本文将分享我在学习强化学习过程中,对基于 GRPO 算法的完整计算流程的理解。重点是搞清楚从采样到参数更新的每个环节究竟发生了什么,而不是讨论特定算法的理论优劣。
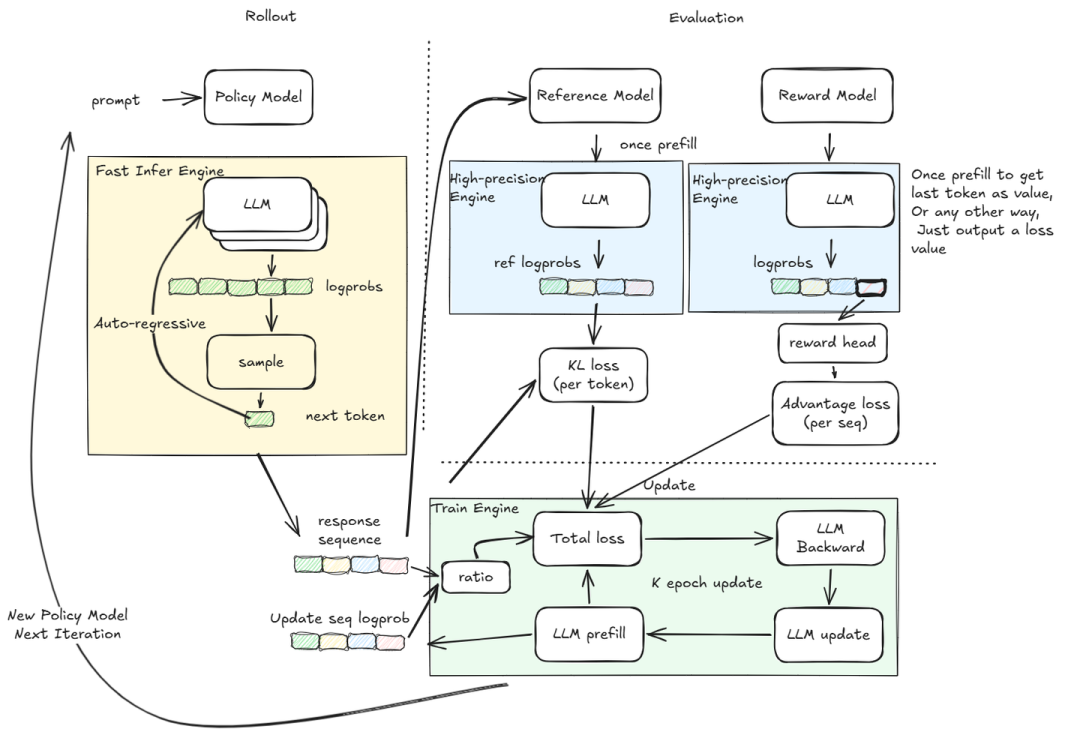
RL 系统非常庞大,不同阶段有不同的计算模式与计算需求,因此需要适配不同的计算框架,主要分为三类:
- Infer Engine:主要用于采样阶段。需要快速完成自回归推理得到完整回答序列,只关心最终 token 的生成。可以采用高效的推理引擎,比如 vLLM 或 SGLang。
- High‑precision Engine:主要用于 loss 计算的阶段。这里只做向前计算(且仅做 prefill),因为涉及 loss 的计算,要求较高的数值精度。常见的推理引擎为了提升效率会做很多融合与加速,其行为与训练引擎差异较大,所以通常直接使用训练框架执行 prefill。
- Train Engine:主要用于参数更新阶段。需要反向传播和 optimizer.step(),因此需要一个完整的分布式训练框架,如 Megatron‑LM 或 DeepSpeed。
一、整体循环流程
大模型 RL 训练本质上是一个循环:让模型自己生成回答 → 评估回答的好坏 → 根据评估结果更新模型参数。每一轮循环包括三个阶段。
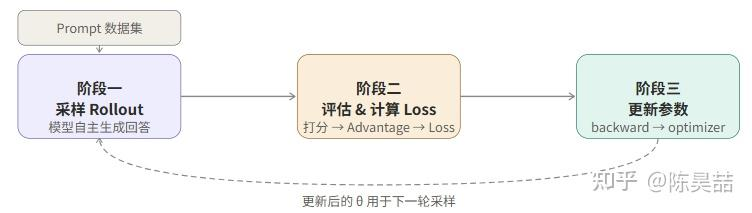
每一轮处理一批 prompt,对每个 prompt 独立采样 G 条回答(G 称为 group size,这是 GRPO 的核心结构),完成评估和参数更新后,用新参数进入下一轮。这个循环会执行成千上万次,直到收敛。
阶段一:采样(Rollout)
采样阶段的任务很直接:给模型一批 prompt,让它自己生成完整的回答。
按 GRPO 的设计,对同一个 prompt 不只会生成一条回答,而是独立采样 G 条。这 G 条回答构成一个“组”,是后续计算 Advantage 的基础单元。
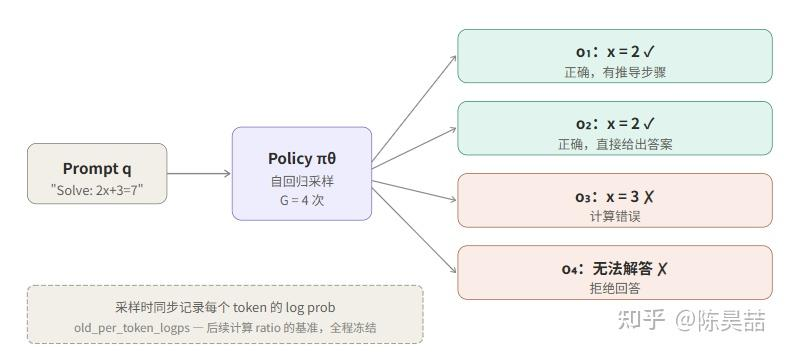
整个采样流程就是一次标准的自回归迭代推理,因此可以直接使用成熟的推理框架(如 vLLM、SGLang)来加速。唯一需要特别留意的点是:
采样过程中会顺带产生一个重要副产品——模型在自回归生成每个 token 时,先输出一整组 logits 向量,选取目标 token 后,同步记录下该 token 对应的 log probability,这就是后续计算中关键的 old_per_token_logps。这个记录无需任何额外计算,但在 loss 计算中至关重要。
