码、高清的图片,还是带有环境底噪的录音,本质上并无二致。这种名为离散原生自回归(DiNA)的架构,在底层实现了全模态的建模统一。
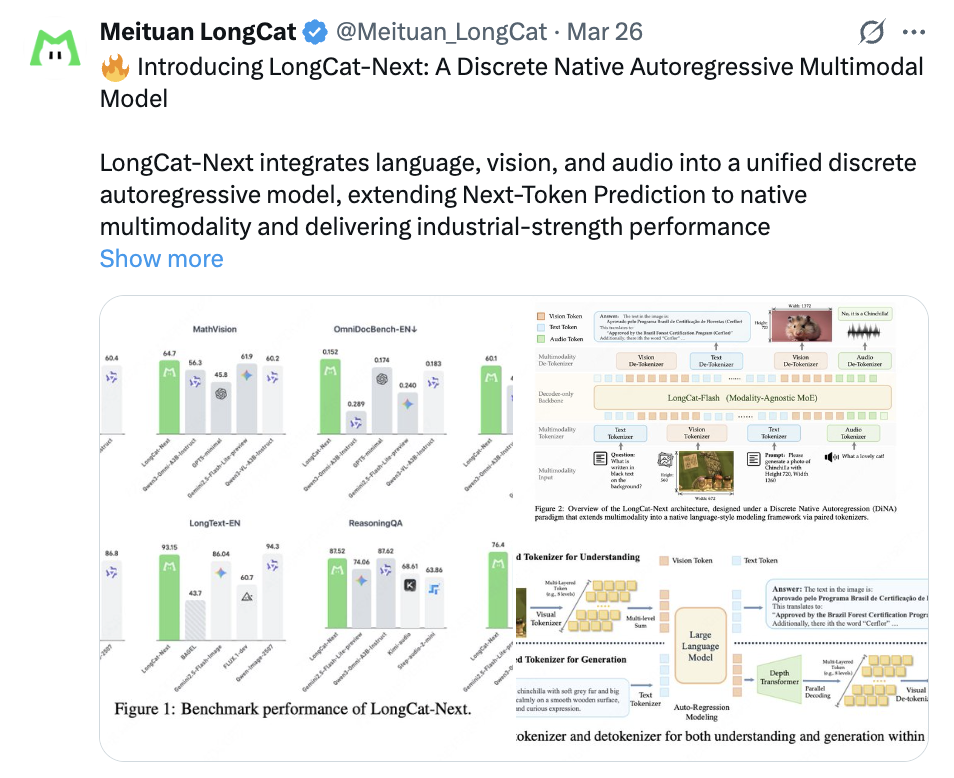
LongCat-Next 构建在美团自研的 LongCat-Flash-Lite MoE 基座之上,激活参数只有 3B。在这个规模下,它表现出了出色的效率。在重点考察文档解析与图表理解能力的 OmniDocBench-EN 和 CharXivRQ 榜单上,它的成绩全面超越了同尺寸的全模态模型 Qwen3-Omni-A3B。不仅如此,其视觉理解能力也与同尺寸的专业模型 QwenVL 相当。
在获得多模态能力的同时,LongCat-Next 成功克服了灾难性遗忘这一痛点,保留了语言模型原本的逻辑深度。它的 SWE-Bench 成绩稳在 43.0,这意味着它在实际的代码工程任务中依然保持着极高的可用性。
美团同时公布了 LongCat-Next 的详细技术报告,代码、模型权重均已开源,为社区研究和应用提供了完整资源。

技术报告地址:https://github.com/meituan-longcat/LongCat-Next/blob/main/tech_report.pdf
GitHub地址:https://github.com/meituan-longcat/LongCat-Next
HuggingFace地址:https://huggingface.co/meituan-longcat/LongCat-Next
Demo体验:https://longcat.chat/longcat-next
一套自回归逻辑处理所有信号
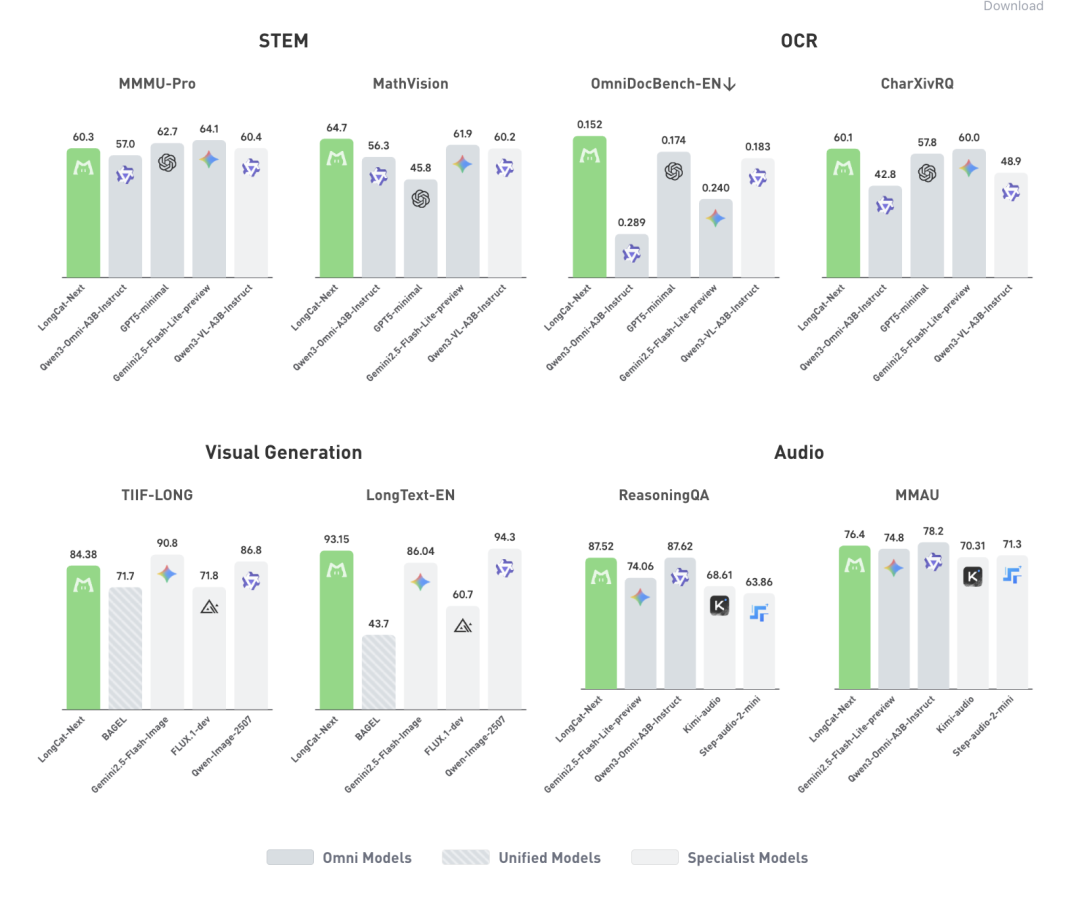
要把物理世界的信号塞进同一个自回归框架,首要解决的是不同模态的表征统一。在 LongCat-Next 的设定中,语言的离散建模已经具备成熟的生态。既然语音可以看作是语言的声态学表示,它同样顺理成章地在离散建模上取得了成功。
