在 MySQL 数据库的使用过程中,事务是一个绕不开的核心概念。我们常说“事务 ACID 特性”,其中“持久性(Durability)”明确表示:事务一旦提交,其对数据库中数据的修改就应该是永久性的,接下来的操作或故障都不应该对其执行结果有任何影响。
本文将从 MySQL 的底层原理出发,一步步拆解“事务提交”的完整流程,找出数据丢失的潜在风险点,同时给出可落地的解决方案。
打破一个关键误区
要搞懂“提交后数据是否会丢”,首先得打破一个认知误区:事务提交的返回结果,只是“数据库内核确认可以完成持久化”,而非“数据已经真正写入磁盘”。
很多人以为的事务提交流程是“执行 SQL→ 修改数据 → 写入磁盘 → 返回成功”,但这与 MySQL 的实际实现相去甚远。
为了平衡性能和可靠性,MySQL 引入了“内存缓冲”、“日志机制”等多层设计,这就导致“提交成功”和“数据持久化”之间存在时间差,而这个时间差正是数据丢失风险的根源。
在深入分析前,我们先明确两个关键前提:
- 事务的持久性:ACID 中的 D,理论上要求事务提交后数据永久不丢,但“永久不丢”是理想状态,实际中需通过技术手段无限趋近这一目标。
- MySQL的存储引擎:只有 InnoDB 支持事务,MyISAM 不支持。本文所有分析均基于 InnoDB 引擎。
InnoDB 事务提交的核心流程
InnoDB 之所以能在高性能下保障事务安全,核心依赖于“缓冲池(Buffer Pool)”和“重做日志(Redo Log)”两大机制。理解 MySQL 事务 的底层流程,对于设计高可靠系统至关重要。
事务提交的全过程,本质就是这两大机制协同工作的过程。我们先通过一张图理清整体流程:
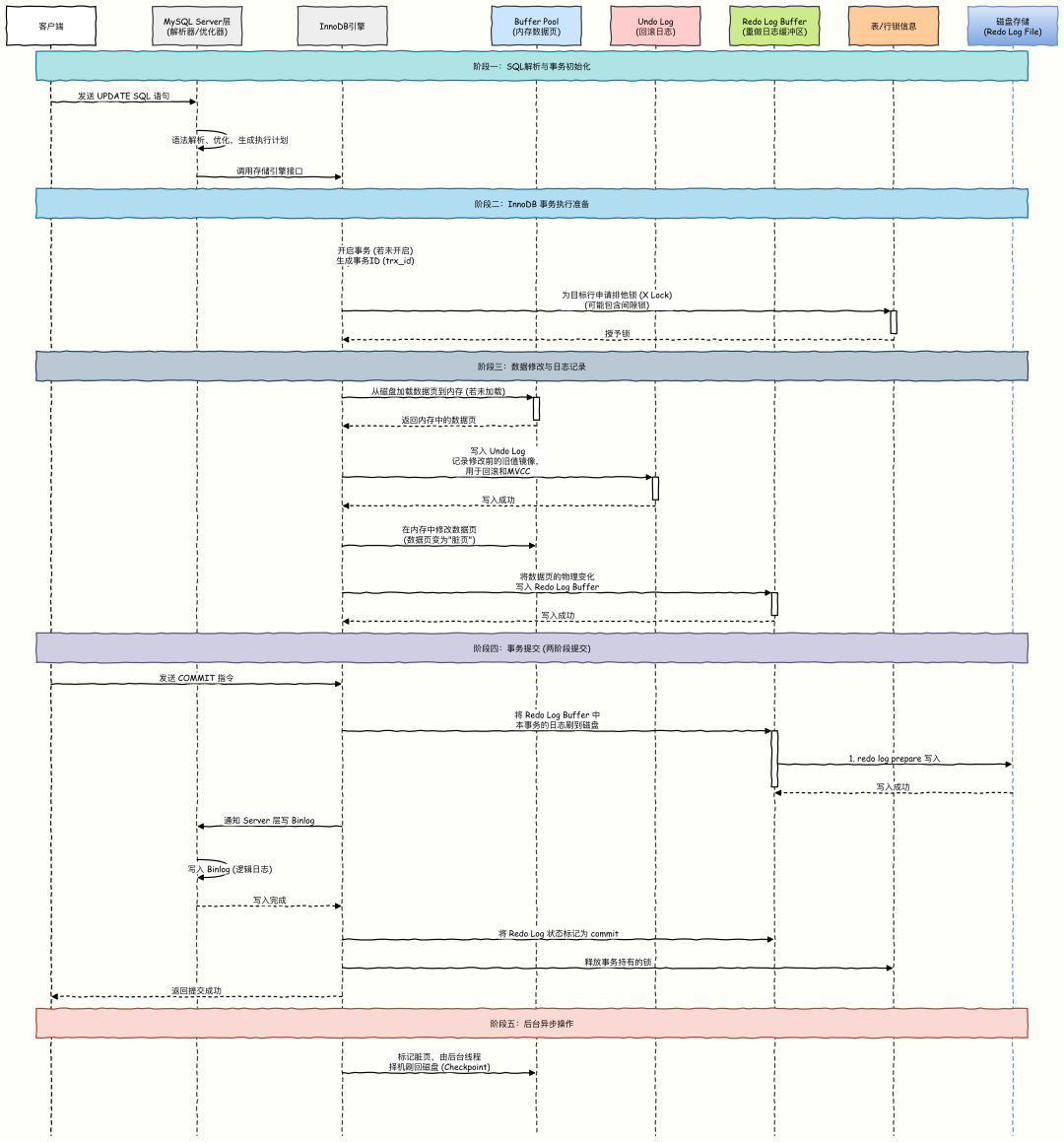
这里用一个 UPDATE 语句执行的例子来介绍事务执行过程。假如说原本 a = 3,现在要执行UPDATE tab SET a = 5 WHERE id = 1。该流程清晰地划分了五个核心阶段:
- SQL 解析与事务初始化:MySQL Server 层负责接收 SQL,进行词法分析、语法优化,生成最优的执行计划。
- InnoDB 事务执行准备:InnoDB 引擎接管后,会为当前事务分配唯一 ID,并根据 WHERE 条件为需要修改的行加上排他锁(X Lock),防止其他事务同时修改相同行。数据被加载到 Buffer Pool 中。
- 数据修改与日志记录(核心):这是保证事务 ACID 特性的关键环节。
- 写 Undo Log:在修改数据前,先将原始数据备份到 Undo Log 中。这确保了事务可以回滚(原子性),同时也是实现 MVCC(多版本并发控制)的基础。
- 修改内存数据页:在 Buffer Pool 中直接修改数据,此时数据页变为“脏页”。
- 写 Redo Log Buffer:将数据页的物理变化记录到重做日志缓冲区。这是 WAL(Write-Ahead Logging)规则的体现,即先写日志,后刷数据。
- 事务提交(两阶段提交):为了确保 Binlog(用于主从复制)和 Redo Log 的一致性,MySQL 使用两阶段提交机制。
- Prepare 阶段:InnoDB 引擎根据
innodb_flush_log_at_trx_commit 参数决定是否将 Redo Log 刷盘,并标记状态为 prepare。
- Commit 阶段:MySQL Server 写入 Binlog 后,再将 Redo Log 标记为
commit。至此,事务才被视为真正提交,锁被释放。
- 后台异步操作:事务提交后,被修改的“脏页”并不会立即刷回磁盘,而是由后台线程异步完成,这极大地提升了性能。
这张图揭示了三个关键问题,也是数据丢失风险的核心:
- 为什么不直接把数据写入磁盘,而要先写缓冲池?
- 重做日志(Redo Log)到底是什么,为什么它的刷盘比数据刷盘更重要?
- 事务提交时,重做日志是“必须刷盘”还是“可以延迟刷盘”?