# 采样时顺手存下每个 token 的 log prob
with torch.no_grad():
logits = model(input_ids)
log_probs = F.log_softmax(logits, dim=-1)
# 只取被实际选中的那个 token 的概率(标量,非整个词表向量)
old_log_prob = log_probs.gather(-1, next_token.unsqueeze(-1))
old_per_token_logps.append(old_log_prob)
阶段二:评估结果,计算 Loss
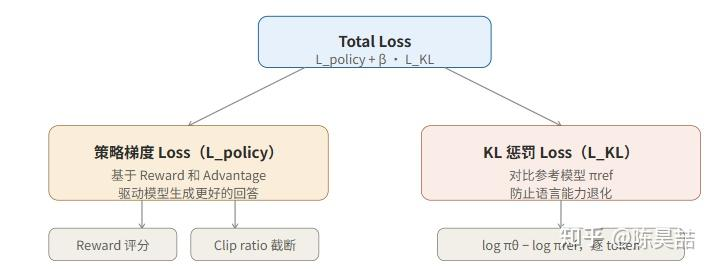
采样结束后,需要对每条回答进行评价,并计算用于反向传播的 loss。整体 loss 由两部分组成:

Reward 的计算
Reward 是对整条 response 给出的一个标量,回答“这条输出有多好”。两种主要的实现方式:
方式一:规则型 reward(verifiable reward)
适用于有客观答案的任务(数学、代码等),无需训练额外模型,直接通过程序判断即可。
def accuracy_reward(completions, solutions):
rewards = []
for completion, sol in zip(completions, solutions):
# 从文本中提取答案,直接做字符串/数值比对
match = re.search(r'<answer>(.*?)</answer>', completion)
reward = 1.0 if (match and match.group(1).strip() == sol) else 0.0
rewards.append(reward)
return rewards # 一个标量列表,每条 response 对应一个分数
方式二:Value Head reward model
适用于主观偏好任务(helpful、harmless 等)。在预训练模型之上添加一个线性层,把最后一个 token 的 hidden state 压缩成标量。
class RewardModel(nn.Module):
def __init__(self, base_model):
self.transformer = base_model
# 额外加一个 hidden_size → 1 的线性层(value head)
self.value_head = nn.Linear(base_model.config.hidden_size, 1, bias=False)
