随着 ChatGPT、OpenAI 等大语言模型的广泛应用,近似最近邻搜索因其在处理向量嵌入方面的核心作用,重新点燃了人们对向量数据库的兴趣。嵌入能将语义含义转化为数值向量,相似的短语具有相似的向量,这使得语义相似度搜索成为可能。
然而,当知识库规模庞大时,在海量向量中快速找到最相似的 K 个项目(即 K 近邻搜索)成为一项关键挑战。在使用 PostgreSQL 及其扩展 pgvector 存储向量时,IVFFlat 索引是一种提升搜索速度的有效方法。
IVFFlat 索引是什么?
IVFFlat 索引,全称为带平面压缩的倒排文件,是 pgvector 中用于加速向量相似度搜索的一种索引。它采用近似最近邻算法,通过将向量聚类并构建倒排索引,将搜索范围缩小到最可能包含最近邻的少数几个簇中,从而显著提升查询性能。
为什么需要 IVFFlat 索引?
传统用于空间搜索的索引(如 R 树、KD 树)在低维数据上表现良好,但面临“维度灾难”问题。当维度超过约 10 维后,数据变得极为稀疏,这些索引方法会失效。而像 OpenAI 生成的嵌入向量通常有 1536 维,因此必须依赖 IVFFlat 这类近似最近邻算法来处理高维向量搜索。
IVFFlat 索引工作原理
