背景与挑战
阿里云开放平台(OpenAPI)是开发者管理云上资源的标准入口。开放平台承载了几乎所有云产品的对外接口,承载客户自动化运维与云资源管控的核心诉求。随着企业对自动化的依赖日益加深,OpenAPI 的稳定性建设变得至关重要。
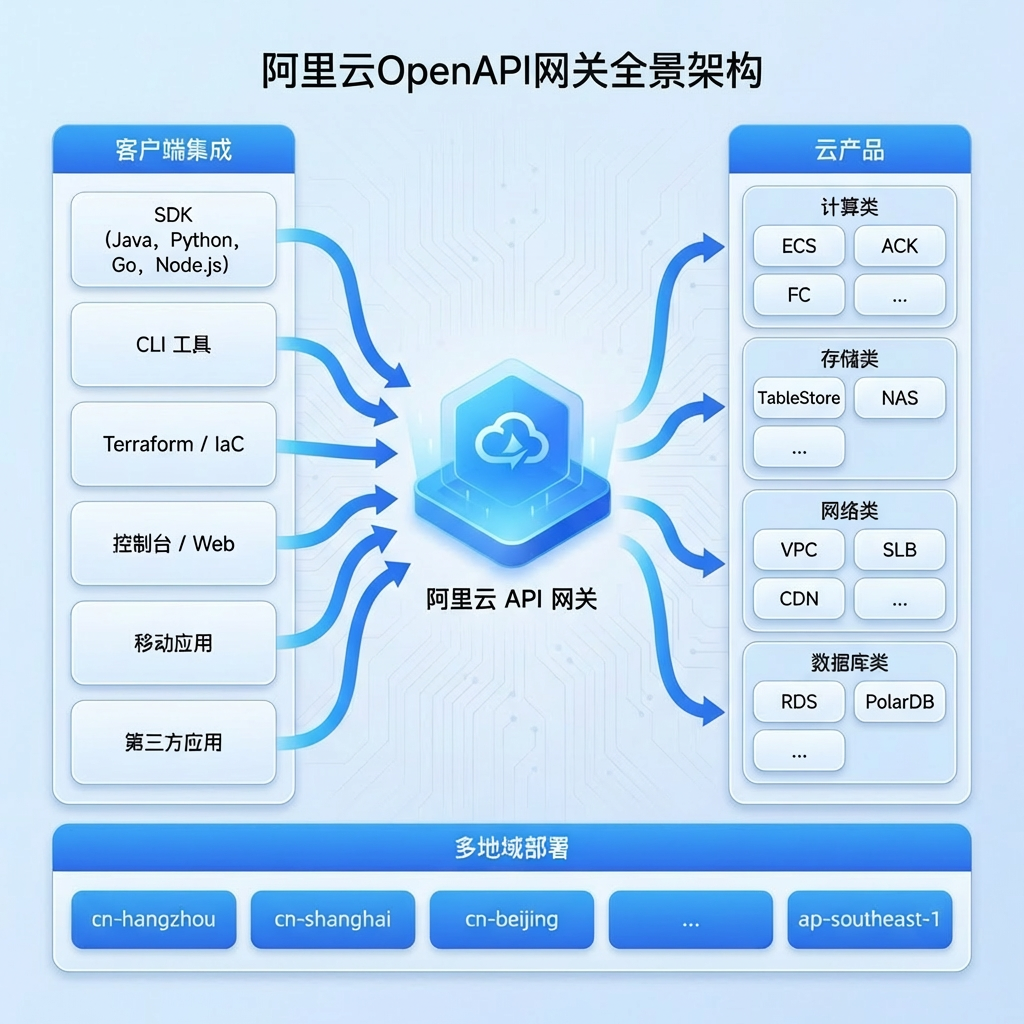
监控体系的需求方包括:
- 开放平台运维团队:负责网关整体可用性,需要全局视角的监控告警。
- 各云产品团队(ECS/RDS/SLB 等):需要查看自己产品的 API 调用指标和大盘,并配置细粒度告警。
- SRE 团队:需要快速定位故障,进行根因分析。
任何接口的波动都可能影响客户的生产业务,因此必须建立全方位的指标监控体系,并配套及时的告警能力,以确保高可用性。
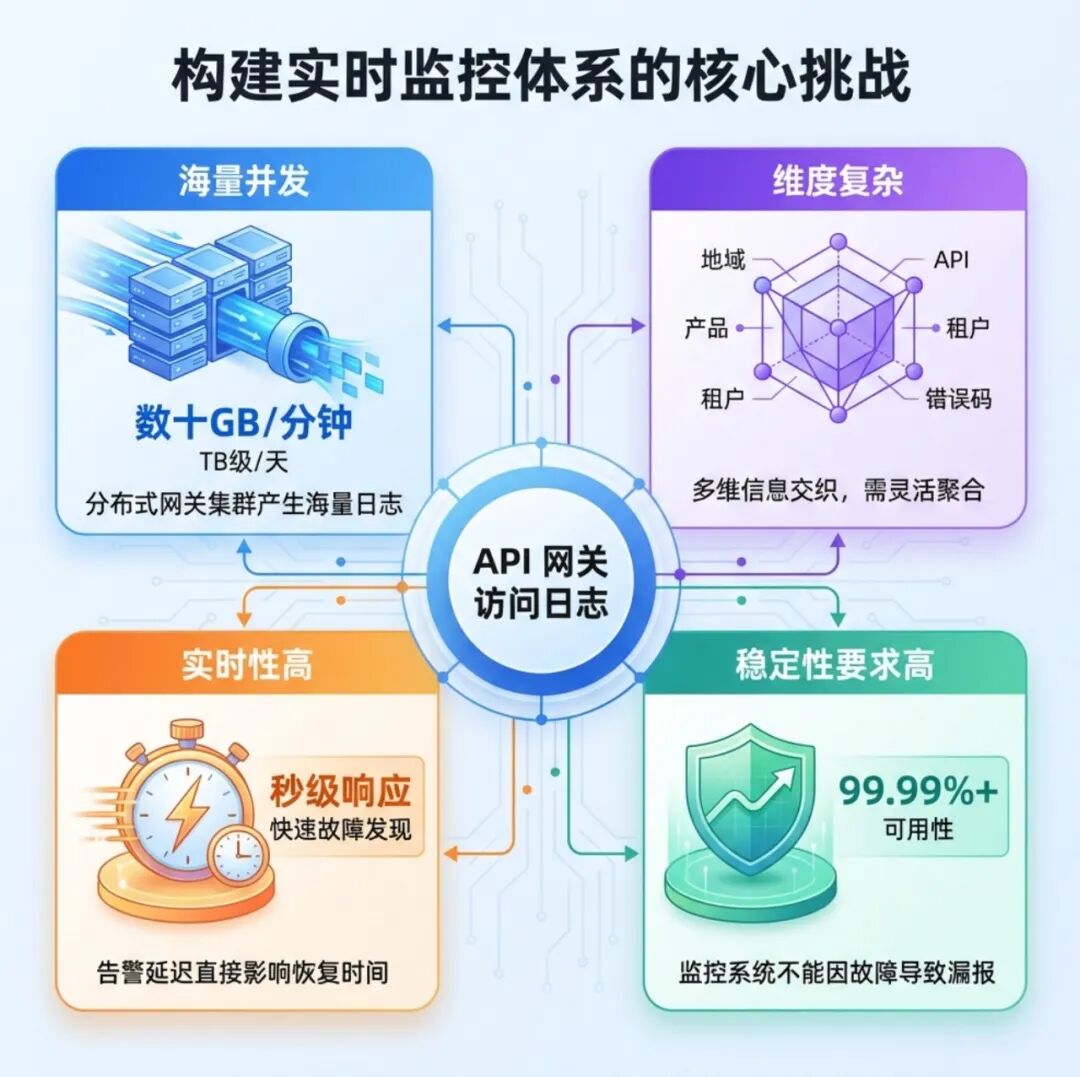
核心挑战
构建监控体系的核心数据源是 API 网关的访问日志。这些日志由分布式部署在各地域的网关节点产生,具有以下鲜明特点:

技术方案
针对上述挑战,我们采用 Flink + SLS(日志服务) 的云原生组合来构建实时监控体系。
技术选型
该方案的核心组件及选型理由如下:

这套组合的核心优势:
- 全托管运维:SLS 和 Flink(基于阿里云实时计算)均为全托管服务,无需运维基础设施。
- 弹性扩展:消费吞吐和计算资源可按需扩缩。
- 端到端保障:从采集到告警的全链路可观测。
整体架构
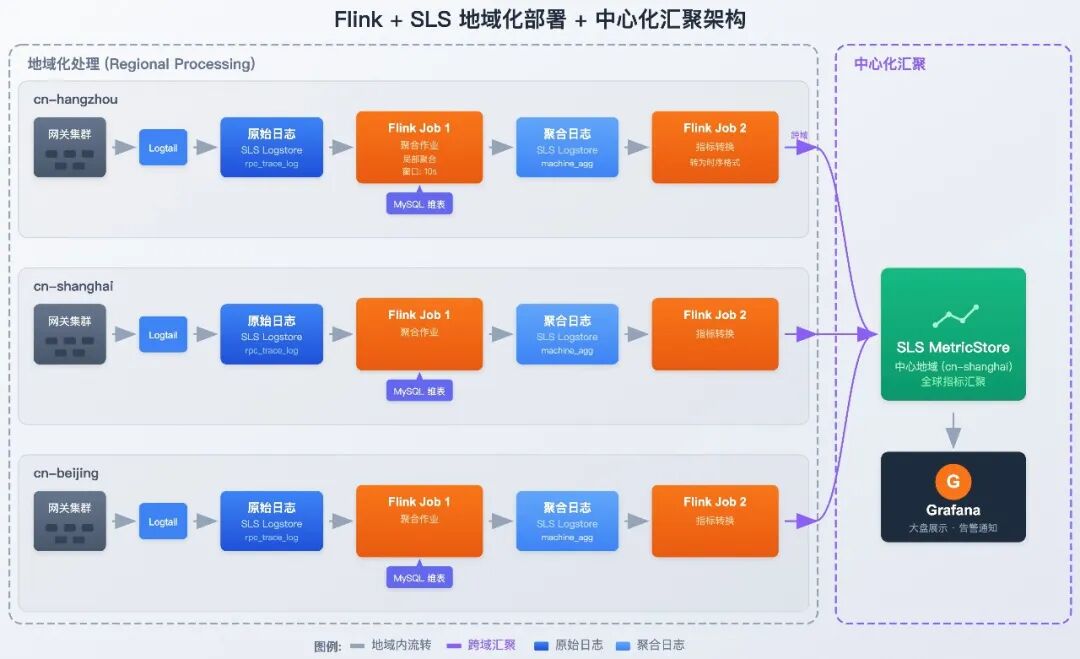