def forward(self, input_ids, attention_mask):
hidden = self.transformer(input_ids, attention_mask).last_hidden_state
# 取最后一个有效 token 的 hidden state
# 原因:causal attention 让最后一个 token 看到了整个序列
last_idx = attention_mask.sum(dim=1) - 1
last_hidden = hidden[torch.arange(len(input_ids)), last_idx]
return self.value_head(last_hidden).squeeze(-1) # 输出标量
Reward model 训练时使用的是 Bradley‑Terry pairwise ranking loss,而不是交叉熵:
# 给定同一 prompt 的两个回答,让 chosen 的分数高于 rejected
loss = -F.logsigmoid(reward_chosen - reward_rejected)
关键区别:reward model 不预测下一个 token,不使用 logits 计算概率分布;它只是把整条 response 映射成一个标量分数。这个标量来自最后一个 token 的 hidden state 经过线性变换,而非词表 logits。
无论采用哪种方式,最终得到的 reward 是一个与 response 数量相同的标量列表。
从标量 reward 到 token‑level advantage
得到的 reward 是对整条回答的评价,需要把它应用到回答中的每一个 token 上。具体如何广播由算法设计决定。
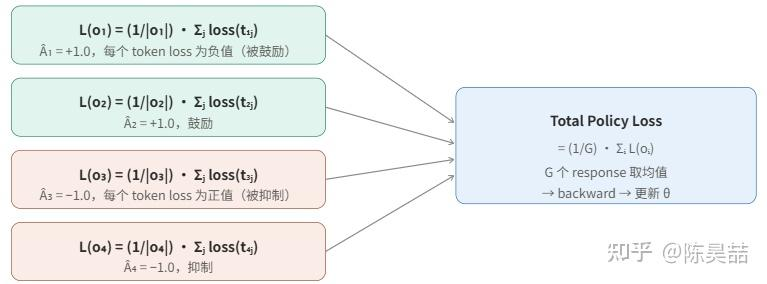
在 GRPO 中,得到 G 个 reward 标量后,通过组内归一化将其转换成每条 response 的 Advantage:
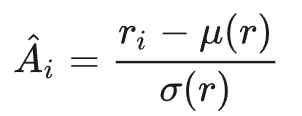
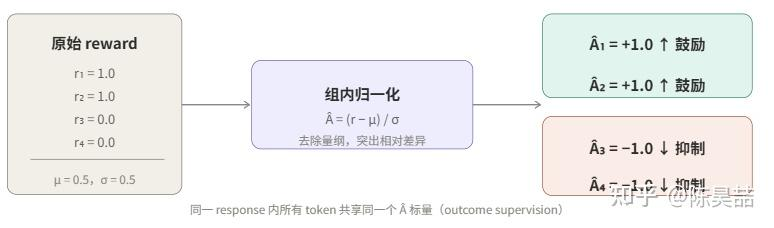
Advantage 的含义:正值表示这条 response 比同组平均更好,其对应 token 的生成概率应该被提高;负值表示低于平均,应该被抑制。
二、KL 惩罚 Loss