1. 划分空间 (空间聚类)
IVFFlat 首先使用 k-means 聚类算法对所有向量进行分析,找到一组簇质心。然后,每个向量都会被分配到距离其最近的质心所在的簇中。这个过程在概念上将向量空间划分成了多个区域(沃罗诺伊图),每个区域包含语义或特征相似的向量。
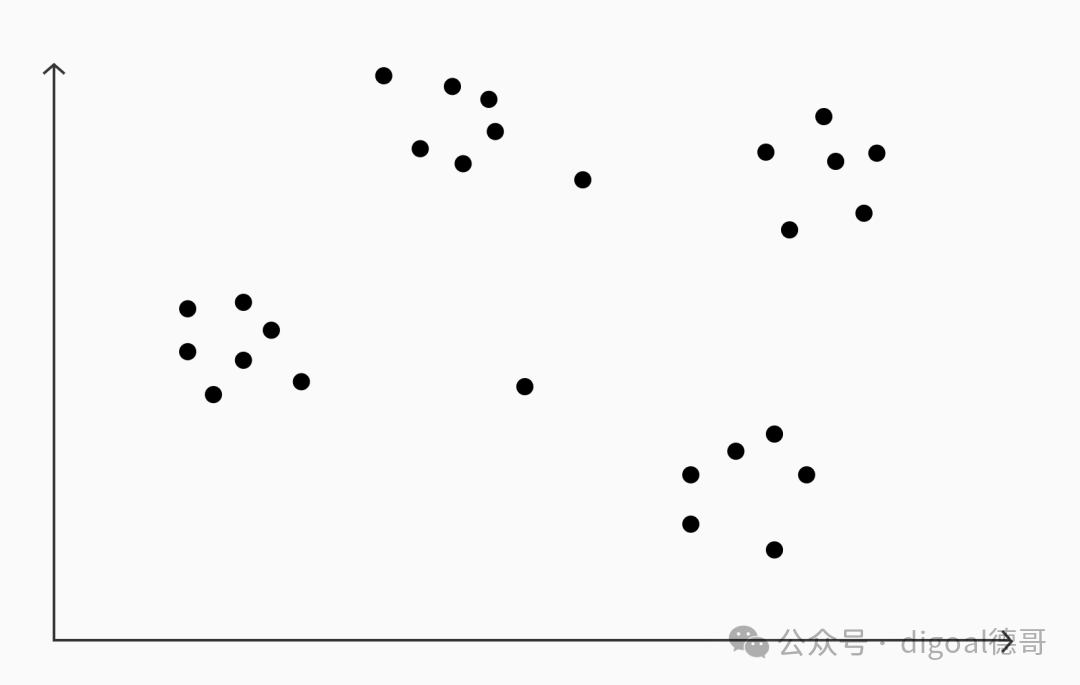
一组表示为二维空间中的点的向量
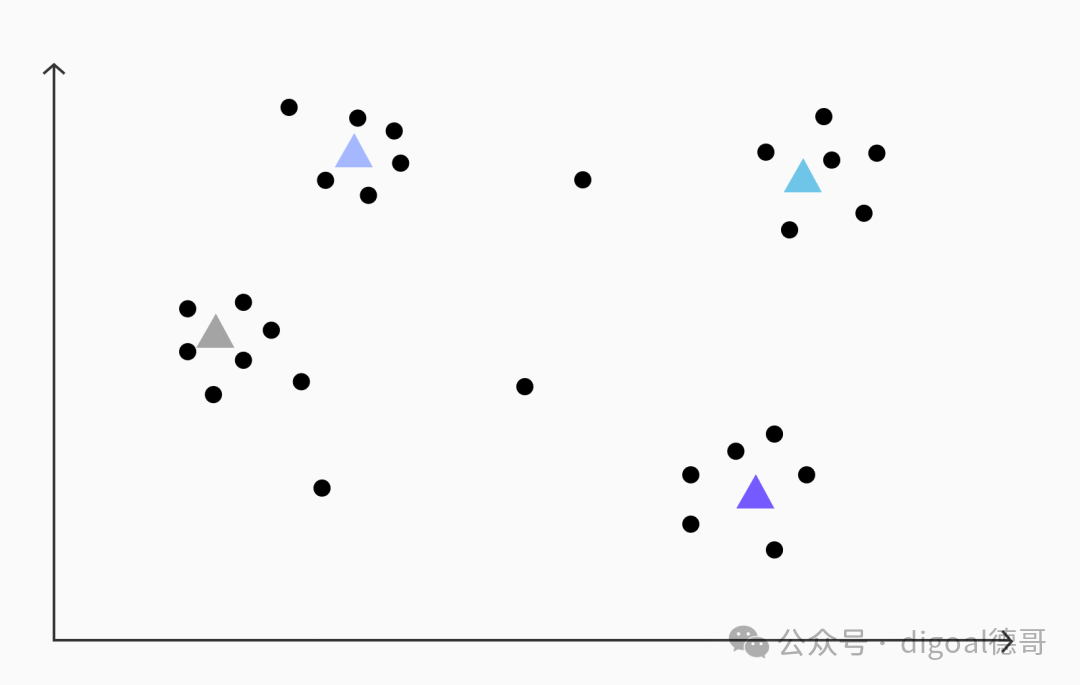
k-均值聚类后,我们识别出由彩色三角形表示的四个簇
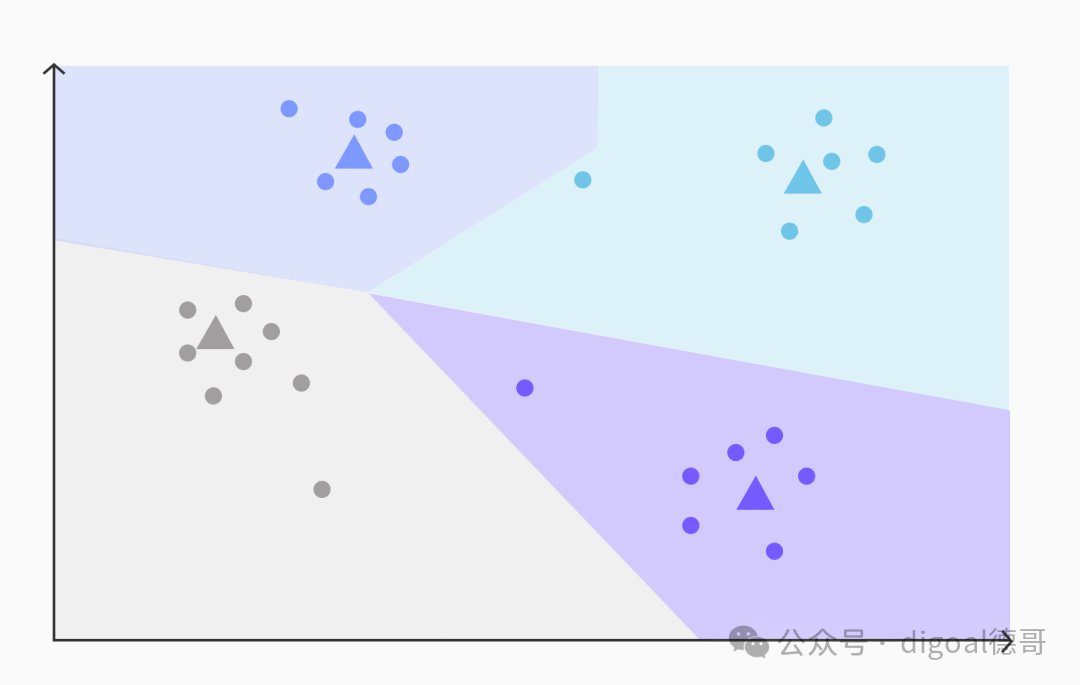
将每个向量分配给其最近质心,从而划分空间
2. 构建倒排索引
接着,IVFFlat 构建一个倒排索引。这个索引以每个质心为键,其对应的值是属于该簇的所有向量列表。伪代码如下:
inverted_index = {
centroid_1: [vector_1, vector_2, ...],
centroid_2: [vector_3, vector_4, ...],
centroid_3: [vector_5, vector_6, ...],
...
