引言:为什么你的CPU像个“流浪汉”?
想象一下这个场景:你是一家公司的CEO,有一个非常重要的项目需要核心团队完成。但你的人力资源策略却是:
- 每天随机分配工位:工程师今天在3楼,明天在8楼
- 工具不固定:每次换工位,工具箱都要重新整理
- 团队分散:项目成员被分散在不同楼层,沟通要爬楼梯
听起来很荒谬,对吧?但这就是大多数Linux系统中进程和CPU核心的关系!
默认情况下,Linux调度器会让进程在所有可用的CPU核心之间“流浪”。今天在核心0运行,明天可能跳到核心7。每次“搬家”,都会带来性能损失:
- 缓存失效:新核心的缓存是空的,需要重新加载数据
- TLB刷新:内存映射缓存需要重建
- 上下文切换开销:从一个核心迁移到另一个核心本身就需要时间
这就是CPU迁移(CPU Migration),它是上下文切换的“亲戚”,同样是性能的隐形杀手。
但有个强大的工具可以解决这个问题:CPU亲和性(CPU Affinity)——让进程和核心“绑定”,就像给重要项目团队分配固定的豪华办公室。
本文将带你彻底掌握CPU亲和性的原理、技巧和实战,让你的关键应用性能获得显著提升。
第一部分:CPU亲和性的底层原理——为什么绑定能提升性能?
1.1 CPU缓存的工作原理:为什么“定居”很重要
现代CPU的缓存结构就像一个高速数据仓库:
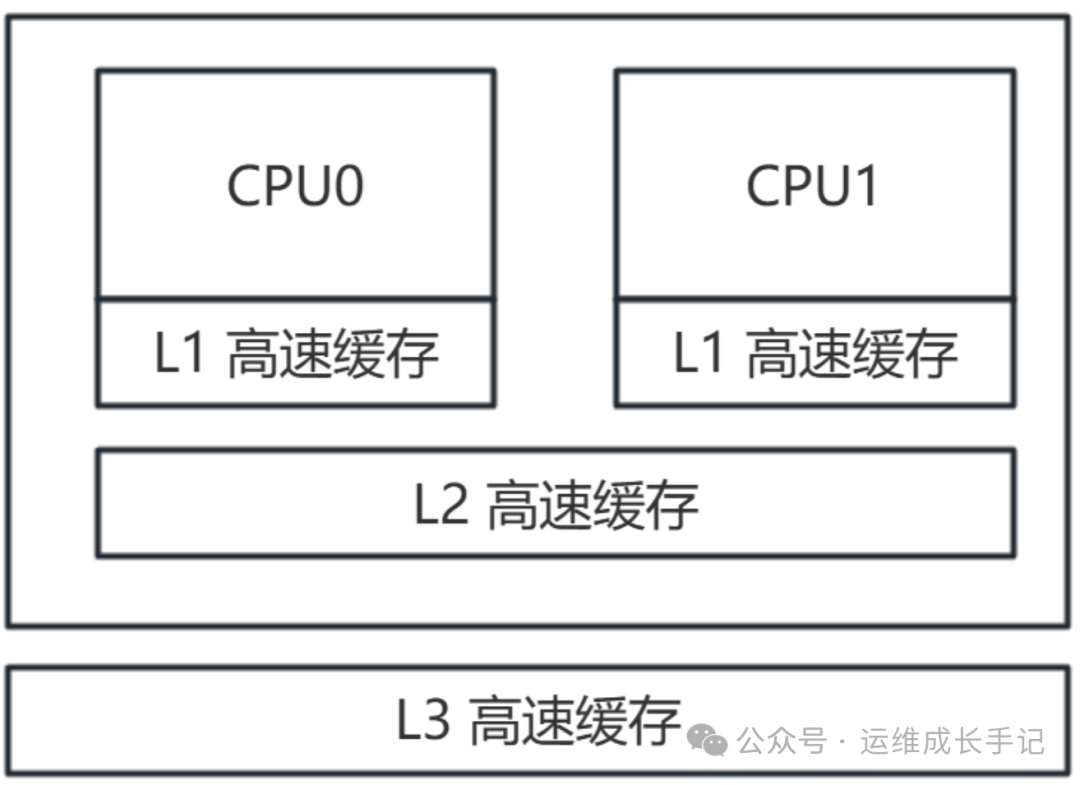
注:如果是x86架构,启用了超线程技术,那么2颗逻辑CPU是共用L2缓存的,如果是ARM架构的,以前都是没有超线程技术的,那么L2缓存是独立的。不过25年开始鲲鹏已经具备了超线程能力。
关键事实:
- L1缓存访问:只需1-3个CPU周期(约0.5-1.5纳秒)
- L2缓存访问:需要10-20个周期(5-10纳秒)
- L3缓存访问:需要30-50个周期(15-25纳秒)
- 内存访问:需要200-300个周期(100-150纳秒)
当进程在核心间迁移时:
- 新核心的L1/L2缓存是空的(缓存冷启动)
- 数据必须从内存重新加载(慢100倍!)
