你是否经历过这样的场景?周五晚上开始迁移数据,预计8小时完成,结果到周日早上还在修复数据不一致。周一业务团队等着用新系统,却连回滚都不敢,因为旧数据已经被污染了。或者更糟的是,新系统上线后,反馈还不如旧系统好用,业务要求立刻切回去,但旧系统已经停掉了。
这正是我们需要重视迁移规划的原因。架构迁移不只是技术升级,它本质上是一项业务连续性保障工程。一个完美的架构设计固然重要,但一个周全、可执行的迁移计划,往往决定着整个项目的成败。本文将以一个从单体消防答题系统升级为综合性微服务答题平台的实际案例,手把手教你制定一套平滑、可靠的架构迁移路线图。
开始之前,不妨先问自己三个问题,测试一下你的迁移计划是否足够扎实:
- 如果迁移过程中发现数据不一致,你有多长时间窗口来修复?
- 当新系统出现性能问题时,你能否在5分钟内切回旧系统?
- 业务团队需要为新系统上线暂停多少小时的业务?
一个合格的迁移规划,就是要系统性地解决这三个层面的挑战,具体可分为三个核心部分:
- 差距分析:我们现在在哪?要去哪里?中间差什么?(AS-IS vs TO-BE)
- 项目规划:分几步走?每个版本交付什么?(版本路线图)
- 实施策略:具体怎么移?数据怎么迁?流量怎么切?(操作手册)
接下来,我们一项一项深入拆解。
差距分析(看清我们现在在哪)
在制定任何路线之前,必须清晰地了解起点和终点。我们对比旧消防答题系统(AS-IS)和新答题平台(TO-BE),从四个层面进行差距分析。
业务能力差距分析
旧系统功能单一,而新平台需要支持复杂的软考场景,业务能力差距显著。
| 能力维度 |
旧系统(消防) |
新系统(软考) |
差距等级 |
影响 |
| 用户角色 |
单一角色(考生) |
多角色(考生/批阅员/管理员) |
⭐⭐⭐ 大 |
需要重构权限体系 |
| 考试模式 |
固定试卷、客观题 |
智能组卷、主客观结合 |
⭐⭐⭐⭐ 很大 |
需要全新考试引擎 |
| 批阅能力 |
自动批阅(客观题) |
人工+AI批阅(主观题) |
⭐⭐⭐⭐⭐ 全新 |
需要建设批阅工作流 |
| 数据分析 |
简单统计报表 |
多维学习分析、预测模型 |
⭐⭐⭐⭐ 很大 |
需要建设分析平台 |
最大的差距集中在主观题批阅和智能分析,这两个能力旧系统完全没有,需要从零开始建设。
技术架构差距分析
技术栈的代差更为明显,下图直观展示了从传统单体架构到现代化云原生微服务架构的转型路径。

具体的技术差距主要体现在:
- 架构模式:单体→微服务,需要服务拆分、服务治理。
- 数据架构:单库→分库分表,需要数据迁移、双写策略。
- 性能架构:无缓存→多级缓存(如
Redis + ES),需要缓存设计、缓存一致性保障。
- 部署架构:物理机→K8s,需要容器化改造、CI/CD流水线。
数据模型差距分析
数据库表结构的变化是迁移中最复杂的一环,直接关系到数据迁移的可行性与工作量。
| 数据实体 |
旧系统表结构 |
新系统ER模型 |
迁移复杂度 |
| 用户 |
user(id, name, password) |
user(id, username, encrypted_password, user_type...) |
⭐⭐ 中(需要补充字段) |
| 题目 |
question(id, content, answer) |
question(id, content, options, question_type, metadata...) |
⭐⭐⭐⭐ 高(结构变化大) |
| 答题记录 |
answer(id, user_id, question_id, answer) |
answer_record(id, exam_session_id, question_id, user_answer, score...) |
⭐⭐⭐⭐⭐ 很高(关联关系变化) |
| 考试 |
无此概念 |
exam_session, exam_report 等 |
⭐⭐⭐⭐⭐ 全新(需要历史数据转换) |
特别需要注意的是,旧系统没有“考试会话”这个概念,所有答题记录都是孤立的点。迁移时,我们需要将历史答题记录重新组织为虚拟的考试会话,这对数据转换逻辑提出了很高要求。
拟定迁移项目(分几个版本)
基于上述差距分析,我们采用 “敏捷迭代、分步上线” 的策略,将庞大的迁移工程拆解为三个可管理、可交付的版本。