整个数据处理链路采用地域化部署 + 中心化汇聚的架构设计,各地域内独立完成日志采集与聚合计算,实现就近处理、降低延迟;最终将轻量化指标跨域汇聚至中心 MetricStore,实现全局统一监控。
地域内处理(Regional Processing)
每个地域独立部署完整的数据处理链路,实现就近计算、降低延迟:
- 数据采集:由 Logtail 实时采集本地域网关节点日志。Logtail 是阿里云自研的高性能日志采集 Agent,具备毫秒级延迟和百万级 EPS 吞吐能力,确保海量日志的可靠传输。
- 日志存储:各地域的 SLS Logstore 存储本地域 OpenAPI 的原始访问日志,支持对请求明细的实时查询与分析,同时作为 Flink 流计算的数据源。
- 流式聚合计算:各地域独立部署 Flink Job 1(聚合作业),关联 MySQL 维表(存储网关机器的集群信息、API 业务域如 ECS 等元数据),进行局部维度的业务指标汇总。地域内处理可大幅减少跨域传输的数据量。
跨地域汇聚(Cross-Region Aggregation)
多个地域的聚合结果统一写入中心化的 MetricStore,实现全局视图:
- 指标汇聚:各地域独立部署的 Flink Job 2(指标转换) 将聚合结果转为时序指标格式,统一跨域推送到中心地域的 SLS MetricStore。通过汇聚设计,运维团队可在单一视图查看全球所有地域的指标。
- 可视化与告警:基于 Grafana 对接中心化的 SLS MetricStore,通过标准 PromQL 实现多维度的指标大盘展示,并配置细粒度告警规则,实现从异常发现到通知的闭环。
分层设计理念
为什么要分两层?核心考虑是平衡实时性与资源效率:

为什么不直接一层聚合?