我们逐一拆解这三个问题,就能彻底搞懂提交后数据丢失的根源。
前置知识:关键日志机制详解
在 update 事务执行过程中,我们看到了几个关键术语:binlog、undo log、redo log、buffer pool。下面详细解释它们的作用。
Undo Log:事务的“后悔药”
Undo Log 指回滚日志,它记录着事务执行过程中被修改前的数据。当事务回滚时,InnoDB 会根据 Undo Log 里的数据撤销事务的更改,把数据库恢复到原来的状态。
- 对于 INSERT 操作,对应的 Undo Log 记录了该行的主键,回滚时根据主键删除记录。
- 对于 DELETE 操作,对应的 Undo Log 记录了该行的主键。因为在事务执行 DELETE 时,实际上只是把原记录的删除标记位设置成了 true。
- 对于 UPDATE 操作,分为两种情况:
- 如果没有更新主键,那么 Undo Log 里面就记录原记录的主键和被修改的列的原值。
- 如果更新了主键,可以看作是删除了原行并插入了新行,因此 Undo Log 对应的是 DELETE 原数据加上 INSERT 新行的组合。
Undo Log 的生命周期还与 MVCC 的构建紧密相关。
-- 示例:多版本链的形成
-- 事务1 (trx_id=100) 插入记录
BEGIN;
INSERT INTO t1 (id, name, value) VALUES (1, 'A', 100);
COMMIT;
-- 事务2 (trx_id=200) 更新记录
BEGIN;
UPDATE t1 SET value = 200 WHERE id = 1; -- 生成 undo log1
-- 此时版本链:当前记录(trx_id=200) -> undo log1(trx_id=100)
-- 事务3 (trx_id=300) 再次更新
BEGIN;
UPDATE t1 SET value = 300 WHERE id = 1; -- 生成 undo log2
-- 此时版本链:当前记录(trx_id=300) -> undo log2(trx_id=200) -> undo log1(trx_id=100)
Redo Log:持久性的守护者
InnoDB 引擎在数据发生更改时,会把更改操作记录在 Redo Log 里,以便在数据库崩溃后能够通过 Redo Log 重做(Redo)所有已提交的操作。