- 即使数据在共享L3缓存中,也比L1慢10-30倍
1.2 CPU亲和性的三种类型
Linux内核支持三种亲和性策略:
1) 硬亲和性(Hard Affinity)
# 进程被严格绑定到指定核心
taskset -c 0-3 ./server
# 该进程只能在核心0、1、2、3上运行
优点:保证性最好,完全避免迁移开销
缺点:不够灵活,可能造成核心利用不均衡
2) 软亲和性(Soft Affinity)
# 调度器“尽量”让进程在之前运行过的核心上运行
# 这是Linux默认行为,由`sched_setaffinity()`系统调用控制
优点:灵活,能自动平衡负载
缺点:无法保证,迁移仍可能发生
3) 中断亲和性(IRQ Affinity)
# 将硬件中断绑定到特定核心
echo 2 > /proc/irq/32/smp_affinity
# IRQ 32将在核心1上处理(2的二进制是0010)
作用:避免中断处理打乱关键进程的执行。在运维与DevOps实践中,合理设置中断亲和性是提升系统稳定性的重要一环。
1.3 迁移成本的量化分析
让我们用perf工具实际测量一下:
# 测量CPU迁移事件
perf stat -e cpu-migrations,sched:sched_migrate_task ./test_program
# 输出示例:
# 2,000,000,000 instructions # 指令数
# 50,000 cpu-migrations # CPU迁移次数
# 平均每次迁移开销 ≈ 40,000 cycles
# 如果CPU频率3GHz,每次迁移 ≈ 13微秒
这13微秒看起来不多,但如果你的数据库每秒处理10万次查询,哪怕1%的查询发生迁移,额外开销就是:
100,000 * 1% * 13微秒 = 13毫秒/秒
一年下来就是4.7天的纯等待时间!