- 数据倾斜(Data Skew):OpenAPI 流量分布极不均匀,某些大产品(如 ECS)的 QPS 是其他产品的数千倍。如果直接按 Product 进行 GroupBy,会导致特定 Flink Task 出现严重的数据倾斜和状态膨胀。
- 资源效率:通过第一层单机维度的局部聚合,输出到下游的数据量可降低 90% 以上,大幅减轻了全局聚合作业的计算和存储开销。
指标体系设计
我们需要生成的指标体系由 Metric Name(指标名称) 和 Labels(标签) 组成,覆盖以下四个核心维度:
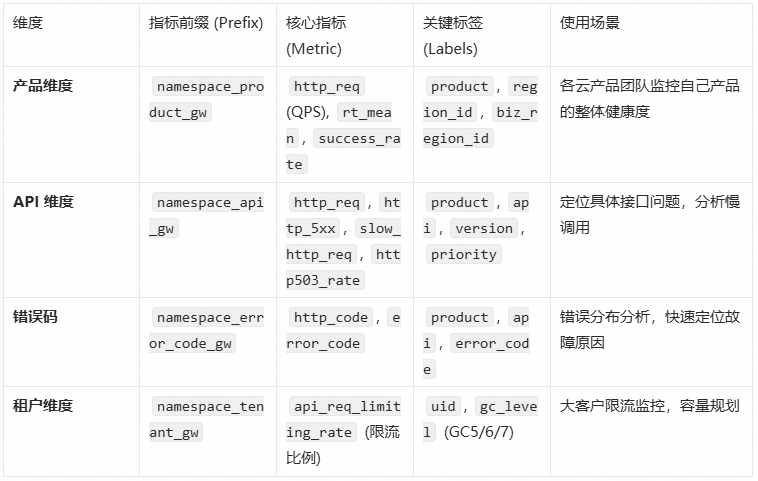
指标命名规范:Prefix_MetricName。例如 ECS 产品的 QPS 指标名为 namespace_product_gw_http_req。
核心作业实践
Job 1:聚合作业
设计意图:消费原始日志,关联 MySQL 维表补充元数据(网关集群信息、API 业务域等),并进行多阶段聚合:先进行细粒度的多维聚合(按产品/API/租户等)以减少下游数据量,再进行全局指标汇总。
1. 数据源:网关原始日志
原始日志由 Logtail 从网关节点采集。以下是一条典型的网关访问日志(已脱敏):
{
"AK": "STS.NZD***Lgwc",
"Api": "DescribeCustomResourceDetail",
"CallerUid": "109837***3503",
"ClientIp": "192.168.xx.xx",
"Domain": "acc-vpc.cn-huhehaote.aliyuncs.com",
"ErrorCode": "ResourceNotFound",
"Ext5": "{\"logRegionId\":\"cn-huhehaote\",\"appGroup\":\"pop-region-cn-huhehaote\",\"callerInfo\":{...},\"headers\":{...}}",
"HttpCode": "404",
"LocalIp": "11.197.xxx.xxx",
"Product": "acc",
"RegionId": "cn-huhehaote",
"RequestContent": "RegionId=cn-huhehaote;Action=DescribeCustomResourceDetail;Version=2024-04-02;...",
"TotalUsedTime": "14",
"Version": "2024-04-02",
"__time__": "1768484243"
}
字段说明:Ext5 包含嵌套的 JSON 结构(调用者信息、请求头等),RequestContent 是 KV 格式的请求参数。这些复杂结构需要在后续处理中解析。
基于上述日志结构,我们定义 Flink Source 表:
CREATE TABLE openapi_log_source (
`__time__` BIGINT,
LocalIp STRING, -- 网关节点 IP
Product STRING, -- 产品 Code (如 Ecs, RDS)
Api STRING, -- API 名称 (如 DescribeInstances)
Version STRING, -- API 版本
Domain STRING, -- 请求域名
AK STRING, -- AccessKey
CallerUid STRING, -- 调用者 UID
HttpCode STRING, -- HTTP 状态码
ErrorCode STRING, -- 网关错误码
TotalUsedTime BIGINT, -- 请求耗时 (ms)
ClientIp STRING, -- 客户端 IP
RegionId STRING, -- 地域
Ext5 STRING, -- 扩展字段 (嵌套 JSON)
RequestContent STRING, -- 请求参数 (KV 格式)
ts AS TO_TIMESTAMP_LTZ(`__time__` * 1000, 3),
WATERMARK FOR ts AS ts - INTERVAL ‘5’ SECOND
) WITH (
‘connector’ = ‘sls’,
‘project’ = ‘*****’,
‘logstore’ = ‘pop_rpc_trace_log’,