KL 惩罚项的作用是防止模型在追求 reward 的过程中丧失原有的语言能力。它通过对比当前策略 πθ 与参考模型 πref(通常是 SFT 之后的初始模型)在每个 token 上的概率差异来工作。
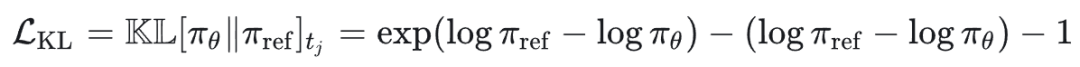
这里使用的是 Schulman 的 k2 近似(low‑var KL),计算公式为 per‑token:
# verl/trainer/ppo/core_algos.py: kl_penalty()
# ref_log_prob, log_prob 均为 shape (batch, seq_len) 的 2D tensor
def kl_penalty(log_prob, ref_log_prob, kl_type="low_var_kl"):
if kl_type == "kl": # k1:最简单,E[logπ - logπref]
return log_prob - ref_log_prob
elif kl_type == "mse": # k2:方差更小
return (log_prob - ref_log_prob) ** 2 * 0.5
elif kl_type == "low_var_kl": # k3:verl GRPO 默认,更稳定
kl = ref_log_prob - log_prob
return torch.exp(kl) - kl - 1
KL 惩罚有两种加入方式:
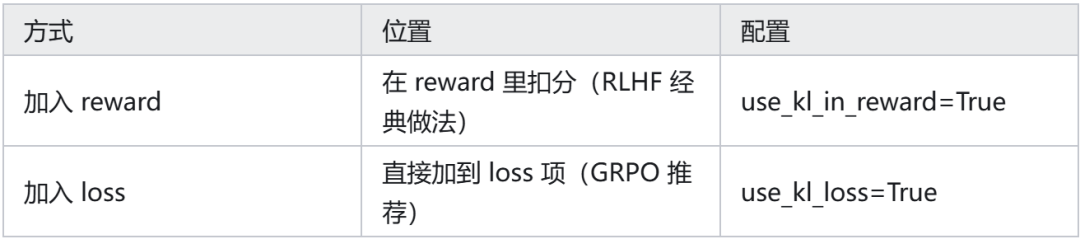
GRPO 推荐将 KL 直接加到 loss 中(use_kl_loss=True),因为逻辑更清晰:KL 是正则化,属于 loss 的一部分,而非 reward 的组成部分。
三、Per‑token Loss 的细节
这是整个计算流程中最精密的部分。Loss 不是对整条 response 计算一个数字,而是对 response 里的每一个 token 单独计算。
为什么 loss 必须是 per‑token 的?
语言模型的参数更新本质上是调整“在特定上下文下,生成某个 token 的概率”。所以梯度信号必须精确到每个 token:哪些 token 的生成概率应该提高,哪些应该降低。
每个 token 的 loss 计算核心是 Importance Sampling Ratio(重要性采样比):
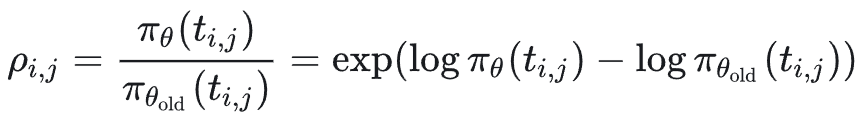
这里要回答一个关键问题:模型在每个位置输出的是整个词表(如 20000 维)的概率分布,loss 用到的是哪一维?
