当中国AI还常被贴着“追赶者”标签时,天工AI却在中关村论坛一口气拿出视频、音乐、世界模型三张王牌,宣告中国AIGC正从单点突破迈向真正的全模态领跑。

创作者们苦AI“盲盒”久矣。
问问游戏制作人,被吹上天的“世界模型”简直是重度失忆症患者,角色跑三步地平线就扭曲,稍微转个身旁边的房子就会凭空消失。
问问短剧操盘手,镜头刚切走男主角的西装变成了夹克,生成的画面全是“无声默片”,后期硬贴配音,爆炸火光亮起两秒后才听到轰隆声。
再问问专业音乐人,AI作曲听着热闹但就是有塑料味。你既不能精准地在第15秒加一段压抑的大提琴,更没法让它在副歌前学会屏住呼吸。
AI游戏、AI视频、AI音乐,三条最火的AIGC赛道,三个最深的行业顽疾。

2026年3月27日,中关村论坛的一场发布会,给出了三个解法。
游戏世界模型Matrix-Game 3.0、视频大模型SkyReels V4、音乐大模型Mureka V9同时登场,全部杀入世界第一梯队。这一天,或许可以称为中国AIGC的“全模态时刻”。


三条赛道,三个顽疾,三剂解药
杀入第一梯队是结果,怎么把行业最头疼的病治好的才是关键。
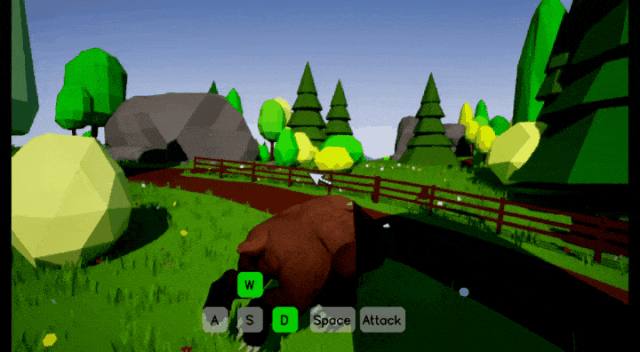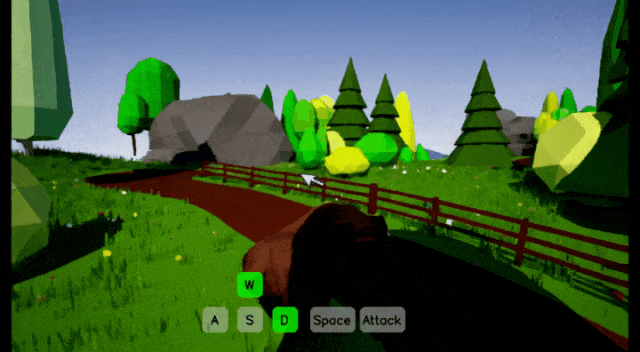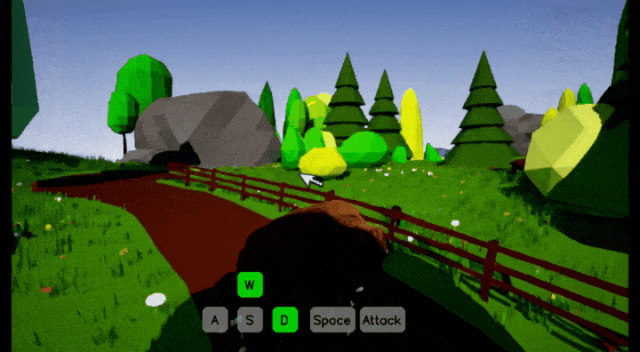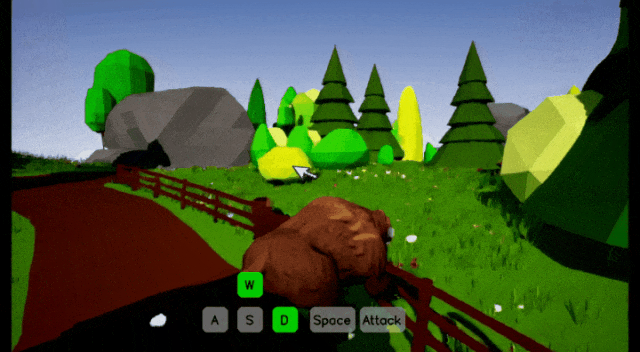
Matrix-Game 3.0:在生成的城市里走上一遭,回头一切照旧
今年1月,图灵奖得主Yann LeCun专门为“世界模型”方向创立了公司AMI。AMI首席科学官谢赛宁推出的全球首个多人世界模型Solaris,其技术底座正是天工AI开源的上一代Matrix-Game 2.0。这本身就说明了天工AI在这条赛道上的技术地位。