真正的挑战在于视觉。为了让图像也能像文本和语音一样被处理,LongCat-Next 将连续的视觉信号全部转化为了同源的离散 token。
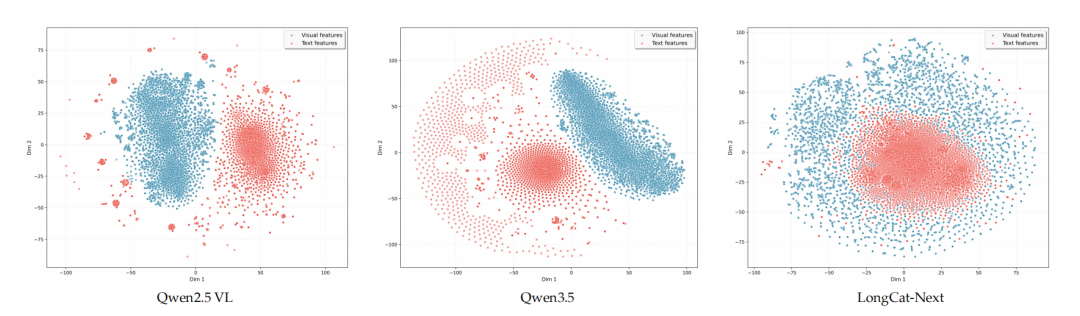
这种模态间的统一在 T-SNE 可视化分析中表现得非常直观,不同模态的表征在空间中高度交织、对齐。
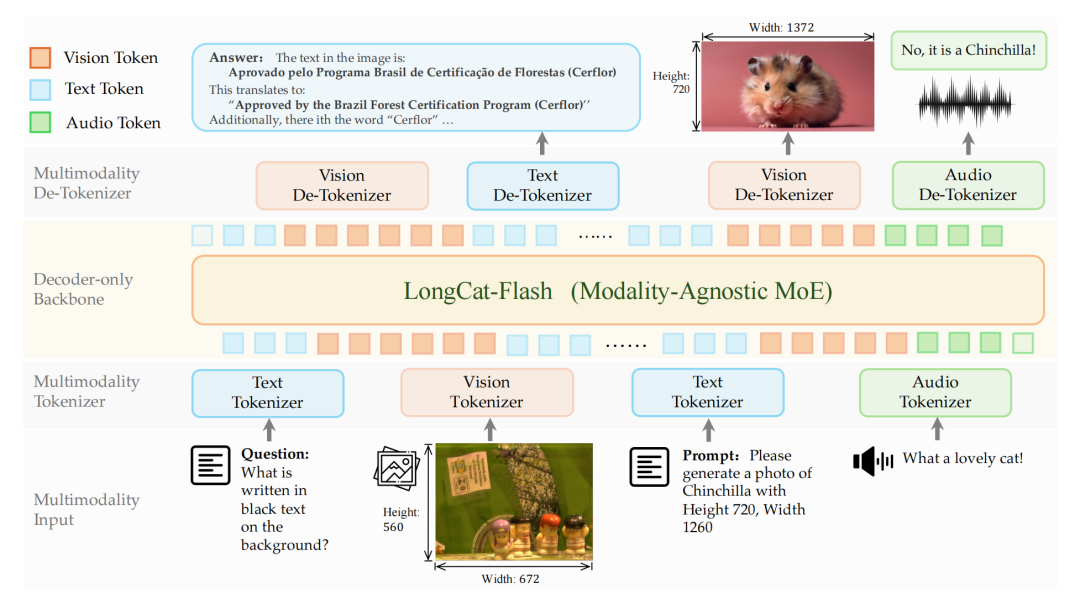
这种天然的融合,让模型无需引入 3D-RoPE 或双向注意力等复杂的额外设计,就能在同一套逻辑里实现“听”、“说”、“看”、“画”的自然涌现。
像处理文字一样给图像分词
解决视觉信号离散化的核心,是 LongCat-Next 首创的离散原生任意分辨率视觉 Transformer(dNaViT)。它提供了一个极其灵活的统一视觉接口,真正让图像拥有了像语言一样的“分词与解词”能力。它能够将视觉特征提取为视觉词汇,并转化为层次化的离散 token。
这套机制支持任意分辨率的输入,使得模型在处理复杂图表推理等对长宽比和微小细节敏感的任务时,具备极强的降维打击优势。
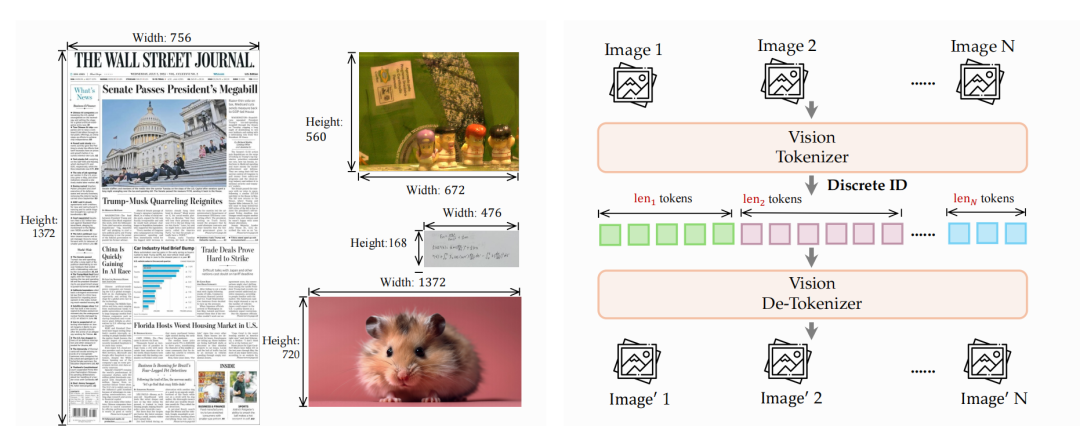
为了在压缩过程中锁住信息,dNaViT 引入了残差向量量化(RVQ)机制。它通过下一层码本递归拟合上一层的残差,在单步自回归内构建出庞大的表征空间,最终达成 28 倍的高效压缩。
在架构设计上,前端的视觉分词与后端的生成解码被严格解耦。多层离散 token 在进入大模型时仅作简单的相加融合;而在生成阶段,LongCat-Next 则独立引入了 Depth Transformer 作为多模态预测头。这种设计不增加前端编码负担,巧妙实现了多级 token 的高效并行解码。
此外,为了有效避免离散化过程带来的高层语义流失,LongCat-Next 引入了语义对齐完备编码器(SAE)。通过全局对齐与多任务密集学习,模型生成的离散 token 具备了内在的信息恢复属性。