答案是:只取被实际选中的那个 token 对应的概率,它是一个标量,而不是整个分布向量。
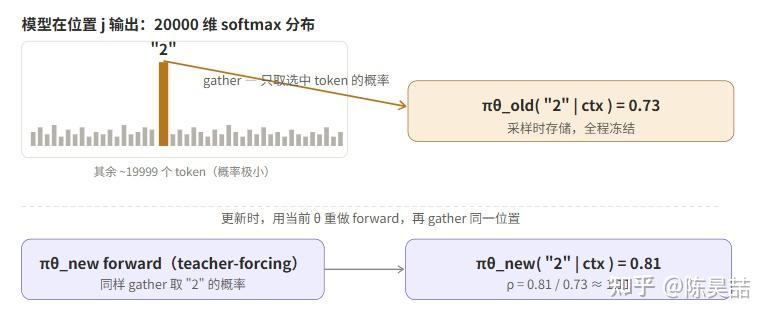
在代码层面,这通过 gather 实现,对应 verl 中的 selective_log_softmax:
# verl/trainer/ppo/core_algos.py 及 dp_actor.py 中的实现
logits = model(input_ids, attention_mask).logits # (B, L, vocab_size)
logits = logits[:, :-1, :] # 去掉最后一个预测位
# 关键:只算实际生成的那些 token 的 log prob,不是整个词表
log_probs = selective_log_softmax(logits, input_ids)
# 等价于:log_softmax(logits).gather(-1, input_ids.unsqueeze(-1)).squeeze(-1)
# 结果 shape:(batch_size, response_length) — 这是一个 2D 矩阵
输出是 (batch_size, response_length) 的二维矩阵,每个位置存放对应 token 的 log prob 标量。这就是 per‑token 的直接体现。
完整的 per‑token loss 计算过程:
# verl/trainer/ppo/core_algos.py: compute_policy_loss()
# Step 1: ratio,shape (batch, seq_len) 的 2D tensor
negative_approx_kl = log_prob - old_log_prob # 逐 token 做差
negative_approx_kl = torch.clamp(negative_approx_kl, -20.0, 20.0) # 数值稳定
ratio = torch.exp(negative_approx_kl) # ρ,仍然 2D
# Step 2: 两个候选 loss,都是 2D
pg_losses1 = -advantages * ratio # 未截断
pg_losses2 = -advantages * torch.clamp(ratio, 1 - ε, 1 + ε) # 截断后
# Step 3: 取较大值(更保守的更新)→ 仍然 2D
pg_losses = torch.maximum(pg_losses1, pg_losses2)
# Step 4: 用 mask 过滤 padding,再折叠成标量
pg_loss = agg_loss(pg_losses, response_mask, loss_agg_mode)
agg_loss 如何把 2D 矩阵折叠成标量?
# 默认 token-mean:所有有效 token 等权平均
if loss_agg_mode == "token-mean":
loss = masked_mean(loss_mat, loss_mask) # 忽略 padding,所有 token 求均值
# 原始 GRPO 论文:先在序列内按 token 数平均,再在序列间平均
elif loss_agg_mode == "seq-mean-token-mean":
seq_losses = loss_mat.sum(-1) / loss_mask.sum(-1) # 每条序列内均值
loss = seq_losses.mean() # 序列间均值
# DrGRPO:用全局固定常数归一化,消除长度偏差
elif loss_agg_mode == "seq-mean-token-sum-norm":
loss = (loss_mat * loss_mask).sum() / loss_mask.shape[-1]
阶段三:参数更新
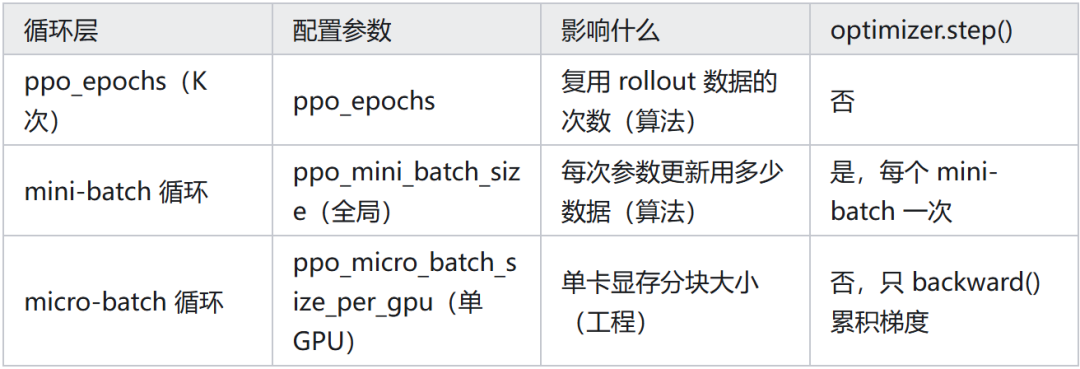
得到标量 loss 之后,就可以通过标准的反向传播更新模型参数。在实现层面,需要理解一个三层嵌套的循环结构。

三层循环的本质区别:
“新旧策略”是什么?
