本文概述了Zendesk对数据迁移工具中长时间运行任务的架构调整,通过利用客户端行为简化了任务执行模式,在提升功能的同时消除了分布式系统中的诸多复杂性问题。

背景:Zendesk的账户迁移
在Zendesk的后台系统中,每个客户账户的数据都存储在全球特定数据中心。我们不希望账户被永久绑定在其创建时的原始数据中心,因此开发了一套账户迁移工具,能够以近乎零停机时间的方式将账户迁移到新的数据中心。
该工具对客户和公司自身都具有重要价值。它最初是为了将单一部署扩展到多个数据中心而设计,后来在将数据中心迁移至AWS的过程中发挥了关键作用。目前,它仍被用于在不同数据中心间平衡容量及其他指标,并在整合收购公司的服务到共享基础设施方面扮演着重要角色。
账户迁移工具由中央协调器和若干数据迁移器构成。协调器负责管理整个迁移生命周期并协调各系统,而数据迁移器则负责具体的数据传输工作,每种支持的数据存储类型都对应一个专用的数据迁移器。
挑战:整合收购公司的数据系统
当我们收购一家使用不同数据库系统的公司时,便会面临整合难题。最直接的解决思路是:“能否避免构建新系统?”如果存在已被验证且适用的数据存储方案,我们会优先采用。
如果此路不通且数据必须迁移,通常就需要开发新的数据迁移工具。这是一项繁重的工作,我们对此持谨慎态度。但若让数据长期游离于核心Zendesk基础设施之外,会使情况复杂化,并让被收购的产品失去许多组织层面的优势。因此,构建数据传输系统的复杂性,深刻影响着收购项目的整合过程。
数据迁移器即作业执行服务器
数据传输的具体细节固然重要,但本文聚焦于任务管理,因为数据迁移工具正是通过执行任务来工作的。那么,什么构成了一个“任务”?其核心特征包括:
- 长时间运行:如果执行时间很短,那可能只是一个普通请求。
- 需监控完成状态:如果无需等待结果,只需触发事件后离开即可。
此外,数据迁移任务通常是持续进行的,它们将数据从源系统复制到目标系统,并随着新变化的出现保持同步。因此,这些任务会一直运行,直至整个账户迁移完成。
典型的作业系统API
如果需要运行作业,通常需要一个作业系统。在这种场景下,协调器是请求作业运行的客户端,而数据迁移器则是实现作业的服务器。
大多数长时间作业系统(包括我们的初始实现)都提供类似的API:
StartJob(config) -> jobIdGetStatus(jobId) -> statusStopJob(jobId)
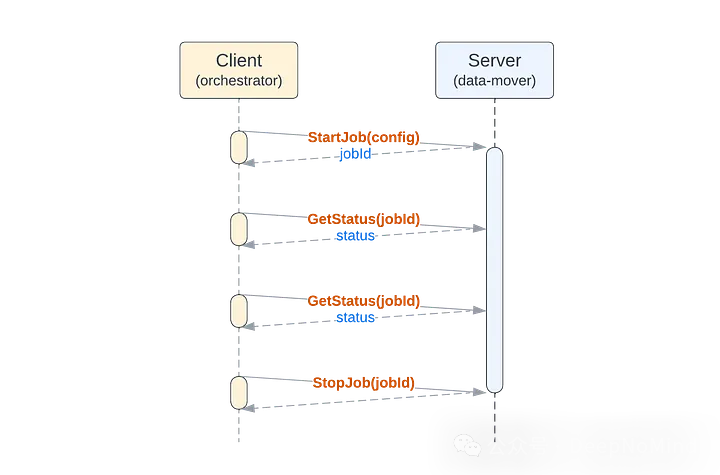
这个API看似简单,但要成为可靠的数据迁移任务执行工具,必须满足一系列严苛要求:
持久性
任务绝不能丢失。一旦客户创建了任务,即使服务器崩溃或重启,也必须记住它。
容错性
作业可能运行很久,而Kubernetes容器并非永久存在。如果容器崩溃或被替换,作业需要由另一个容器接替执行。
可恢复性
中断不应导致工作从头开始,而应从(接近)上次中断点继续。
唯一性
同一时间不应有两个实例执行相同的任务。
悬置任务处理
