技术背景
在构建多因子模型的过程中,除了因子计算与预处理,因子择时是提升策略有效性的关键环节。其核心在于通过分析因子的历史表现,提炼轮动规律,预测因子未来收益潜力,进而在合成时给予预期表现好的因子更高权重,降低甚至剔除预期不佳因子的权重。
此前我们探讨过多种因子合成与赋权方法,例如通过最大化ICIR的目标函数进行条件优化,以及等权、IC加权等七种常见合成方法。本文将聚焦于一种更为前沿的实践:利用XGBoost算法进行多因子动态择时,该方法综合考量因子自身时序信息与外部宏观市场变量,为因子权重的动态调整提供了数据驱动的解决方案。
算法原理
一、核心思路
传统的因子择时多依赖因子自身的IC、IR等时序指标,通过时间序列模型或优化算法确定静态或缓慢变化的权重。一个更深入的思考是:因子,尤其是风格因子的收益,是否与宏观经济状态、市场整体波动等外部信息相关?能否引入这些变量来更精准地预测因子未来有效性?
基于此,本文介绍的算法将因子择时问题转化为一个预测问题:使用XGBoost模型,以因子历史IC、宏观指标、市场波动率等作为特征,预测因子在未来一期的IC值。预测出的IC值将直接作为动态调整因子权重的依据。简言之,在通过因子预测股票收益的基础上,增加了一层对因子本身预测能力的预测,从而优化顶层因子的权重配置,旨在提升整体模型的选股能力。
二、XGBoost算法简介
XGBoost(eXtreme Gradient Boosting)是一种高效的梯度提升框架,属于集成学习中Boosting家族。其核心思想是通过迭代地添加决策树(弱学习器),不断修正前序模型的残差,最终组合成一个强预测模型。
1. 目标函数
假设经过 t 轮迭代,模型预测结果为所有树预测值的加和:$\hat{y}_i = \sum_{k=1}^{t} f_k(x_i)$。XGBoost的目标函数同时考虑预测误差和模型复杂度:
$$Obj^{(t)} = \sum_{i=1}^{n} l(y_i, \hat{y}_i^{(t)}) + \sum_{k=1}^{t} \Omega(f_k)$$
其中,$l$ 为损失函数(如均方误差),$\Omega(f_k)$ 为第 k 棵树的复杂度正则项。
2. 近似优化
为高效求解,XGBoost对目标函数进行二阶泰勒展开近似:
$$Obj^{(t)} \approx \sum_{i=1}^{n} [g_i f_t(x_i) + \frac{1}{2} h_i f_t^2(x_i)] + \Omega(f_t)$$
这里,$g_i$ 和 $h_i$ 分别是损失函数的一阶和二阶梯度。
3. 树结构与分裂
通过贪心算法寻找最优分裂点,分裂增益(Gain)计算公式为:
$$Gain = \frac{1}{2} \left[ \frac{(\sum_{i \in I_L} g_i)^2}{\sum_{i \in I_L} h_i + \lambda} + \frac{(\sum_{i \in I_R} g_i)^2}{\sum_{i \in I_R} h_i + \lambda} - \frac{(\sum_{i \in I} g_i)^2}{\sum_{i \in I} h_i + \lambda} \right] - \gamma$$