但Matrix-Game 2.0有一个未解决的问题:失忆症。你在AI生成的世界里走了一分钟再回头,房子可能消失,路灯可能换位,整个世界面目全非。3.0版本正是来治这个病的。
在演示中,视角穿过斑马线,大范围环顾四周后再折返回来。镜头转了一大圈重回原地时,那栋顶着巨大青蛙雕像的绿色小楼原封不动,墙上的粉红灯笼还在,路口的绿色公交车也没有凭空消失或扭曲变形。
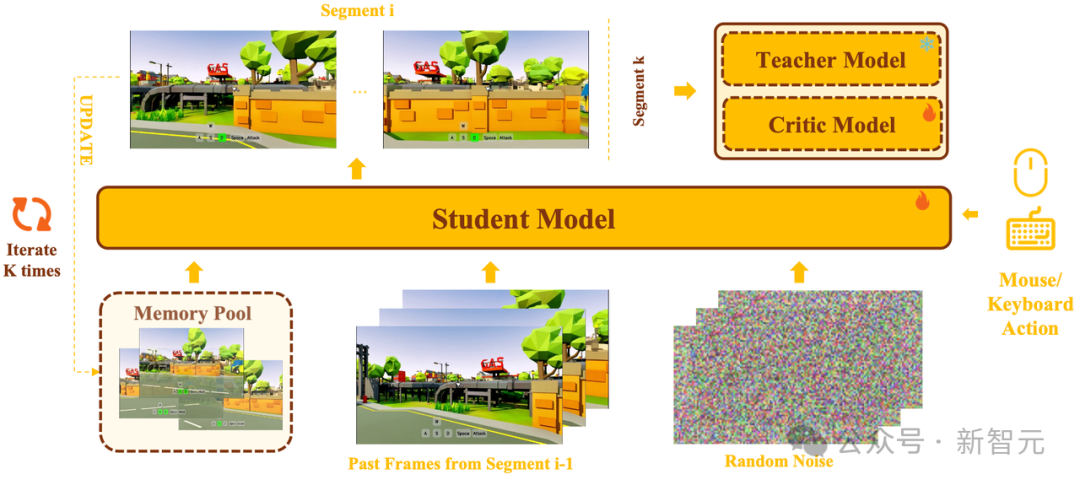
看完效果,我们拆解一下背后的技术。世界模型最大的瓶颈不是算法,是数据。互联网上的视频只有画面,缺少相机位姿和操作指令,AI无法从中学会“我按了方向键,世界应该怎么变”的因果关系。
Matrix-Game 3.0为此搭建了一套工业级的无限数据引擎,双管线并行:
- 管线一:基于Unreal Engine 5自动生成覆盖1000+场景的高精度交互数据,由强化学习驱动的AI Agent在场景中自主探索,每一帧都同步记录视频、6-DoF相机位姿和操作指令,毫秒级对齐。
- 管线二:从3A游戏中全自动提取动态交互数据,7×24小时无人值守,TB级数据持续产出。
世界模型要“记住”世界,首先得“见过”足够多的世界。


在模型层面,Matrix-Game 3.0从三个维度做了系统性升级。
第一是记忆注入。
模型在生成当前画面时,不只看最近几帧,还会根据相机位姿检索出更早期的“记忆帧”,只取与当前视角相关的内容,放进同一个注意力空间联合建模。走过的路、看过的楼,模型都记得。
第二是Error Buffer抗漂移机制。
长时序生成中模型会逐渐偏离真实状态,3.0在训练时就显式建模生成结果与真实帧之间的误差,并把误差作为条件重新注入,让模型大量接触“已经跑偏”的状态,逼它学会自我纠正。
第三是蒸馏加速。
要让5B参数的模型在720P分辨率下跑到40FPS实时生成,需要将推理步数压下来。3.0采用了多段自回归蒸馏框架,在训练阶段就让学生模型连续生成多个视频段,完全模拟真实长视频推理的误差累积环境,配合模型量化和VAE解码器蒸馏,最终实现了分钟级长时序一致性下的实时交互。