总体迁移路线图
一个清晰的路线图能让整个团队对齐目标,明确里程碑。下图展示了从基础平台搭建到AI赋能扩展的完整演进路径。
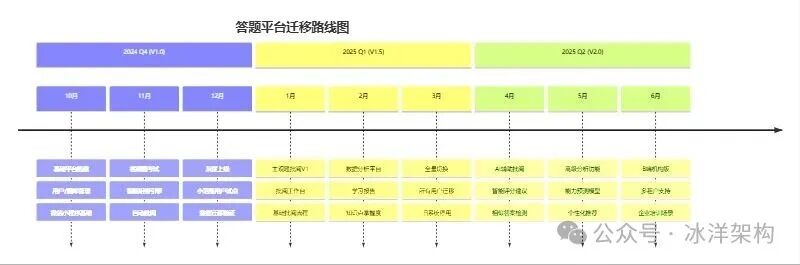
版本详细规划
V1.0(基础平台+客观题考试)
- 目标:替换旧系统核心功能,建立新平台基础。
- 交付内容:用户中心、题库管理、客观题考试、自动批阅与基础报告、微信小程序考生端。
- 技术重点:搭建微服务基础框架(如 Spring Cloud Alibaba)、实现双写迁移机制、建立监控告警体系。
- 业务价值:旧系统用户可无缝迁移,获得更好的考试体验。
V1.5(主观题批阅+智能分析)
- 目标:上线核心差异化功能,建立产品优势。
- 交付内容:主观题支持、批阅工作台、多维学习分析报告、管理后台功能完善。
- 技术重点:实时通信(WebSocket)用于批阅界面、
Elasticsearch实现复杂查询与分析、消息队列解耦批阅流程。
- 业务价值:支撑软考真实考试场景,提供深度学习洞察。
V2.0(AI赋能+B端扩展)
- 目标:智能化升级,拓展商业边界。
- 交付内容:AI辅助批阅、智能学习路径推荐、多租户机构版、开放API平台。
- 技术重点:机器学习模型集成、多租户数据隔离、API网关与开发者门户。
- 业务价值:从C端工具升级为B端平台,开辟新的营收渠道。
制定实施与迁移策略(具体怎么搬家)
路线图明确了“做什么”,实施策略则要解决“怎么做”,这是确保迁移平稳落地的关键。
数据迁移:五步迁移法
数据迁移是重中之重,绝不能指望一次 INSERT INTO ... SELECT 就能搞定。我们采用标准化的五步迁移流程,如下图所示:

具体操作要点:
步骤1:数据评估与清洗(V1.0开发阶段)
在开发早期就开始分析旧数据质量,避免上线前才发现“历史债务”。
- 识别并修复脏数据(如空密码、无效邮箱)。
- 评估数据量,估算迁移时间。
- 制定数据清洗规则和脚本。
-- 示例:用户数据质量检查SQL
SELECT
COUNT(*) as total_users,
COUNT(DISTINCT email) as unique_emails,
SUM(CASE WHEN email LIKE '%@%' THEN 1 ELSE 0 END) as valid_emails,
SUM(CASE WHEN password IS NULL OR password = '' THEN 1 ELSE 0 END) as null_passwords
FROM old_system.users;
-- 如果null_passwords > 0,需要设计密码重置流程
步骤2:结构映射与转换
编写数据转换服务,将旧数据结构映射到新模型。这是迁移逻辑的核心。
- 字段映射与类型转换。
- 关联关系重建(如创建虚拟考试会话)。
- 默认值填充与逻辑补全。
// 数据转换服务示例
@Service
public class DataMigrationService {
public NewQuestion convertOldQuestion(OldQuestion old) {
NewQuestion newQuestion = new NewQuestion();
newQuestion.setId(old.getId());
newQuestion.setContent(old.getContent());
// 旧系统只有纯文本答案,新系统需要结构化
if (old.getQuestionType() == 1) { // 单选题
newQuestion.setQuestionType(QuestionType.SINGLE_CHOICE);
newQuestion.setOptions(parseOptionsFromContent(old.getContent())); // 解析选项
newQuestion.setStandardAnswer(old.getAnswer());
}
// ...其他题型转换
return newQuestion;
}
}
步骤3:增量同步(双写期间)
新系统上线后,需要与旧系统并行运行一段时间。在此期间,所有写操作必须同时写入新旧两套系统,确保数据同步。