‘endpoint’ = ‘cn-shanghai-intranet.log.aliyuncs.com’
);
Watermark 策略说明:这里设置 ts - INTERVAL ‘5’ SECOND 表示允许最多 5 秒的乱序数据。该值需根据实际业务场景权衡:生产环境中,网关日志通过 Logtail 采集,端到端延迟通常在 2-3 秒内,5 秒的 Watermark 延迟可以覆盖绝大多数场景。对于跨地域同步场景,可适当放宽至 10-15 秒。
2. MySQL 维表:元数据富化
为了满足指标的标签需求(如 app_group, gc_level),需要关联维表:
-- 网关集群信息 (关联 LocalIp)
CREATE TABLE gateway_cluster_dim (
local_ip STRING,
app_group STRING, -- 集群名称
region_id STRING, -- 物理 Region
PRIMARY KEY (local_ip) NOT ENFORCED
) WITH (‘connector’ = ‘jdbc’, ...);
-- 租户等级信息 (关联 Uid)
CREATE TABLE user_level_dim (
uid STRING,
gc_level STRING, -- 客户等级 (GC5/GC6/GC7)
PRIMARY KEY (uid) NOT ENFORCED
) WITH (
‘connector’ = ‘jdbc’,
‘url’ = ‘jdbc:mysql://xxx:3306/dim_db’,
‘table-name’ = ‘user_level’,
‘lookup.cache.max-rows’ = ‘50000’, -- 缓存最大行数
‘lookup.cache.ttl’ = ‘10min’, -- 缓存过期时间
‘lookup.max-retries’ = ‘3’ -- 查询失败重试次数
);
维表缓存策略选择:生产环境中,gateway_cluster_dim 采用 ALL 策略,启动时全量加载并定时刷新;user_level_dim 采用 LRU 策略,缓存 5 万条热点租户数据,TTL 设为 10 分钟以平衡命中率和数据新鲜度。
3. Job 1 输出:写入本地域聚合日志
计算结果写入本地域的 SLS Logstore machine_agg_log,作为中间存储。
-- 定义本地聚合日志存储
CREATE TABLE machine_agg_log_sink (
window_start TIMESTAMP(3),
product STRING,
api STRING,
version STRING,
caller_uid STRING,
region_id STRING,
app_group STRING,
gc_level STRING,
http_code STRING,
error_code STRING,
qps BIGINT,
rt_mean DOUBLE,
slow1s_count BIGINT,
http_2xx BIGINT,
http_5xx BIGINT,
http_503 BIGINT
) WITH (
‘connector’ = ‘sls’,
‘project’ = ‘****’,
‘logstore’ = ‘machine_agg_log’, -- 地域化部署,写入本地域 Logstore
‘endpoint’ = ‘cn-shanghai-intranet.log.aliyuncs.com’ -- 实际部署时替换为各地域 Endpoint
);
-- 执行写入
INSERT INTO machine_agg_log_sink
SELECT
TUMBLE_START(l.ts, INTERVAL ’10’ SECOND),
l.Product, l.Api, l.Version, l.CallerUid, g.region_id, g.app_group, u.gc_level, l.HttpCode, l.ErrorCode,
COUNT(*) as qps,
AVG(CAST(l.TotalUsedTime AS DOUBLE)),
SUM(CASE WHEN l.TotalUsedTime > 1000 THEN 1 ELSE 0 END),
SUM(CASE WHEN l.HttpCode >= ‘200’ AND l.HttpCode < ‘300’ THEN 1 ELSE 0 END),