更新循环里有容易混淆的概念:“新策略”和“旧策略”不是两个不同的模型,而是同一模型在不同时刻的参数状态。
- πθ_old(旧策略):采样那一刻的参数快照,体现为
old_per_token_logps(冻结,不随更新变化)。
- πθ(新策略):当前正在被梯度更新的参数,体现为每次 forward 动态计算的
per_token_logps。
每执行一次 optimizer.step(),θ 就会变化一点,ratio ρ = πθ_new / πθ_old 也会偏离 1 一点。clip 操作(把 ratio 限制在 [1-ε, 1+ε])正是为了防止这个偏差在 K 次更新内累积过多,导致 importance sampling 的修正失效。
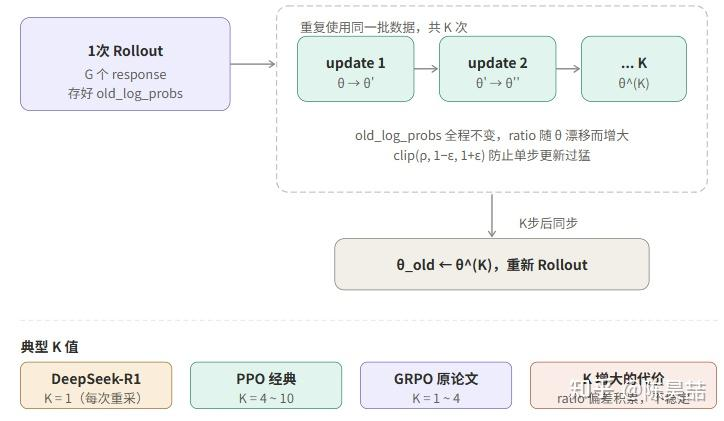
老策略 log prob 的来源
old_per_token_logps 是采样阶段的副产品(在阶段一中顺手记录的),不需要额外的 forward pass。而 per_token_logps 则在每次梯度更新时用当前参数重新计算(通过 teacher‑forcing 模式,一次 forward 即可得到全部位置的 log prob,而非自回归)。
四、核心要点总结
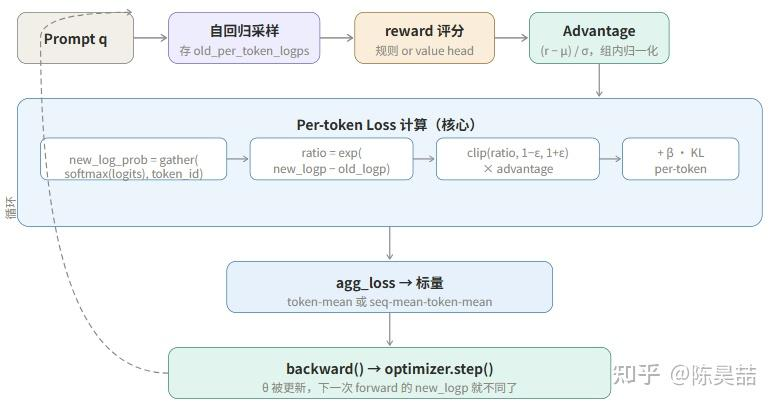
- Loss 是 per‑token 的,不是 per‑sequence 的。
模型输出 20000 维词表分布,loss 通过 gather 只取被选中那个 token 的概率标量。每个 token 独立计算 ratio 和 clip loss,最终 shape 为 (batch, seq_len) 的二维矩阵,再由 agg_loss 折叠成标量。
old_per_token_logps 是采样时的副产品,全程冻结。