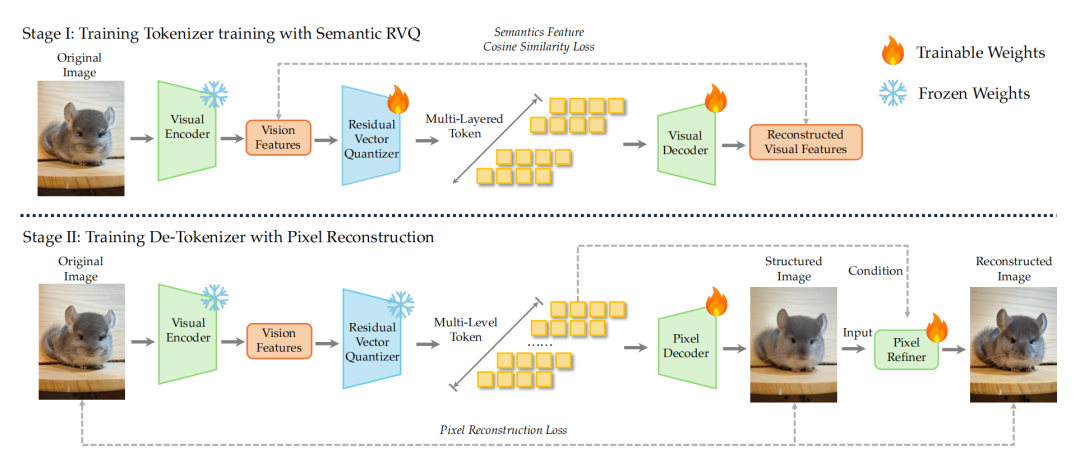
解耦双轨架构下的高保真还原
在生成阶段,单纯依靠冻结的 SAE 编码器难以捕捉高频的视觉细节。因此,LongCat-Next 设计了独特的解耦的双轨生成解码器 (Dual-Path Detokenization)。
第一轨是基于 ViT 的结构像素解码器,负责生成低分辨率锚点图以保全全局排版,从而极大降低生成方差。第二轨则是扩散像素细化器(Diffusion Refiner),专门负责向画面中注入和还原超高频的微小细节,确保图像实现高保真重建。
在测试中,面对包含高阶连加和分式嵌套的复杂结构,在 Diffusion Refiner 模块的介入下,模型依然能够做到字迹清晰、结构准确的完美复刻。

此外,由于这些离散 token 天生编码了图像的排版与结构化元素,LongCat-Next 从底层逻辑上规避了图文生成中常见的文字错乱问题,在极限 OCR 任务中展现出了优异的文本还原度。
能力实测
在 LongCat-Next 开源后,我们进行了一系列实测。首先是一张包含更正记录的超市小票,测试它的信息提取与逻辑核对能力。

LongCat-Next 避开了商品名中“100g*3”这类数字的干扰,直接输出了结构化的 JSON 数据。
{
"store_info": {
"name": "华润万家便利超市",
"store_number": "205383",
"machine_number": "V001",
"serial_number": "354",
"cashier_id": "1337",
"date": "2019-12-13"
},
"items": [
{
"item_name": "(削)卡士鲜酪乳(草莓三连杯)100g*3",
"item_code": "2905169890005",
