
在视频生成领域,实现精准的“运动可控”一直是技术难点。传统方法通常只能控制整体运动方向,或者需要引入额外的运动编码器和复杂结构改造,导致训练和扩展成本极高。
近期,阿里巴巴达摩院视觉团队(ali-vilab)开源了Wan-Move项目,提出了一种几乎零结构侵入的运动控制方案。该方案在不修改原有Image-to-Video(I2V)模型结构的前提下,实现了点级精细运动控制,为人工智能视频生成带来了新的突破。
一、Wan-Move 解决了什么问题?
当前主流视频生成模型在运动控制上普遍存在三大问题:
- 控制粒度粗:多数方法只能控制整体运动方向,无法精确指定局部区域如何移动。
- 结构改造重:依赖额外的运动编码器、ControlNet或光流网络,导致训练成本高、迁移困难。
- 难以扩展到大模型:一旦模型参数规模增大,运动模块往往成为性能瓶颈。
Wan-Move的目标很明确:在不修改基础视频生成模型结构的情况下,实现精细、稳定且可扩展的运动控制。
二、核心思想:Latent Trajectory Guidance
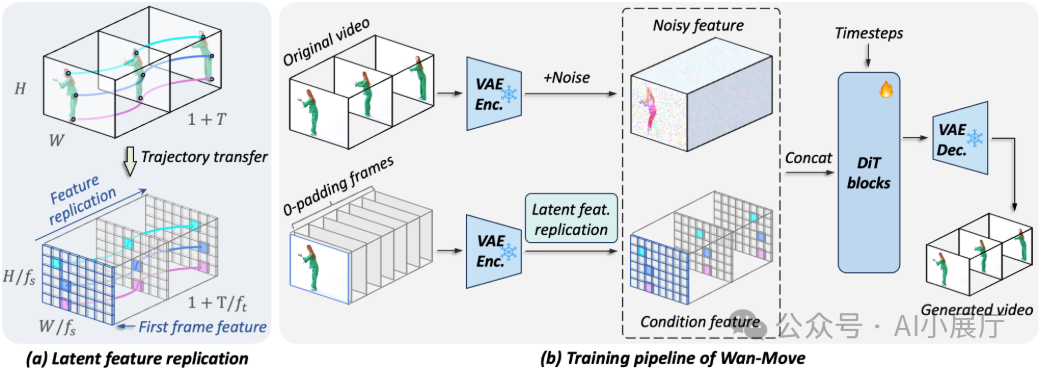
Wan-Move的核心创新在于提出了潜空间轨迹引导(Latent Trajectory Guidance)。
简单来说,它不直接控制像素或网络结构,而是把“运动轨迹”写入模型的潜空间条件中。具体实现包含四个关键步骤。
三、关键技术机制详解
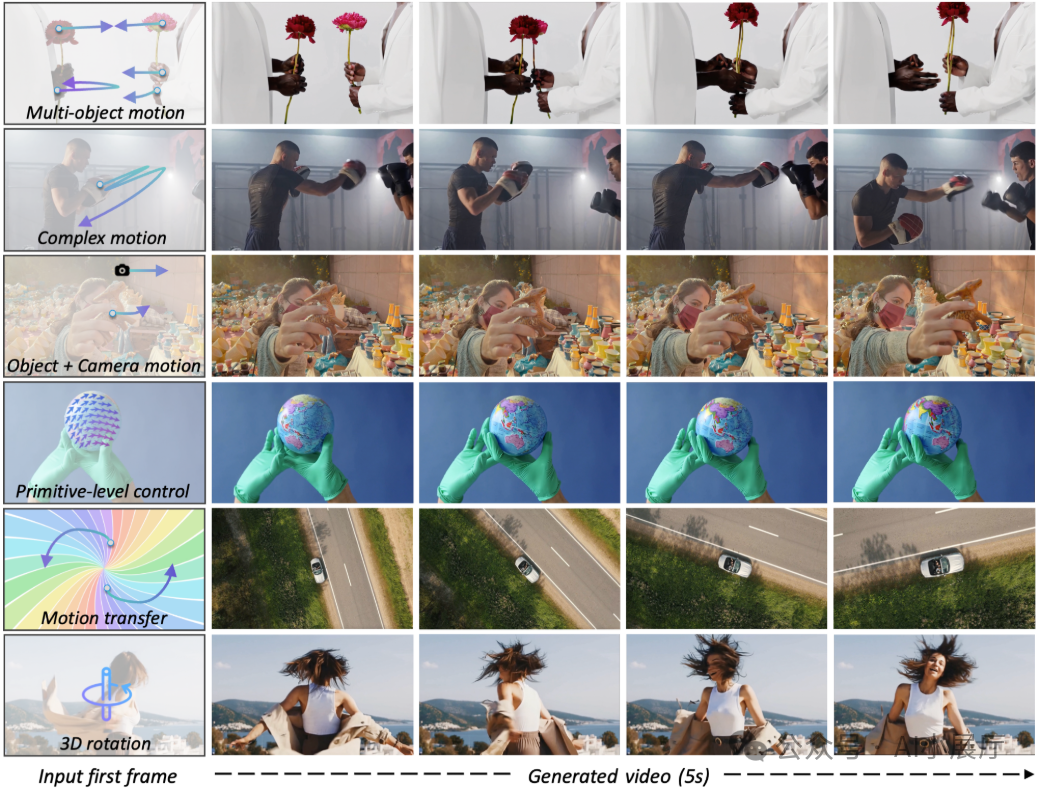
1️⃣ 用“点轨迹”表示运动
Wan-Move使用点级轨迹(Point Trajectory)来描述运动:
- 每条轨迹表示某个点在视频时间维度上的位移。
- 支持单点、多点甚至稠密点集。
- 可表达直线、曲线或大幅度位移。
相比光流或整体运动参数,点轨迹具备更高精度、更灵活的表达能力,更适合局部控制。
2️⃣ 轨迹映射到潜空间(Latent Space)
与传统方法不同,Wan-Move不在像素空间操作运动,而是:
- 将首帧输入VAE或编码器。
- 得到对应的潜特征图(latent feature map)。