它在自回归采样时顺手记录,不需要额外 forward pass。更新阶段动态计算的 per_token_logps 随 θ 变化,两者的差的指数就是 ratio ρ。- Reward model 输出标量,不是 token 概率。
规则型 reward 直接从文本内容计算;value head reward model 取最后一个 token 的 hidden state 经线性变换得到标量,都不涉及词表 logits。
- Advantage 是组内相对归一化的结果,同一 response 内所有 token 共享同一个 Advantage 标量。
(r − μ)/σ 消除了 reward 的量纲影响,只保留“比同组平均好多少”的信号。
- Clip 操作防止单次更新幅度过大。
min(ratio × A, clip(ratio, 1-ε, 1+ε) × A) 将 ratio 限制在 [1-ε, 1+ε] 内(通常 ε=0.2),这是 importance sampling 修正假设成立的前提。
- mini‑batch 与 micro‑batch 是两个不同维度的概念。
mini‑batch 决定算法行为(每次 optimizer.step() 使用的数据量);micro‑batch 是工程优化(单卡显存切分),只影响吞吐量,不改变算法结果。
五、完整 Loss 公式
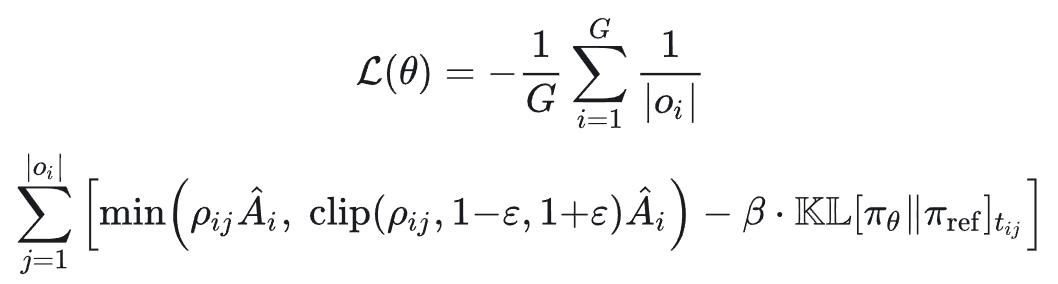
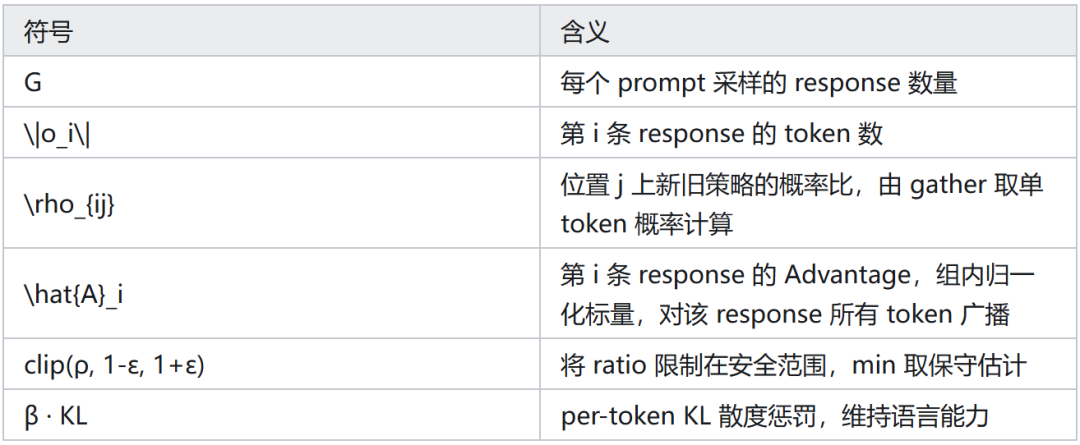
以上便是大模型 RL 训练中计算流程的详细拆解,理解 per‑token loss 机制对深入掌握强化学习优化至关重要。更多技术探讨欢迎来 云栈社区 交流。
 发表于 2026-4-29 04:18:45
|
查看: 347|
回复: 0
发表于 2026-4-29 04:18:45
|
查看: 347|
回复: 0