"quantity": 1.000,
"unit_price": 9.00,
"amount": 9.00
},
{
"item_name": "219小热狗面包4个",
"item_code": "6972244650362",
"quantity": 1.000,
"unit_price": 8.99,
"amount": 8.99
},
{
"item_name": "晨光老街酸奶160g",
"item_code": "6924686502921",
"quantity": 1.000,
"unit_price": 8.99,
"amount": 8.99
},
{
"item_name": "晨光老街酸奶160g",
"item_code": "6924686502921",
"quantity": 1.000,
"unit_price": 8.99,
"amount": 8.99
},
{
"item_name": "单品折扣 50.00%",
"item_code": "",
"quantity": "",
"unit_price": "",
"amount": -9.00
},
{
"item_name": "[更正]219小热狗面包4个",
"item_code": "6972244650362",
"quantity": -1.000,
"unit_price": 8.99,
"amount": -8.99
},
{
"item_name": "219小热狗面包4个",
"item_code": "6972244650362",
"quantity": 1.000,
"unit_price": 8.99,
"amount": 8.99
},
{
"item_name": "单品折扣 50.00%",
"item_code": "",
"quantity": "",
"unit_price": "",
"amount": -4.50
},
{
"item_name": "0.20",
"item_code": "",
"quantity": "",
"unit_price": 0.20,
"amount": 0.20
}
],
"payment_info": {
"payment_method": "微信支付",
"transaction_amount": 22.67,
"account_number": "o5DBmwtm08iai1YbijvhSYN5b86822.67",
"transaction_codes": "205383191213V001 0354 0102 0101"
},
"summary": {
"subtotal": 22.67,
"change": 0.00,
"total_items": 5,
"sales_discount": 0.00,
"net_discount": 13.50
},
"footer_messages": [
"欢迎再次惠顾—服务电话:0755-28376290",
"华润万家全国客服电话:4008222666",
"华润万家与您携手,共创食品安全城市"
],
"barcode_data": "205383 V001 191213 0003540"
}
同时,它准确理清了结算逻辑。识别出单品折扣是负数扣减、删除折扣是正数加回,并列出完整算式 (-9.00) + (-4.50) + (-4.50) + (+4.50),与最终的优惠总额完成了精准核对。

紧接着,我们又上传了一张 YaRN 论文中的困惑度(PPL)折线图,要求它分析不同方法的表现差异。
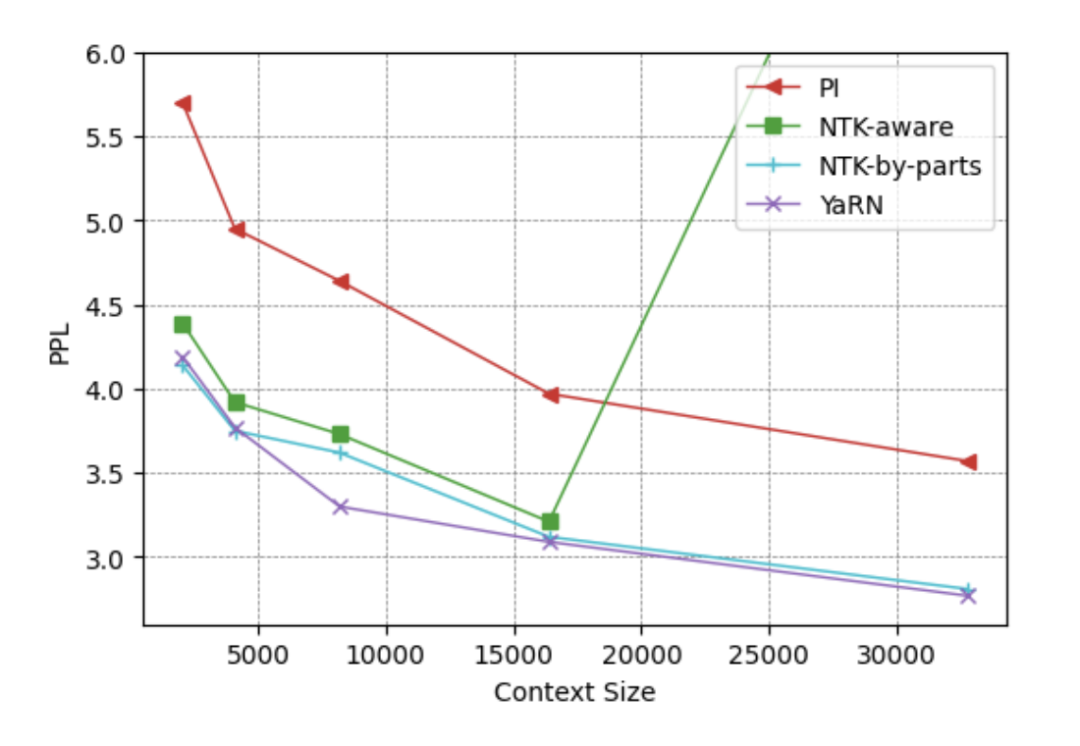
LongCat-Next 准确读出了不同序列长度下 PPL 的走势,并得出了与原论文一致的结论,在处理这类密集的学术图表时没有出现信息遗漏或幻觉。

在图像生成方面,我们尝试让它生成一张儿童绘本封面,提示词中要求包含主标题、副标题和作者名,并指定了排版位置与雪花纹理字体。

