当Transformer架构席卷计算机视觉领域,高分辨率图像、超长序列任务带来的算力与显存瓶颈愈发凸显。标准Softmax注意力机制因其二次复杂度,让处理70K以上token的超分辨率任务时直接面临显存爆炸,高分辨率图像分割、检测的推理延迟也居高不下。
线性注意力虽通过核函数重构实现了线性复杂度,完美解决了算力开销问题,却始终无法摆脱性能退化的问题,与原生Softmax注意力的精度差距难以弥合。
近日,哈工深(深圳)张正副教授团队联合鹏城实验室、昆士兰大学等机构,在预印本平台arXiv上发布重磅论文 《Norm×Direction: Restoring the Missing Query Norm in Vision Linear Attention》 ,提出了名为 NaLaFormer(Norm-aware Linear Attention Transformer) 的全新框架。
该研究首次通过“模长-方向”(Norm×Direction)分解,精准定位并解决了线性注意力长期存在的两大核心缺陷,在保持线性复杂度的同时,实现了在多项视觉任务上精度的全面超越。更关键的是,在处理70K+token的超分任务中,其峰值显存占用降低了惊人的92.3%,为线性注意力在视觉领域的实际落地开辟了全新范式。

论文信息
- 论文标题:Norm×Direction: Restoring the Missing Query Norm in Vision Linear Attention
- 论文链接:https://arxiv.org/pdf/2506.21137
- 作者团队:哈尔滨工业大学(深圳)SMULL Group、鹏城实验室、昆士兰大学 UQMM Lab
- 核心作者:Weikang Meng, Yadan Luo, Liangyu Huo, Yingjian Li, Yaowei Wang, Xin Li, Zheng Zhang (通讯作者)
痛点直击:线性注意力性能崩塌的两大致命伤
线性注意力的核心目标,是通过线性可分核函数替代Softmax中的指数算子,利用矩阵结合律将计算复杂度从$O(N^2)$降至$O(N)$。