如果客户因故遗忘了某个任务,我们不希望它无限期运行,这既浪费资源也可能引发意外问题。系统需要能检测并停止这些悬置任务。
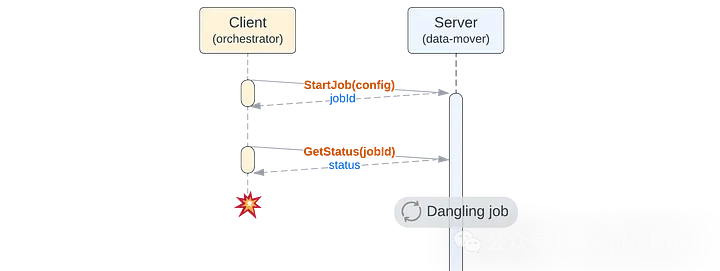
传统的任务执行架构
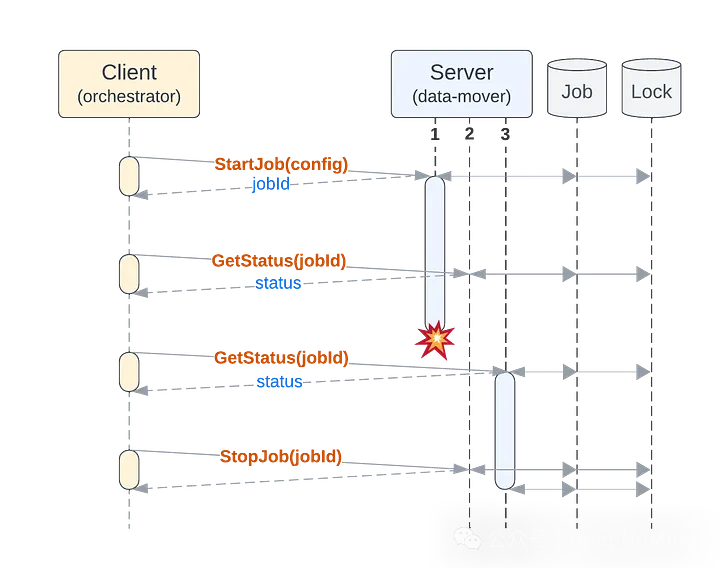
基于上述API和需求,一个显而易见的架构包含一个数据库和一个锁服务。锁服务可能复用底层数据存储,也可能是独立的系统,如Consul或etcd。
当作业被创建时,它被保存到数据库中(确保持久性),其状态会定期保存(便于恢复)。进程在执行作业前,会先获取该作业的锁(确保唯一性)。如果数据库中存在未完成且没有活跃锁的作业,工作进程就可以接管它(实现容错)。
我们通过3个服务器实例、1个作业数据库和1个锁服务来整合这一切。下图展示了一个包含在另一个服务器实例上恢复操作的作业执行序列:
遗留问题与思考
我们接近了目标,但仍有问题待解决。
悬置任务:如果允许任务在客户端离开后继续运行一段时间,这不算太难处理。我们决定,仅当客户端查询任务状态时才执行非活跃任务。如果客户端不再调用GetStatus,当前容器会继续运行任务直到终止,此后该任务将不再被执行。
重复任务:如果客户端创建任务后因错误未能处理响应,就会产生一个失效任务。我们不会永远为之浪费资源,但它可能持续运行数小时。对于数据处理任务,两个相同任务的并发执行还可能导致写入冲突和传输失败。
关键解决方案:幂等性密钥
防止重复任务的一个常见且有效的方法是使用幂等性密钥(idempotency key)。这种技术在Stripe、Square等支付API中很常见,因为它能确保同一笔交易只被处理一次。
将其应用于工作流:客户端为每个要创建的工作生成一个唯一密钥,并随StartJob请求发送。如果服务器收到两个具有相同“幂等性密钥”的请求,就知道客户端指的是同一个工作。因此,客户端可以多次调用StartJob,而服务器知道只需启动一次即可。
这种责任划分很巧妙:服务器和客户端各司其职,结合起来就构成了可靠的重复任务防护方案。但客户端的潜力不止于此——事实证明,利用客户端易于提供的特性,可以解决更多问题。

迈向极简API
之前提到,如果任务时间很短,它可能只是一个请求。那么,如果任务本身就是请求呢?这存在两个明显问题:
- 客户端希望在任务运行时了解其状态。
- 请求是脆弱的——单个请求很难持续到长时间任务完成。
第一个问题(状态感知)可以通过流式响应解决。我们使用gRPC,但流式HTTP也能很好地工作。服务器可以随时发送新的状态更新,客户端能即时接收。这比让客户端定期轮询任务状态更简单、响应更快。
关于连接的脆弱性:我们的任务本就要求具备可恢复性。因此,如果连接中断,客户端可以发起一个新的长时RunJob请求(使用相同的幂等性密钥和配置),而服务器则可以从最新保存的状态继续执行任务。
在这种设置下,下图展示了任务执行的流程示例(包括在另一个服务器实例上重启任务):
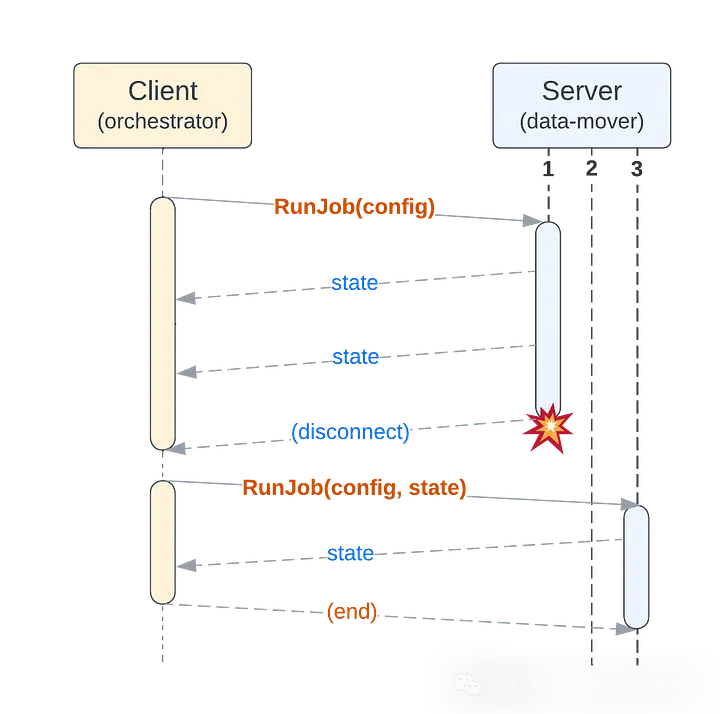
请注意,我们移除了服务器端的锁API和任务存储。