从生成的图片来看,文本拼写完全准确、大小写遵循指令,标题和作者名的上下排版也没有出现文字飘浮或遮挡问题。
在官方展示的测试案例中,团队输入了一段用四川方言录制的逻辑推理题:
“骑士说真话,无赖说假话。A 说:‘我是骑士。’问 A 可能是什么人?”
LongCat-Next 直接听懂了方言音频,并给出了准确的逻辑推导过程。同样在官方的语音合成案例中,模型被要求合成一句中英夹杂的日常会议通知:“明天的 meeting 在三楼的 Conference Room 举行。”在处理这种中英混语时,它的发音和韵律切换非常自然,没有生硬的机器拼接感。
走向下一代基座
回到文章开篇的那个问题:所有的物理世界信号,最终都能收敛为同源的离散 token 吗?
LongCat-Next 用实际表现给出了一份清晰的答卷。在多模态模型普遍依赖参数堆砌和异构模块拼接的今天,它证明了底层架构的重构依然存在巨大的红利空间。通过将连续的视觉与听觉信号转化为同源的离散 token,它成功把多模态任务拉回了语言模型最成熟的下一通证预测轨道。
这不仅让一个激活参数仅为 3B 的基座模型展现出了跨级别的图音理解与生成能力,更重要的是,它为系统工程提供了一条极简且高效的新路线。目前,LongCat-Next 的开源代码和完整技术报告均已发布,对于苦于跨模态融合信息损耗的研究者和开发者来说,这套纯离散架构提供了一个值得深挖与验证的全新样本。
模态融合的最终形态究竟是什么样,现在下定论或许还为时尚早。但 LongCat-Next 至少让我们看到,在寻找物理世界统一表征的道路上,除了不断堆砌外挂模块做加法,我们同样可以通过底层逻辑的统一来做减法。关于此类多模态模型的更多技术细节与实践,开发者们也可以在云栈社区交流探讨。
 发表于 2026-3-28 02:32:34
|
查看: 161|
回复: 0
发表于 2026-3-28 02:32:34
|
查看: 161|
回复: 0
