
当前,AI大模型规模已突破万亿参数,但单颗GPU芯片在物理功耗密度、互连带宽与内存容量上的瓶颈日益凸显。单纯依靠“芯片堆砌”的传统模式,正面临通信开销剧增、算力利用率骤降的行业共性难题。技术的快速迭代表明,AI基础设施的竞争焦点正从“单一芯片”转向以“整机系统”为核心。
在这一背景下,中兴通讯推出了其超节点技术。不同于聚焦于GPU芯片本身的性能竞赛,中兴选择从系统级协同架构出发,通过重构算力互联体系,将数十至数百颗不同厂家的GPU逻辑整合为统一的计算单元,旨在实现算力的全局最优。近期发布的《中兴通讯超节点白皮书》,不仅为突破单GPU瓶颈提供了新思路,更重塑了AI算力基础设施的构建逻辑。
核心逻辑:锚定系统级算力协同
面对单GPU的性能天花板,行业共识是通过高速无损互联将多GPU整合为逻辑上的“超级计算机”。中兴超节点的设计正契合这一趋势,它避开了高壁垒的GPU芯片研发竞赛,将发力点精准放在解决多芯片协同效率过低这一核心痛点上。
中兴超节点并非简单的硬件堆砌,而是一个融合了多芯片、整机硬件、高速互联与配套软件的集成系统。其构建遵循四大核心前提:
- 芯片能力均衡:要求GPU的算力、显存、互联带宽三者匹配,避免资源浪费。
- 互联架构有效:超节点内任意GPU间的互联带宽需达到机间互联的8倍左右,兼顾通信效率与扩展性。
- 内存访问便捷:所有GPU支持统一内存编址,兼容内存语义和消息语义,保障编程易用性与数据访问效率。
- 架构扩展原生:集群扩展后仍属于高带宽域,满足算力按需弹性配置的需求。
这四大前提从底层确立了“系统级算力最优”的目标,为后续所有技术创新奠定了基础。
硬件架构创新:OEX正交无背板互联
传统GPU集群依赖Cable Tray线缆架构,存在信号损耗大、算力密度低、运维难、成本高等短板。中兴超节点的核心硬件创新是推出了 Orthogonal Electrical eXchange (OEX) 正交无背板互联交换架构,该架构已于2025年入选ODCC“年度重大技术突破”案例。
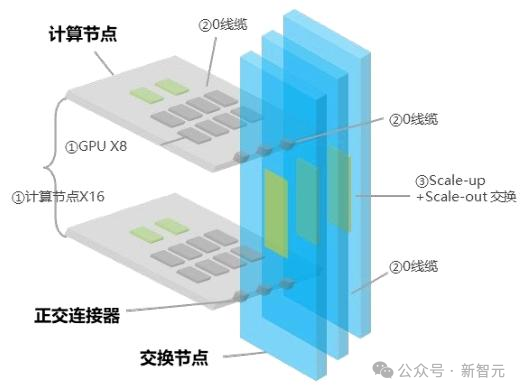
OEX架构的核心在于让计算托盘与交换托盘实现垂直交叉物理直连,彻底摒弃传统高速线缆,通过正交连接器与单级交换拓扑构建无线缆互联体系。这一设计带来了多重价值:
- 性能提升:在112G高速信号下,SerDes链路长度缩短30%以上,消除了线缆引入的6.5dB插损,端到端链路插损余量大于3dB,为TB级互联带宽提供了稳定支撑。
- 密度提升:无线缆设计释放了机柜空间,使标准机柜可集成64/128卡甚至更多GPU,实现了单位空间算力密度的跨越式提升。
- 可靠性增强:从根源上减少了线缆松动、老化导致的宕机风险,将系统故障修复时间(MTTR)从小时级缩短至分钟级。
- 成本与复杂度降低:交换板内集成参数面leaf交换,省去了传统组网所需的leaf层级交换机、光模块和光纤。