但在NaLaFormer的研究中,团队首次系统性地揭示了现有方案始终无法逼近Softmax性能的两大根源:
1. Query Norm被抵消,注意力尖峰性彻底丢失
团队通过数学推导与实验验证发现:在Softmax注意力中,查询(Query)向量的模长(Norm)与注意力分布的熵呈强负相关。Query模长越大,注意力分布越尖锐(熵越低),模型越能精准聚焦于语义关键的信息点,这是Softmax注意力具备强表征能力的核心原因之一。
然而,在传统线性注意力中,归一化操作会直接抵消Query Norm的影响,导致线性注意力彻底失去了对注意力分布尖峰性的动态调控能力。最终,模型输出的注意力分布过于平滑,无法聚焦关键信息,表征能力因此大幅退化。
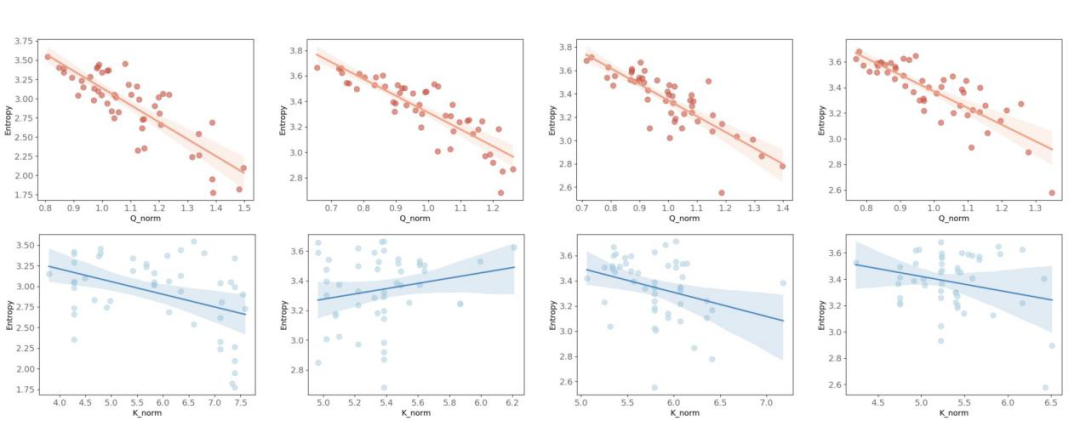
图1. Softmax注意力中熵与模长的相关性:Query模长(x轴)与注意力熵(y轴)呈强负相关,Key模长则无稳定影响。
2. 非负性约束导致不可逆的信息损失
线性注意力的核函数必须满足非负性,才能将注意力得分解释为归一化的概率分布。现有方案普遍通过ReLU、1+ELU等激活函数直接抹除向量中的负值,但这直接导致了Query和Key内积中有效交互信息的丢失——原本具有区分度的负向语义关联被直接清零,最终使得相似度表征变得稀疏且缺乏细粒度信息。
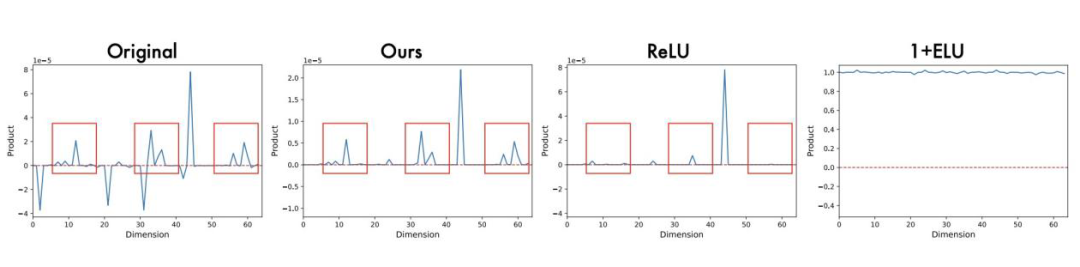
图2. 不同非负策略的内积贡献对比:ReLU、1+ELU均丢失了原始内积的尖峰性与细粒度信息,而本文提出的余弦方向方法完美保留了原始分布特征。
核心创新:Norm×Direction分解,双管齐下补全线性注意力短板
针对上述两大核心痛点,研究团队提出了基于 Norm×Direction(ND)向量分解 的解决方案。该方案将向量的模长(Norm,表征信息重要性)与方向(Direction,编码语义信息)解耦,分别针对性解决两大缺陷,最终实现了对Softmax注意力核心特性的完美复刻,同时完整保留了线性复杂度。
1. Query-Norm-Aware特征映射:重建丢失的模长-信息熵关联