细心的读者可能会怀疑我将这些责任转移给了客户端(图中未展示其基础设施)。请继续阅读,你会发现这其实是一种有意为之的优势,而非设计缺陷。
重构带来的优势
这个简单的API重构令人惊喜地完美满足了所有需求。以下是其主要优点:
消除“悬置任务”
在这种模式下,工作仅在客户端主动等待(通过保持连接开放体现)时进行。连接断开,工作即停止。这与结构化并发的理念有很好的相似性,后者通过防止子任务生命周期超出父任务来避免线程失控。保持请求开放迫使客户端主动等待,实现了类似的防失控任务安全机制。
简化任务分配
客户端每次只发出一个请求。我们原本依赖分布式锁来确保只有一个进程执行特定任务。但如果工作仅在客户端有活跃请求时进行,且客户端只有一个活跃请求,就不再需要显式的任务分配逻辑,直接在接收请求的实例上执行工作即可。
错误处理与重试
账户迁移任务耗时、昂贵且重要。旧系统默认较为脆弱:任何错误都可能导致任务失败,直到数据迁移器实现了可靠的错误重试机制(包括退避逻辑和放弃条件)。
通过新接口,任何错误默认会导致请求失败。但客户端本就具备处理失败请求的能力,可以让客户端在决定何时重试或放弃时拥有最大灵活性,同时保持服务器实现的简洁。实际上,对于重要操作,客户端可以转而寻求人工干预,这同样不需要服务器的特殊支持。
负载均衡
这是一个更长远的目标,实现起来通常很复杂。理想情况下,若有10个实例和100个任务,我们希望每个实例处理10个。当连接数量直接反映工作数量时,平衡变得简单,因为这正是负载均衡器的工作——例如,Istio的默认设置就是将流量发送到活跃请求最少的实例。我们在工作完成时虽不会主动重新平衡,但除此之外,几乎免费地获得了近乎最优的负载分布。
状态存储
这可能是我们最依赖客户端的地方——将状态交给客户端存储。作为流式响应的一部分,我们有一个不透明的字节字段persist_state。客户端收到后将其存储在本地。每次发起新请求时,客户端将最近存储的状态作为persist_state字段值发送。
这使得服务器可以完全实现无状态化,这对于处理持久化数据的服务来说是一个独特优势。这些数据属于被迁移的服务,不适合作为我们自己的作业存储。
对我们而言,这样做是值得的,因为服务器数量远多于客户端(在可预见的未来只有一个客户端)。一个完全无状态的服务器带来的好处,超过了让客户端保存状态所增加的少量工作。
你可以采纳本文的其他观点而无需让客户端控制状态。请注意,除非完全信任客户端,否则切勿这样做。我们选择充分信任客户端,甚至允许其发送可能导致跳过部分数据传输的错误状态。但我们不会在状态中暴露任何与授权相关的敏感数据,以防客户端影响其无权访问的数据存储系统。
有趣的是,对无状态数据迁移器的需求正是整个设计的最初动机。回过头看,移除状态存储可能并非最重要的好处——如果没有分布式协调的难题,写入数据库本身并不困难。
方法生效的条件与范围
当然,这一切生效的前提是客户端具备良好行为,例如“不会遗忘任务”和“每个任务只发起一个请求”。这听起来像是作业执行器该做的事?