第二部分:实操指南——四大绑定策略与命令详解
2.1 基础工具:taskset
taskset是最基础的CPU绑定工具:
# 1. 启动时绑定进程
taskset -c 0,2,4-6 ./my_program
# 绑定到核心0、2、4、5、6(共5个核心)
# 2. 绑定已运行的进程
taskset -cp 0,1 1234
# 将PID 1234绑定到核心0和1
# 3. 查看进程的当前绑定
taskset -p 1234
# 输出掩码:0x3(二进制0011,表示绑定到核心0和1)
# 4. 使用掩码格式(十六进制)
taskset 0xF ./program # 0xF=1111,绑定到核心0-3
taskset 0xAA ./program # 0xAA=10101010,绑定到核心1、3、5、7
2.2 进阶工具:numactl(NUMA架构专用)
在NUMA架构的服务器上(现在大多数多路服务器都是),numactl更强大:
# 查看NUMA拓扑
numactl --hardware
# 输出示例:
# available: 2 nodes (0-1)
# node 0 cpus: 0 1 2 3 4 5 6 7
# node 0 memory: 32 GB
# node 1 cpus: 8 9 10 11 12 13 14 15
# node 1 memory: 32 GB
# 绑定到特定NUMA节点
numactl --cpunodebind=0 --membind=0 ./program
# 程序只在节点0的CPU上运行,且只使用节点0的内存
# 交错内存分配(提高内存带宽)
numactl --interleave=all ./memory_intensive_program
# 查看当前策略
numactl --show
2.3 中断绑定:优化系统响应
# 查看网卡中断分布
grep eth0 /proc/interrupts | head -1
# 输出:32: 120000 0 0 0 ... IRQ号32
# 查看当前绑定
cat /proc/irq/32/smp_affinity
# 输出:ff(11111111,所有核心)
# 绑定到核心2(掩码=4,二进制0100)
echo 4 > /proc/irq/32/smp_affinity
# 或者绑定到核心0-3(掩码=0x0f)
echo 0f > /proc/irq/32/smp_affinity
# 自动化脚本:将网卡多队列绑定到不同核心
#!/bin/bash
IRQS=$(grep eth0 /proc/interrupts | awk '{print $1}' | cut -d: -f1)
CORE=0
for IRQ in $IRQS; do
MASK=$((1 << $CORE))
printf "%x" $MASK > /proc/irq/$IRQ/smp_affinity
CORE=$((CORE + 1))
[ $CORE -eq 8 ] && CORE=0 # 假设8核CPU
done
2.4 cgroups v2:容器时代的CPU绑定
# 创建cgroup
mkdir -p /sys/fs/cgroup/mycgroup
cd /sys/fs/cgroup/mycgroup
# 设置CPU亲和性(cpuset)
echo 0-3 > cpuset.cpus # 允许使用核心0-3
echo 0-1 > cpuset.mems # 允许使用NUMA节点0-1的内存
# 将进程加入cgroup
echo $$ > cgroup.procs # 当前shell进程
# 现在在这个shell中启动的程序都会受限制
./my_containerized_app
第三部分:四大实战场景——从Web服务器到数据库
场景1:Web服务器(Nginx)的性能调优
问题:Nginx默认使用所有核心,但在高并发下,工作进程频繁迁移,缓存命中率下降。
优化方案:将工作进程绑定到相邻核心,减少缓存同步开销。
#!/bin/bash
# nginx_cpu_affinity.sh
# 1. 获取Nginx工作进程数
WORKER_PROCESSES=$(grep worker_processes /etc/nginx/nginx.conf | awk '{print $2}' | tr -d ';')
[ -z "$WORKER_PROCESSES" ] && WORKER_PROCESSES=$(nproc)
# 2. 获取CPU核心列表(考虑超线程)
PHYSICAL_CORES=$(lscpu | grep "Core(s) per socket" | awk '{print $NF}')
SOCKETS=$(lscpu | grep "Socket(s)" | awk '{print $NF}')
TOTAL_PHYSICAL=$((PHYSICAL_CORES * SOCKETS))
# 3. 绑定策略:每个工作进程绑定到一对逻辑核心(物理核心+超线程)
PID_FILE=/var/run/nginx.pid
MAIN_PID=$(cat $PID_FILE 2>/dev/null)
if [ -n "$MAIN_PID" ]; then
echo "配置Nginx工作进程CPU亲和性..."