InnoDB 引擎的读写并非直接操作磁盘,而是操作内存中的 Buffer Pool,之后再异步将修改过的“脏页”刷新到磁盘。这两个步骤之间存在着时间窗口,如果在此期间数据库崩溃,Buffer Pool 中已提交但未落盘的数据就会丢失。
为了解决这个问题,InnoDB 引入了 Redo Log。相当于 InnoDB 先更新 Buffer Pool 里的数据,再写一份 Redo Log 记录下这个“动作”。等到事务结束后,Buffer Pool 的数据才会被异步刷盘。万一事务提交后,Buffer Pool 的数据因崩溃丢失,就可以用已持久化的 Redo Log 来恢复。
Redo Log 的核心作用是“故障恢复”:如果服务器断电,缓冲池中的脏页丢失,重启后 MySQL 会读取 Redo Log,将所有已提交但未刷盘的操作重新执行一遍,从而恢复数据。 这就是“持久性”的底层保障——只要 Redo Log 已经刷盘,即使数据没刷盘,数据也能恢复。
到这里,我们可以得出一个关键结论:事务提交后数据是否会丢,本质上取决于 Redo Log 是否已经刷盘。如果 Redo Log 没刷盘,即使提示提交成功,断电后数据也会丢失;如果 Redo Log 已经刷盘,即使数据没刷盘,重启后也能通过 Redo Log 恢复。
Redo Log 记录的是“数据修改的物理动作”,而非修改后的数据本身。记录“动作”比记录“结果”更精简,写入速度更快。
那么,Redo Log 本身如何刷盘呢?Redo Log 也是先写入内存中的 Redo Log Buffer,之后再根据策略刷新到操作系统的 Page Cache 或磁盘。InnoDB 提供了关键参数 innodb_flush_log_at_trx_commit 来控制刷盘时机,该参数的设置直接影响着 运维与 DevOps 场景下的数据可靠性与性能平衡:
- 0:每秒将 Redo Log Buffer 的内容刷新到磁盘一次。事务提交时并不强制刷盘。
- 1:每次事务提交时都将 Redo Log Buffer 的内容刷新到磁盘。这是最安全的选项,也是 InnoDB 的默认值。
- 2:每次事务提交时仅将 Redo Log Buffer 的内容刷新到操作系统的 Page Cache 中,依赖操作系统后续调度刷盘。