可交互基础模型结构示意图
记忆增强基础模型结构示意图
多段自回归蒸馏示意图
三层技术叠加,5B轻量模型就跑出了720P、40FPS的实时生成,并保持分钟级长时序一致性。这在一年前是不可想象的。更大的MoE-28B模型,则在泛化性和动态表现上更进一步。它为第一人称和第三人称分别训练独立的动作模型,共享同一个视觉细节模型,可生成时长约60秒。
放眼全球,在可交互世界模型这条赛道上,Google DeepMind的Genie 3是闭源标杆,Matrix-Game 2.0是该技术范式的首个开源实现。3.0版本在记忆、分辨率和实时性上全面超越2.0,是目前与Genie齐头并进的方案。

以前的世界模型是“能看不能摸”的橱窗展品,现在的Matrix-Game 3.0是一个可以真正走进去玩的虚拟世界,是迈向通用人工智能的重要一步。
世界的问题解决了,接下来看画面。
SkyReels V4:画面里人开口说话的瞬间,声音就跟上了
注意“听”,在演示的漫天黄沙场景里,女主开口说“谢谢你救了我”的瞬间,声音严丝合缝地跟上;男主回应时,背景音乐的节奏也刚好踩在了画面的情绪点上。这段戈壁戏,不仅演员表情自然,连呼啸的风声都与画面完美交融。
这就是SkyReels V4最突出的改进之一。以前的AI视频通常先生成画面,再用另一个模型配音。两套系统各干各的,经常出现音画对不上的情况。SkyReels V4直接从底层解决了这个问题。
它自研了一套双流MMDiT架构。视频和音频不再是两个模型各自生成,而是在同一个模型内部,通过双向交叉注意力机制同时生成,音画从第一帧起就是锁死同步的。
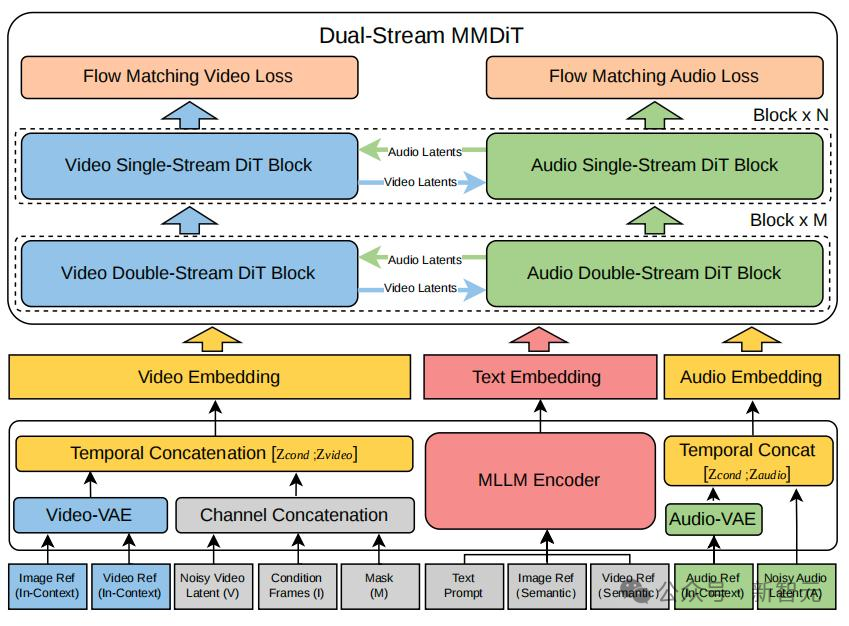
但光解决音画同步还不够。短剧制作中的另一个噩梦是控制失灵,镜头一转主角就变脸。
SkyReels V4的解法是全模态强化学习加上精准控制系统。强化学习搭建了一套覆盖全场景的语义Reward模型,教AI“看大局”,不只是死磕每个像素是否好看,而是让画面整体在“讲一个逻辑自洽的故事”。
它支持关键帧参考自动补全节点间的画面。网格图参考功能更强大,上传最多9张剧情帧,即可一键生成角色不走形、场景不跳跃的连贯短剧。此外,多角色对话场景也能自动处理正反打镜头切换、台词分配和表情匹配,并支持中、英、法、日等多语种。
同一套框架还覆盖了去水印、去台标、删除或添加角色等后期编辑功能,对影视后期来说是刚需。例如,只需给模型喂一张静图加一段实拍视频,真人演员就能被无缝替换,动作节奏分毫不差,背景运镜也能被完美保留。