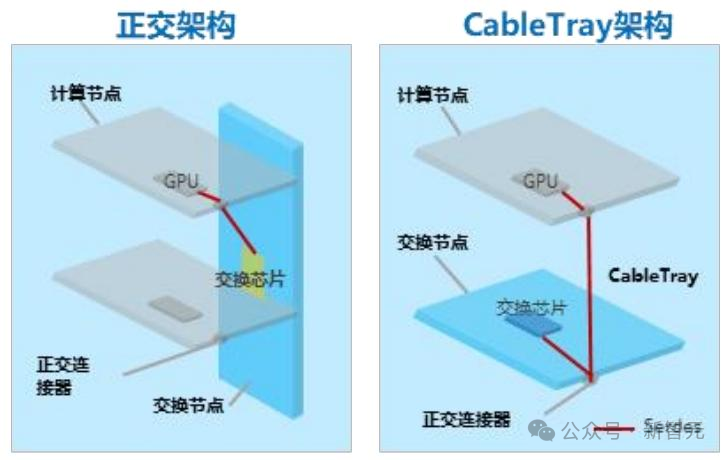
相较于其他正交方案,中兴OEX的无集中式背板设计进一步降低了层间损耗与硬件复杂度。
高速互联创新:自研芯片与全维度优化
GPU间的高效互联是系统级协同的关键。中兴依托通信领域积累,从芯片、物理层、协议层、计算卸载、扩展性五个维度实现了全面创新。
- 核心芯片:自研大容量交换芯片,实现TB级带宽、百纳秒级时延,支持大规模全对等互联,并全面兼容RDMA、CLink、UEC等主流协议。
- 物理层选型:放弃传统PCIe总线,采用以太网物理层。PCIe 5.0 x16双向带宽约128GB/s,而以太网SerDes速率已达112Gbps并向224Gbps演进,可通过多通道绑定轻松实现TB/s级端口带宽。
- 协议层开放:既支持UALink、ESUN等国际协议,也积极参与工信部牵头的CLink协议制定,推动国内算力互联标准统一。
- 在网计算:将GPU的高负载通信操作(如All-Reduce)卸载至交换芯片。在白皮书测试中,此举使MoE模型的分发时延下降20%-50%,归约时延下降40%-60%以上,干线流量减少超30%。
- 可扩展设计:从协议、拓扑、物理形态、介质四个维度进行Scale-Up设计,预留足够GPU ID标识位,采用线性无收敛扩展拓扑,并以机柜为单元实现模块化“即插即用”扩容。
功耗管理创新:液冷与高压直流供电
高密度集成带来功耗指数级增长。中兴构建了一套“前瞻布局”的功耗管理体系。
- 散热体系:
- 当前采用成熟的单相冷板式液冷,支撑百千瓦级机柜。
- 针对未来单芯片功耗突破2000W的趋势,规划硅基微通道冷板和两相冷板液冷技术。
- 兼容浸没式液冷,为未来兆瓦级机柜散热提供解决方案。
- 供电架构:突破48V/54V极限,采用±400V DC或800V DC的高压直流(HVDC)供电。
- 同等功率下,电流降低8-16倍,铜材用量减少40%-50%。
- 端到端供电效率提升3%-5%,对电力成本占比高的智算中心意义重大。
- 可轻松支撑从当前150kW向1MW+级机柜的演进。
集群扩展创新:Nebula Matrix实现平滑扩展
面对超大模型训练需求,算力需规模化扩展。中兴通过Nebula Matrix集群超节点实现从百卡到万卡的平滑扩展。
采用“电交换+光互联”主流路线,机柜内用高性能电交换,跨机柜用光纤互联,兼顾了技术成熟度与成本。基于Nebula X32单体超节点,可灵活扩展为X256/800集群超节点,未来更可扩展至X8192/16384超大规模集群。
创新提出Scale-Up与Scale-Out网络融合设计,打破两类网络独立组网的模式。融合后的统一网络,既能承载对带宽时延要求极高的张量并行流量,也能适配数据并行等常规流量。白皮书模型测算显示,该融合架构能显著降低总拥有成本(TCO),并保障部署扩容的平滑性。
软件栈创新:打造超节点“操作系统”