其中 $I_L$, $I_R$ 为分裂后的左右节点样本集,$\lambda$ 和 $\gamma$ 为正则化参数。选择使 Gain 最大的特征和分裂点进行节点分裂。
具体算法与实现步骤
整个策略的实现框架如下图所示,通常以Python作为开发主体:
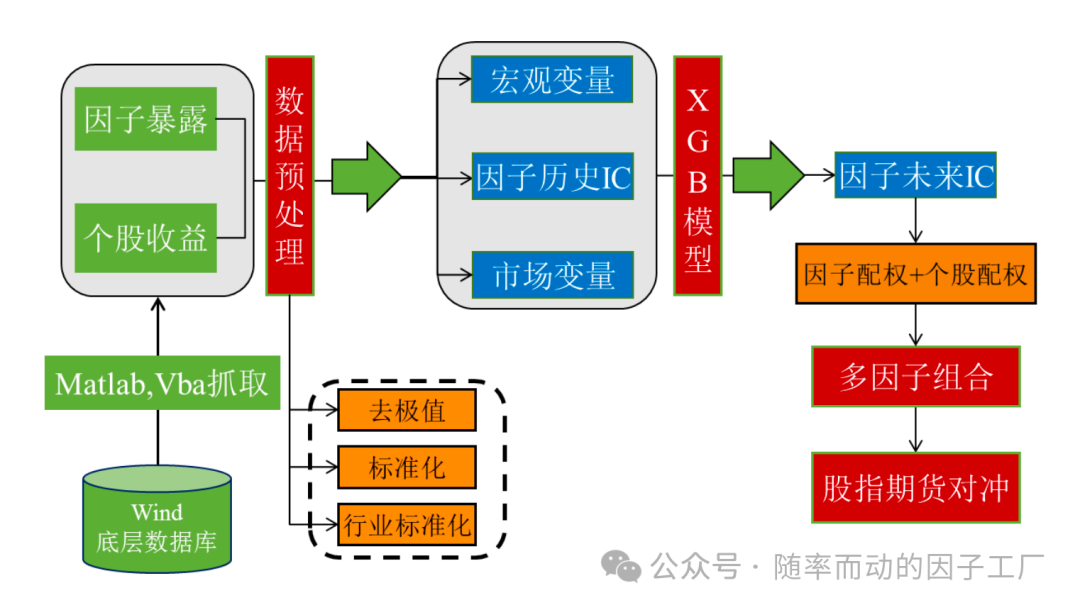
1. 选股因子池
构建涵盖基本面、技术面、动量、质量等多维度的因子库。使用Python进行数据获取,并完成因子的去极值、标准化、行业中性化等预处理。
2. 因子IC计算
采用常规方法计算各因子在历史各期的Rank IC(排名相关性系数)。
3. 特征工程:宏观与市场因子
引入宏观经济指标(如PMI、利率、通胀数据)和市场指标(如指数波动率、动量、宽基指数收益率)作为预测因子IC的特征。对于非平稳的宏观序列,通常进行一阶差分处理以获取平稳的“变化量”序列,该信息对市场往往更具指示意义。
4. 模型训练与IC预测
以历史各期的因子IC作为标签,以同期的因子自身历史IC序列、宏观及市场因子作为特征,滚动训练XGBoost模型,预测下一期的因子IC值。
5. 特征重要性分析
XGBoost内置特征重要性评估功能,常用方式有‘weight’(特征被用作分裂点的次数)、‘gain’(分裂带来的平均增益)和‘cover’(分裂覆盖的平均样本数)。此功能可用于策略优化:若某因子或宏观特征的重要性持续低于阈值,可在当期将其从预测模型中剔除,以防止过拟合。
6. 动态调仓策略
- 调仓频率:通常采用周频(例如5个交易日)进行预测和调仓,以平衡信号频率与交易成本。
- 权重计算:
- 对于正向因子,若预测IC $IC_{i,t}^{pred} > 0$,则令其当期权重 $w_{i,t} = IC_{i,t}^{pred}$;否则 $w_{i,t} = 0$。
- 对于负向因子,若预测IC $IC_{i,t}^{pred} < 0$,则令 $w_{i,t} = -IC_{i,t}^{pred}$;否则 $w_{i,t} = 0$。
- 权重归一化:对非零权重进行归一化,使得 $\sum w_{i,t} = 1$。若所有因子预测IC均无效,则回退至等权配置。
模型效果检验
类比Rank IC评价因子选股能力,我们可以定义“预测IC”与“实际下一期IC”之间的相关系数,作为评价择时模型有效性的指标。回溯测试显示,该相关性在中证500指数增强场景中可达18%左右,表明模型对因子未来有效性具备一定的预测能力。
总结与应用场景
应用一:单因子择时策略
根据模型预测的单因子IC值决定操作:若预测有效,则依据该因子构建多头组合;若预测无效,则持有基准指数。
应用二:多因子动态合成策略
每期根据上述权重计算规则,动态合成当期的综合因子。仅保留预测IC方向与因子理论方向一致的因子参与合成,并按其预测IC绝对值大小加权,从而实现因子的动态择优与权重分配。
核心总结
在多因子模型中,因子择时的本质是预估因子未来的有效性。本文将股票收益预测问题转化为因子IC预测问题,并详细阐述了利用XGBoost这一强大机器学习工具实现因子动态择时的完整流程。该方法通过引入更丰富的信息维度,为提升多因子模型的适应性与表现提供了一种可行的技术路径。
 发表于 2025-12-16 17:14:16
|
查看: 318|
回复: 0
发表于 2025-12-16 17:14:16
|
查看: 318|
回复: 0