团队首先通过ND分解,对线性注意力的计算过程进行了数学重构,精准定位了Query Norm被抵消的核心环节。
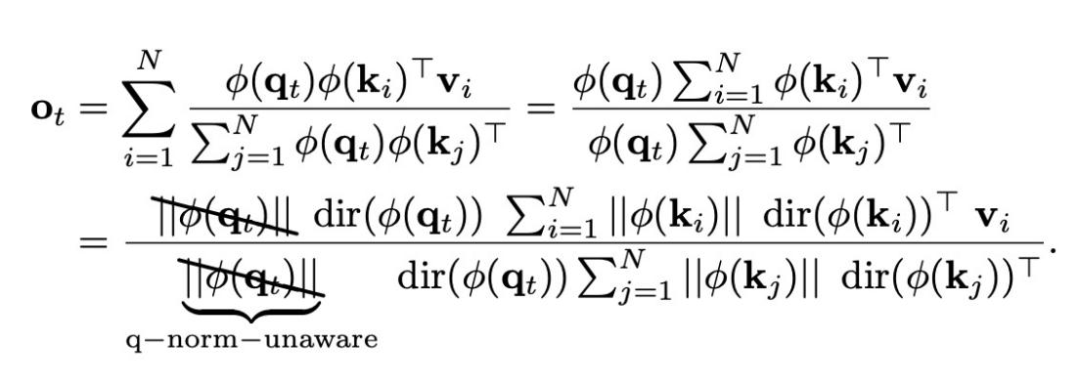
传统线性注意力的输出仅受Key Norm影响,Query Norm在归一化中被完全抵消,导致模型对Query Norm“无感”。对此,团队设计了Query-Norm-Aware特征映射,将Query Norm显式编码进核函数中,通过Norm依赖的锐化函数动态调控注意力熵:
$$
\varphi_q(q) = \text{dir}(q)^{f(||q||)},\quad \varphi_k(k) = k^\lambda
$$
其中锐化函数$f(x)=\lambda \times (\tau + \tanh(x))$,可根据Query Norm动态调整幂次,完美复刻了Softmax注意力中“Query模长越大,注意力分布越尖锐”的核心特性,重建了Query Norm与注意力熵的负相关关系。
2. 余弦方向相似度:无损实现非负性,零信息丢失
针对传统非负约束的信息丢失问题,团队基于三角同构理论,提出了全新的余弦方向相似度机制。该机制对方向分量进行几何变换,在保证非负性的同时,完整保留内积的细粒度信息。
团队为每个标量方向分量设计了二维向量映射:
$$
\varphi_c(\text{dir}(\mathbf{q})_i) = \begin{pmatrix} |\text{dir}(\mathbf{q})_i| \cos(\text{dir}(\mathbf{q})_i) \\ |\text{dir}(\mathbf{q})_i| \sin(\text{dir}(\mathbf{q})_i) \end{pmatrix}, \quad \varphi_c(\text{dir}(\mathbf{k})_i) = \begin{pmatrix} |\text{dir}(\mathbf{k})_i| \cos(\text{dir}(\mathbf{k})_i) \\ |\text{dir}(\mathbf{k})_i| \sin(\text{dir}(\mathbf{k})_i) \end{pmatrix}.