由此可知,除非将 innodb_flush_log_at_trx_commit 设置为 1,否则其他两个选项都存在数据丢失风险:
- 设置为 0:事务提交后,若在下一秒刷盘前发生宕机,Redo Log 丢失。
- 设置为 2:事务提交后,Redo Log 已进入 Page Cache,若此时发生操作系统级别崩溃(如断电),Page Cache 中的数据丢失。
在这两个场景下,业务层都认为事务提交成功了,但数据库实际上丢失了这个事务。
流程如下:
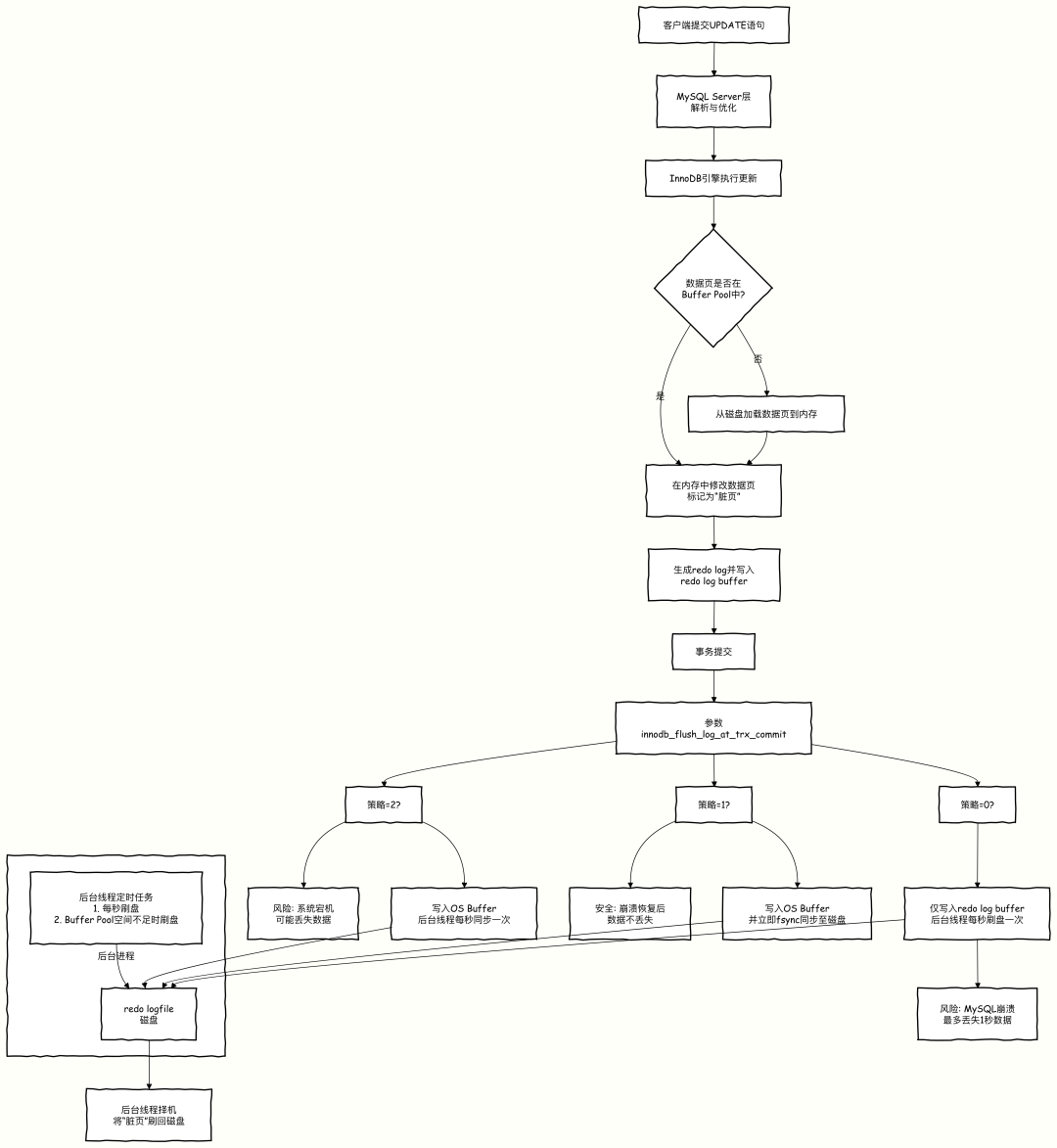
实际案例:某电商平台的订单系统,MySQL 的 innodb_flush_log_at_trx_commit 配置为 2。某次服务器突然断电,重启后发现有 10 分钟内的订单数据丢失。事后排查发现,正是因为这 10 分钟内的订单事务虽然提交成功,但 Redo Log 还在 OS Page Cache 中,没刷到物理磁盘,断电后无法恢复。
Binlog 与两阶段提交
Binlog(Binary Log)是 MySQL Server 级别的二进制日志,它记录了所有对数据库的数据变更操作(DML、DDL),主要用于主从复制和数据恢复。
在事务执行过程中,Binlog 的写入时机与 Redo Log 紧密耦合,共同构成了 MySQL 的两阶段提交(2PC) 机制,这是保证主从数据一致性的核心。
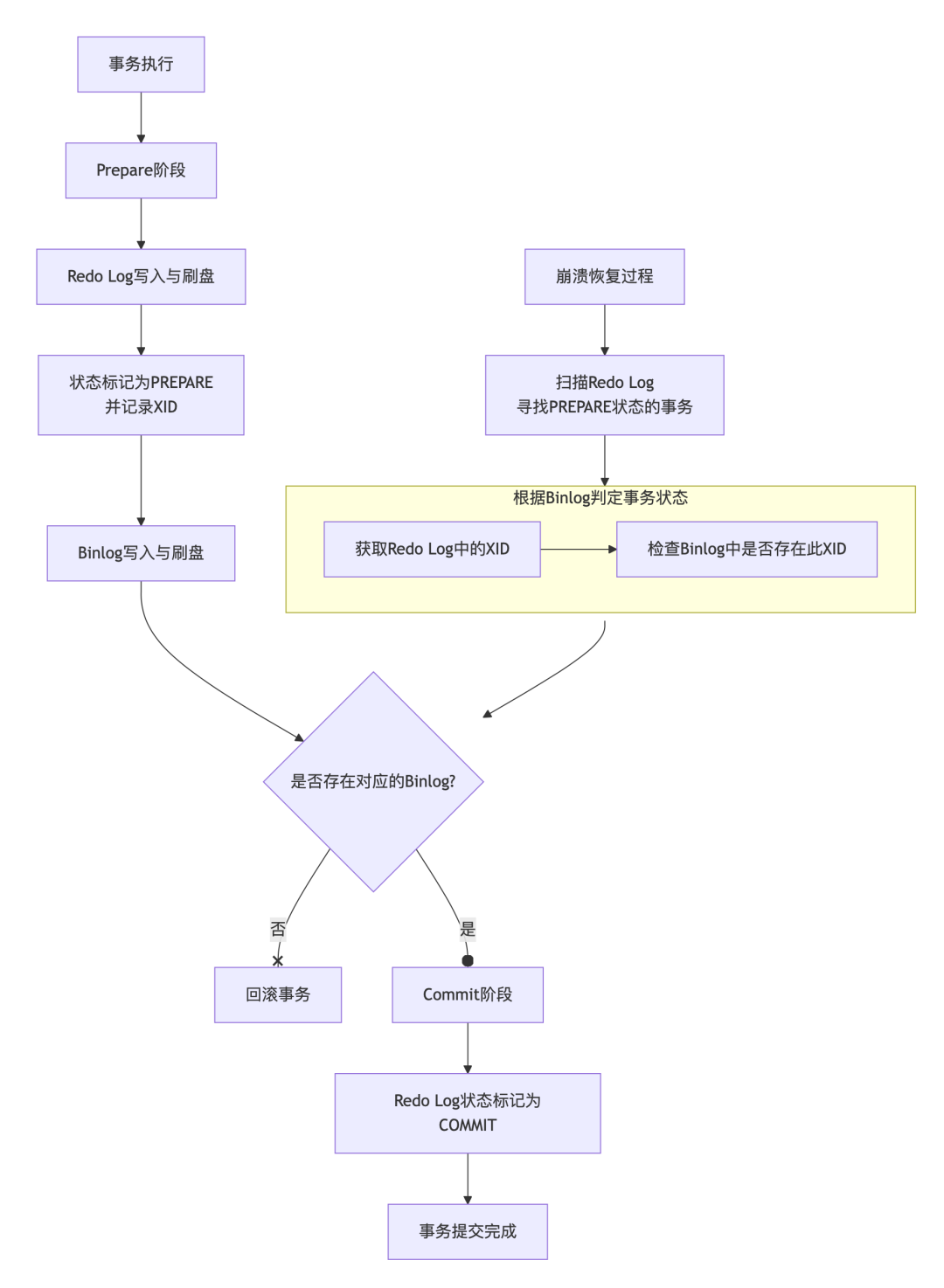
- Prepare 阶段:InnoDB 将事务的 Redo Log 写入磁盘(取决于
innodb_flush_log_at_trx_commit 设置),并将事务状态标记为 PREPARE。
- Commit 阶段:
- 写入 Binlog:MySQL Server 将事务的 Binlog 写入磁盘文件(可能还在 Page Cache)。
- 刷盘 Binlog:根据
sync_binlog 参数决定何时将 Binlog 从缓存强制刷盘。
- 标记 Commit:InnoDB 在 Redo Log 中将该事务状态标记为
COMMIT。
崩溃恢复逻辑:MySQL 重启后,会检查 Redo Log 和 Binlog。