- 根据轨迹,在潜特征图中定位对应位置的特征向量。
这样,每个轨迹点都对应一段潜空间特征。
3️⃣ 沿轨迹传播首帧特征
这是Wan-Move最关键的一步:
- 将首帧的潜特征沿着轨迹方向进行传播。
- 在每个时间步生成一个“对齐后的潜特征”。
- 最终形成一个时空一致的潜空间条件。
这一过程本质上是利用轨迹“搬运”首帧的语义和外观信息,从而保证外观一致性、运动方向准确性和时序稳定性。
4️⃣ 无侵入式接入 I2V 模型
生成的时空潜特征会被直接作为更新后的条件输入,喂给原本的Image-to-Video模型(如Wan-I2V-14B)。
整个过程不增加新的网络模块,也不修改原模型结构,仅做条件层面的替换或叠加。这也是Wan-Move能快速扩展到14B参数模型的关键原因。
四、训练与规模化策略
Wan-Move采用可扩展的训练流程:
- 基于大规模视频数据进行训练。
- 支持生成5秒、480p(832×480)分辨率的视频。
- 在训练中加入时序一致性与对齐约束。
项目最终发布了Wan-Move-14B-480P模型,可直接用于推理与复现。
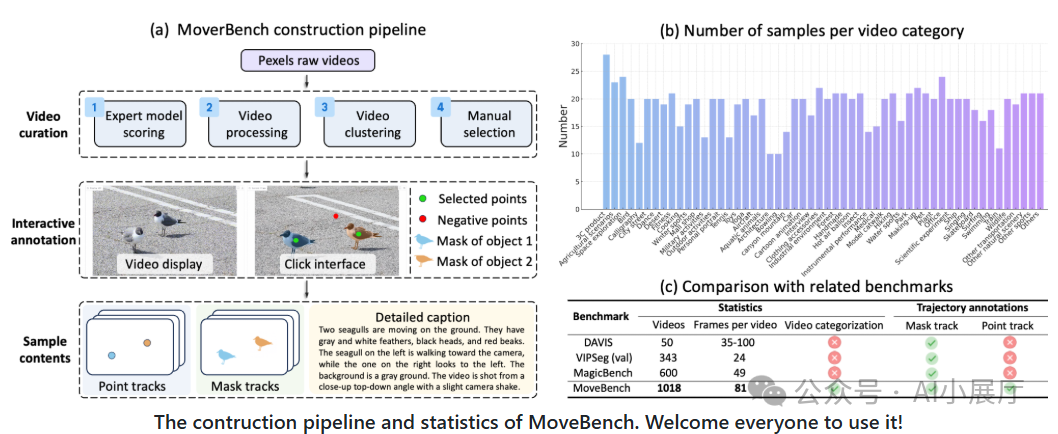
五、MoveBench:专门为“运动控制”设计的评测集
为客观评估运动可控能力,作者构建了MoveBench评测集:
- 包含更长视频时长(如5秒)和更复杂运动场景。
- 提供点轨迹与分割掩码标注。
- 专注评测模型是否真正按轨迹运动。
在MoveBench和公开数据集上,Wan-Move在运动准确性、外观保持和时序稳定性等指标上均取得了显著优势。
六、效果与对比结论
根据论文与项目展示结果:
- Wan-Move的点级运动控制精度显著优于传统方法。
- 在用户研究中,其运动可控体验接近部分商用方案水平。
- 同时保持了高画质和时序一致性。
更重要的是,这些能力是在不修改模型结构的前提下实现的。
七、项目与资源汇总
|  发表于 2025-12-15 23:19:37
|
查看: 242|
回复: 0
发表于 2025-12-15 23:19:37
|
查看: 242|
回复: 0