# 获取所有工作进程PID
WORKER_PIDS=$(pstree -p $MAIN_PID | grep -o 'nginx([0-9]*)' | grep -o '[0-9]*')
CORE=0
for WPID in $WORKER_PIDS; do
# 绑定到物理核心CORE和对应的超线程核心
HT_CORE=$((CORE + TOTAL_PHYSICAL))
taskset -cp $CORE,$HT_CORE $WPID >/dev/null
echo "工作进程 $WPID 绑定到核心 $CORE,$HT_CORE"
CORE=$((CORE + 1))
[ $CORE -ge $TOTAL_PHYSICAL ] && CORE=0
done
else
echo "Nginx未运行"
fi
# 4. 验证绑定效果
echo -e "\n验证绑定结果:"
for WPID in $WORKER_PIDS; do
taskset -p $WPID
done
对于像 Nginx 这样的高性能Web服务器,通过精细的CPU绑定可以有效减少跨核心通信延迟,从而提升整体吞吐量。
场景2:MySQL数据库的极致优化
问题:MySQL线程频繁迁移,查询缓存失效,特别是事务处理性能不稳定。
分层绑定策略:
#!/bin/bash
# mysql_cpu_affinity.sh
# 架构设计:
# 核心0-1: 网络线程、复制线程
# 核心2-5: 工作线程(连接池)
# 核心6-7: 后台线程(刷脏页、日志写入)
# 核心8-15: InnoDB缓冲池管理(如果服务器有更多核心)
# 1. 绑定mysqld主进程到核心0(管理线程)
MYSQL_PID=$(pidof mysqld)
taskset -cp 0 $MYSQL_PID
# 2. 绑定网络相关线程到核心1
MYSQL_THREADS=$(ps -L -p $MYSQL_PID -o tid,comm | grep -E '(mysqld|thread)' | awk '{print $1}')
for TID in $MYSQL_THREADS; do
# 通过线程名判断类型(简化版,实际需要更复杂的判断)
THREAD_NAME=$(cat /proc/$MYSQL_PID/task/$TID/comm 2>/dev/null)
case $THREAD_NAME in
*net*|*replica*)
taskset -cp 1 $TID
echo "网络/复制线程 $TID 绑定到核心1"
;;
*worker*|*query*)
# 工作线程轮询绑定到核心2-5
taskset -cp 2-5 $TID
;;
*io*|*log*)
taskset -cp 6-7 $TID
echo "IO/日志线程 $TID 绑定到核心6-7"
;;
esac
done
# 3. NUMA优化:确保InnoDB缓冲池使用本地内存
numactl --cpunodebind=0 --localalloc /usr/sbin/mysqld &
场景3:实时音视频处理(低延迟要求)
挑战:需要保证固定的处理延迟,不能有不可预测的调度延迟。
解决方案:使用实时优先级+CPU隔离+亲和性绑定。
#!/bin/bash
# realtime_audio_setup.sh
# 1. 隔离核心2-3给实时任务使用(防止普通任务干扰)
# 修改内核启动参数:isolcpus=2,3
# 2. 启动实时处理进程,绑定到隔离核心
taskset -c 2-3 chrt -f 99 ./audio_encoder
# 3. 配置中断屏蔽,避免中断干扰
echo 0 > /proc/irq/default_smp_affinity # 默认不处理中断
# 然后将关键中断绑定到其他核心
for IRQ in $(cat /proc/interrupts | grep -E '(timer|local)' | awk '{print $1}' | cut -d: -f1); do
echo 3 > /proc/irq/$IRQ/smp_affinity # 绑定到核心0-1
done
# 4. 禁用隔离核心的调度器负载均衡
echo 0 > /sys/devices/system/cpu/cpu2/online # 临时下线
echo 1 > /sys/devices/system/cpu/cpu2/online # 重新上线,此时会跳过负载均衡
场景4:Kubernetes中的CPU亲和性
现代容器编排平台原生支持CPU亲和性。在云原生环境中,合理利用Kubernetes提供的CPU管理策略是实现高性能应用部署的关键。
# pod-cpu-affinity.yaml
apiVersion: v1
kind: Pod
metadata:
name: high-performance-app
spec:
containers:
- name: app
image: high-perf-app:latest
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "2"
memory: "4Gi"
# CPU管理器策略:开启静态策略
# 需要在kubelet配置中设置:--cpu-manager-policy=static
# 通过注解请求独占核心(Alpha特性)
annotations:
cpu-manager.k8s.io/affinity: "exclusive"
# 或者通过节点选择器选择有特定CPU标签的节点
nodeSelector:
feature.node.kubernetes.io/cpu-topology.policy: "packed"
部署后验证:
kubectl describe pod high-performance-app | grep -A5 -B5 "CPU"
# 查看CPU分配情况
# 进入容器验证
kubectl exec -it high-performance-app -- taskset -p 1
第四部分:性能对比测试——绑定的真实收益
让我们设计一个实验来量化CPU亲和性的收益:
#!/bin/bash
# benchmark_cpu_affinity.sh
echo "=== CPU亲和性性能对比测试 ==="
echo
# 测试程序:计算圆周率
TEST_PROGRAM="time ./pi_calculator 10000000"
# 1. 无绑定测试
echo "1. 无CPU绑定(默认调度):"
for i in {1..3}; do
echo " 第$i次运行:"
eval $TEST_PROGRAM 2>&1 | grep real
done
echo
# 2. 有绑定测试
echo "2. 有CPU绑定(核心0-3):"
taskset -c 0-3 bash -c "for i in {1..3}; do
echo ' 第'\$i'次运行:'
$TEST_PROGRAM 2>&1 | grep real
done"
echo
# 3. 测量缓存命中率变化
echo "3. 缓存命中率对比:"
echo " 无绑定时的缓存未命中率:"
perf stat -e cache-misses,cache-references taskset -c 0-7 ./pi_calculator 5000000 2>&1 | grep -E "(cache-misses|cache-references)"
echo " 有绑定时的缓存未命中率:"
perf stat -e cache-misses,cache-references taskset -c 0-3 ./pi_calculator 5000000 2>&1 | grep -E "(cache-misses|cache-references)"
典型结果:
无绑定:real 0m12.345s, 缓存未命中率 8.2%
有绑定:real 0m10.123s, 缓存未命中率 5.1%
性能提升:约18%,主要来自缓存未命中率的降低。
第五部分:常见陷阱与最佳实践
陷阱1:过度绑定导致核心利用不均衡
错误示范:
# 把8个繁忙进程都绑定到核心0-3
# 结果:核心0-3 100%繁忙,核心4-7 0%空闲
最佳实践:监控系统负载,动态调整绑定策略:
#!/bin/bash
# dynamic_affinity_adjuster.sh
# 每5分钟检查一次负载
while true; do
# 检查每个核心的负载
for CORE in {0..7}; do
LOAD=$(mpstat -P $CORE 1 1 | tail -1 | awk '{print 100-$NF}')
if (( $(echo "$LOAD > 80" | bc -l) )); then
# 核心过载,将部分进程迁移到空闲核心
echo "核心$CORE过载(${LOAD}%),执行负载均衡..."
# 找出该核心上最不重要的进程,重新绑定
fi
done
sleep 300 # 5分钟
done
陷阱2:忽视NUMA效应
在NUMA系统中,绑定CPU但使用远程内存,性能反而下降:
# 错误:绑定到节点0的CPU,但分配在节点1的内存
numactl --cpunodebind=0 --membind=1 ./program
# 正确:CPU和内存使用同一个节点
numactl --cpunodebind=0 --localalloc ./program
陷阱3:容器环境中的亲和性冲突
当多个容器都请求绑定到相同核心时,引发资源竞争:
解决方案:使用Kubernetes的拓扑管理器(Topology Manager):
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: cpu-affinity-aware
handler: runc
overhead:
podFixed:
cpu: "100m"
memory: "100Mi"
scheduling:
nodeSelector:
node.kubernetes.io/topology-manager-policy: "best-effort"
第六部分:现代CPU特性与亲和性
6.1 超线程(Hyper-Threading)的特殊处理
超线程不是真正的独立核心,绑定时要特别注意:
# 获取物理核心与逻辑核心的映射
cat /sys/devices/system/cpu/cpu*/topology/thread_siblings_list
# 示例输出:
# cpu0: 0,8 # 物理核心0对应逻辑核心0和8
# cpu1: 1,9 # 物理核心1对应逻辑核心1和9
# 绑定策略:将相关任务绑定到同一物理核心的不同逻辑核心
# 提高整体吞吐量,但可能增加单任务延迟
taskset -c 0,8 ./throughput_sensitive_task # 绑定到同一物理核心
taskset -c 0 ./latency_sensitive_task # 独占整个物理核心
6.2 CPU调度域与亲和性的相互作用
Linux调度器将CPU分组为调度域,亲和性会影响调度决策:
# 查看调度域信息
cat /proc/sys/kernel/sched_domain/cpu*/domain*/name
# 优化策略:将相关进程绑定到同一调度域内
# 减少跨域迁移的开销
今日工具箱:CPU亲和性管理套件
#!/bin/bash
# cpu_affinity_manager.sh
# 完整的CPU亲和性管理工具
VERSION="1.0"
AUTHOR="Linux运维登神计划"
show_menu() {
echo "=== CPU亲和性管理器 v$VERSION ==="
echo "1. 查看系统CPU拓扑"
echo "2. 查看进程绑定状态"
echo "3. 绑定进程到CPU核心"
echo "4. 批量绑定(按进程名)"
echo "5. 优化网络中断"
echo "6. 生成亲和性报告"
echo "7. 恢复默认设置"
echo "8. 退出"
echo "================================"
}
view_topology() {
echo "CPU拓扑信息:"
echo "--------------"
lscpu | grep -E "(Architecture|CPU\(s\)|Thread|Core|Socket|NUMA)"
echo
echo "NUMA节点信息:"
numactl --hardware
}
view_process_affinity() {
read -p "请输入进程PID(或按回车查看所有进程): " PID
if [ -z "$PID" ]; then
ps aux --sort=-%cpu | head -20 | awk 'NR>1 {print $2, $11}' | while read P COMM; do
echo -n "PID:$P CMD:$COMM 绑定:"
taskset -p $P 2>/dev/null || echo "无法访问"
done
else
echo "进程 $PID 的CPU亲和性:"
taskset -p $PID
fi
}
bind_process() {
read -p "请输入进程PID: " PID
read -p "请输入CPU核心(如0,2-4,6): " CPUS
if taskset -cp $CPUS $PID; then
echo "成功将进程 $PID 绑定到核心 $CPUS"
else
echo "绑定失败,请检查权限和PID"
fi
}
optimize_network_irq() {
echo "优化网络中断分布..."
INTERFACE=$(ip route | grep default | awk '{print $5}' | head -1)
IRQS=$(grep $INTERFACE /proc/interrupts | awk '{print $1}' | cut -d: -f1)
CORE=0
for IRQ in $IRQS; do
MASK=$((1 << $CORE))
printf "%x" $MASK > /proc/irq/$IRQ/smp_affinity 2>/dev/null && \
echo "IRQ $IRQ 绑定到核心 $CORE"
CORE=$(( (CORE + 1) % $(nproc) ))
done
}
generate_report() {
REPORT_FILE="/tmp/cpu_affinity_report_$(date +%Y%m%d_%H%M%S).txt"
{
echo "CPU亲和性分析报告"
echo "生成时间:$(date)"
echo "=========================="
echo
echo "1. 系统拓扑:"
lscpu | grep -E "(CPU\(s\)|Thread|Core|Socket)"
echo
echo "2. 当前负载:"
uptime
echo
echo "3. CPU迁移统计:"
grep -E "(ctxt|cpu_migrations)" /proc/stat
echo
echo "4. 关键进程绑定状态:"
for PROC in nginx mysqld redis java; do
PIDS=$(pidof $PROC)
for P in $PIDS; do
echo -n "$PROC(PID:$P): "
taskset -p $P 2>/dev/null | awk '{print $NF}'
done
done
echo
echo "5. 中断分布:"
grep -E "(eth|enp)" /proc/interrupts | head -5
} > $REPORT_FILE
echo "报告已生成:$REPORT_FILE"
}
# 主循环
while true; do
show_menu
read -p "请选择操作 [1-8]: " CHOICE
case $CHOICE in
1) view_topology ;;
2) view_process_affinity ;;
3) bind_process ;;
4) echo "批量绑定功能开发中..." ;;
5) optimize_network_irq ;;
6) generate_report ;;
7) echo "恢复默认设置功能开发中..." ;;
8) echo "退出管理器,再见!"; exit 0 ;;
*) echo "无效选择,请重新输入" ;;
esac
echo
read -p "按回车继续..."