SUM(CASE WHEN l.HttpCode >= ‘500’ THEN 1 ELSE 0 END),
SUM(CASE WHEN l.HttpCode = ‘503’ THEN 1 ELSE 0 END)
FROM openapi_log_source l
LEFT JOIN gateway_cluster_dim FOR SYSTEM_TIME AS OF l.ts AS g ON l.LocalIp = g.local_ip
LEFT JOIN user_level_dim FOR SYSTEM_TIME AS OF l.ts AS u ON l.CallerUid = u.uid
GROUP BY
TUMBLE(l.ts, INTERVAL ’10’ SECOND),
l.Product, l.Api, l.Version, l.CallerUid, g.region_id, g.app_group, u.gc_level, l.HttpCode, l.ErrorCode;
Job 2:指标转换与跨域汇聚
设计意图:各地域独立部署 Job 2,消费本地域的聚合日志 machine_agg_log,将数据转换为时序格式,并跨域写入中心地域(cn-shanghai)的 MetricStore。
1. 数据源:消费本地聚合日志
CREATE TABLE machine_agg_log_source (
window_start TIMESTAMP(3),
product STRING,
region_id STRING,
-- ... 其他字段同 Sink 定义
WATERMARK FOR window_start AS window_start - INTERVAL ‘5’ SECOND
) WITH (
‘connector’ = ‘sls’,
‘project’ = ‘****’,
‘logstore’ = ‘machine_agg_log’, -- 消费本地域 Logstore
‘endpoint’ = ‘cn-shanghai-intranet.log.aliyuncs.com’
);
2. 目标汇聚:中心化 MetricStore Sink
CREATE TABLE metricstore_sink (
`__time_nano__` BIGINT,
`__name__` STRING,
`__labels__` STRING,
`__value__` DOUBLE
) WITH (
‘connector’ = ‘sls’,
‘project’ = ‘****’, -- 中心化 Project
‘logstore’ = ‘openapi_metrics’, -- 中心化 MetricStore
‘endpoint’ = ‘cn-shanghai-intranet.log.aliyuncs.com’ -- 统一指向中心地域 Endpoint
);
3. 计算与汇聚逻辑
Job 2 将聚合日志进一步汇总(如按 Product 维度)并格式化为 Metric 写入中心。
示例:计算产品维度 QPS 并汇聚
INSERT INTO metricstore_sink
SELECT
UNIX_TIMESTAMP(CAST(TUMBLE_START(window_start, INTERVAL ‘1’ MINUTE) AS STRING)) * 1000000000,
‘namespace_product_gw_http_req’,
CONCAT(‘product=‘, product, ‘|region_id=‘, region_id), -- 保留地域标签,实现全球视角
CAST(SUM(qps) AS DOUBLE)
FROM machine_agg_log_source
GROUP BY TUMBLE(window_start, INTERVAL ‘1’ MINUTE), product, region_id;
架构优势:
- 带宽节省:Job 1 将海量明细日志聚合为少量统计数据(数据量减少 99%),Job 2 仅跨域传输这些轻量级指标,极大降低了专线带宽成本。
- 隔离性:各地域计算独立,单地域故障不影响其他地域及中心监控的写入。
作业配置与调优
为了保障作业的稳定性和数据准确性,生产环境中我们对 Checkpoint 和状态后端进行了专项调优。
Checkpoint 配置与权衡
提供了两种配置策略,需根据业务对数据一致性与服务可用性的偏好进行选择:
策略 A:标准与一致性优先(推荐通用场景)
适用于绝大多数对数据准确性有要求的监控场景。
SET ‘execution.checkpointing.interval’ = ‘60s’; -- 1分钟 Checkpoint
SET ‘execution.checkpointing.mode’ = ‘EXACTLY_ONCE’; -- 精确一次语义
SET ‘execution.checkpointing.timeout’ = ‘10min’;
策略 B:高可用优化配置(本案例生产实践)
在 OpenAPI 网关这种超高并发且对可用性极度敏感的场景下,为了避免 Checkpoint 过于频繁导致的性能抖动,同时又不希望完全牺牲数据可靠性,我们采取了“弱一致性 + 低频打点 + 允许失败”的组合策略:
SET ‘execution.checkpointing.interval’ = ‘180s’; -- 延长至 3 分钟,减少频率
SET ‘execution.checkpointing.mode’ = ‘AT_LEAST_ONCE’; -- 降低 Barrier 对齐开销
SET ‘execution.checkpointing.timeout’ = ‘15min’; -- 放宽超时时间
SET ‘execution.checkpointing.max-concurrent-checkpoints’ = ‘1’;
SET ‘execution.checkpointing.tolerable-failed-checkpoints’ = ‘10’; -- 允许连续失败,不因 CP 失败重启作业
优化思路:

状态后端选择
阿里云实时计算 Flink 版提供了企业级的 GeminiStateBackend,相比开源 RocksDB,它在存算分离架构下针对大状态场景进行了深度优化。针对本案例中“状态大(GB 级)、聚合 Key 多”的特点,我们开启了 KV 分离功能:
SET ‘table.exec.state.backend’ = ‘gemini’; -- 使用企业级 GeminiStateBackend
SET ‘state.backend.gemini.kv.separate.mode’ = ‘GLOBAL_ENABLE’; -- 开启 KV 分离
GeminiStateBackend 核心优势对比:
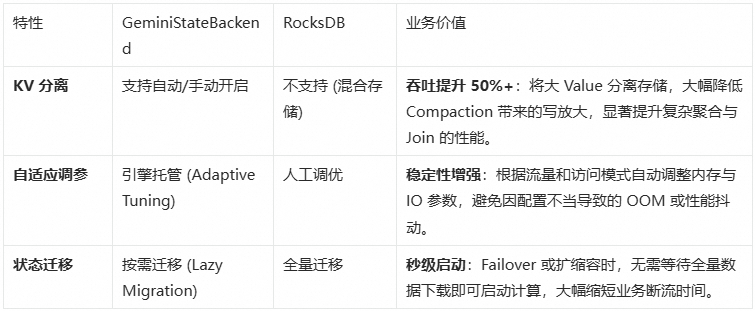
生产建议:对于网关日志聚合这种 State Size 较大且吞吐要求极高的场景,强烈推荐使用 GeminiStateBackend + KV 分离。实测开启后,作业在流量高峰期的 CPU 使用率下降了 20%,且 Checkpoint 耗时更加稳定。
可视化与告警
监控效果展示
通过两个 Flink 作业的聚合,我们在 Grafana 中构建了多维度的 OpenAPI 监控大盘,实现了从产品全局视图到具体错误码的深度下钻。
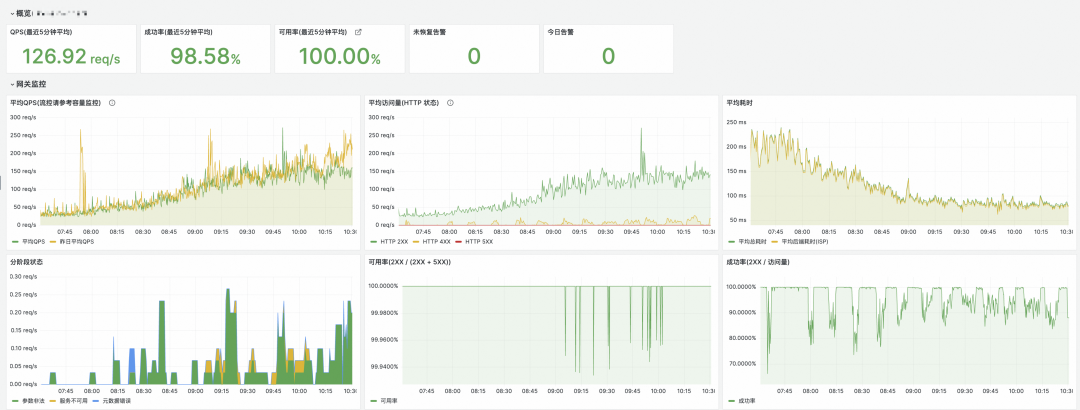
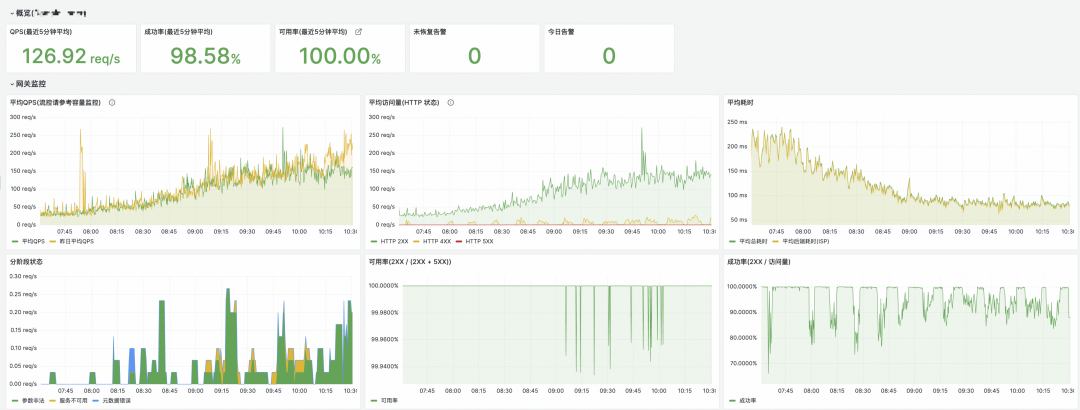
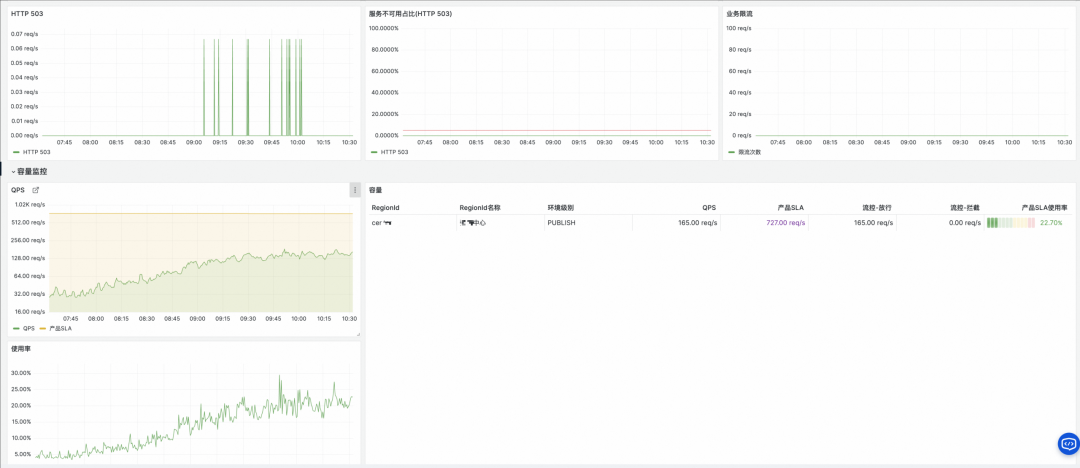
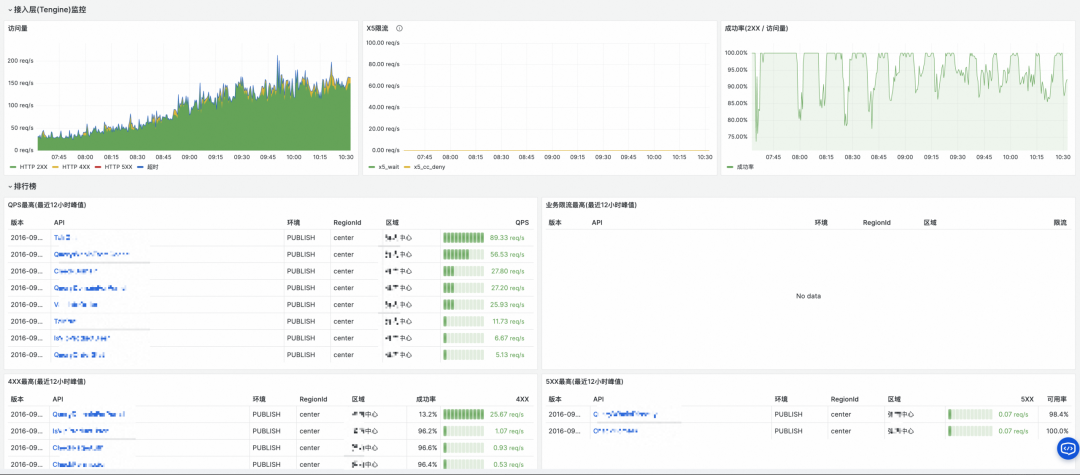
自助查询与告警
在 Grafana 中添加 SLS MetricStore 作为数据源后,各云产品团队可以使用 PromQL 语法自助查询指标并配置告警规则:
常用查询示例:
# QPS 趋势
sum(namespace_product_gw_http_req) by (product)
# 错误率环比(当前 1 分钟与 1 小时前对比)
(
sum(rate(namespace_product_gw_http_5xx[1m])) / sum(rate(namespace_product_gw_http_req[1m]))
) / (
sum(rate(namespace_product_gw_http_5xx[1m] offset 1h)) / sum(rate(namespace_product_gw_http_req[1m] offset 1h))
) > 2
# 平均延迟趋势
avg(namespace_product_gw_rt_mean) by (product)
告警规则示例:
- alert: HighErrorRate