$$
经过变换后,Query与Key的内积可转化为:
$$
\sum_{i=1}^d \varphi_c(\text{dir}(q))_i \varphi_c(\text{dir}(k))_i^\top = \sum_{i=1}^d |\text{dir}(q)_i| |\text{dir}(k)_i| \cos(\text{dir}(q)_i - \text{dir}(k)_i)
$$
通过tanh映射将方向分量缩放至$[0, \pi/2)$,即可保证余弦项始终非负,同时完整保留了原始内积的方向交互信息,彻底避免了传统激活函数带来的信息损失。
3. NaLaFormer:统一的Norm感知线性注意力架构
基于上述两大核心创新,团队构建了端到端的NaLaFormer架构,将Norm感知线性注意力模块与门控架构深度融合,实现了对视觉Transformer中注意力模块的无缝替换。
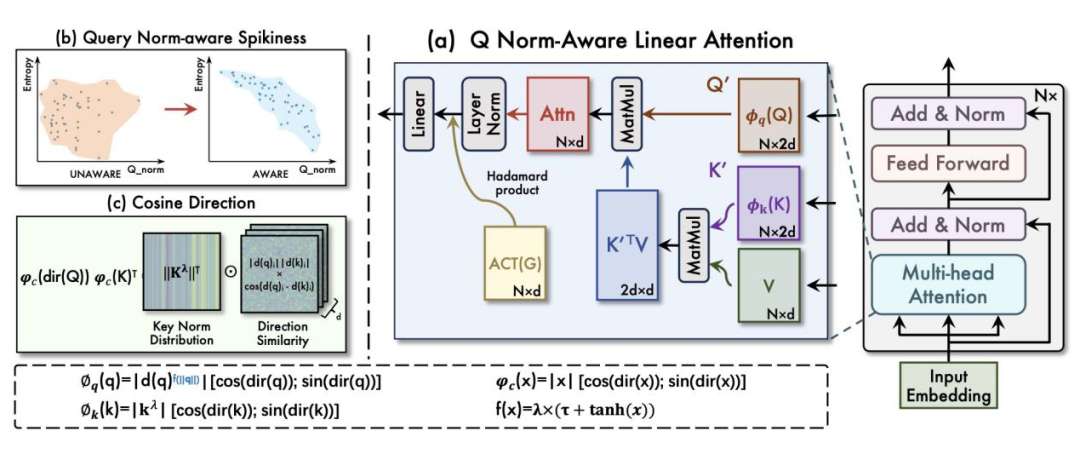
图3. NaLaFormer整体架构与核心机制:(a)NaLaFormer基础模块;(b)Norm感知方法恢复了Query Norm - 熵负相关;(c)余弦方向机制实现无损非负性约束。
最终的注意力输出公式为:
$$
o_t = \frac{\phi_q^{\cos}(q_t) \sum_{i=1}^N \phi_k^{\cos}(k_i)^\top v_i + \phi_q^{\sin}(q_t) \sum_{i=1}^N \phi_k^{\sin}(k_i)^\top v_i}{\phi_q^{\cos}(q_t) \sum_{j=1}^N \phi_k^{\cos}(k_j)^\top + \phi_q^{\sin}(q_t) \sum_{j=1}^N \phi_k^{\sin}(k_j)^\top} \odot G
$$
其中$\phi_q$与$\phi_k$为融合了Norm感知与余弦方向映射的Query/Key特征映射,$G$为门控矩阵,实现了对注意力输出的自适应调制。
实验结果:全面超越,效能惊人