再比如,在另一个演示视频中有一个手持紫色液体的角色。只需给模型指令“找到这个人和这瓶东西,删掉”,目标和物品就能被干净移除,背景无缝填补。


视频的问题解决了,接下来看声音。
Mureka V9:唱对了,混对了,该停的地方也停了
先说一个事实。前一代Mureka V8,已经凭借自研的MusiCoT(Music Chain-of-Thought)技术在Artificial Analysis音乐模型榜单上,同时拿下了人声和乐器双料冠军。
全球第一了,V9还升级什么?核心是两个字:“好控”。
过去AI音乐最让人抓狂的不是“能不能生成”,而是生成了却“控不住”。歌词落不到对的段落,人声唱不对重点,离创作者真正想要的总差最后一层。V9重点攻克的就是可控性。
在主观听感上,V9实现了段落级歌词语义控制更精准,人声不只是“唱出来”而是“唱对了”,混音质感更通透,生成速度更快,同一创意方向下的结果也更有新鲜度。而且,V9还多了一个能力:知道什么时候不该唱。不必要的哼唱和模糊唱词大幅减少,该留白就留白。
在产品层面,同一创意可以快速产出多个版本,支持在旋律、人声、结构上进行局部保留与替换,创作从“写一首歌然后定稿”变成了版本化的迭代工作流。
一句话概括:从“能做出作品”走向“能稳定做出你真正想要的作品”。
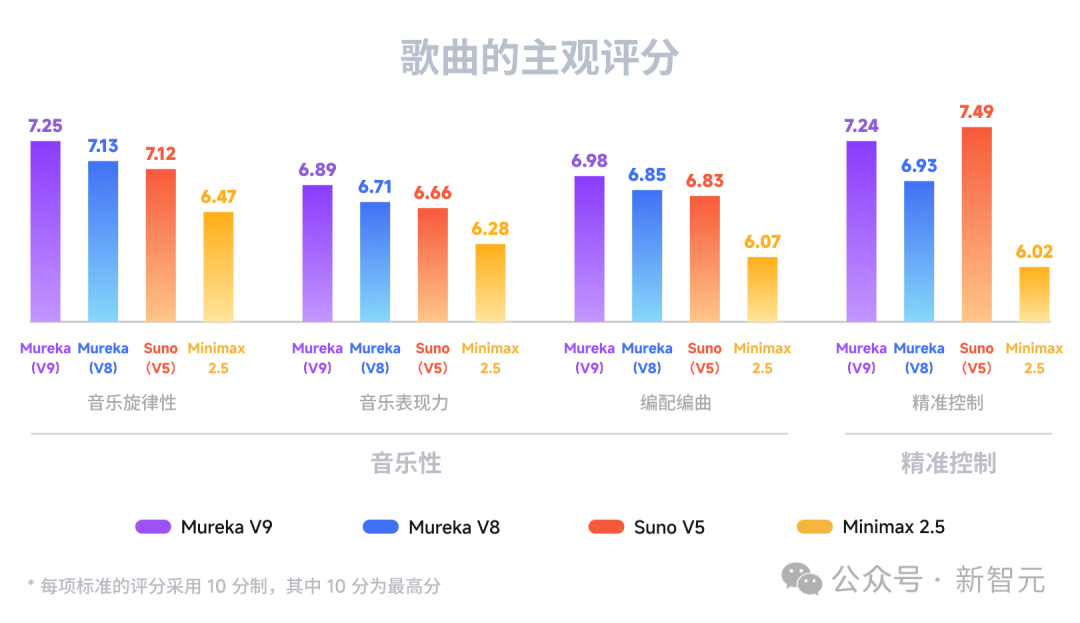
数据也印证了这个判断。在主观评分中,V9在音乐旋律性(7.25)、音乐表现力(6.89)、编配编曲(6.98)三个维度全部拿下第一,超越Suno V5和Minimax 2.5。而涨幅最大的恰恰是精准控制维度,从V8的6.93直接跳到V9的7.24。
在实测曲目中,主唱人声在短短20秒内,于中、英、法、西四种语言间无缝穿梭。不管语言怎么切换,慵懒的民谣腔调、换气节奏甚至咬字气声都保持着惊人的一致性。
但Mureka的野心不止于一个AI作曲工具,它瞄准的是AI音乐时代的“Spotify”。逻辑在于,当AI让音乐创作从“少数专业人士的低频行为”变成“所有人的高频表达”时,音乐需要一个新的原生平台来承载。Mureka正以此为目标构建,以模型能力为底座,版本化创作工作流为引擎,同时面向B端开放API。市场反馈积极,其ARR(年度经常性收入)已达到竞品同类模型的10倍以上,不到两年迭代九个大版本。
在论坛现场的互动展区,体验者几乎都发出了“这真的是AI做的?!”的惊叹。这或许是对一个AI音乐模型最高的赞美。