expr: sum(namespace_product_gw_http_5xx) by (product) / sum(namespace_product_gw_http_req) by (product) > 0.01
for: 2m
labels:
severity: warning
annotations:
summary: “{{ $labels.product }} 错误率过高”
description: “当前错误率: {{ $value | printf \"%.2f\" }}%”
各云产品团队可以在 Grafana 中配置自己产品的监控大盘和告警规则,实现自主运维。
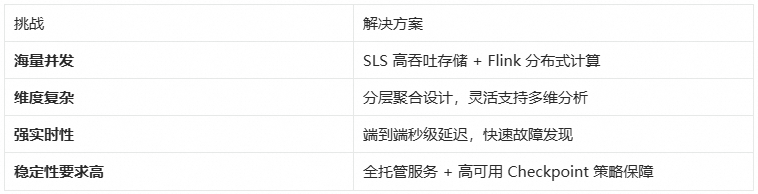
规模化验证
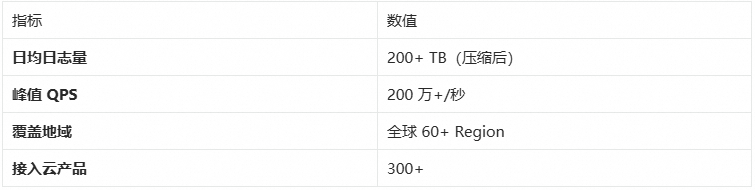
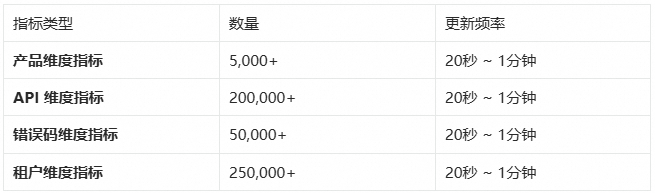
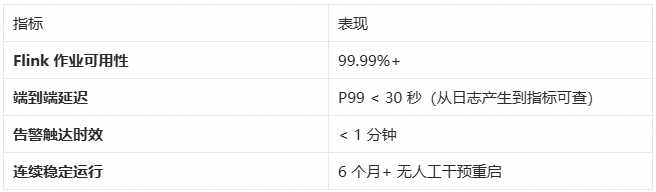
该方案已在阿里云开放平台稳定运行,以下是生产环境的核心指标:

上图展示了系统在生产环境中的核心运行指标。得益于 Flink 的分布式计算能力和 SLS 的高吞吐存储,该方案成功支撑了阿里云开放平台全量 API 调用的实时监控,覆盖 60+ 个全球地域、300+ 个云产品,日均处理 200TB+ 压缩日志(原始日志约 2PB,单条日志约 4-5KB),生成 50 万+ 时序指标。
数据处理规模
指标生成能力
系统稳定性
业务价值
- 故障发现提速:故障发现时间从分钟级缩短到秒级。
- 运维效率提升:300+ 云产品团队实现自助监控配置。
在方案落地过程中,我们发现原始日志包含大量冗余字段和嵌套结构,而指标计算只需其中的核心字段。为此,我们引入了 Source 端谓词下推技术,在数据进入 Flink 之前完成字段裁剪,有效降低了网络传输量并加速了 Flink 计算。
进阶优化:Source 端谓词下推(Predicate Pushdown)
谓词下推概念与 Connector 能力对比
谓词下推(Predicate Pushdown)是数据库和大数据领域的经典优化策略,核心思想是将过滤条件下推到数据源端执行,减少数据传输量和计算开销。
Flink 的下推能力取决于 Source Connector 的实现:
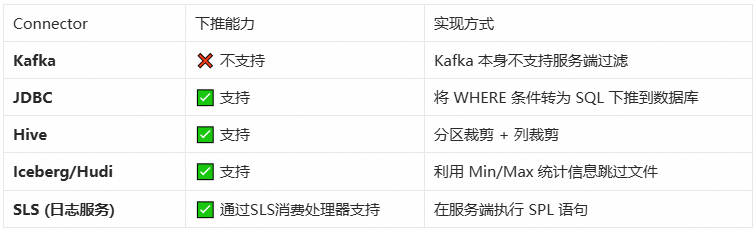
SLS 消费处理器:一种 Source 端下推实现
早期版本的 Flink SLS Connector 会默认全量拉取 SLS Logstore 的数据,但实际上很多字段是不需要的。借助SLS 消费处理器,我们实现了真正的 Source 端谓词下推——过滤和转换逻辑在 SLS 服务端执行,Flink 只接收处理后的结果。
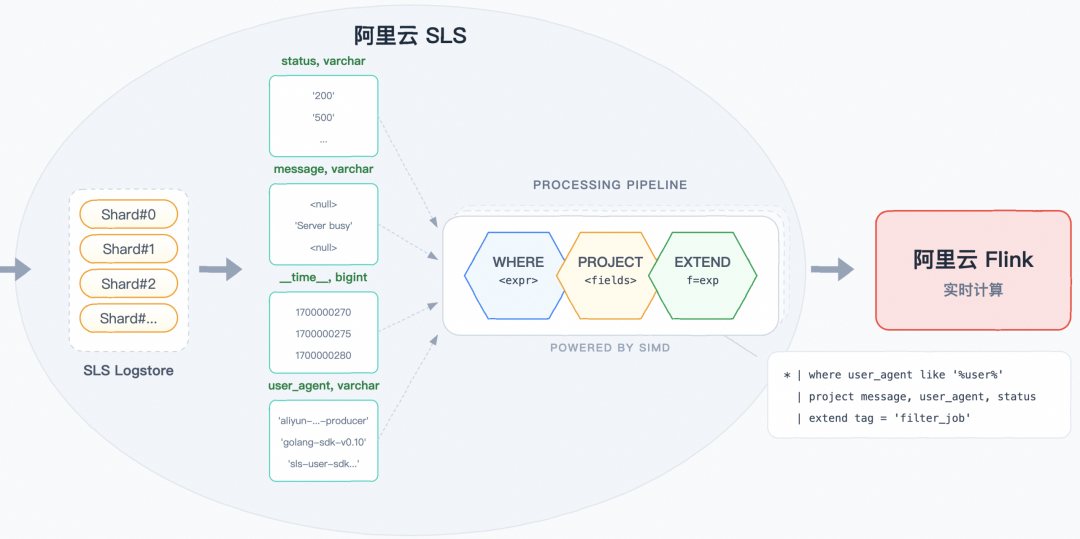
技术优势:
- SIMD 向量化引擎:SPL 底层采用向量化执行引擎,利用 CPU SIMD 指令集(如 AVX2/AVX-512)批量处理数据,相比逐行处理性能提升数倍。
- 同机房本地计算:数据处理在 SLS 存储节点本地完成,无需跨网络传输原始数据,避免了网络 I/O 成为瓶颈。
- 列式存储加速:SLS 底层采用列式存储,配合
project 列裁剪,只读取必要的列数据,大幅减少磁盘 I/O。
- 零拷贝传输:处理后的数据直接进入消费通道,减少内存拷贝开销。

计费提示:
SPL 配置示例
基于前文介绍的网关日志结构,我们通过 SPL 消费处理器实现 Source 端过滤。对比传统的 Flink 侧过滤:
-- 传统方式:Flink 侧过滤(需拉取全量数据)
SELECT * FROM openapi_log_source
WHERE Domain != ‘popwarmup.aliyuncs.com’
AND JSON_VALUE(Ext5, ‘$.logRegionId’) NOT IN (‘cn-shanghai’, ‘cn-beijing’)
使用 SPL 消费处理器后,过滤和转换在 SLS 服务端完成:
-- 1. 行过滤:排除无效数据
*
| where Domain != ‘popwarmup.aliyuncs.com’
-- 2. 嵌套 JSON 分层展开(只对有效数据执行)
| parse-json -prefix=‘ext5_’ Ext5