实际上,账户管理协调器本身就是一个被赋予了更高职责的作业执行器,其主要工作包括运行各种内部作业并记录状态。本文描述的方法并未消除对作业执行器的需求,而是意味着可以将一个单一的作业执行器应用于系统的最外层。我们不是直接与作业系统集成,而是通过设计接口来利用其提供的有利特性。
这显著简化了现有数据迁移系统,使其无需再管理任务(及随之而来的复杂性和故障)。更重要的是,这影响了未来尚未编写的数据迁移程序。现在,当我们需要为被收购公司的数据存储编写迁移程序时,主要工作就只是数据传输本身,而无需构建可靠的任务执行系统。
重新审视“耦合”
人们通常倾向于构建模块化、解耦、独立的系统,这些特质本身是积极的。
事实上,康威定律表明,如果将“数据迁移器”设立为独立的系统和团队,人们自然会将其构建为一个独立的系统,正如我们所做的那样。但通过采用轻量级的耦合方式(即在客户端和服务器间定义一套特定的协议),可以实现巨大的效率提升,从而构建出整体上更健壮、复杂度更低的系统。
结语:关于现成作业系统的思考
“为什么不直接使用[某个现成作业系统]呢?”
由于不了解所有细节,或许可以。但考虑到我们的需求涉及多种编程语言,没有现成系统能完全满足所有功能。当然,可以通过额外编码来集成或增强缺失的功能。但有什么比编写一堆代码更好呢?那就是不编写它们!
参考资料
[1] Less is More: Improving job execution by ditching the job executor: https://zendesk.engineering/less-is-more-improving-job-execution-by-ditching-the-job-executor-d00eff680de4
[2] Consul: https://www.consul.io
[3] etcd: https://etcd.io
[4] Stripe Idempotency: https://docs.stripe.com/api/idempotent_requests
[5] Square Idempotency: https://developer.squareup.com/docs/build-basics/common-api-patterns/idempotency
[6] Structured Concurrency: https://en.wikipedia.org/wiki/Structured_concurrency
[7] Istio Load Balancing: https://istio.io/latest/docs/concepts/traffic-management/#load-balancing-options
[8] Conway‘s Law: https://en.wikipedia.org/wiki/Conway%27s_law
 发表于 2025-12-15 15:59:11
|
查看: 228|
回复: 0
发表于 2025-12-15 15:59:11
|
查看: 228|
回复: 0