- 如果 Redo Log 中有
PREPARE 记录,但找不到对应的 COMMIT 记录,则会去检查 Binlog。
- 如果 Binlog 是完整且已落盘的,MySQL 则认为事务应该提交,会重做该事务(依据 Redo Log)并补上
COMMIT 标记。
- 如果 Binlog 中没有该事务的记录,MySQL 则认为事务应该回滚,会利用 Undo Log 进行回滚。
简而言之,只要 Binlog 写成功了,MySQL 就认为事务最终应该提交。Binlog 自身的完整性由参数 sync_binlog 控制:
- 0:由操作系统决定刷盘时机,写入 Page Cache 即返回成功。默认值,性能最好。
- 1:每次事务提交都将 Binlog 刷盘。最安全,性能开销最大。
- N (N>1):每 N 次事务提交刷盘一次 Binlog。性能与安全性的折中。
总结与参数调优建议
为了在保证数据安全和高性能之间取得平衡,后端架构师 需要审慎调整以下几个关键参数:
sync_binlog:控制 Binlog 刷盘策略。
- 设为 1 最安全(每次提交都刷盘),但性能开销最大。
- 设为 大于1的值(如100)可提升性能,但宕机可能丢失最近 N 个事务的 Binlog。
innodb_flush_log_at_trx_commit:控制 Redo Log 刷盘策略。
- 设为 1 最安全(每次提交都刷盘),是金融、交易等核心系统的推荐配置。
- 设为 0 或 2 可显著提升写入性能,但存在数据丢失风险,适用于可容忍少量数据丢失的业务(如日志采集、 metrics 统计)。
配置策略参考:
- 对数据一致性要求极高的场景:建议
sync_binlog=1 且 innodb_flush_log_at_trx_commit=1。这是最安全的配置组合。
- 对性能要求高,可容忍少量数据丢失的场景:可考虑将
innodb_flush_log_at_trx_commit 设为 0 或 2,同时将 sync_binlog 设为一个较大的值(如 100),以平衡性能与可靠性。
理解这些机制和参数,是构建高可靠 MySQL 数据库服务的基石。
 发表于 2025-12-16 00:18:58
|
查看: 174|
回复: 0
发表于 2025-12-16 00:18:58
|
查看: 174|
回复: 0