- 使用拦截器或AOP实现业务无侵入的双写。
- 异步写入旧系统,避免影响新系统性能。
- 记录双写失败差异,用于事后补偿。
// 双写拦截器示例
@Component
public class DualWriteInterceptor {
@Autowired
private OldSystemClient oldSystemClient;
@Around("@annotation(DualWrite)")
public Object dualWrite(ProceedingJoinPoint joinPoint) throws Throwable {
// 1. 写新系统
Object result = joinPoint.proceed();
// 2. 异步写旧系统(保持兼容)
CompletableFuture.runAsync(() -> {
try {
oldSystemClient.writeToOldSystem(buildOldFormat(joinPoint.getArgs()));
} catch (Exception e) {
log.error("双写旧系统失败,记录差异", e);
// 记录到差异表,定时任务补偿
differenceRecordService.recordFailure(/*...*/);
}
});
return result;
}
}
步骤4:数据验证脚本
自动化校验是保证数据一致性的最后一道防线。
- 对比新旧系统关键数据的总数、样本一致性。
- 校验关键业务逻辑(如用户总分计算)。
- 输出差异报告,指导人工复核。
#!/usr/bin/env python3
# 数据一致性校验脚本
def validate_user_data():
# 从新旧系统分别查询
new_users = query_new_system("SELECT id, username FROM users LIMIT 1000")
old_users = query_old_system("SELECT id, name FROM users LIMIT 1000")
differences = []
for new, old in zip(new_users, old_users):
if new['username'] != old['name']:
differences.append({
'id': new['id'],
'new_username': new['username'],
'old_name': old['name']
})
if differences:
print(f"发现 {len(differences)} 条差异")
save_to_csv(differences, 'user_differences.csv')
else:
print("用户数据一致性校验通过")
流量切换:灰度发布与回滚
数据迁移完成后,如何将用户流量平滑地切换到新系统?采用灰度发布是唯一可靠的方式。

灰度发布规则:
- 按用户ID哈希分流:确保同一用户始终访问同一版本,体验一致。
- 关键业务指标监控:
- 错误率 > 5%:自动告警。
- 响应时间 > 2000ms:自动告警。
- 交卷成功率 < 98%:人工干预。
- 回滚机制:
- 配置一键切换流量比例。
- 确保5分钟内可全量回退到旧系统。
并行运行与回滚方案
新旧系统必须有一段并行运行期,这是降低风险、建立信心的关键。我们规划了为期4周的并行期。
| 时间 |
阶段 |
写入策略 |
读取策略 |
回退复杂度 |
| 第1周 |
内部试用 |
新系统写,异步同步旧系统 |
内部用户读新系统,其他读旧系统 |
低(只影响内部用户) |
| 第2周 |
种子用户 |
双写(新旧同时写) |
种子用户读新系统,其他读旧系统 |
中(需合并种子用户数据) |
| 第3周 |
A/B测试 |
双写 |
50%用户读新系统,50%读旧系统 |
高(需处理数据分裂) |
| 第4周 |
全量切换 |
只写新系统,旧系统只读 |
100%读新系统 |
很高(需完整回滚) |
回退方案必须可执行,不能停留在“不行就切回去”的层面。需要预先准备回滚脚本和配置。
# 回滚配置示例(ConfigMap)
rollback:
enabled: true
triggers:
- metric: error_rate
threshold: 5%
duration: 5m
- metric: response_time
threshold: 2000ms
duration: 10m
actions:
- stage1: "流量100%切回旧系统"
- stage2: "停止新系统写入"
- stage3: "启动数据补偿作业(将新系统数据同步回旧系统)"
- stage4: "发送业务通知"
迁移实战清单
理论最终要落地为可执行的清单。不同团队流程或有差异,但以下清单可作为通用参考。
成立迁移专项组
明确分工是成功的前提。
| 角色 |
人员 |
职责 |
关键产出 |
| 迁移总指挥 |
架构师/技术总监 |
整体方案决策、风险评估 |
迁移路线图、应急预案 |
| 数据迁移负责人 |
DBA + 后端开发 |
数据评估、清洗、迁移、验证 |
数据迁移方案、校验报告 |
| 应用迁移负责人 |
前后端负责人 |
功能验证、兼容性测试 |
功能对比清单、测试报告 |
| 运维保障负责人 |
DevOps工程师 |
环境准备、监控、回滚 |
部署手册、监控大盘 |
| 业务协调人 |
产品经理 |
用户通知、培训、反馈收集 |
用户通知文案、培训材料 |
迁移计划表(按切换日T日倒排)
迁移准备阶段(T-30天 ~ T-7天):
- 环境准备:生产K8s集群、中间件集群就绪。
- 数据备份:旧系统全量备份+增量备份机制。
- 监控部署:新系统监控告警配置完毕。
- 迁移演练:在预发环境进行完整迁移演练。
- 用户通知:向用户发送迁移预告。
迁移执行阶段(T-7天 ~ T日):
- T-7:开始数据全量迁移(夜间低峰期)。
- T-5:全量数据校验,修复不一致。
- T-3:开启双写,业务低峰期验证。
- T-1:最终检查清单核对。
- T日(周五晚):执行切换。
切换日详细操作清单(T日 20:00开始):
20:00-20:30 迁移团队集合
20:30-21:00 旧系统进入只读模式,停止新写入
21:00-22:00 执行最终增量数据同步
22:00-23:00 数据一致性最终校验
23:00-23:30 切换DNS/负载均衡配置
23:30-00:30 新系统功能快速验证
00:30-01:00 灰度开放5%流量,监控指标
01:00-06:00 根据监控情况逐步放大流量
06:00-08:00 核心功能完整回归测试
08:00-09:00 业务团队验收,确认上线成功
09:00 发送上线成功通知
风险与应急预案
高风险场景及应对:
- 数据不一致超过可接受范围
- 预案:暂停切换,使用差异数据修复工具,延长双写期。
- 新系统性能不达标
- 关键功能缺失或故障
- 预案:功能降级(如关闭复杂分析),保障核心考试流程。
- 用户大规模投诉
- 预案:提供临时回退通道,加强客服支持,快速修复问题。
最容易犯的三个错误
- 低估数据迁移复杂度
- 错误预判:以为直接
INSERT INTO SELECT就能搞定。
- 正确操作:提前进行数据评估,设计清洗、转换、验证全流程。
- 缺少充分的并行运行期
- 错误操作:周末迁移,周一直接全量切换。
- 正确操作:至少安排2-4周双写期,逐步切换流量。
- 没有可执行的回滚方案
- 错误操作:回滚方案停留在“不行就切回去”。
- 正确操作:回滚脚本经过演练,5分钟内可完成回退。
总结
回顾整个迁移规划过程,其核心思想是 “稳”字当头。一个好的迁移计划必须确保:
- 业务无损:用户无感或体验提升。
- 风险可控:有完备的监控和回退机制。
- 团队有信心:每个人都清楚自己的角色和应急方案。
从单体到微服务,从传统部署到云原生,每一次架构升级都是一次“在飞行中更换引擎”的挑战。详细的差距分析、清晰的版本路线、严谨的实施策略,以及可落地的操作清单,共同构成了平滑迁移的基石。希望这份基于真实场景的迁移路线图,能为你下一次的架构演进提供切实可行的参考。如果你有更多关于分布式系统或高可用架构的实践经验,欢迎在云栈社区与我们深入探讨。
 发表于 2026-3-13 07:15:19
|
查看: 222|
回复: 0
发表于 2026-3-13 07:15:19
|
查看: 222|
回复: 0