硬件是基础,软件是释放算力的关键。中兴打造了一套深度协同的全栈优化软件栈,堪称超节点的“操作系统”。
- 统一资源池与智能编排:将算力、内存、存储资源抽象池化,根据AIGC训练、推理等负载动态分配。
- 极致通信优化与拓扑感知:通过优化通信库,自动识别最优传输路径,结合计算通信重叠等技术隐藏通信开销。
- 异构计算统一调度:实现CPU/GPU/DSA等异构单元的统一调度与编译器优化。
- 全栈可观测与智能运维:实现芯片-节点-集群多级监控,结合AI运维进行故障预测与根因分析。
- 高可靠冗余机制:通过冗余算力节点与故障切换,保障大模型训练的业务连续性。
- “算力-电力”绿色调度:结合任务优先级、功耗模型与实时电价,动态调整算力调度,降低能耗。
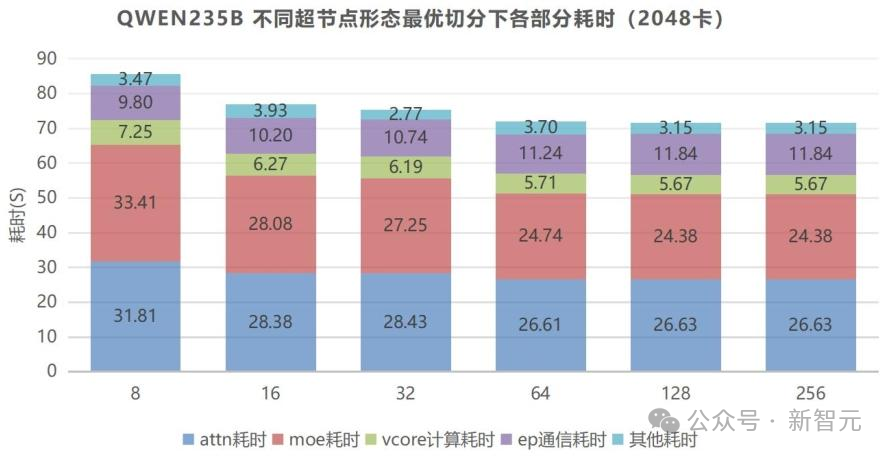
此外,中兴还提供了算力仿真平台,为用户硬件选型与并行策略提供“数字孪生”推演。以Qwen3-235B模型为例,仿真显示在2048卡规模下,256卡超节点相比8卡服务器,训练性能可提升15%。
多厂家GPU兼容:打破生态锁定
在封闭生态趋势下,中兴将多厂家GPU兼容作为核心创新,通过五个维度系统化设计打破生态锁定。
- 硬件层:OEX架构采用组件化设计,将GPU适配模块独立为UBB模组,更换模组即可实现不同厂家GPU的“即插即用”。
- 芯片层:自研交换芯片兼容主流互联协议,打造“一次设计,多卡兼容”的通用互联底座。
- 协议层:积极参与行业标准制定,同时自研的OLink协议采用开放标准设计。
- 生态层:开放OEX架构的机械与电气接口规范,并推动超节点硬件的行业标准化立项。
- 集群层:融合组网架构继承了协议兼容能力,支持跨机柜、跨品牌GPU的高效协同。
小结
纵观中兴超节点的技术体系,其核心定位是“做TCO最优算力系统级整合者”。它跳出了芯片内卷,从系统协同架构出发,通过六大维度的创新,绕开了单GPU性能瓶颈,拼出了AI算力的系统级最优解。
这份创新的价值,不仅体现在具体指标提升上(如MoE模型通信时延大幅下降),更在于对算力建设模式的重构:从“芯片堆叠”走向“协同释放”,从“单一硬件竞争”走向“全栈系统优化”。其打造的“AI工厂”,旨在将AI开发升级为标准化、规模化的现代化流水线。
更重要的是,其开放兼容设计打破了单一厂商的生态锁定,为用户提供了灵活的算力选择,推动了行业的开放融合。正如白皮书所言,未来算力的竞争将是“每瓦Token数”的竞争。中兴超节点通过系统级创新,在效率、扩展性与生态兼容性上寻求多重最优,为整个智算行业的发展提供了新思路。对于关注前沿算力架构的开发者而言,这类系统级优化的探讨在云栈社区等技术论坛中具有很高的交流价值。
 发表于 2026-3-28 02:27:17
|
查看: 164|
回复: 0
发表于 2026-3-28 02:27:17
|
查看: 164|
回复: 0