done
总结与展望
今日关键收获:
- CPU亲和性的本质:减少缓存失效和迁移开销,提升数据局部性
- 三大绑定策略:硬亲和性(严格绑定)、软亲和性(倾向性绑定)、中断亲和性(避免干扰)
- 核心工具:taskset用于进程绑定,numactl用于NUMA优化,cgroups用于容器环境
- 应用场景:从Web服务器到数据库,从实时系统到容器编排,CPU亲和性都有用武之地
- 性能收益:典型场景下可获得15-25%的性能提升
CPU亲和性的“黄金法则”:
- 绑定重要进程,让普通进程自由调度
- 考虑NUMA架构,确保内存访问局部性
- 监控负载均衡,避免“旱的旱死,涝的涝死”
- 在容器环境中,利用平台提供的亲和性功能
一个重要的认知转变:
从“让调度器决定一切”
变为“指导调度器做出更优决策”
CPU亲和性不是要取代Linux调度器,而是增强它。我们告诉调度器:“这个进程特别重要,请尽量让它在这里运行”,而不是“你必须让它在这里运行”。
思考题:
“在多租户的Kubernetes集群中,如何平衡CPU亲和性带来的性能优势和资源利用率?当多个租户都要求独占CPU核心时,调度器应该如何决策?”
(提示:思考Kubernetes的CPU管理器策略、资源配额、以及优先级调度)
昨日思考题回复
“如果pidstat显示系统总的上下文切换率很高,但每个具体进程的自愿切换(cswch/s)都很低,这暗示了什么样的问题场景?”
这是一个很典型的系统级调度问题。当总的切换率很高但每个进程的自愿切换都很低时,说明:
根本原因:调度器过于“勤奋”而进程却“不愿交出CPU”
想象这样一个场景:在一个办公室里,经理(调度器)不停地把员工(进程)从座位上拉起来换人,但每个员工其实都想继续工作,不想被中断。
两种典型场景:
场景1:大量CPU密集型进程在少量核心上竞争
# 8个计算密集型进程在4核CPU上运行
# 每个进程都想一直运行(自愿切换低)
# 但调度器必须每几毫秒就强制切换一次(非自愿切换高)
# 用pidstat看会是:
# 进程A: cswch/s=5, nvcswch/s=5000
# 进程B: cswch/s=3, nvcswch/s=5200
# ...
# 总计:总切换率很高(几万/秒),但每个进程的自愿切换都很低
场景2:调度器参数配置不当
# 调度器的时间片设置过短
cat /proc/sys/kernel/sched_min_granularity_ns
# 如果设得太小(如1ms),即使进程还想继续运行
# 调度器也会频繁强制切换
诊断方法:
# 1. 查看非自愿切换
pidstat -w 1 | grep -v PID | awk '{print $4, $5}' | sort -k2 -nr
# 2. 检查运行队列长度
vmstat 1
# 如果r列(运行队列)一直很高(>CPU核心数*2)
# 说明进程在排队等CPU
# 3. 检查时间片设置
sysctl kernel.sched_min_granularity_ns
# 正常值:3-10ms(3000000-10000000纳秒)
解决方案:
- 增加CPU资源:最直接的解决方式
- 调整调度参数:适当增加时间片
- 优化进程设计:减少CPU密集型任务数量
- 使用CPU亲和性:让关键进程“定居”在特定核心
记住:CPU亲和性就像给重要的项目团队分配固定办公室——不是为了限制自由,而是为了提高效率。合理使用,你的系统将运行得更快、更稳。
 发表于 2025-12-15 10:26:51
|
查看: 225|
回复: 0
发表于 2025-12-15 10:26:51
|
查看: 225|
回复: 0
