YOLOv5的detect.py脚本是模型训练完成后执行推理(Inference)任务的核心文件。它负责加载训练好的权重,对图像、视频、实时流等多种输入源进行预测,识别并标记出其中的目标对象。本文将从参数解析、模型加载到结果输出的完整流程,对该脚本的源代码进行详细解读。
典型调用方式
执行推理任务时,最核心的两个参数是--weights(指定模型文件)和--source(指定输入源)。以下是几种常见的使用场景:
对单张图片或图片目录进行检测并显示结果:
python detect.py --weights best.pt --source path/to/image.jpg --view-img
python detect.py --weights best.pt --source path/to/directory --view-img
对视频文件进行检测,并保存结果视频及检测数据(如标签文件):
python detect.py --weights best.pt --source video.mp4 --conf-thres 0.5 --save-txt --save-conf
调用摄像头(如UVC摄像头)进行实时检测,并仅检测特定类别:
python detect.py --weights best.pt --source 0 --classes 0 2 --view-img
执行后,生成的结果默认保存在 runs/detect/exp 目录下,可通过 --project 和 --name 参数修改保存路径。
参数详解
detect.py 使用 argparse 模块管理丰富的运行参数。下表列出了其主要参数、默认值及功能说明:
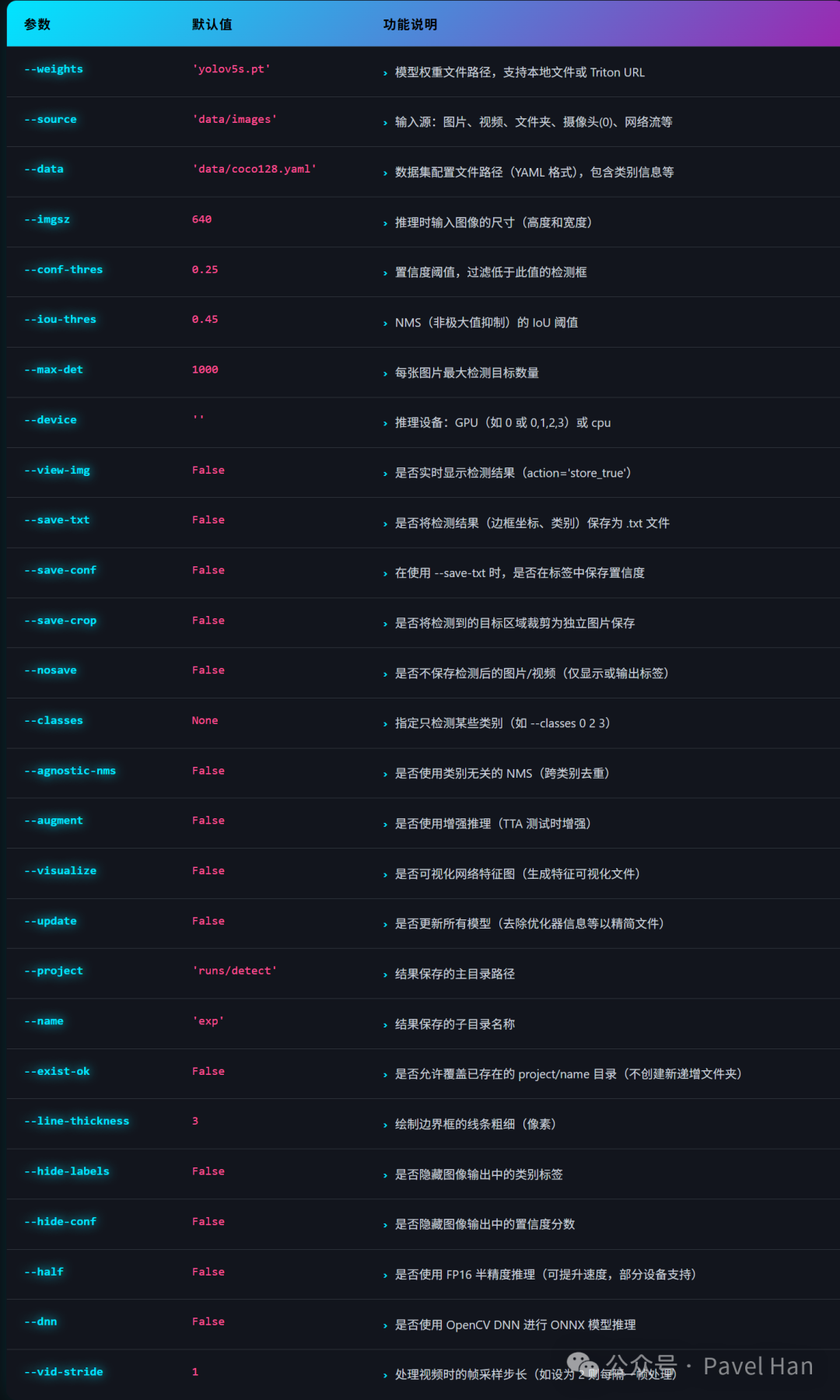
下面对部分需要重点理解的参数进行补充说明:
--data:通常无需指定。因为 .pt 模型文件中已内嵌了训练时的类别信息。若强制指定一个YAML配置文件,其中的类别名(names)会覆盖模型内置信息,可能引起混淆。推荐直接使用模型文件自带的类别定义。--dnn:此参数用于尝试使用OpenCV的DNN模块(而非默认的PyTorch)进行推理计算,旨在与某些C++应用集成时可能获得更好的性能。注意:使用此参数的前提是模型必须为ONNX格式。--visualize:启用后,会在推理过程中保存YOLOv5主干网络各层的特征图,便于直观分析网络的工作机制与特征提取过程。--augment:对应推理时的测试时增强(Test Time Augmentation, TTA)技术。通过对输入图像进行缩放、翻转等操作生成多个变体,分别推理后再融合结果,可以提升检测的稳定性和准确性,但会显著增加单次推理耗时。--update:训练得到的 .pt 文件包含优化器状态、训练轮次等冗余信息。使用此参数后,推理过程会剥离这些信息,生成一个只包含模型权重、结构和必要元数据的“干净”版本,更适合部署与分享。请注意,此操作不可逆,处理后的模型无法用于恢复训练,操作前请备份原权重文件。
推理执行流程源码解析
detect.py的主体逻辑主要由两个函数构成:parse_opt() 负责参数解析,run() 负责执行完整的推理流程。run函数的执行流程可概括为下图:
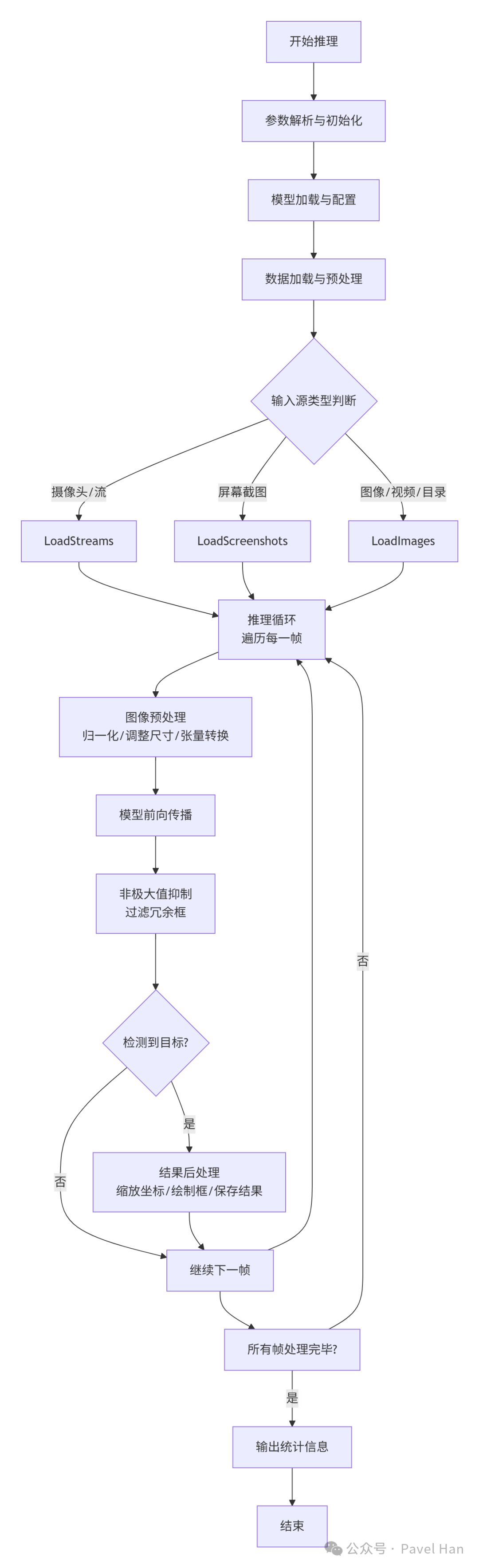