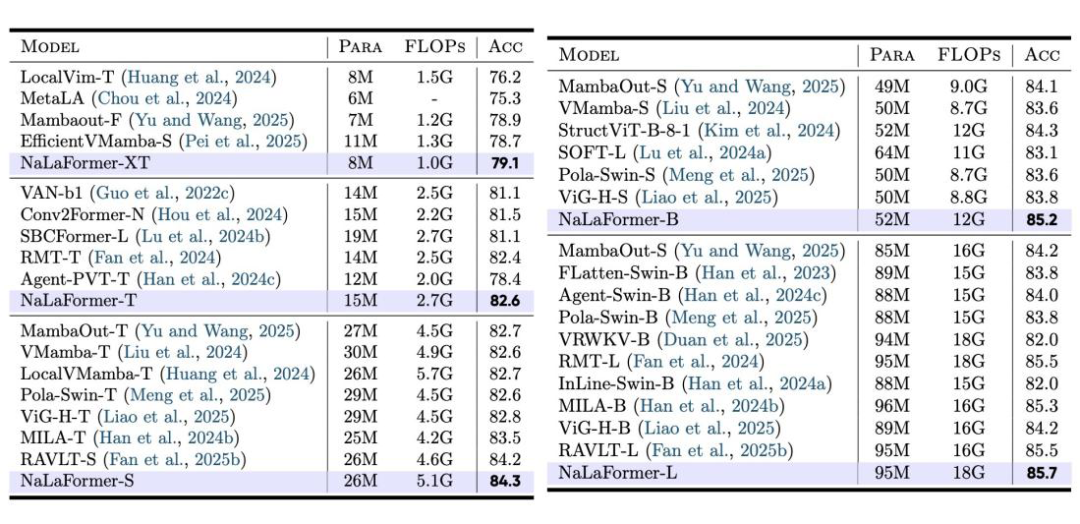
✅ 图像分类:刷新线性注意力ImageNet纪录
在ImageNet-1K图像分类基准上,NaLaFormer实现了对现有线性注意力模型的全面超越。轻量级NaLaFormer-XT仅8M参数量就达到了79.1%的Top-1精度,同量级下较基线最高提升7.5%;大规模NaLaFormer-L以95M参数量实现了85.7%的Top-1精度,刷新了线性注意力模型在该基准上的新纪录。
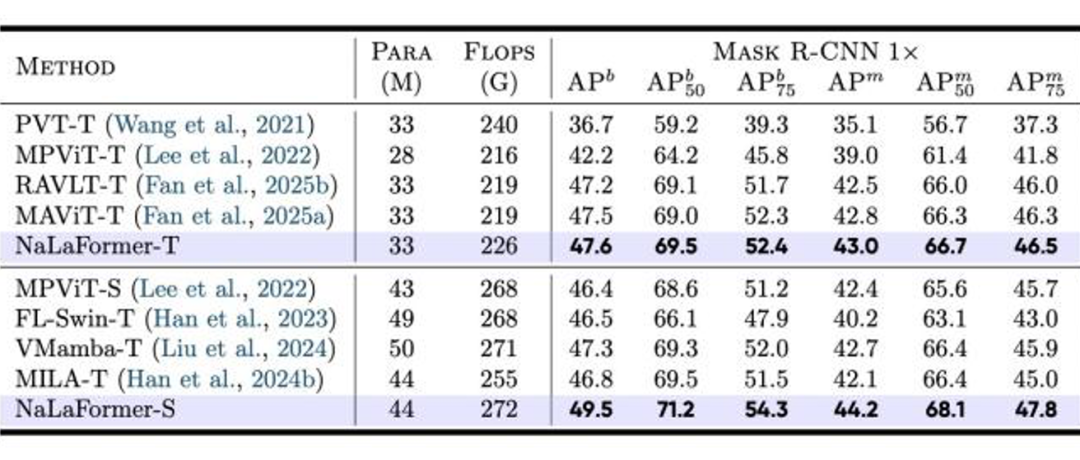
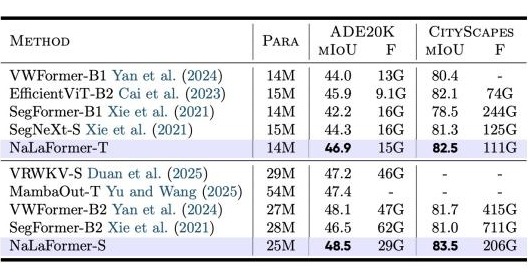
✅ 密集预测:检测、分割全面领跑同量级模型
在COCO目标检测、ADE20K/CityScapes语义分割等密集预测任务中,NaLaFormer展现出极强的细粒度表征能力。
在COCO数据集上,NaLaFormer-T基于Mask R-CNN框架实现了47.6%的检测AP、43.0%的分割AP,全面超越同量级经典视觉Transformer骨干网络。
在ADE20K语义分割任务中,较同量级基线最高提升4.7% mIoU;在CityScapes城市场景分割任务中,也以82.5% mIoU领跑同规模模型。
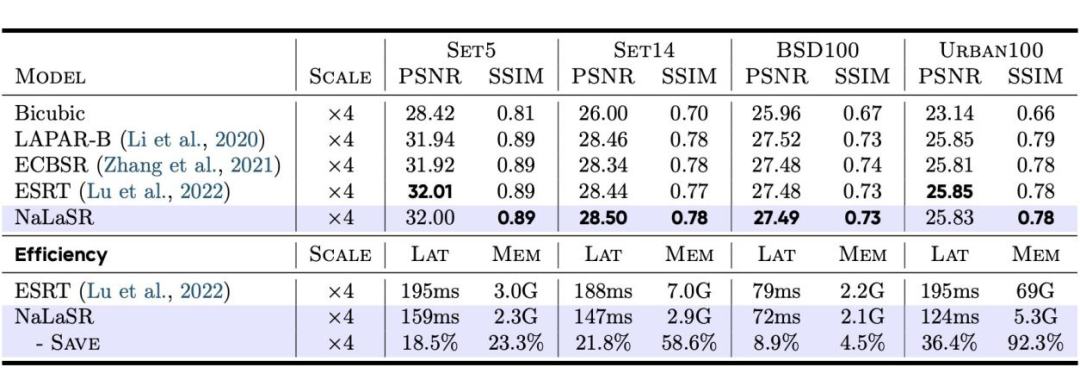
✅ 超分辨率:70K+token峰值显存直降92.3%
在70K+token的高分辨率图像超分辨率任务中,NaLaFormer的线性复杂度优势被彻底释放。在保持重建精度与主流方案(如ESRT)持平的同时,在Urban100 4×超分任务中实现了36.4%的推理延迟降低。最引人注目的是,其峰值显存占用从基线模型的69GB大幅降至5.3GB,降幅高达92.3%,彻底解决了高分辨率视觉任务中的显存爆炸痛点。

✅ 长序列与跨模态能力:LRA新SOTA,语言建模超越Mamba
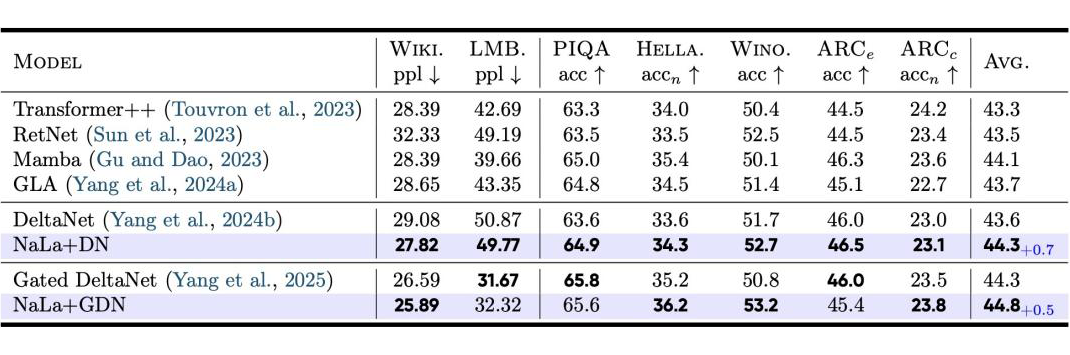