}
3. 执行搜索
当进行查询时,算法执行以下步骤:
- 计算查询向量与所有质心之间的距离。
- 找到距离最近的质心(即查询向量所在的区域)。
- 从倒排索引中取出该质心对应的向量列表。
- 计算查询向量与该列表中每个向量的距离。
- 返回距离最小的 K 个向量作为近似最近邻。
通过仅搜索少数簇内的向量,而非全表扫描,搜索效率得到巨大提升。

我们想找到由问号表示的向量的最近邻
4. 处理边界情况与召回率
“最近邻一定在同一个簇内”的假设并非永远成立,尤其是在簇的边界附近,这可能导致召回错误。

当搜索向量空间两个区域边界上的点的最近邻时,IVFFlat 有时会出错
为了提高召回率(找到真实最近邻的概率),pgvector 允许搜索多个最近的簇,这是通过 probes 参数控制的。
Pgvector IVFFlat 核心参数
lists 参数
- 作用:决定聚类时簇的数量。每个簇在倒排索引中对应一个列表。
- 权衡:
lists 值越大,每个簇内的向量越少,搜索速度越快,但可能因区域过小增加遗漏最近邻的风险。
- 建议:
- 数据集行数 < 100 万:
lists = 行数 / 1000(至少为10)。
- 数据集行数 > 100 万:
lists = sqrt(行数)。
probes 参数
- 作用:查询时参数,指定搜索时要检查的簇(列表)数量。
- 权衡:增加
probes 可以提高召回率,但会减慢查询速度,因为需要计算更多向量间的距离。
- 建议:
probes = sqrt(lists)。
在 Pgvector 中使用 IVFFlat
创建索引
创建索引前,表中应有代表性数据,以便 k-means 算法能计算出准确的质心。pgvector 支持三种距离计算方式,需与查询时使用的操作符一致:
| 距离类型 |
查询操作符 |
索引方法 |
| L2 (欧几里得) |
<-> |
vector_l2_ops |
| 负内积 |
<#> |
vector_ip_ops |
| 余弦 (OpenAI推荐) |
<=> |
vector_cosine_ops |
创建索引的 SQL 示例如下:
CREATE INDEX ON embeddings USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);
以下是一个 Python 辅助函数,可根据数据量自动计算合理的 lists 参数并创建索引:
import math
def create_ivfflat_index(conn, table_name, column_name, query_operator="<=>"):
index_method = "invalid"
if query_operator == "<->":
index_method = "vector_l2_ops"
elif query_operator == "<#>":
index_method = "vector_ip_ops"
elif query_operator == "<=>":
index_method = "vector_cosine_ops"
else:
raise ValueError(f"unrecognized operator {query_operator}")
with conn.cursor() as cur:
cur.execute(f"SELECT COUNT(*) as cnt FROM {table_name};")
num_records = cur.fetchone()[0]
num_lists = num_records / 1000
if num_lists < 10:
num_lists = 10
if num_records > 1000000:
num_lists = math.sqrt(num_records)
cur.execute(f'CREATE INDEX ON {table_name} USING ivfflat ({column_name} {index_method}) WITH (lists = {num_lists});')
conn.commit()
执行查询
当查询语句包含 ORDER BY column <操作符> 向量 LIMIT K 的形式时,将可能使用 IVFFlat 索引。
- 示例1:查找与给定向量最相似的记录
SELECT * FROM my_table ORDER BY embedding_column <=> '[1,2]' LIMIT 2;
- 示例2:在 RAG 应用中查找相似文档
# 辅助函数:从数据库获取与查询最相似的3个文档
def get_top3_similar_docs(query_embedding, conn):
embedding_array = np.array(query_embedding)
cur = conn.cursor()
cur.execute("SELECT content FROM embeddings ORDER BY embedding <=> %s LIMIT 3", (embedding_array,))
top3_docs = cur.fetchall()
return top3_docs
- 设置 probes 参数
SET ivfflat.probes = 5;
-- 然后执行您的查询
索引维护与重建
IVFFlat 索引会随着数据的插入、更新和删除而动态更新向量列表。但是,簇的质心在创建后不会自动更新。随着时间的推移,数据分布可能发生变化,导致质心无法很好代表当前数据,从而影响搜索准确率。

数据变化后,旧质心可能无法很好拟合数据,导致搜索不准确
因此,定期重建索引是必要的维护操作。建议在数据已具代表性时创建索引,并使用并发方式重建以减少对业务的影响:
REINDEX INDEX CONCURRENTLY index_name;
总结
IVFFlat 索引是 pgvector 中应对高维向量近似最近邻搜索的经典解决方案。它通过聚类和倒排索引结构,巧妙地在搜索速度与结果准确性之间取得平衡。合理配置 lists 和 probes 参数,并定期重建索引以保持其效能,可以使其在语义搜索、推荐系统、RAG 等 AI 应用中发挥重要作用,让 PostgreSQL 化身高性能的向量数据库。
 发表于 2025-12-15 23:16:51
|
查看: 193|
回复: 0
发表于 2025-12-15 23:16:51
|
查看: 193|
回复: 0