接下来,我们对代码中的关键环节进行剖析。
1. 模型加载
# Load model
device = select_device(device) # 根据 --device 参数选择CPU/CUDA/MPS设备
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # 检查并调整图像尺寸为stride的整数倍
首先,select_device 函数根据 --device 参数创建对应的计算设备(CPU、CUDA或Apple MPS)。随后,通过 DetectMultiBackend 类加载模型。该类设计用于支持多种模型格式,提升了部署的灵活性,其支持的后端包括:
- PyTorch (
.pt)
- TorchScript (
.torchscript)
- ONNX Runtime (
.onnx)
- ONNX OpenCV DNN (
.onnx with --dnn)
- TensorRT (
.engine)
- TensorFlow (
.pb, _saved_model)
- TensorFlow Lite (
.tflite)
- CoreML (
.mlpackage)
- OpenVINO (
_openvino_model)
- PaddlePaddle (
_paddle_model)
2. 数据加载器(Dataloader)创建
根据 --source 指定的输入源类型,创建相应的数据加载器,后续推理循环将从中逐帧读取数据。
# Dataloader
bs = 1 # batch_size
if webcam: # 摄像头或网络流
view_img = check_imshow(warn=True)
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
bs = len(dataset) # batch_size 等于流数量
elif screenshot: # 屏幕截图
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else: # 图片、视频文件或目录
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
webcam:处理摄像头索引(如0)或RTSP/RTMP等流媒体URL,使用LoadStreams,batch_size等于同时处理的流数量。screenshot:处理屏幕截图,使用LoadScreenshots,batch_size固定为1。- 其他:处理图片、视频文件或目录,使用
LoadImages,batch_size固定为1。
3. 推理循环
对于数据加载器中的每一帧(或每一批)数据,执行以下三步核心操作:
for path, im, im0s, vid_cap, s in dataset:
# 预热模型并创建性能分析器
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz))
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
# 子过程1:图像预处理
with dt[0]:
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float() # 转换数据类型
im /= 255 # 像素值归一化 [0, 255] -> [0, 1]
if len(im.shape) == 3:
im = im[None] # 扩展出batch维度
# 子过程2:模型前向推理
with dt[1]:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
# 子过程3:非极大值抑制(NMS)
with dt[2]:
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
- 预热(Warmup):在正式推理前,向模型传入虚拟数据(dummy data)进行几次前向传播,使GPU/CPU达到最佳性能状态,对连续视频流推理尤为重要。
- 预处理:将numpy数组转为PyTorch张量,移至指定设备,进行归一化并添加批次维度。
- 推理:调用模型进行前向计算。这里支持 Python 生态下的多种推理后端,并可选择是否启用TTA或特征图可视化。
- NMS:对原始预测结果进行过滤,消除重叠度高的冗余检测框。
4. 结果解析与输出
NMS处理后得到的 pred 是一个列表,包含批次中每张图片的检测结果。每张图片的检测结果 det 是一个形状为 (n, 6) 的张量,n 为目标数量,6个维度依次为:(x1, y1, x2, y2, conf, cls),即边界框左上角、右下角坐标、置信度和类别索引。
后续处理代码负责解析这些结果,并将其绘制到原始图像上或保存到文件:
# Process predictions
for i, det in enumerate(pred): # 遍历批次中的每张图片
...
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det): # 如果检测到目标
# 将边界框坐标从模型输入尺寸缩放回原始图像尺寸
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# 统计各类别数量
for c in det[:, 5].unique():
n = (det[:, 5] == c).sum()
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, "
# 遍历每个检测框,进行标注或保存
for *xyxy, conf, cls in reversed(det):
c = int(cls)
label = f"{names[c]} {conf:.2f}"
annotator.box_label(xyxy, label, color=colors(c, True))
代码首先使用 scale_boxes 函数将模型输出坐标(基于640x640输入)映射回原始图像尺寸。然后,它利用 Annotator 类在图像上绘制边界框和标签。整个过程充分体现了 人工智能 应用从模型计算到结果可视化的完整链路。
 发表于 2025-12-16 17:38:03
|
查看: 259|
回复: 0
发表于 2025-12-16 17:38:03
|
查看: 259|
回复: 0