| where ext5_logRegionId not in (‘cn-shanghai’, ‘cn-beijing’, ‘cn-hangzhou’)
| parse-json -prefix=‘callerInfo_’ ext5_callerInfo
| parse-json -prefix=‘headers_’ ext5_headers
-- 3. 正则提取 KV 格式字段
| parse-regexp RequestContent, ‘[;]RegionId=([^;]*)’ as request_regionId
-- 4. 列裁剪:只保留必要字段(放在最后,减少输出数据量)
| project LocalIp, Product, Version, Api, Domain, ErrorCode, HttpCode,
TotalUsedTime, AK, RegionId, ClientIp,
callerInfo_callerType, callerInfo_callerUid, callerInfo_ownerId,
ext5_regionId, ext5_appGroup, ext5_stage, request_regionId
在 Flink SLS Source 中引用
在 Flink SQL 中,通过 processor 参数引用预先配置好的消费处理器:
CREATE TABLE openapi_log_source (
`__time__` BIGINT,
-- SPL 处理后的字段(已展开嵌套 JSON、已裁剪冗余列)
LocalIp STRING,
Product STRING,
Version STRING,
Api STRING,
Domain STRING,
ErrorCode STRING,
HttpCode STRING,
TotalUsedTime BIGINT,
AK STRING,
RegionId STRING,
ClientIp STRING,
callerInfo_callerType STRING, -- 从 Ext5.callerInfo 展开
callerInfo_callerUid STRING,
callerInfo_ownerId STRING,
ext5_regionId STRING, -- 从 Ext5 展开
ext5_appGroup STRING,
ext5_stage STRING,
request_regionId STRING, -- 从 RequestContent 正则提取
ts AS TO_TIMESTAMP_LTZ(`__time__` * 1000, 3),
WATERMARK FOR ts AS ts - INTERVAL ‘5’ SECOND
) WITH (
‘connector’ = ‘sls’,
‘project’ = ‘****’,
‘logstore’ = ‘pop_rpc_trace_log’,
‘endpoint’ = ‘cn-shanghai-intranet.log.aliyuncs.com’,
‘processor’ = ‘openapi-processor’ -- 引用消费处理器,实现过滤下推
);
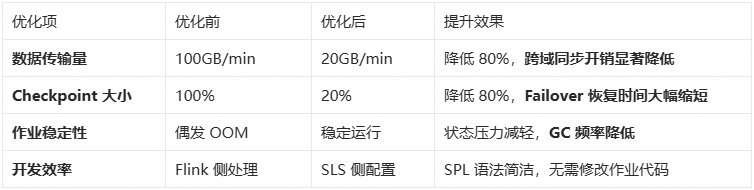
优化效果
通过 SPL 源头预处理,我们在以下几个维度取得了显著提升:
总结
通过 Flink + SLS 的云原生组合,我们成功构建了阿里云 OpenAPI 网关的实时监控体系:
Flink 核心技术要点
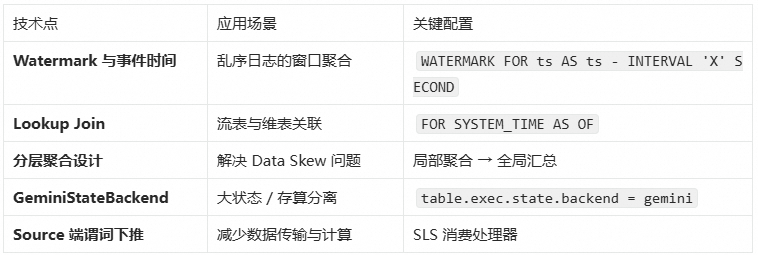
架构设计启示
- 分层聚合缓解数据倾斜:流量分布不均时,先按物理节点局部聚合,再按业务维度全局汇总。
- 谓词下推降低成本:将过滤逻辑下推到 Source 端(如 SLS 消费处理器),减少网络传输和计算资源消耗。
- 选择企业级状态后端:大状态场景选用 GeminiStateBackend + KV 分离,显著提升 I/O 效率与作业稳定性。
本案例的技术方案可推广至微服务调用链监控、CDN 日志分析、物联网数据聚合等类似场景。对于希望深入了解实时数据处理与监控体系搭建的开发者,可以访问云栈社区的大数据或智能 & 数据 & 云板块,获取更多关于云原生技术的实践分享和深度解析。
 发表于 2026-4-1 01:23:50
|
查看: 149|
回复: 0
发表于 2026-4-1 01:23:50
|
查看: 149|
回复: 0