中国AI的“全模态时刻”
现在,世界能记住了(Matrix-Game 3.0),画面能听见了(SkyReels V4),音乐能控住了(Mureka V9)。三个行业最头疼的问题,在同一场发布会上同时给出了解法。
这件事的意义,远不止于三个模型本身。DeepSeek在大语言模型领域的突破,说明中国AI有能力在单个赛道上挑战全球最强。而天工AI在游戏、视频、音乐三条AIGC核心赛道上的同时登顶,指向一件更重要的事——中国AI企业有能力构建全模态的技术体系,而不仅仅是在某个单点上追赶。从单点突破到全面开花,这就是“全模态时刻”的真正含义。
2026 AGI战略:从全模态突破到AI平台经济
技术登顶只是上半场。在同一场发布会上,天工AI董事长兼CEO周亚辉发布了2026 AGI战略,核心是“3+1”布局——三大场景大模型(Matrix-Game + SkyReels + Mureka)加上天工超级智能体。

三个模型是三把尖刀,分别插入游戏、视频、音乐三个百亿级内容产业。天工超级智能体则是串联它们的超级平台,面向C端用户提供一站式AI创作体验,面向B端开发者开放API和生态接口。

这就是天工AI在发布会上亮出的“AIGC全家桶”——不是单个模型的炫技,而是一整套从生成到编辑到分发的全链条能力。配合AI短剧平台DramaWave、AI音乐平台Mureka、AI游戏平台猫森学园2.0等产品矩阵,实现了文本、音乐、视频、游戏四大领域的全覆盖。

按照周亚辉的表述,模型是引擎,平台是工厂,创作者是老板。天工AI要做的不只是模型提供商,更是AI创作者经济的平台运营者。这套全家桶意味着,“一人公司”成为可能:一个人加DramaWave就能出品一部短剧,加Mureka就能发行一张全球专辑,加猫森学园就能创造一个游戏世界。

技术不是凭空而来,而是一行行代码、一篇篇论文积累的结果。回顾天工AI的发展路径:2023年宣布All in AGI时外界充满质疑,到2026年三大模型同时站到世界第一梯队,多年的坚持给出了答案。

而这只是起点。按照公布的路线图:
- 2026年(基础设施年):四大SOTA模型全部就位,能力锁定全球第一梯队,天工超级智能体操作系统上线。
- 2027年(生态爆发年):Skills生态全面开放,创作者变现通路打通,B端API对外输出。
- 2028年(平台经济年):垂直平台在各领域冲击全球头部,天工超级智能体成为创作者标配基础设施。

当“全模态”从概念变成榜单上的排名、API接口里的能力、用户手中可感知的产品时,中国AIGC的“全模态时刻”,确实已经到来。天工AI的实践,特别是其开源的Matrix-Game系列,为全球的研究者提供了宝贵的参考,是AIGC技术发展中的重要贡献,相关技术细节和探讨也常在云栈社区这样的技术论坛中被深入分析。
参考资料
 发表于 2026-3-28 02:24:02
|
查看: 133|
回复: 0
发表于 2026-3-28 02:24:02
|
查看: 133|
回复: 0