团队进一步验证了NaLaFormer的跨模态泛化性与长序列建模能力。在长序列建模基准Long Range Arena(LRA)上,NaLaFormer实现了61.2%的平均精度,刷新了线性注意力模型的SOTA纪录,同时保持了高吞吐量与极低的显存占用。在从零开始训练的340M参数量语言模型上,NaLaFormer在常识推理任务中的平均得分超越了Mamba、RetNet、GLA等强基线,证明了其在语言模态的强大适配性。
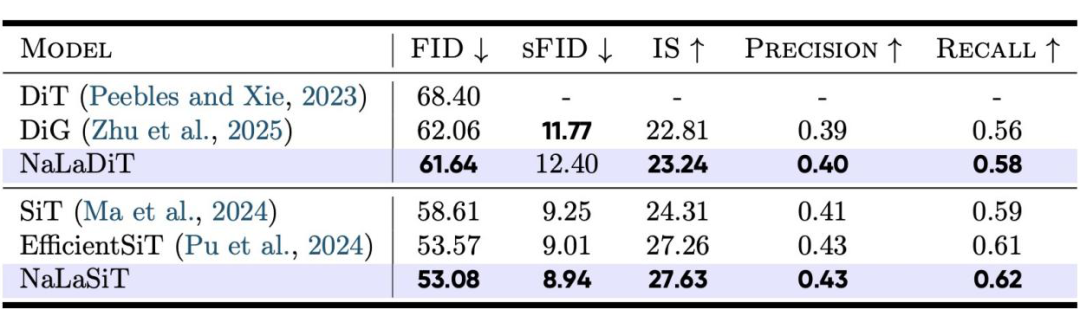
✅ 扩散生成:DiT/SiT性能稳步提升
团队还在扩散Transformer框架中验证了NaLaFormer的生成建模能力。在ImageNet-1K 256×256图像生成任务中,将原始注意力模块替换为NaLaFormer后:
- NaLaDiT相比原版DiT,FID从68.40降至61.64,IS(Inception Score)提升至23.24,生成质量稳步提升;
- NaLaSiT在SiT变体中的表现同样出色,FID低至53.08,sFID为8.94,IS达到27.63,实现了基于SiT架构的高效能生成。

总结与展望
哈工深SMULL团队提出的NaLaFormer框架,通过创新的Norm×Direction分解,系统性解决了线性注意力在Query Norm感知缺失和非负性约束导致信息损失两大根本性难题。这不仅在理论层面深化了对注意力机制的理解,更在实践层面带来了性能与效率的双重飞跃。
该研究标志着线性注意力在视觉任务上的应用迈出了关键一步,其卓越的显存效率尤其为处理高分辨率图像、视频等大规模视觉任务开辟了新的可能性。随着对注意力机制本质的持续探索,诸如NaLaFormer这类高效架构有望在更广泛的人工智能应用场景中发挥作用。
本文基于论文《Norm×Direction: Restoring the Missing Query Norm in Vision Linear Attention》进行解读。更多前沿技术动态与深度讨论,欢迎访问云栈社区的智能 & 数据 & 云板块。
 发表于 2026-3-28 02:36:17
|
查看: 124|
回复: 0
发表于 2026-3-28 02:36:17
|
查看: 124|
回复: 0
